AID: Adapting Image2Video Diffusion Models for Instruction-guided Video Prediction
Zhen Xing, Qi Dai, Zejia Weng, Zuxuan Wu, Yu-Gang Jiang·June 10, 2024
Summary
The paper presents AID, a method for adapting image-to-video models to generate instruction-guided videos. AID addresses limitations of previous techniques by transferring video priors, incorporating an MLLM with a DQFormer for instruction control, and using adapters for efficient adaptation. The model significantly outperforms state-of-the-art on four datasets, demonstrating its effectiveness in tasks like robotic manipulation and VR applications, with improved video prediction and controllability.
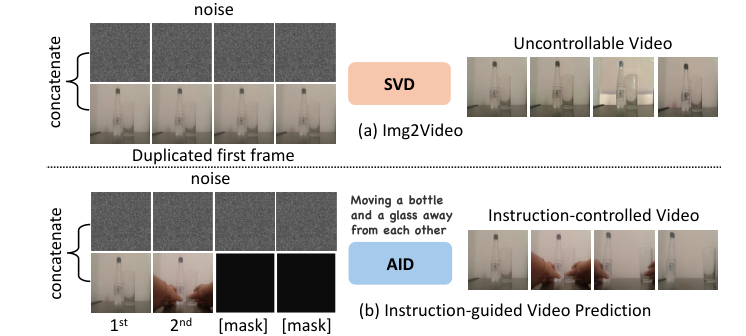
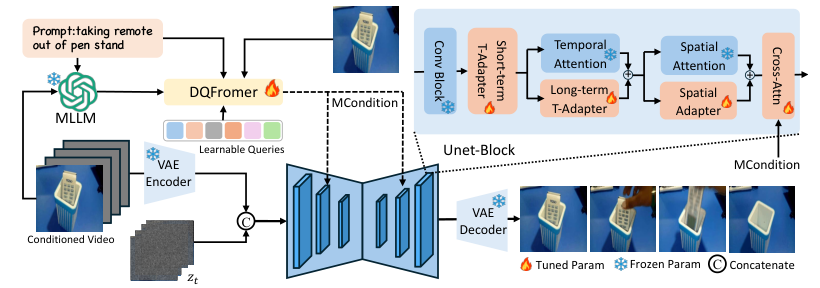

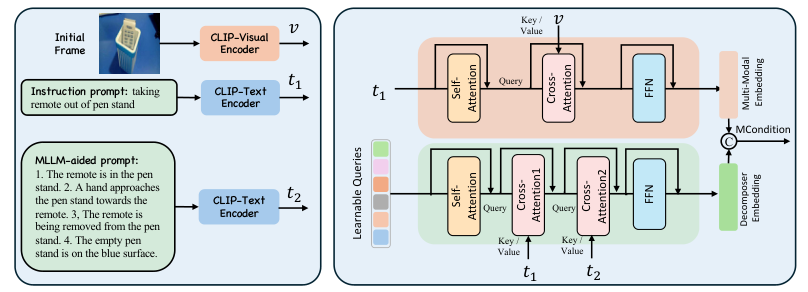









I. Introduction
A. Background on image-to-video generation
B. Limitations of previous methods
C. Purpose of AID: addressing challenges and improving controllability
II. Methodology
A. Video Prior Transfer
1.1. Extracting video style and structure
1.2. Incorporating priors into the adaptation process
B. MLLM with DQFormer for Instruction Control
2.1. Multi-Modal Language Learning Model (MLLM)
2.2. DQFormer: Dynamic Query Generation for Instruction Understanding
2.3. Integration of MLLM and DQFormer for precise control
C. Adapter-based Adaptation
3.1. Adapters for efficient fine-tuning
3.2. Adapter design and training
3.3. Adapting to new tasks and domains
III. Experiments and Results
A. Datasets and Evaluation Metrics
B. Comparison with State-of-the-Art
Robotic Manipulation
Virtual Reality Applications
C. Improved Video Prediction and Controllability
Quantitative Analysis
Qualitative Examples
IV. Applications and Implications
A. Real-world use cases
B. Advantages over previous methods
C. Future directions and potential improvements
V. Conclusion
A. Summary of AID's achievements
B. Significance for the field of video generation
C. Open questions and future research directions
Basic info
papers
computer vision and pattern recognition
computation and language
multimedia
machine learning
artificial intelligence
Advanced features