A Chinese Multi-label Affective Computing Dataset Based on Social Media Network Users
Jingyi Zhou, Senlin Luo, Haofan Chen·November 13, 2024
Summary
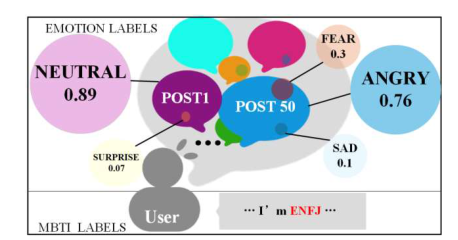
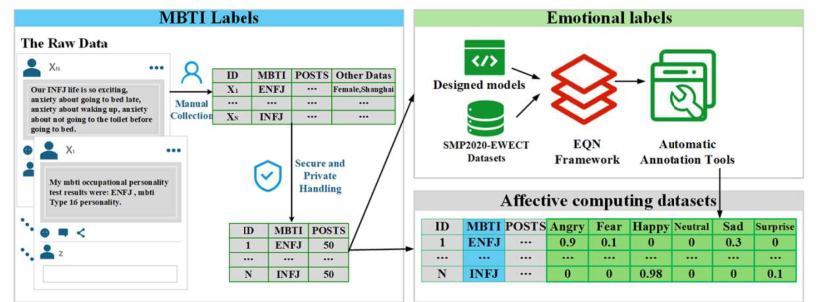
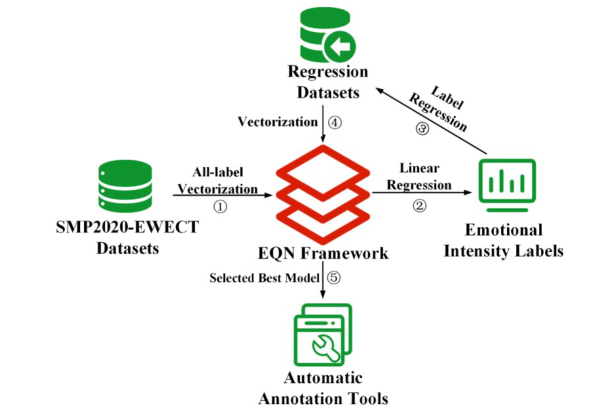
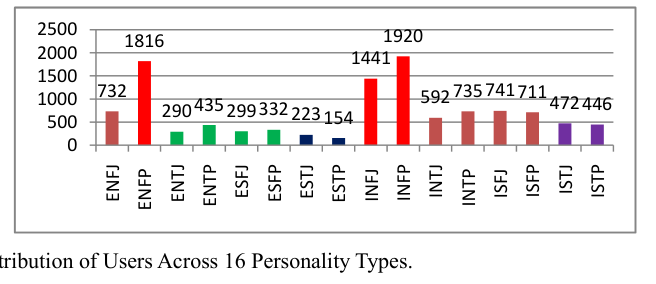
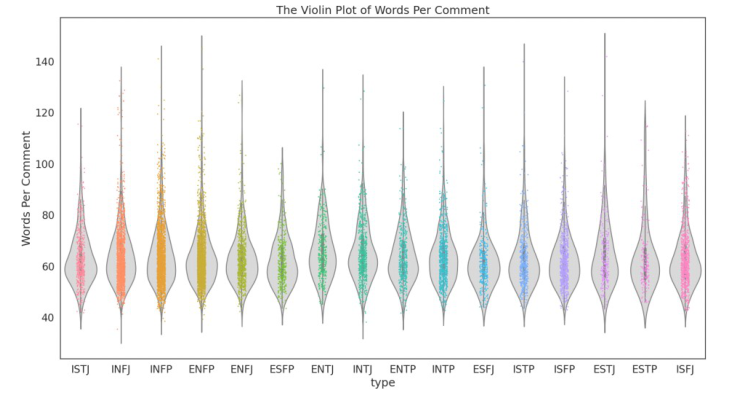
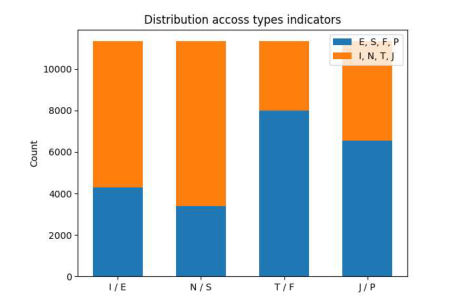
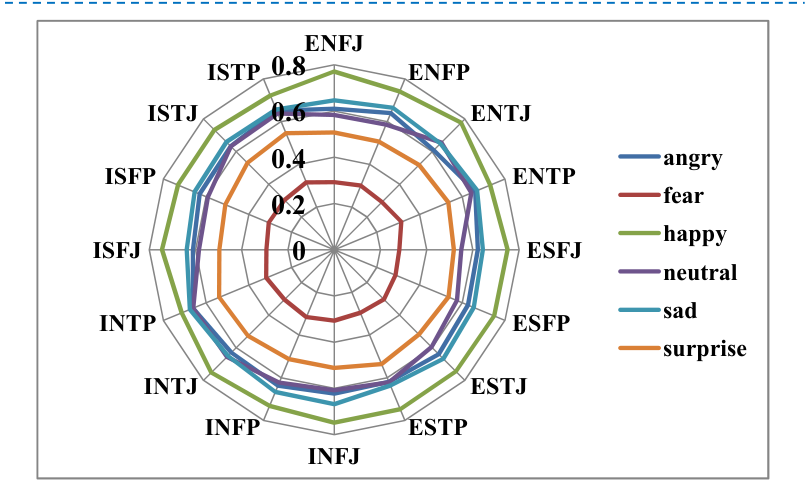
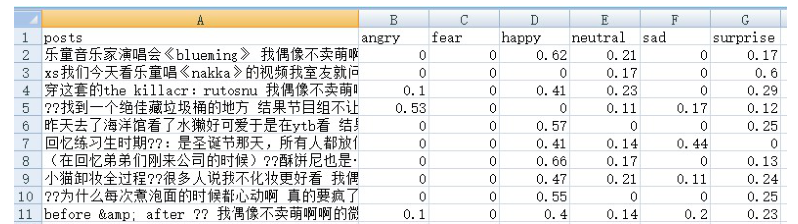
