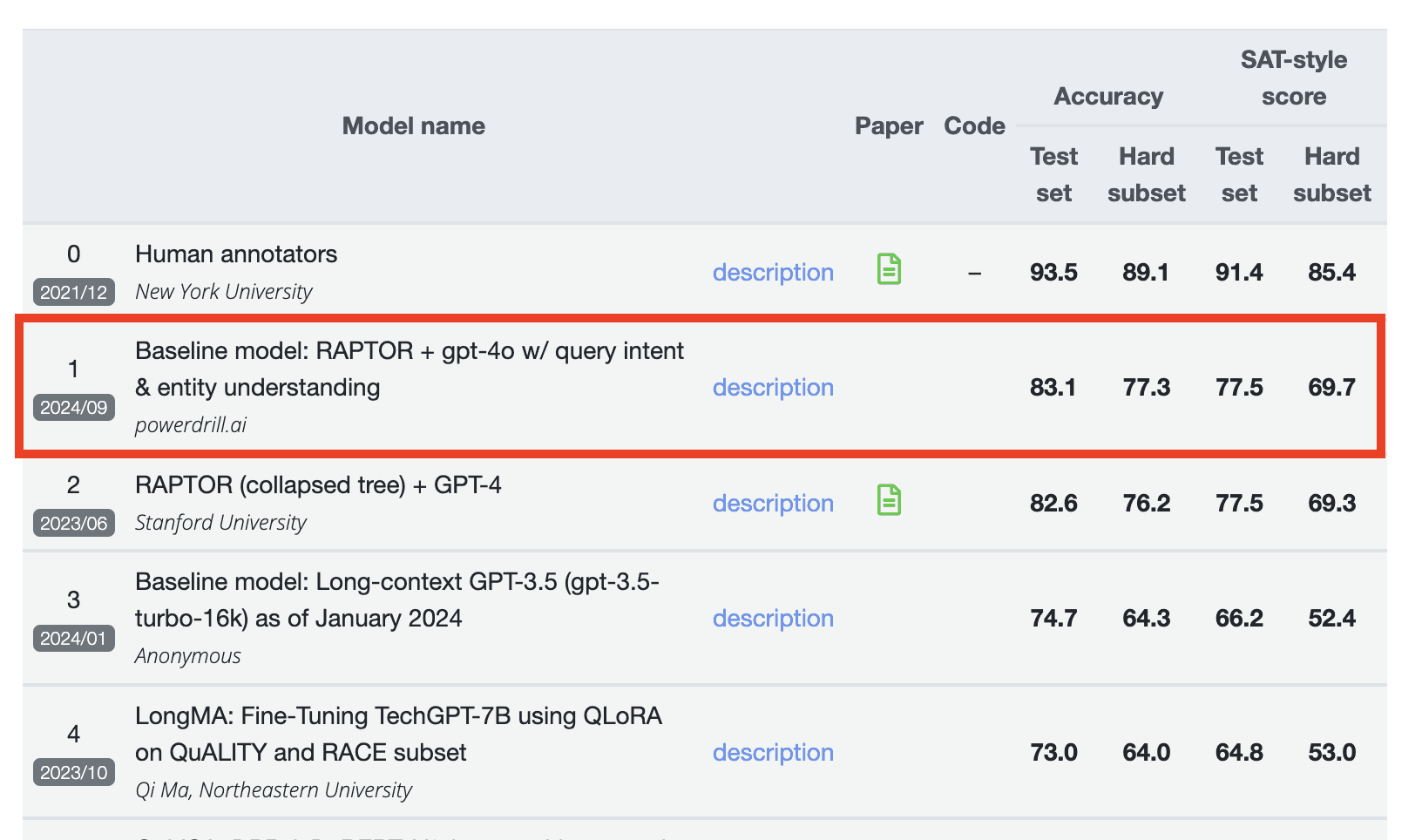
Powerdrill AI Ranks #1 spot on the QuALITY Benchmark

We are excited to announce that Powerdrill AI has ranked #1 on the QuALITY benchmark leaderboard (last updated: September 2024). In terms of accuracy, it scored 83.1 on the test set and 77.3 on the hard subset. For the SAT-style score, it achieved 77.5 on the test set and 69.7 on the hard subset. Check out the leaderboard for more details: https://nyu-mll.github.io/quality
What is QuALITY?
