Asynchronous RLHF: Faster and More Efficient Off-Policy RL for Language Models
Michael Noukhovitch, Shengyi Huang, Sophie Xhonneux, Arian Hosseini, Rishabh Agarwal, Aaron Courville·October 23, 2024
Summary
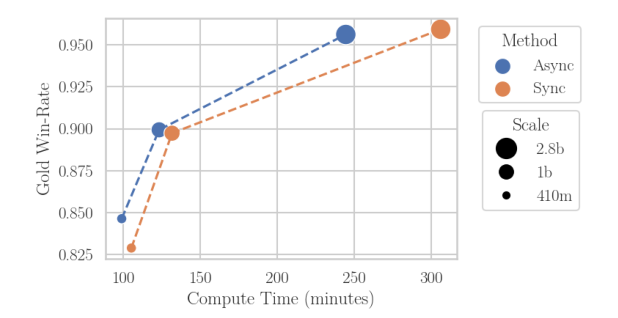
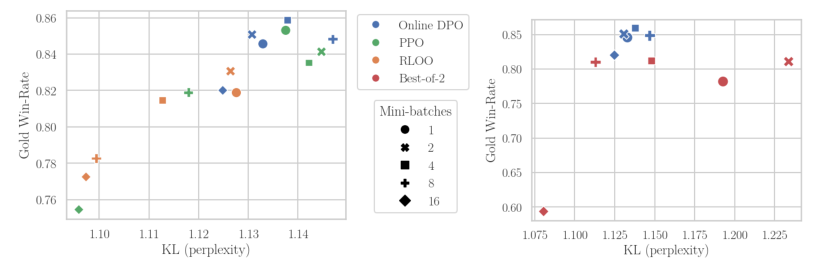
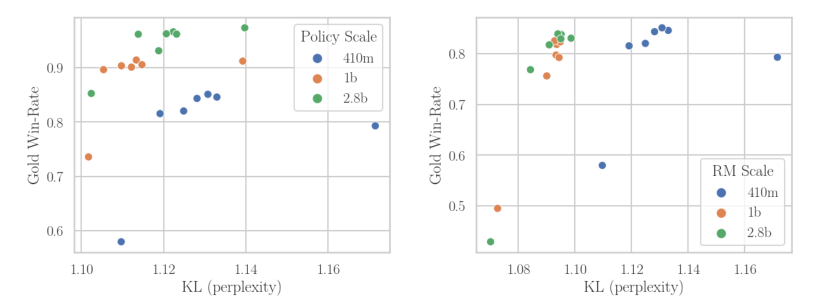
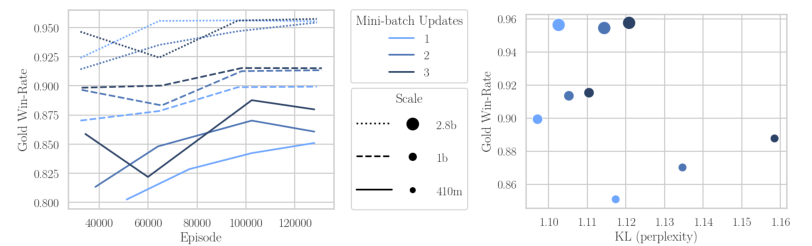
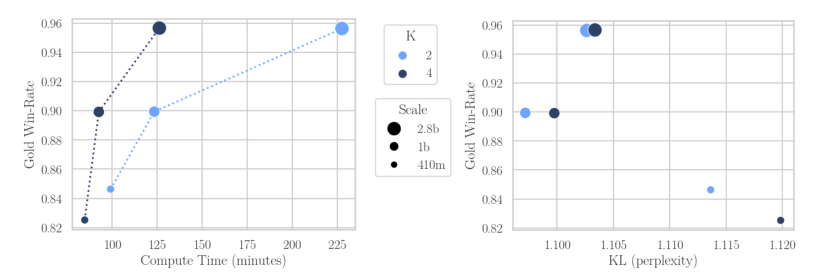
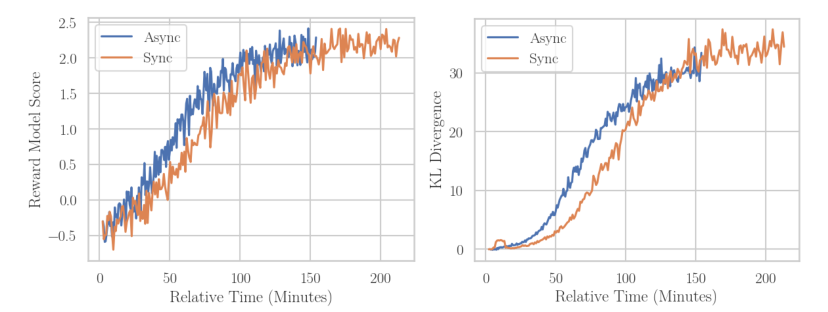
Asynchronous reinforcement learning for human feedback (RLHF) in language models, contrasting it with synchronous approaches, optimizes compute efficiency by separating generation and training on different GPUs. This method, inspired by Cleanba-style, uses libraries like vllm for faster generation, sacrificing some training efficiency but reducing overall runtime. Key findings include the need for off-policy learning in RLHF, robustness of Online DPO to off-policy data, and asynchronous RLHF's superior scaling, achieving 25% faster training with 2.8B models. Demonstrated on a general purpose chatbot, asynchronous RLHF outperforms synchronous approaches by 40% in training speed.




Advanced features