Annotation-Efficient Preference Optimization for Language Model Alignment
Yuu Jinnai, Ukyo Honda·May 22, 2024
Summary
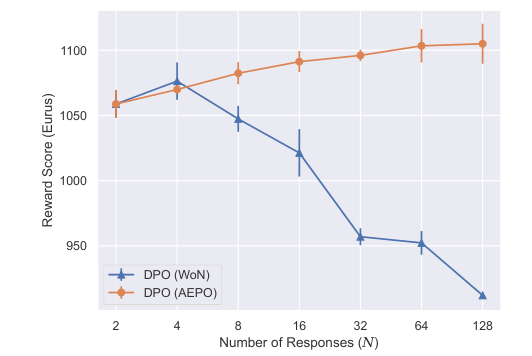
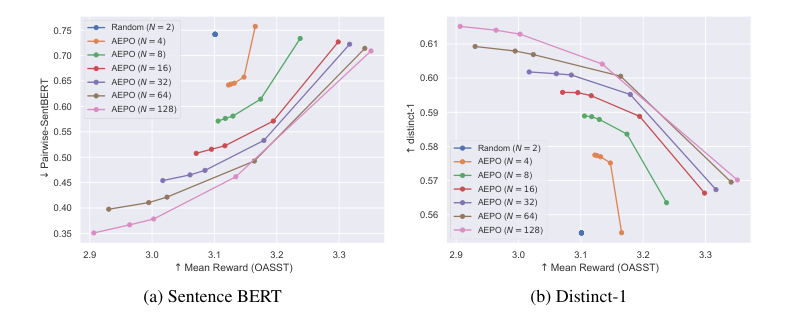
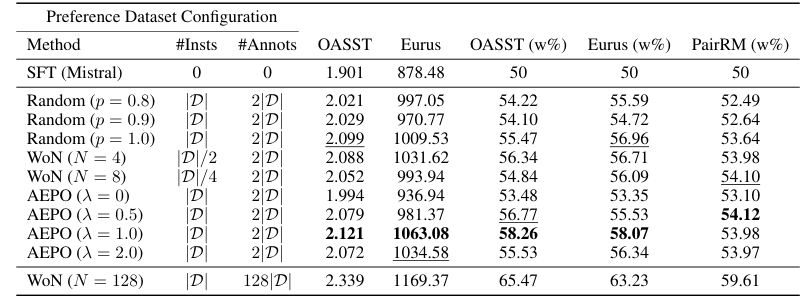
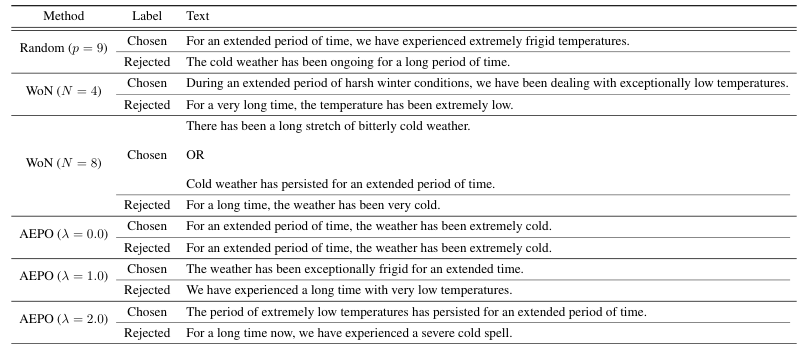
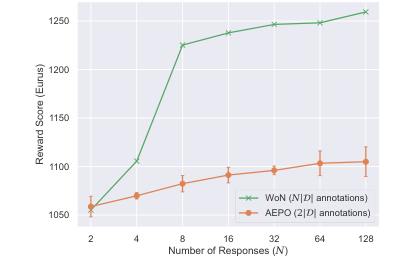
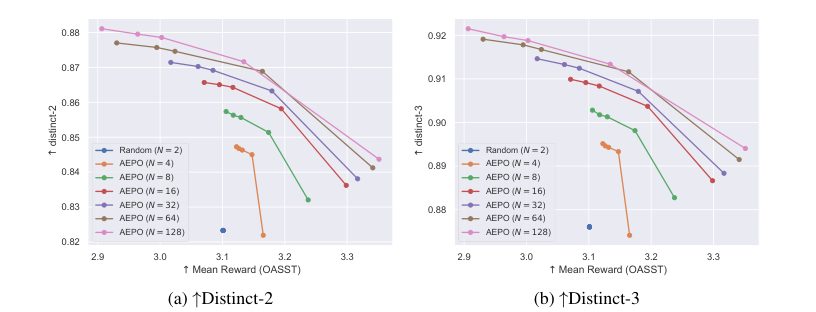
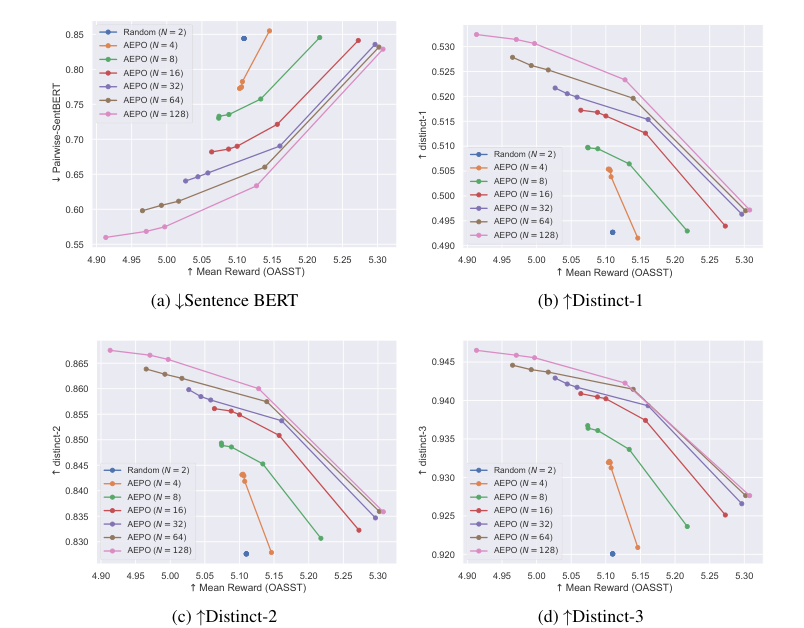
The paper introduces Annotation-Efficient Preference Optimization (AEPO), a method that enhances fine-tuning large language models for better alignment with human preferences. It addresses the issue of high annotation costs by strategically selecting a diverse and high-quality subset of response texts. AEPO, compared to standard methods, improves Direct Preference Optimization (DPO) performance using a limited annotation budget. The paper emphasizes the importance of diverse preferences in model alignment and acknowledges biases in LLMs, advocating for more efficient data collection techniques. Experiments on AlpacaFarm and Anthropic's datasets show AEPO's effectiveness, with better results as the number of responses increases. The study also explores different annotation strategies and highlights the need for diverse and high-quality datasets in preference learning, with AEPO outperforming other methods in terms of performance and efficiency. Future research will focus on optimizing AEPO for different datasets and addressing potential biases and polarized views.








Advanced features