Causality-Enhanced Behavior Sequence Modeling in LLMs for Personalized Recommendation
Yang Zhang, Juntao You, Yimeng Bai, Jizhi Zhang, Keqin Bao, Wenjie Wang, Tat-Seng Chua·October 30, 2024
Summary
The study introduces Counterfactual Fine-Tuning (CFT) for enhancing Large Language Models (LLMs) in personalized recommendations. CFT emphasizes behavior sequences by using counterfactual reasoning to identify their causal effects on model outputs, directly fitting ground-truth labels based on these effects. A token-level weighting mechanism adjusts emphasis strength, reflecting diminishing influence from earlier to later tokens. Extensive experiments on real-world datasets validate CFT's effectiveness in improving behavior sequence modeling and recommendation accuracy.




Background
Overview of Large Language Models (LLMs)
Importance of personalized recommendations in various applications
Objective
Aim of the study: Enhancing LLMs for personalized recommendations through Counterfactual Fine-Tuning (CFT)
Key objectives of CFT: Utilizing counterfactual reasoning and token-level weighting
Method
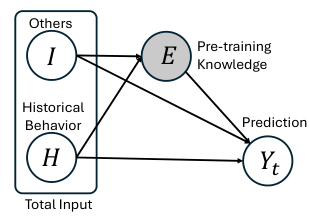
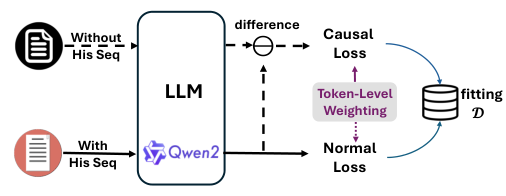
Counterfactual Fine-Tuning (CFT)
Concept and mechanism of CFT
Counterfactual reasoning for identifying causal effects on model outputs
Direct fitting of ground-truth labels based on causal effects
Token-Level Weighting Mechanism
Explanation of the mechanism
How it adjusts emphasis strength from earlier to later tokens
Data Collection
Methods for collecting data relevant to the study
Data Preprocessing
Techniques used for preparing the data for CFT
Evaluation
Metrics for assessing the effectiveness of CFT
Real-world datasets used for validation
Results
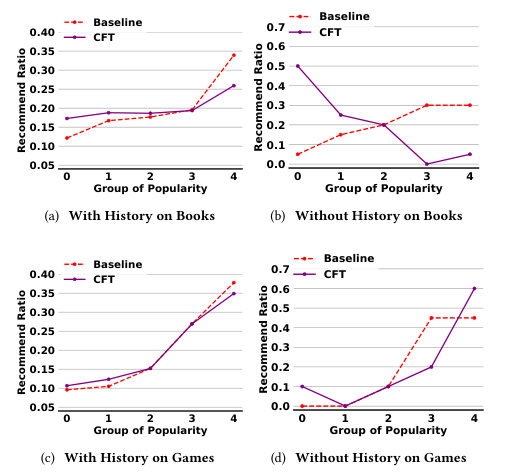
Improvement in Behavior Sequence Modeling
Quantitative and qualitative analysis
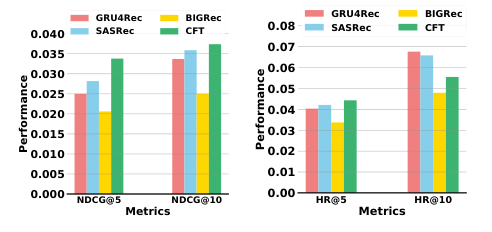
Enhanced Recommendation Accuracy
Comparative analysis with baseline models
Case Studies
Detailed examples demonstrating CFT's impact
Conclusion
Summary of Findings
Implications for Future Research
Practical Applications of CFT in Personalized Recommendations
Basic info
papers
information retrieval
artificial intelligence
Advanced features
Insights
What is the main focus of the study on Counterfactual Fine-Tuning (CFT) for Large Language Models (LLMs)?
How does CFT utilize counterfactual reasoning to enhance personalized recommendations?
What are the results of the extensive experiments conducted on real-world datasets regarding CFT's effectiveness?
What mechanism does CFT employ to adjust the emphasis on tokens in behavior sequences?