Are LLMs Prescient? A Continuous Evaluation using Daily News as the Oracle
Hui Dai, Ryan Teehan, Mengye Ren·November 13, 2024
Summary
The Daily Oracle is a benchmark for evaluating Large Language Models (LLMs) using daily news. It assesses temporal generalization and forecasting abilities by generating question-answer pairs that challenge LLMs to predict future events. This method addresses limitations of static benchmarks, which can become outdated and lack temporal dynamics. The benchmark enables continuous evaluation and tracks LLM performance over time, highlighting the need for model updates. The text discusses a dataset from Daily Oracle, consisting of 16,082 True/False and 13,906 Multiple Choice QA pairs covering January 1, 2020, to September 30, 2024. The dataset broadly covers different categories, such as Economics & Business, Politics & Governance, Security & Defense, Arts & Recreation, Sports, Environment & Energy, Healthcare & Biology, Science & Tech, Education & Research. The analysis shows a linear relationship between word frequency in past 100 days and its occurrence on the 101st day, replicating findings from Anderson & Schooler's study on human information environments.


Introduction
Background
Overview of Large Language Models (LLMs)
Importance of temporal generalization and forecasting in LLMs
Objective
Purpose of The Daily Oracle benchmark
Addressing limitations of static benchmarks
Continuous evaluation of LLM performance over time
Method
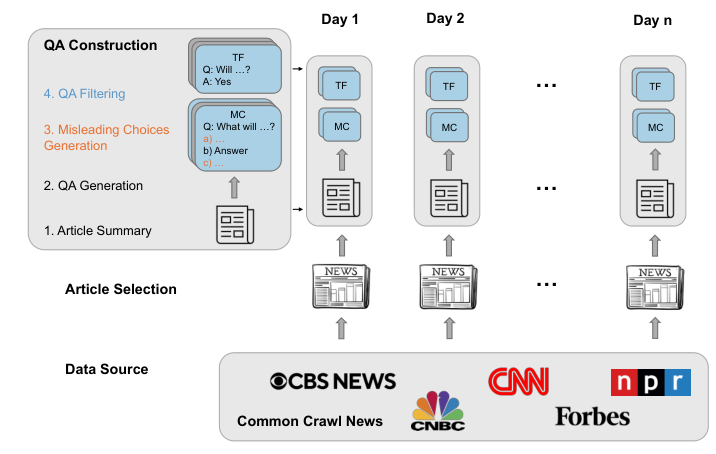