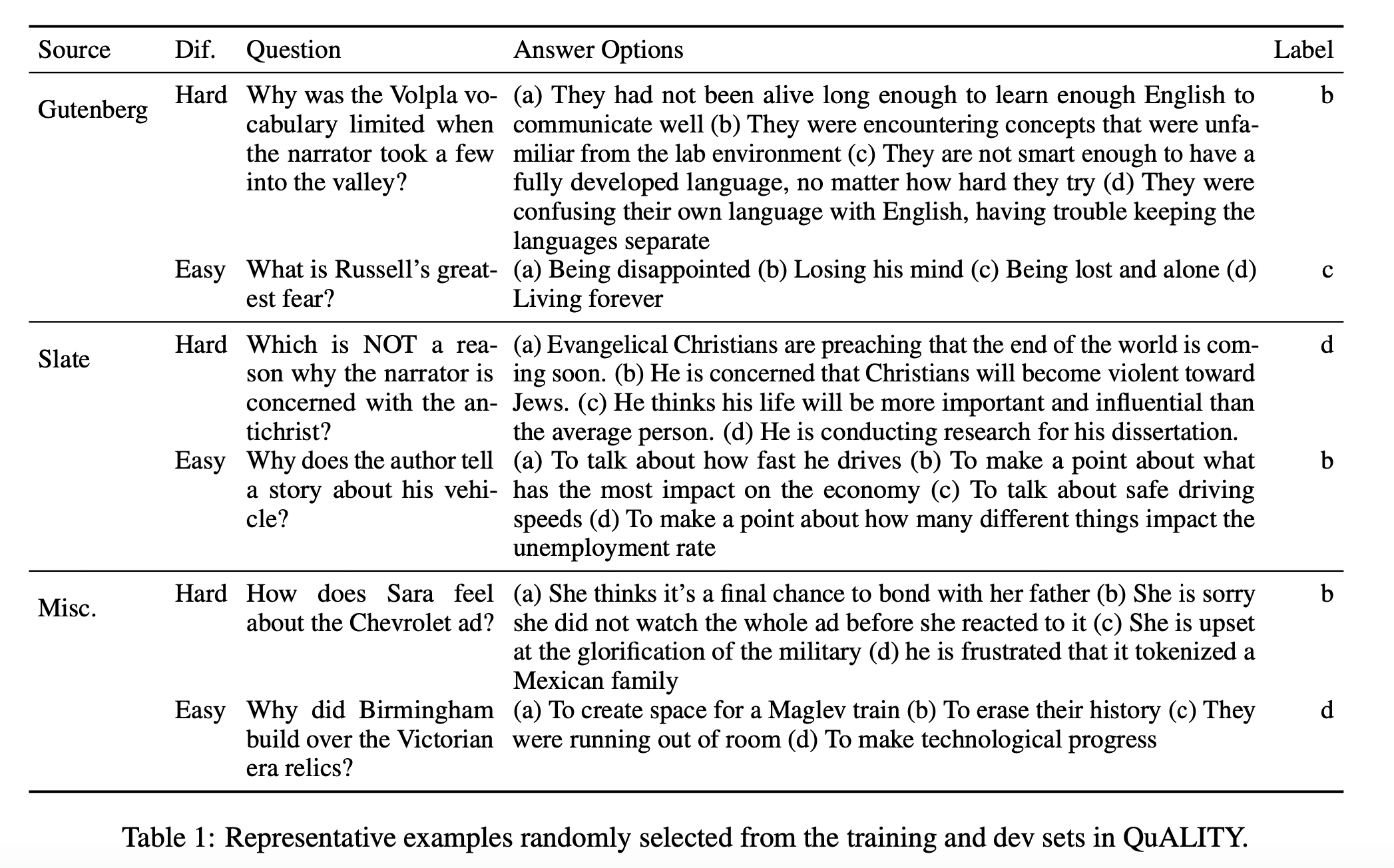
QuALITY (Question Answering with Long Input Texts) is a dataset designed to test models on long-document comprehension, especially when dealing with contexts much longer than what current models can typically handle. The dataset contains passages in English with an average length of about 5,000 tokens. Unlike some other datasets where questions are created based on summaries or excerpts, QuALITY's questions are written and validated by contributors who have read the entire passage.
