A Data-Centric Perspective on Evaluating Machine Learning Models for Tabular Data
Andrej Tschalzev, Sascha Marton, Stefan Lüdtke, Christian Bartelt, Heiner Stuckenschmidt·July 02, 2024
Summary
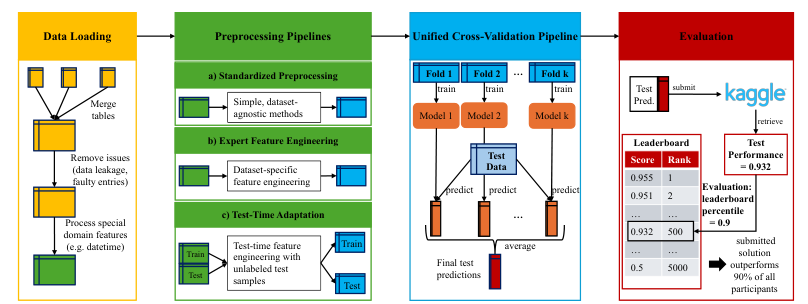
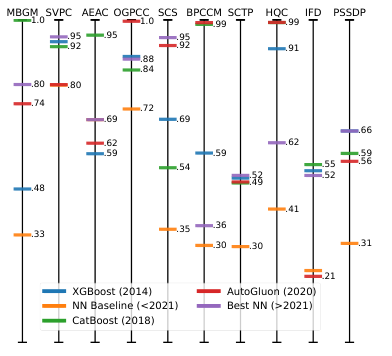
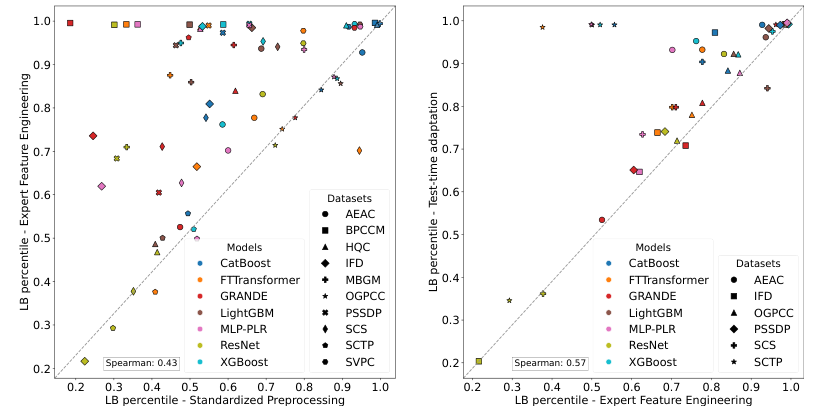
The paper argues that traditional model-centric evaluations of tabular data models are biased due to dataset-specific preprocessing and feature engineering being overlooked. The authors propose a data-centric framework by analyzing 10 Kaggle datasets, implementing expert-level preprocessing, and examining model selection, hyperparameter optimization, and feature engineering. Key findings include:
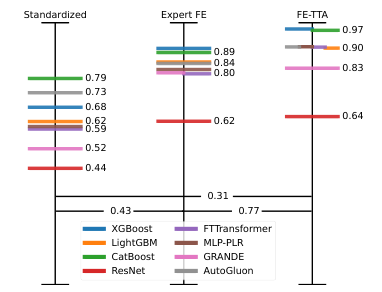
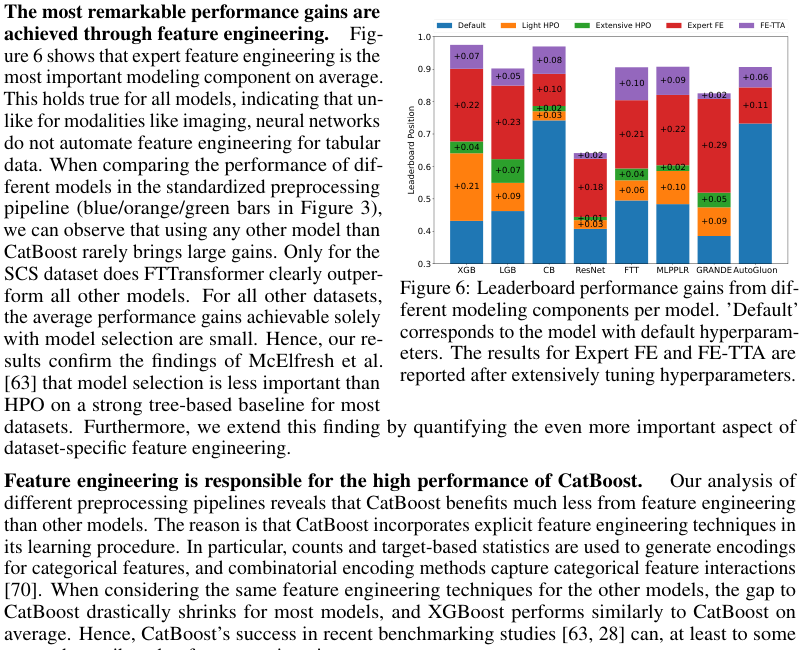
1. Dataset-specific feature engineering significantly impacts model performance.
2. Manual feature engineering remains crucial for modern models, even with recent advancements.
3. Temporal characteristics in static data are not always considered in academic evaluations.
4. The study suggests future research should focus on data-driven approaches to better understand model performance in real-world scenarios.
5. The framework highlights the importance of feature engineering and the need for more data-specific techniques, as well as a shift away from overly relying on leaderboard comparisons.
The paper calls for a more realistic evaluation of tabular data models, acknowledging the practical challenges faced by practitioners, such as temporal data and test-time adaptation. It also emphasizes the need for improved benchmarks that align with real-world tasks and the importance of considering preprocessing and feature engineering in model comparisons.


Advanced features