Augmenting Multimodal LLMs with Self-Reflective Tokens for Knowledge-based Visual Question Answering
Federico Cocchi, Nicholas Moratelli, Marcella Cornia, Lorenzo Baraldi, Rita Cucchiara·November 25, 2024
Summary
ReflectiVA, a multimodal Large Language Model (LLM), enhances knowledge-based visual question answering by integrating external knowledge through reflective tokens. These tokens dynamically assess the need for external data and predict its relevance, enabling the LLM to manage external knowledge while maintaining performance on tasks without it. ReflectiVA outperforms existing methods in experiments, demonstrating its effectiveness.
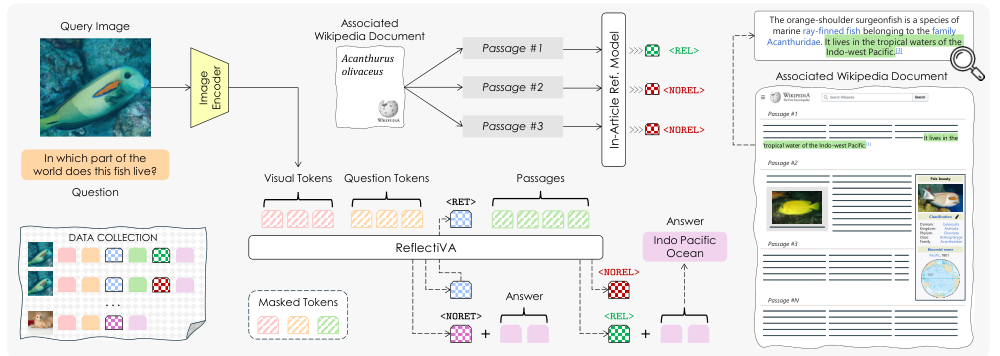




Introduction
Background
Overview of multimodal Large Language Models (LLMs)
Importance of external knowledge in visual question answering
Objective
To introduce ReflectiVA, a novel approach that integrates external knowledge through reflective tokens for improved visual question answering performance
Method
Data Collection
Sources of external knowledge for integration
Methods for collecting relevant data
Data Preprocessing
Techniques for preparing external knowledge for integration into the LLM
Handling of reflective tokens for dynamic knowledge assessment
Model Architecture
Description of ReflectiVA's architecture
Integration of reflective tokens within the LLM framework
Training and Evaluation
Training process of ReflectiVA
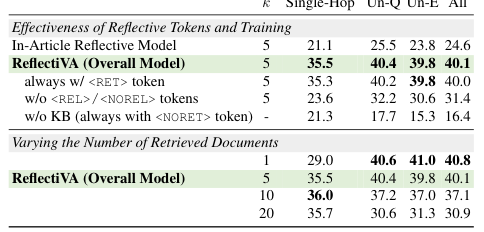
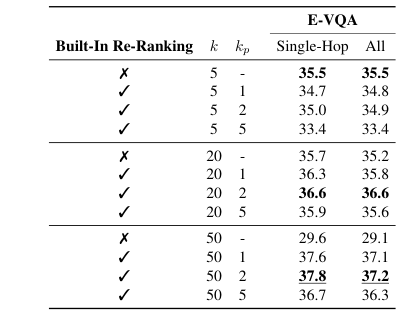
Metrics for evaluating performance improvements
Results
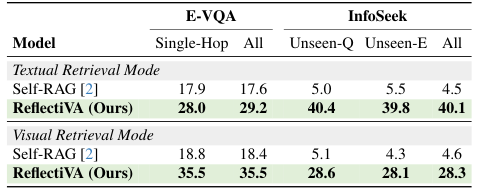
Comparative Analysis
Comparison of ReflectiVA with existing methods
Quantitative and qualitative results demonstrating performance gains
Case Studies
Detailed examples showcasing ReflectiVA's effectiveness in various scenarios
Experimental Setup
Description of the experimental environment and conditions
Discussion
Challenges and Limitations
Discussion on challenges faced during the development and implementation of ReflectiVA
Limitations of the current approach and potential future improvements
Implications
Impact of ReflectiVA on the field of multimodal LLMs and visual question answering
Potential applications and future research directions
Conclusion
Summary of Contributions
Recap of ReflectiVA's advancements in knowledge-based visual question answering
Future Work
Suggestions for further research and development
Acknowledgments
Recognition of contributions from collaborators and sources of data
Basic info
papers
computer vision and pattern recognition
computation and language
multimedia
artificial intelligence
Advanced features
Insights
How does ReflectiVA integrate external knowledge for enhancing knowledge-based visual question answering?
What role do reflective tokens play in the operation of ReflectiVA?
In what way does ReflectiVA outperform existing methods according to the experiments mentioned?
What is the main contribution of ReflectiVA in the context of multimodal Large Language Models (LLMs)?