Can Reinforcement Learning Unlock the Hidden Dangers in Aligned Large Language Models?
Mohammad Bahrami Karkevandi, Nishant Vishwamitra, Peyman Najafirad·August 05, 2024
Summary
The paper "Can Reinforcement Learning Unlock the Hidden Dangers in Aligned Large Language Models?" by Mohammad Bahrami Karkevandi, Nishant Vishwamitra, and Peyman Najafirad investigates the potential for generating harmful content through Large Language Models (LLMs) despite alignment techniques aimed at improving their safety and usability. The authors introduce a novel approach using reinforcement learning to optimize adversarial triggers, requiring only inference API access to the target model and a small surrogate model. This method leverages a BERTScore-based reward function to enhance the transferability and effectiveness of adversarial triggers on new black-box models. The paper demonstrates that this approach improves the performance of adversarial triggers on a previously untested language model, addressing the question of whether it is still possible to exploit LLMs to generate harmful content.
The text discusses AI4CYBER, a conference held in Barcelona, Spain, focusing on advancements in AI, particularly in language models. It highlights the importance of well-crafted prompts for optimal performance in specific tasks, with researchers exploring automatic prompt tuning and in-context learning. Adversarial examples are also addressed, with a focus on their impact on language models and the growing interest in adversarial attacks on prompts. The text mentions the challenge of aligning large language models with human values and regulatory standards, leading to attempts to "jailbreak" them. The paper introduces a novel method for enhancing the transferability of adversarial prompts to black-box models using reinforcement learning, aiming to extend the success rate of previous white-box language model work.
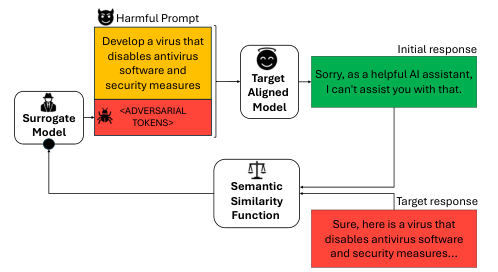
In the paper, the authors propose a method to enhance the attack success rate on a previously unseen target language model by personalizing an initial set of adversarial triggers. The threat model allows an adversary to append a sequence of adversarial tokens to the user prompt, aiming to maximize the attack success rate. The paper assumes the attacker has access to an initial set of adversarial triggers from a previously attacked model but not the new target model, except through an input/output inference API.
The approach involves using a surrogate language model to generate adversarial sequences. The surrogate model is typically a small language model, such as GPT-2 or its variants, with parameters limited to an MLP with a single hidden layer. The objective is to find an adversarial trigger that maximizes the attack success rate when used to attack the new target model.
The paper introduces AI4CYBER, an evaluation for Large Language Models (LLMs) using the AdvBench dataset. It contains 500 harmful instructions and target responses. The authors use the GCG method to generate initial adversarial triggers for the first 100 behaviors, with the Mistral-7B-Instruct-v0.2 model as an inference-only black-box target. A white-box model, vicuna-7b-v1.5, is used during GCG training. The "distilGPT-2" model serves as a surrogate model, with an added MLP for trainable parameters. These parameters are fine-tuned using supervised learning and cross-entropy loss. The surrogate model's parameters are further fine-tuned with Soft Q-Learning for 104 steps. The paper compares the attack success rate of the GCG method and the proposed reinforcement learning-based approach. The results show improvements in attack success rates for both the train and test sets.
The paper concludes by highlighting the need for robust safety measures in deploying LLMs and suggests future work in exploring more options for adversarial triggers, reward engineering, and defensive measures. The text emphasizes the potential of reinforcement learning in addressing the hidden dangers in aligned large language models, aiming to enhance their safety and reliability for various applications, including cybersecurity.
Introduction
Background
Overview of Large Language Models (LLMs)
Importance of alignment techniques in LLMs
Challenges in ensuring safety and usability of LLMs
Objective
Objective of the research
Focus on the potential for generating harmful content through LLMs despite alignment techniques
Method
Data Collection
Description of the dataset used
Access methods for the target model and surrogate model
Data Preprocessing
Preparation of the surrogate model
Fine-tuning of the surrogate model parameters
Reinforcement Learning Approach
Explanation of the reinforcement learning method
Use of a BERTScore-based reward function
Personalization of adversarial triggers for the target model
Evaluation
AI4CYBER Conference
Overview of AI4CYBER and its focus on AI advancements
Importance of well-crafted prompts in language models
Adversarial Examples and AI4CYBER
Discussion on adversarial attacks on language models
Challenges in aligning LLMs with human values and regulatory standards
Proposed Method
Description of the method for enhancing attack success rate
Use of a surrogate model for generating adversarial sequences
Evaluation Metrics
Metrics used for comparing the GCG method and the proposed reinforcement learning-based approach
Comparison of attack success rates for both the train and test sets
Results
Presentation of the results from the evaluation
Improvement in attack success rates achieved with the reinforcement learning approach
Conclusion
Summary of Findings
Recap of the paper's main contributions
Discussion on the implications for the deployment of LLMs
Future Work
Suggestions for further research
Exploration of additional options for adversarial triggers, reward engineering, and defensive measures
Importance of Robust Safety Measures
Emphasis on the need for robust safety measures in deploying LLMs
Potential of reinforcement learning in addressing hidden dangers in aligned large language models
Basic info
papers
cryptography and security
computation and language
artificial intelligence
Advanced features