中国开发了一个多标签情感计算数据集,基于微博用户,以填补情绪和个性特征注释的空白。该数据集包含11,338个有效用户,具有多样化的MBTI个性标签和566,900条帖子。它整合了六种情绪和微情绪,每种情绪都使用EQN方法标注了强度级别。这个多标签数据集旨在促进复杂人类情绪的机器识别,对心理学、教育、市场营销、金融和政治研究具有重要意义。跨NLP模型的验证显示其强大的实用性。MuSe 2022挑战引入了幽默和情绪压力维度,增强了情绪模型。ChineseEmoBank提供了精细的情绪强度分析,是第一个具有多级粒度的中文资源。GoEmotions由谷歌推出,具有详细的多类别、多标签数据集,但缺乏强度区分和个性特征。中国多标签情感计算数据集(CMACD)使用微情绪注释框架和连续强度评分,解决了依赖于手动注释的现有情绪数据集的稀缺性、缺乏情绪强度数据、单标签注释、缺乏中文个性特征和罕见的多标签数据集的问题。它是第一种类型的数据集,为基于个性的情感计算提供了重大价值。



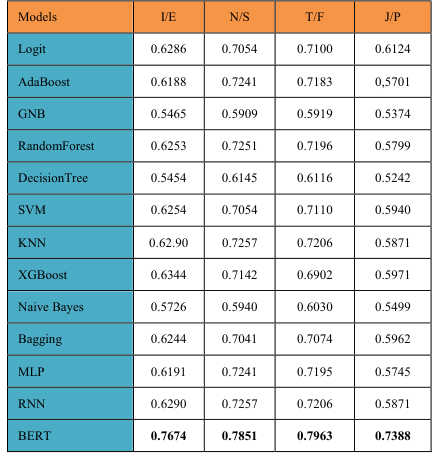
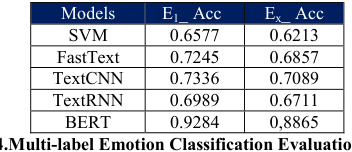
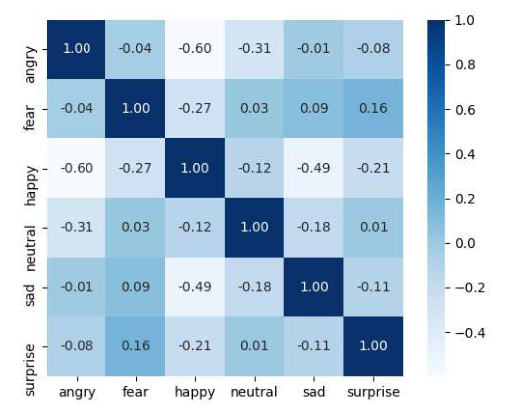
Advanced features