Beyond Data Quantity: Key Factors Driving Performance in Multilingual Language Models
Sina Bagheri Nezhad, Ameeta Agrawal, Rhitabrat Pokharel·December 17, 2024
Summary
The study examines factors affecting multilingual language model performance across 204 languages, focusing on token & country similarity, pre-training data, and model size. Analyzed through regression models and SHAP values, findings highlight token and country similarity's pivotal role in enhancing model effectiveness, offering insights for developing equitable multilingual models. Key factors include model size, pre-training data distribution, instruction tuning, geographical proximity, country similarity, language family, and script type. Tokenization's impact on cross-lingual transfer and task performance is also considered. The study fills a gap in understanding multilingual language models and guides the development of more equitable models, particularly for underrepresented languages.
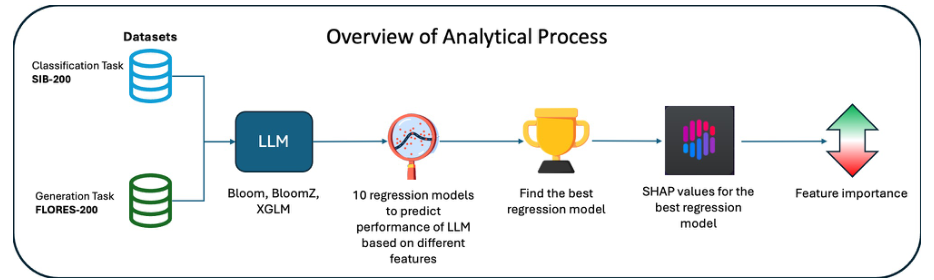
Introduction
Background
Overview of multilingual language models
Importance of understanding model performance across languages
Objective
To investigate factors influencing multilingual language model performance across 204 languages
To analyze the role of token & country similarity, pre-training data, and model size
Method
Data Collection
Gathering datasets for 204 languages
Collecting information on model size, pre-training data, and geographical data
Data Preprocessing
Cleaning and standardizing data
Encoding categorical variables like language family and script type
Regression Models
Applying regression models to identify significant factors
Analyzing the impact of token & country similarity, pre-training data, and model size
SHAP Values
Exploring feature importance through SHAP (SHapley Additive exPlanations) values
Understanding the contribution of each factor to model performance
Analysis
Key Factors
Model size: Impact on performance and resource requirements
Pre-training data distribution: Effect on model generalization and bias
Instruction tuning: Role in adapting models for specific tasks
Geographical proximity: Influence on model performance and data availability
Country similarity: Importance in model transferability and effectiveness
Language family: Influence on model performance and linguistic complexity
Script type: Impact on tokenization and cross-lingual transfer
Tokenization's Impact
Analysis of tokenization's role in cross-lingual transfer and task performance
Findings
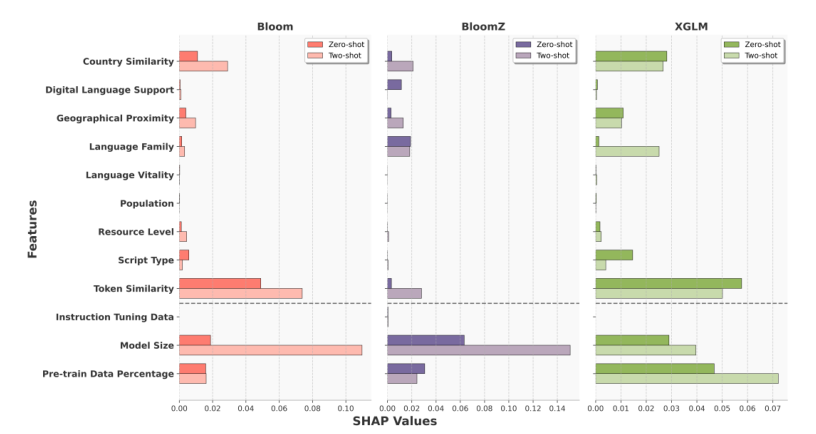
Token and Country Similarity
Highlighting the pivotal role of token and country similarity in enhancing model effectiveness
Model Size, Pre-training Data, and Instruction Tuning
Insights into the optimal balance between model size, pre-training data, and instruction tuning
Geographical Proximity, Country Similarity, Language Family, and Script Type
Understanding how these factors influence model performance and development
Discussion
Equity in Multilingual Models
Addressing the gap in understanding multilingual language models
Implications for developing equitable models, especially for underrepresented languages
Future Directions
Recommendations for further research and model development
Conclusion
Summary of Key Insights
Recap of the study's main findings
Implications for Practice
Practical guidance for improving multilingual language model performance
Call to Action
Encouragement for the language technology community to prioritize equitable model development
Basic info
papers
computation and language
artificial intelligence
Advanced features
Insights
How do token and country similarity contribute to enhancing the effectiveness of these models?
What are the main factors affecting the performance of multilingual language models according to the study?
Which factors, including model size, pre-training data distribution, instruction tuning, and others, are identified as key influencers in the study?