Data Collection
Source of daily news data
Selection criteria for news articles
Data Preprocessing
Data cleaning and formatting
Splitting data into training, validation, and testing sets
Benchmark Design
Question-Answer Pair Generation
Criteria for creating True/False and Multiple Choice QA pairs
Ensuring relevance and temporal dynamics
Evaluation Metrics
Metrics for assessing LLM performance
Comparison with baseline models
Dataset Analysis
Overview of the Dataset
Size and structure of the dataset
Distribution across different categories
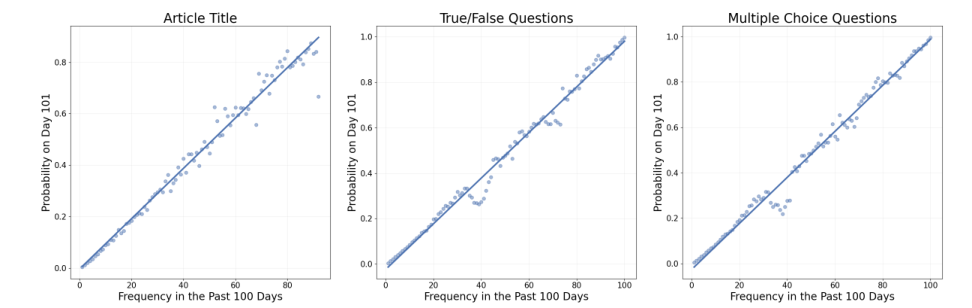
Word Frequency Analysis
Correlation between word frequency in past 100 days and its occurrence on the 101st day
Replication of findings from Anderson & Schooler's study
Results and Findings
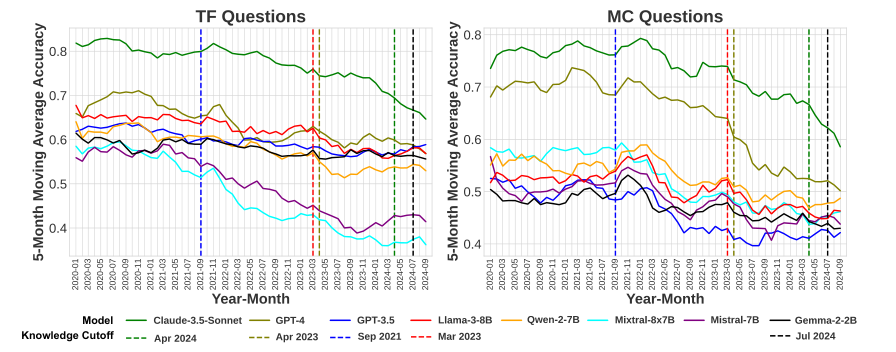
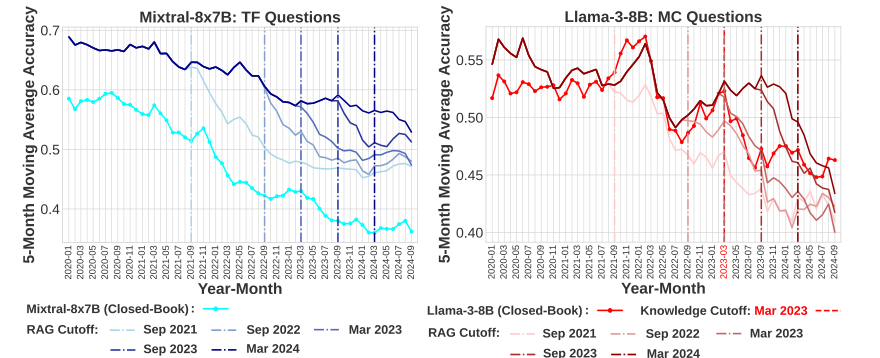
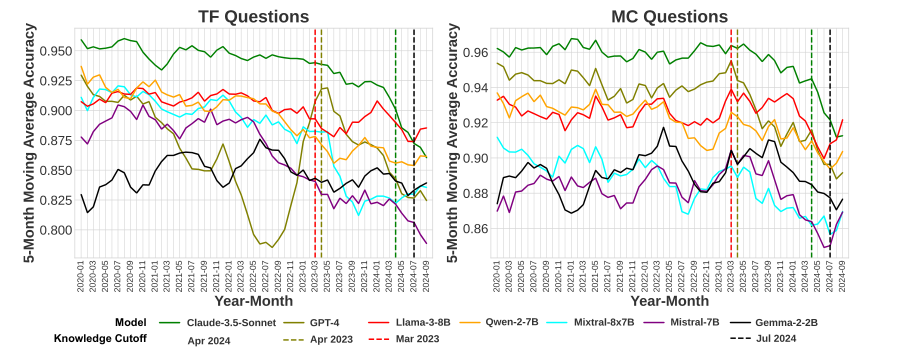
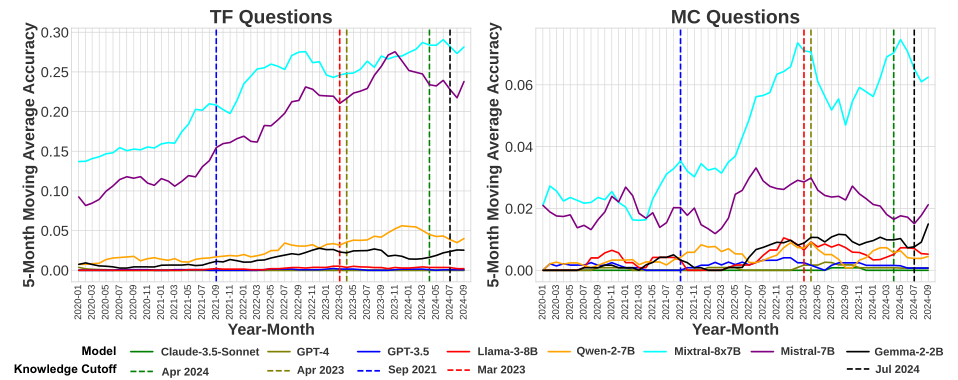
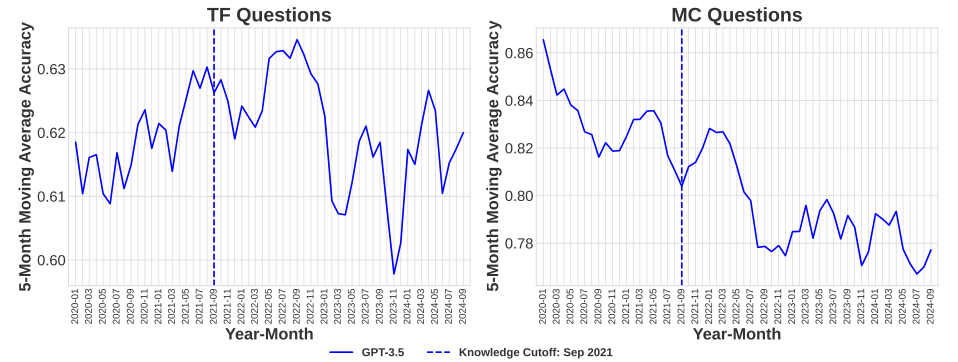
Performance of LLMs
Comparison of different LLM models
Trends in performance over time
Insights into LLM capabilities
Strengths and weaknesses identified
Areas for improvement
Conclusion
Implications for LLM Research
Importance of dynamic benchmarks
Future directions in LLM evaluation
Recommendations for Practitioners
Strategies for model adaptation and improvement
Continuous monitoring and updating of benchmarks
Basic info
papers
computation and language
machine learning
artificial intelligence
Advanced features