One key feature of QuALITY is that only half of the questions are answerable by annotators working under time constraints, which indicates that skimming or simple keyword search is insufficient to consistently perform well. This makes the dataset particularly challenging and aims to promote the development of models that can engage in deep comprehension rather than just shallow extraction.
Baseline models perform poorly on this task, with accuracies around 55.4%, far behind human performance at 93.5%. The dataset also includes a "hard subset" (QuALITY-HARD), composed of questions that are particularly challenging.
Evaluation criteria for the QuALITY list

Rankings are determined by evaluating accuracy across the entire test set. This means that a participant's position in the ranking is based on how accurately they answer all the questions, without focusing on just a subset of them.
Accuracy, in this context, is calculated by dividing the total number of correct answers by the total number of examples in the test set. This gives a straightforward measure of how well someone performed overall.
The SAT-style score is a bit more nuanced. It starts with the number of correct answers a participant provides. However, to discourage random guessing, the formula deducts one-third of a point for every incorrect answer. This penalty helps ensure that participants are more thoughtful in their responses. On the other hand, answers that are abstained from—meaning the participant chose not to answer—do not affect the score, as they are given a weight of zero. Finally, the adjusted score is divided by the total number of examples to normalize the result and provide a final score that reflects the participant's overall performance.
In the final QuALITY list, the score ranking is determined by two main components: Accuracy and SAT-style scores. Each of these components is evaluated using both the Test set and the Hard subset. It's important to highlight that Powerdrill AI excelled in every aspect, surpassing models from Stanford University, Northeastern University, and others, achieving the highest score in each part of the evaluation. For reference, a score of 0 represents the benchmark value. This outstanding performance by Powerdrill AI underscores its superior capabilities in handling the tasks set forth in the QuALITY evaluation.
