Danoliteracy of Generative, Large Language Models
Søren Vejlgaard Holm, Lars Kai Hansen, Martin Carsten Nielsen·October 30, 2024
Summary
The text discusses a Danish GLLM benchmark evaluating models' abilities across eight scenarios, correlating with human feedback at ρ ∼ 0.8. GPT-4 and Claude Opus rank highest, indicating a strong underlying factor of model consistency in language adaptation, explaining 95% of scenario performance variance. This benchmark aims to standardize the evaluation of Generative, Large Language Models in low-resource languages like Danish. Key findings highlight GPT-4 and Claude Opus models' consistent top performance, outperforming others in Danish contexts. The study suggests a 'Danoliteracy g factor' in GLLMs, correlating performance across diverse scenarios.
Introduction
Background
Overview of Generative Large Language Models (GLLMs)
Importance of evaluating GLLMs in low-resource languages
Context of the Danish GLLM benchmark
Objective
Purpose of the Danish GLLM benchmark
Correlation between model performance and human feedback
Identification of consistent top-performing models
Method
Data Collection
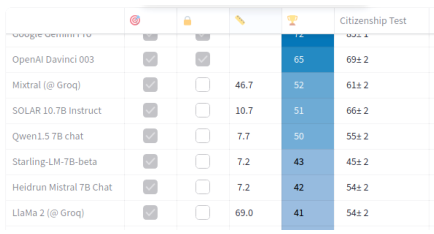
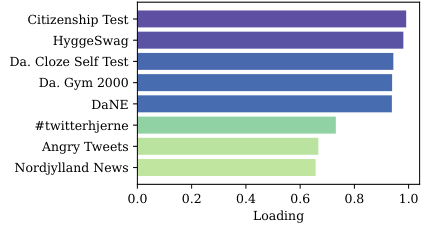
Selection of scenarios for evaluation
Gathering human feedback for correlation analysis
Data Preprocessing
Preparation of data for model evaluation
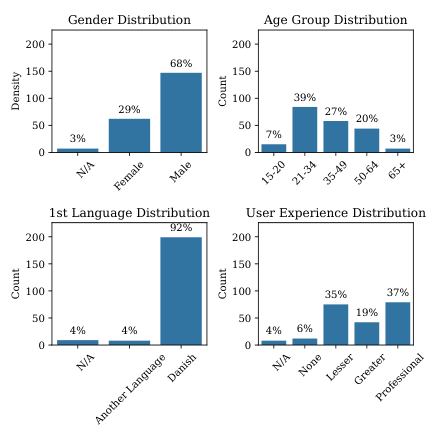
Handling of low-resource language specifics
Results
Model Performance
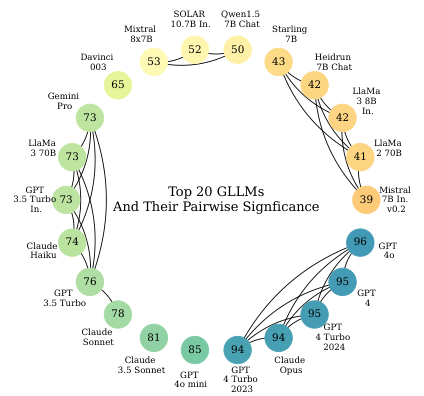
Ranking of GPT-4 and Claude Opus
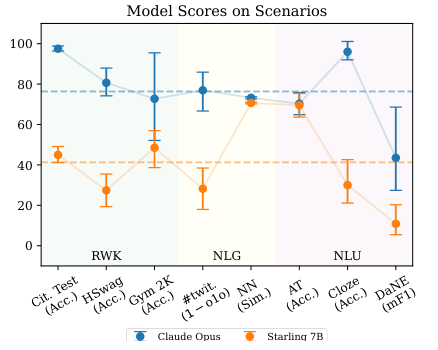
Consistency in performance across eight scenarios
Correlation Analysis
Correlation coefficient (ρ) between model performance and human feedback
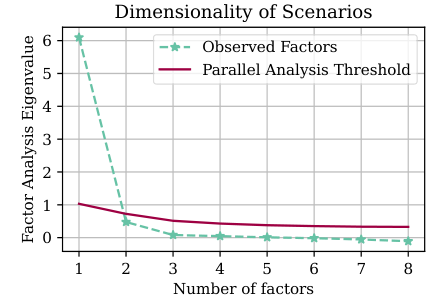
Explanation of 95% variance in scenario performance
Findings
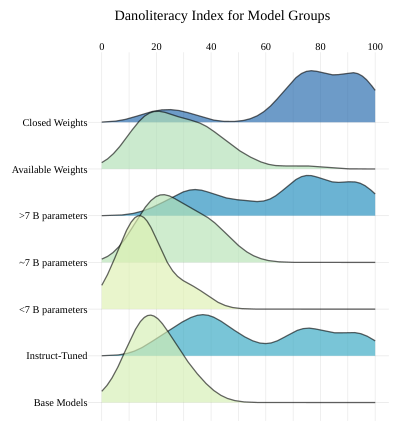
'Danoliteracy g factor'
Identification of a common underlying factor in GLLM performance
Explanation of consistent top performance in Danish contexts
Key Models
Detailed analysis of GPT-4 and Claude Opus
Performance metrics and comparative analysis
Conclusion
Implications
Standardization of GLLM evaluation in low-resource languages
Importance of 'Danoliteracy g factor' in model selection
Future Directions
Potential improvements in model evaluation techniques
Expansion of the benchmark to other low-resource languages
Basic info
papers
computation and language
machine learning
artificial intelligence
Advanced features
Insights
Which models performed the best in the benchmark, and what does this suggest about their capabilities?
How does the benchmark aim to standardize the evaluation of GLLMs in low-resource languages like Danish?
What does the term 'Danoliteracy g factor' refer to in the context of Generative, Large Language Models (GLLMs)?
What is the main focus of the Danish GLLM benchmark discussed in the text?