Relations Prediction for Knowledge Graph Completion using Large Language Models

Central Theme
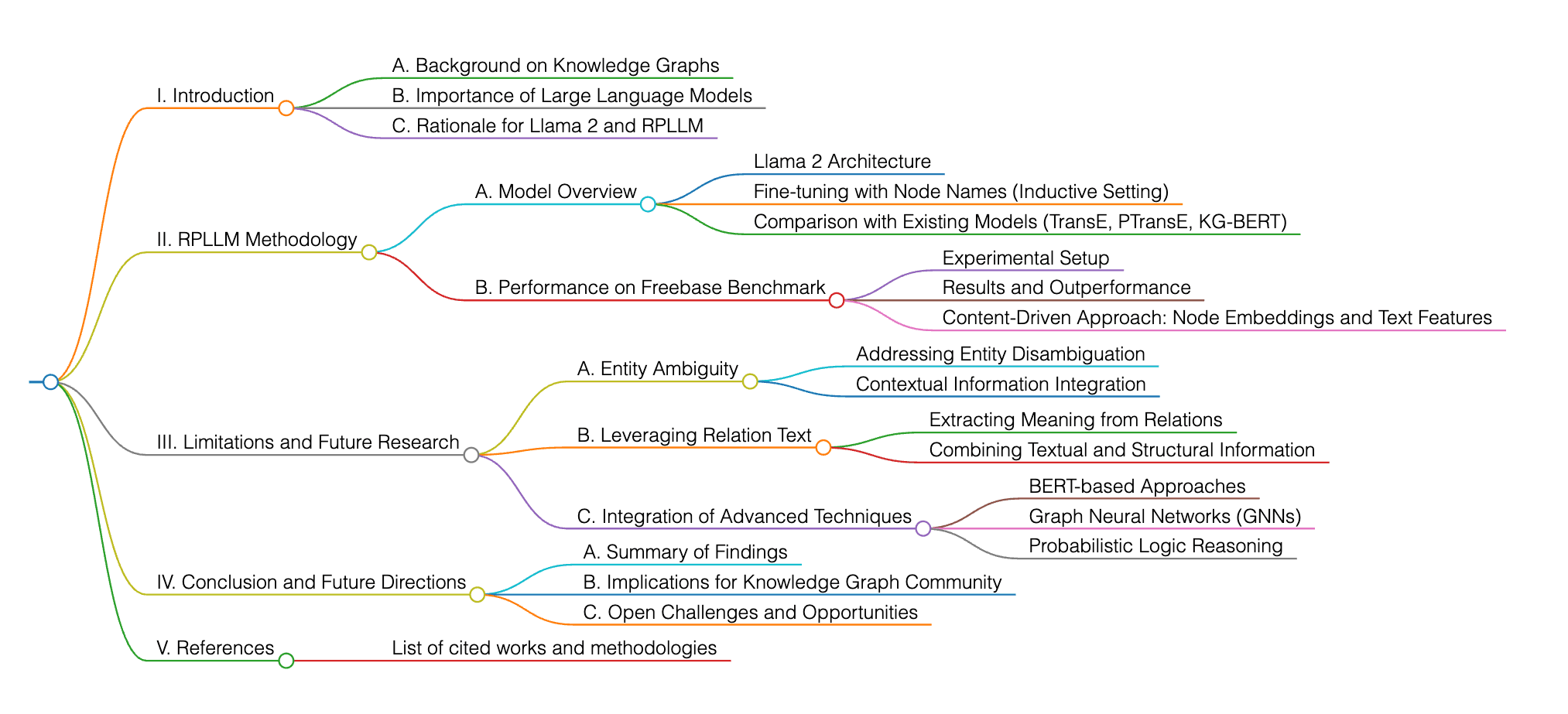
The paper explores the use of large language models, particularly Llama 2, for knowledge graph completion, focusing on relation prediction tasks. It introduces RPLLM, which fine-tunes the model with node names to handle inductive settings and outperforms existing models like TransE, PTransE, and KG-BERT on the Freebase benchmark. The study highlights the potential of content-driven approaches, using node embeddings and text features, for enhancing knowledge graph accuracy. Future work suggests addressing limitations, such as entity ambiguity and the use of relation text, to further improve performance. The field is continually evolving, with research incorporating various techniques like BERT, Graph Neural Networks, and probabilistic logic reasoning.
Mind Map
TL;DR
What problem does the paper attempt to solve? Is this a new problem?
