A Step Towards Mixture of Grader: Statistical Analysis of Existing Automatic Evaluation Metrics
Yun Joon Soh, Jishen Zhao·October 13, 2024
Summary
The paper addresses limitations in automatic QA evaluation metrics, focusing on their correlation with human evaluations. It proposes a Mixture Of Grader (MOG) to classify question types and select appropriate metrics, improving objective grading for varying question types and ambiguous grading rubrics. The MOG aims to enhance evaluation quality by addressing metric limitations. Preliminary results involve using ChatGPT-o1-preview model data to evaluate QA pairs, correlating metrics with model scores. Various metrics are evaluated for AI-generated answers, with the Pedant Score showing the best correlation with human evaluations. The study compares metrics across different answer types, suggesting no single metric fits all, advocating for a classification system to select appropriate evaluation metrics. Future work explores alternative embedding models and additional automatic evaluators.
Introduction
Background
Overview of automatic QA evaluation metrics
Challenges in aligning machine-generated evaluations with human assessments
Objective
Aim of the study: Enhancing the quality of automatic QA evaluations through a Mixture of Grader (MOG) approach
Method
Data Collection
Gathering QA pairs for evaluation
Utilizing ChatGPT-o1-preview model data for preliminary analysis
Data Preprocessing
Cleaning and formatting data for analysis
Preparing data for MOG classification and metric evaluation
MOG Classification
Development and implementation of the Mixture of Grader model
Classification of question types based on characteristics
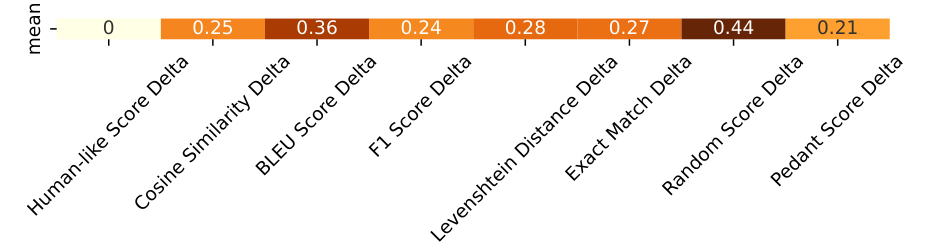
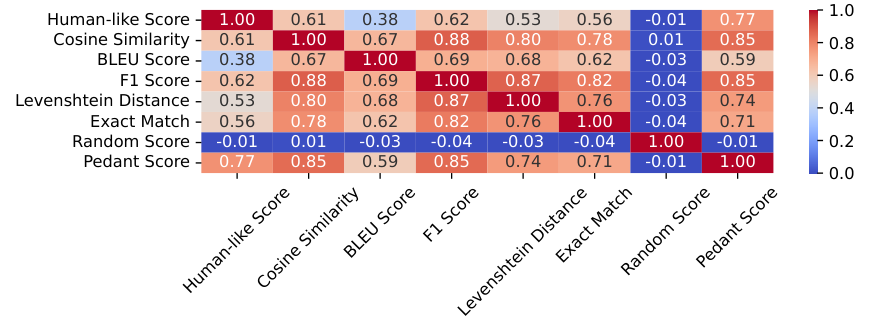
Metric Evaluation
Selection and application of various evaluation metrics
Correlation analysis between metrics and model scores
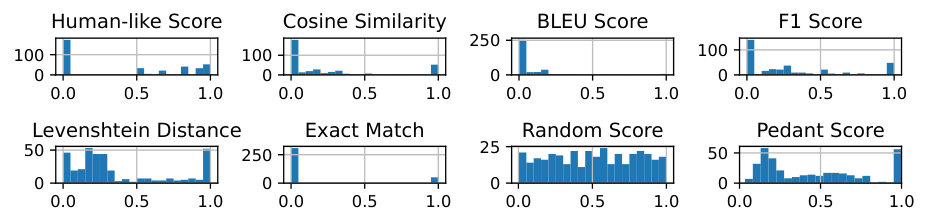
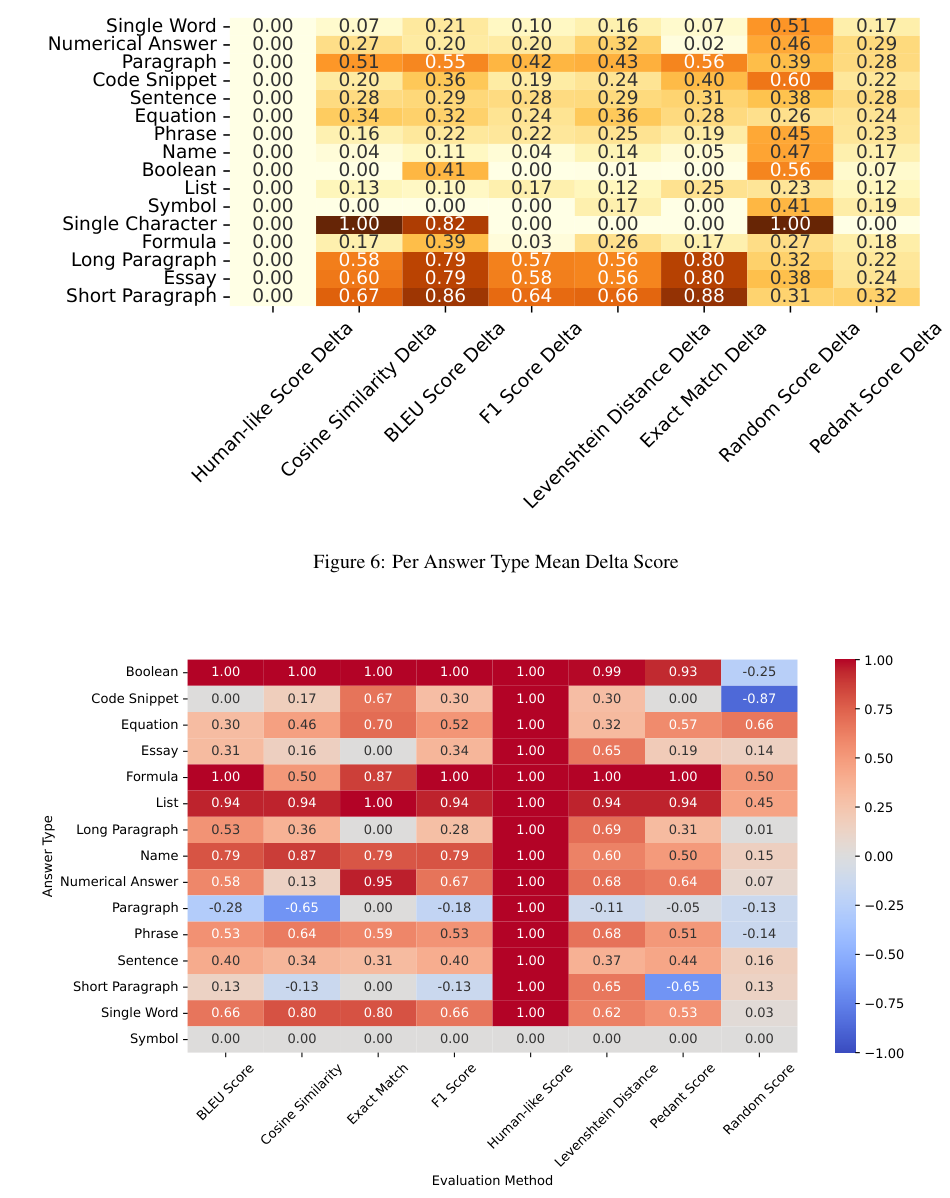
Analysis of Results
Evaluation of metrics for AI-generated answers
Identification of the Pedant Score as the most correlated with human evaluations
Results
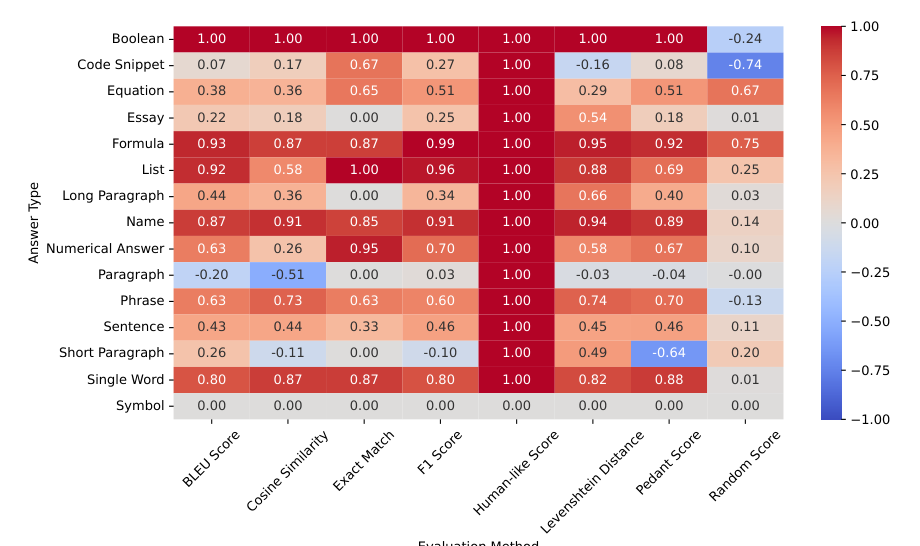
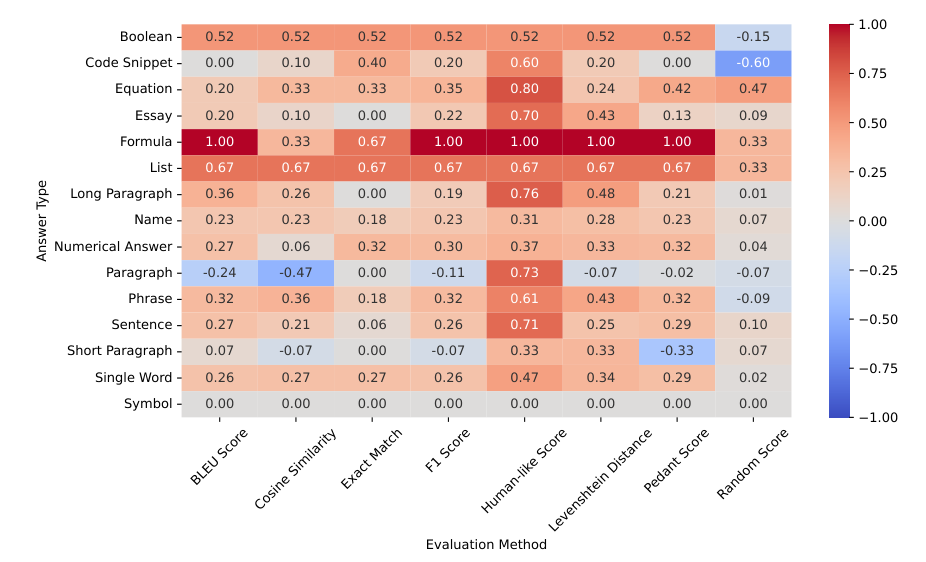
Comparative Analysis
Comparison of metrics across different answer types
Insights into the limitations of single-metric approaches
MOG Performance
Evaluation of MOG in improving objective grading
Correlation between MOG classifications and human evaluations
Discussion
Limitations and Future Directions
Challenges in MOG implementation and scalability
Exploration of alternative embedding models for enhanced performance
Implications for AI Evaluation
Potential improvements in AI-generated answer assessments
Advantages of a classification-based approach in automatic QA evaluation
Conclusion
Summary of Findings
Recap of the study's main contributions
Recommendations for Future Research
Directions for further investigation into automatic evaluators
Considerations for refining MOG and metric selection processes
Basic info
papers
computation and language
artificial intelligence
Advanced features
Insights
What is the main focus of the paper regarding automatic QA evaluation metrics?
How does the proposed Mixture Of Grader (MOG) system improve the objective grading of questions with varying types and ambiguous grading rubrics?
Which metric, among those evaluated, showed the best correlation with human evaluations for AI-generated answers, according to the preliminary results using ChatGPT-o1-preview model data?
What does the study suggest about the suitability of a single metric for evaluating all types of questions, and what alternative approach does it propose?