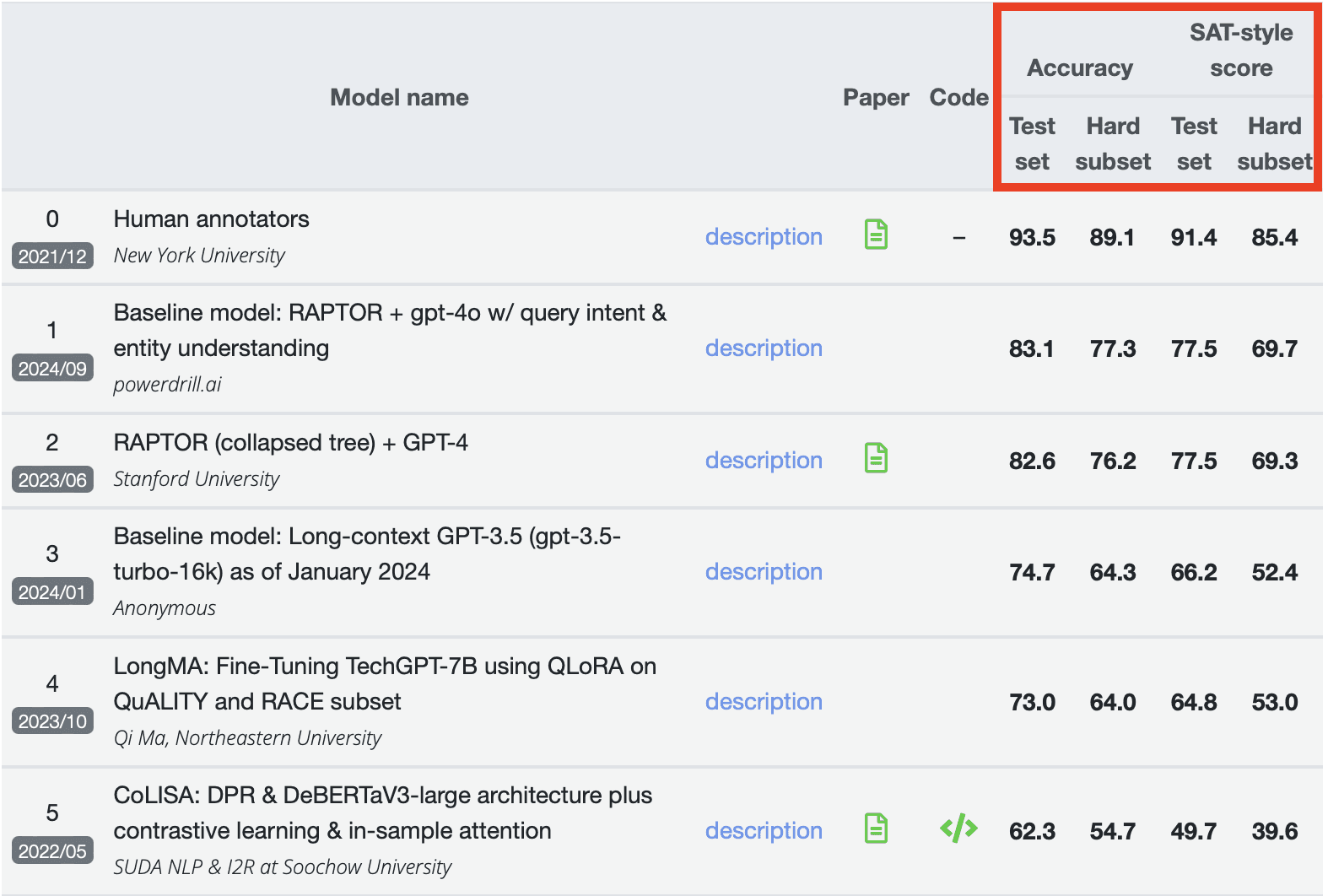
The test set is a portion of the dataset that is set aside for evaluating the performance of a model after training. It typically contains examples that the model has not seen during training or validation. The goal is to measure how well the model generalizes to new, unseen data. Performance metrics such as accuracy, precision, recall, and others are calculated based on the model's performance on this test set.
The hard subset is a portion of the test set that consists of particularly challenging or difficult examples for the model to handle. These might be cases where the distinctions between classes are subtle, where the data is noisier, or where the model historically struggles. The performance on the hard subset is often analyzed separately to understand how the model performs under more difficult conditions and to identify specific areas where the model needs improvement.
Why Powerdrill AI ranks first
Powerdrill AI is a sophisticated system designed to efficiently handle complex queries. It excels at breaking down user inputs and optimizing the retrieval process through advanced algorithms, ensuring accurate and relevant information is delivered quickly. This system adapts to various contexts, providing a seamless and effective user experience.
RAPTOR is an innovative tree-based retrieval system that enhances the parametric knowledge of large language models by incorporating contextual information at multiple levels of abstraction. It employs recursive clustering and summarization techniques to build a hierarchical tree structure that synthesizes information across various sections of the retrieval corpora. Starting from the bottom up, RAPTOR clusters chunks of text and generates summaries, creating a multi-layered tree where leaf nodes contain the original text and upper nodes represent summarized information.
