DistillNeRF: Perceiving 3D Scenes from Single-Glance Images by Distilling Neural Fields and Foundation Model Features
Letian Wang, Seung Wook Kim, Jiawei Yang, Cunjun Yu, Boris Ivanovic, Steven L. Waslander, Yue Wang, Sanja Fidler, Marco Pavone, Peter Karkus·June 17, 2024
Summary
DistillNeRF is a self-supervised learning framework for autonomous driving that combines Neural Radiance Fields (NeRFs) and pre-trained 2D foundation models like CLIP or DINOv2. The model introduces a novel architecture with a two-stage encoder and hierarchical voxel representation, enabling scene reconstruction, novel view synthesis, depth estimation, and zero-shot 3D semantic prediction. Key contributions include a Lift-Splat-Shoot encoder, sparse voxels, and differentiable volumetric rendering for efficient training. Experiments on the NuScenes dataset demonstrate superior performance over existing methods in various tasks, showcasing its potential for open-world scene understanding in real-time scenarios. The model's strength lies in its ability to generalize from offline NeRF optimization and 2D feature extraction, making it suitable for tasks like RGB and depth rendering, semantic occupancy prediction, and open-vocabulary text queries.
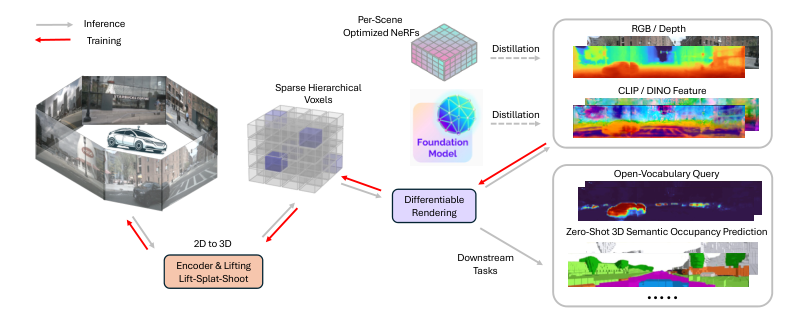

Introduction
Background
Evolution of Neural Radiance Fields (NeRFs) in computer vision
Importance of foundation models in 2D tasks
Objective
To develop a unified framework for autonomous driving tasks
Improve scene understanding with self-supervision
Method
Architecture
Lift-Splat-Shoot Encoder
Description of the two-stage encoder design
Contribution to efficient feature extraction
Hierarchical Voxel Representation
Voxelization for 3D scene representation
Benefits for memory and computational efficiency
Data Collection
Use of pre-trained 2D foundation models (CLIP, DINOv2)
Self-supervised learning with unlabeled driving data
Data Preprocessing
Preprocessing techniques for real-world driving data
Integration of 2D features with 3D voxels
Training Process
Sparse Voxelization
Explanation of sparse voxel sampling for optimization
Differentiable Volumetric Rendering
How the model handles rendering and gradients for learning
Loss Functions
Overview of loss functions for scene reconstruction and novel view synthesis
Experiments and Evaluation
NuScenes Dataset
Dataset description and its relevance
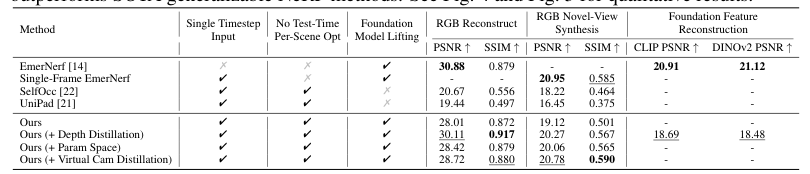
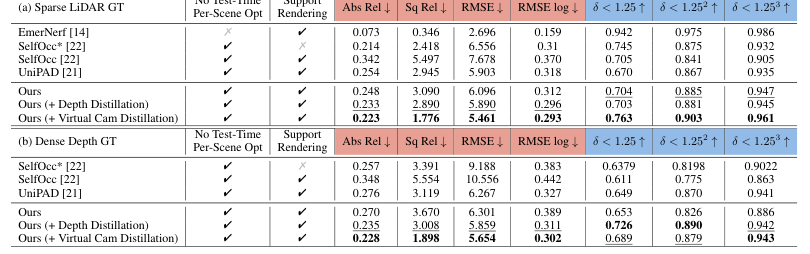
Performance comparison with existing methods
Tasks and Benchmarks
RGB and depth rendering
Depth estimation
Semantic occupancy prediction
Zero-shot 3D semantic prediction
Open-vocabulary text queries
Applications and Real-Time Considerations
Potential for real-world deployment
Scalability and adaptability to open-world scenarios
Conclusion
Summary of key contributions
Future directions and potential improvements
Basic info
papers
computer vision and pattern recognition
robotics
artificial intelligence
Advanced features
Insights
What is the primary focus of DistillNeRF in the context of autonomous driving?
What are the key tasks that DistillNeRF excels at on the NuScenes dataset?
How does the Lift-Splat-Shoot encoder contribute to the DistillNeRF architecture?
How does DistillNeRF leverage pre-trained 2D foundation models for scene understanding?