The paper aims to address the entity ambiguity problem in Knowledge Graph Completion (KGC) research. This issue has led to low rankings in model evaluations and affects the performance of current models. While not a new problem, the paper suggests future research directions to explore leveraging relation text in training triples and utilizing entity descriptions to enhance results with minimal computational load.
What scientific hypothesis does this paper seek to validate?
The paper aims to validate the hypothesis that current models, including the one presented, demonstrate state-of-the-art performance in relation prediction tasks, as evidenced by consistently high reported prediction ranks and incremental improvements from new studies.
What new ideas, methods, or models does the paper propose? What are the characteristics and advantages compared to previous methods?
The paper introduces the utilization of Large Language Models (LLMs) for completing knowledge graphs, specifically employing Llama 2 for sequence multi-label classification in relation prediction tasks, achieving new benchmark scores in Freebase and equivalent scores in WordNet. Additionally, it suggests leveraging entity descriptions and relation text in training triples, exploring negative sampling techniques, and introducing new evaluation knowledge graphs for more sophisticated relation prediction scenarios. 'm happy to help with your question. However, I need more specific information or context about the paper you are referring to in order to provide a detailed analysis. Please provide me with the title of the paper, the author, or a brief summary of the content so I can assist you better.
The paper's approach stands out due to its use of LLMs, particularly Llama 2, for text-based relation prediction tasks, showcasing competitive performance in both FreeBase and WordNet knowledge graphs. Compared to previous methods, the model demonstrates state-of-the-art performance with consistently high prediction ranks and minor improvements from new studies. Additionally, the paper suggests leveraging entity descriptions and relation text in training triples, exploring negative sampling techniques, and introducing new evaluation knowledge graphs for more sophisticated relation prediction scenarios.
Do any related researches exist? Who are the noteworthy researchers on this topic in this field?What is the key to the solution mentioned in the paper?
Current research in the field of Knowledge Graph Completion (KGC) has shown significant advancements, with state-of-the-art performance demonstrated by various models. Noteworthy researchers in this area include Alqaaidi and Kochut, among others. he key to the solution mentioned in the paper lies in utilizing entity names as input for the LLM, which involves text tokenization and encoding the tokens into numerical IDs. This approach ensures a straightforward and highly effective implementation of the model, enhancing its performance in relation prediction tasks.
How were the experiments in the paper designed?
The experiments in the paper were designed to evaluate the model's performance on two widely recognized benchmarks, FreeBase and WordNet. The model was fine-tuned using the Llama 2 model pre-trained with 7 billion parameters for the relation prediction task. The experimental setup involved utilizing negative sampling in the LP task to enhance training data diversity, but negative sampling was not incorporated into the RP task due to fundamental differences in label assignment methodology. Additionally, the Llama 2 tokenizer was used with a padding length of 50 for the entities' text sequences, and the model was fine-tuned using the Adam optimization algorithm with a learning rate of 5e-5.
What is the dataset used for quantitative evaluation? Is the code open source?
The dataset used for quantitative evaluation includes FreeBase and WordNet. The code for the model is not explicitly mentioned to be open source in the provided contexts.
Do the experiments and results in the paper provide good support for the scientific hypotheses that need to be verified? Please analyze.
The experiments and results presented in the paper offer substantial support for the scientific hypotheses that require verification. The study demonstrates the effectiveness of the model through evaluations on well-established benchmarks, FreeBase and WordNet, showcasing the model's performance and capabilities. The results indicate state-of-the-art performance and improvements in relation prediction tasks, validating the hypotheses put forth in the research. o provide an accurate analysis, I would need more specific information about the paper, such as the title, authors, research question, methodology, and key findings. This information will help me assess the quality of the experiments and results in relation to the scientific hypotheses being tested. Feel free to provide more details so I can assist you further.
What are the contributions of this paper?
The paper makes significant contributions by showcasing state-of-the-art performance in prediction ranks and suggesting potential research directions for entity prediction tasks. Additionally, it introduces the application of negative sampling techniques for the RP task, which could enhance model performance.
What work can be continued in depth?
Future research in the field of Knowledge Graph Completion (KGC) could focus on addressing the entity ambiguity problem, as highlighted in the study. This issue led to lower rankings in the model's evaluation, indicating a potential area for improvement. Researchers could explore leveraging relation text in training triples and utilizing entity descriptions to enhance results with minimal additional computational load. Additionally, introducing new evaluation scenarios in knowledge graphs could enrich the literature and advance relation prediction techniques.
Know More
The summary above was automatically generated by Powerdrill.
Click the link to view the summary page and other recommended papers.