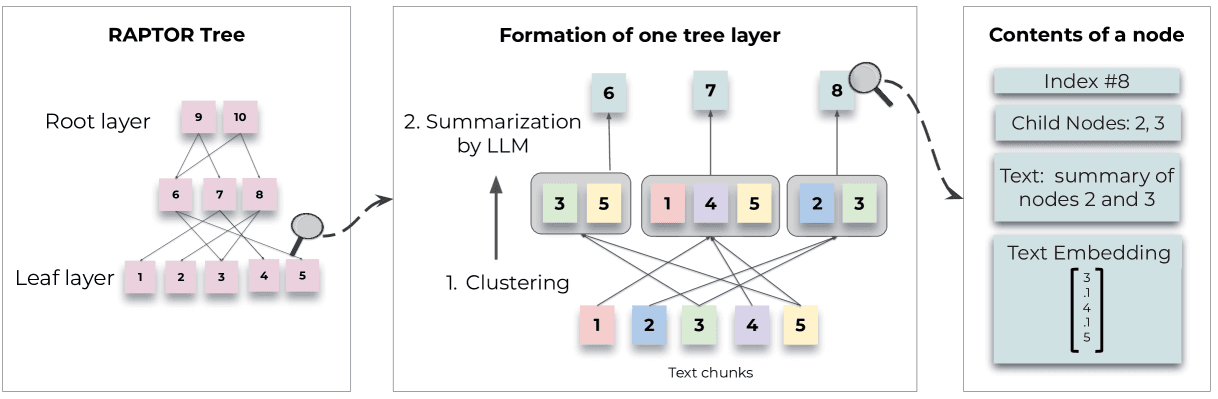
Powerdrill AI leverages RAPTOR indexing to retrieve more refined chunks, thereby enhancing reasoning and response in retrieval-augmented generation (RAG) tasks.Powerdrill AI first breaks down user queries into a multi-hop plan,this decomposition allows the system to tackle complex queries in a step-by-step manner, ensuring that each step is handled with precision.
For each step in the multi-hop plan, key entities are extracted from the query. These entities are critical as they help in matching the query with the most relevant information from the database or document, improving accuracy in retrieving the needed data.
To further optimize the process, Powerdrill AI implements a rerank model. This model filters out unnecessary chunks of information that are not essential to answering the query. By eliminating these irrelevant pieces, the system avoids processing overly long contexts, which not only reduces costs but also enhances system performance by lowering latency.
Overall, Powerdrill AI is focused on delivering accurate and efficient query processing by carefully managing the query decomposition, entity extraction, and data retrieval processes.
Future steps of Powerdrill AI
Powerdrill AI’s recent achievement of claiming the #1 spot on the QuALITY benchmark for Question Answering with Long Input Texts is a pivotal moment for the platform. This recognition underscores Powerdrill AI's unmatched precision in understanding and responding to complex user queries, especially when dealing with long and intricate input texts. The QuALITY benchmark, known for its challenging test cases, evaluates models on their ability to comprehend extended passages and answer questions accurately—a feat that requires advanced comprehension and sophisticated processing capabilities. By outperforming competitors in this space, Powerdrill AI has demonstrated its superior ability to handle real-world data scenarios, further solidifying its position as a leader in AI-powered query interpretation.
This milestone not only validates the effectiveness of the strategies and technologies underlying Powerdrill AI but also paves the way for its future development. With this achievement, Powerdrill AI is well-positioned to expand its capabilities, refining its models to handle even more complex tasks with greater efficiency. Looking ahead, the focus will likely shift towards further optimizing latency, reducing costs, and enhancing the system's ability to process even longer and more detailed input texts. This success will drive ongoing innovation, allowing Powerdrill AI to continue leading in the AI-driven query processing industry while expanding its applications across various domains.
Try it now:/