
引言
AI 领域发展得非常快。一周前你还在高度依赖 ChatGPT;下一周你可能就想测试 Claude 更强的编码能力,或者转向像 OpenClaw 或 Hermes Agent 这样的专用智能体。
为了更好的任务分工、团队偏好或能力差异而切换工具很常见。然而,用户很快会意识到,真正的挑战并不是切换工具——而是保持工作流的连续性。
当你切换到一个新的智能体时,你其实就像走进一间空办公室。你的文件、笔记、项目上下文、重复性指令和部分交付成果都被困在旧工具里。如果你想在切换 AI 智能体时不必从头开始,就需要一套可移植的 AI 记忆策略。
在本指南中,我们将探讨为什么迁移 AI 工作流在结构上如此困难,为什么常见的迁移捷径会失效,以及如何使用持久记忆层来确保跨智能体上下文共享。
快速答案:如何在不丢失上下文的情况下将您的 AI 工作流迁移到新代理
要在不丢失上下文、记忆或先前工作的情况下将您的 AI 工作流迁移到新智能体,你需要将记忆与聊天界面解耦。请遵循以下核心步骤:
采用可移植的记忆层(例如 MemoryLake),为你的 AI 系统充当持久的“第二大脑”。
通过将你的文件、笔记和先前结论上传到这个独立层,而不是直接放进单一智能体中,来集中管理文档和数据。
通过 API、插件或 MCP(模型上下文协议)将新的 AI 智能体连接到这个记忆层。
配置你的新智能体以拉取已有的项目记忆,确保工作流连续性,而无需从头开始或重新上传文件。
为什么迁移 AI 工作流比听起来更难
当你把 AI 工作流迁移到另一个代理时,你不只是更换输入文字的界面。你是在试图移动一张复杂、相互关联的上下文网络。AI 工具天然会形成信息孤岛;你使用得越多,它们积累的上下文就越多。
切换 AI 智能体时通常会丢失什么
如果你只是打开一个新标签页并开始向新智能体输入内容,那么你工作的几个关键组成部分就会被遗留在后面:
已上传文件:你花了数小时上传并解释的 PDF、电子表格和 Word 文档。
笔记和先前结论:前一个智能体生成的战略决策、摘要和综合研究结果。
随着时间积累的上下文:AI 在数十次交互中学到的对你的项目目标、语气和约束的细致理解。
工作流连续性:多日项目中持续推进的、逐步展开的逻辑。
先前指令:重复性规则、格式偏好和项目级记忆。
为什么常见的迁移捷径会失效
大多数用户会试图通过手动变通办法硬生生完成代理切换。遗憾的是,这些方法很少能真正保留实际的工作流连续性。
复制粘贴:把长串文本从一个智能体复制到另一个智能体,会产生杂乱、token 密集的提示词,反而让新模型困惑。
聊天导出:导出聊天历史只会得到一个静态文本文件,而不是一个可搜索、具备文档感知能力的记忆系统。
重新上传文档:手动重新上传每个文件既浪费时间,又会完全抹去前一个智能体已经从这些文件中得出的历史洞见。
提示词填充:试图把项目背景全部塞进一个“超级提示词”里,往往会超过上下文窗口,并导致模型性能下降。
更好的工作流迁移方案是什么样
迁移 AI 工作流的目标不仅仅是移动聊天记录。目标是在一个可移植层中保留可复用的上下文、文档、笔记和先前工作。
你不应把 AI 智能体同时当作处理器(大脑)和存储(记忆)来使用,而是需要把两者分开。通过为 AI 工作流引入持久的记忆层,你就创建了一个“记忆护照”。这使你可以将任何新的智能体接入你现有的知识中枢。
这就是 MemoryLake 这类基础设施发挥作用的地方。MemoryLake 的设计目标是成为 AI 系统的持久记忆层。它不仅仅是一个聊天历史导出器;它是一个跨工具、模型、会话和智能体的可移植记忆层。通过充当具备文档感知和工作流感知能力的记忆基础设施,它帮助用户在不同智能体之间切换,而无需从零开始。
分步指南:使用 MemoryLake 将您的工作流迁移到新代理
如果你想在不丢失先前工作的情况下将 AI 工作流迁移到另一个智能体,下面是一个使用 MemoryLake 的实用迁移流程。
第 1 步:创建项目并集中管理您的文件和数据
实现可移植 AI 记忆的第一步,是把原始资料从旧智能体中移到持久层中。
创建新项目 in MemoryLake。
点击附件按钮上传你的核心文档。该平台支持多种格式,包括 PDF、Word、Excel 和 Markdown。
MemoryLake 会自动分析并索引内容,将其转换为可复用的记忆。
你也可以在文件部分直接连接外部数据源。
迁移价值:只要在持久层中完成这一步,你就能让文档上下文保持可移植。每次切换 AI 工具时,你都无需反复重新上传文件。
第 2 步:测试搜索和对话能力
在迁移到新的外部智能体之前,请先确认你的上下文已经成功保留。
打开 MemoryLake Playground。
直接针对你的项目记忆提问,确保系统能够准确检索你的笔记、先前工作和文档洞见。
迁移价值:这可以确保你的先前工作真正可用且可搜索,并在你连接新工具之前就保障工作流连续性。
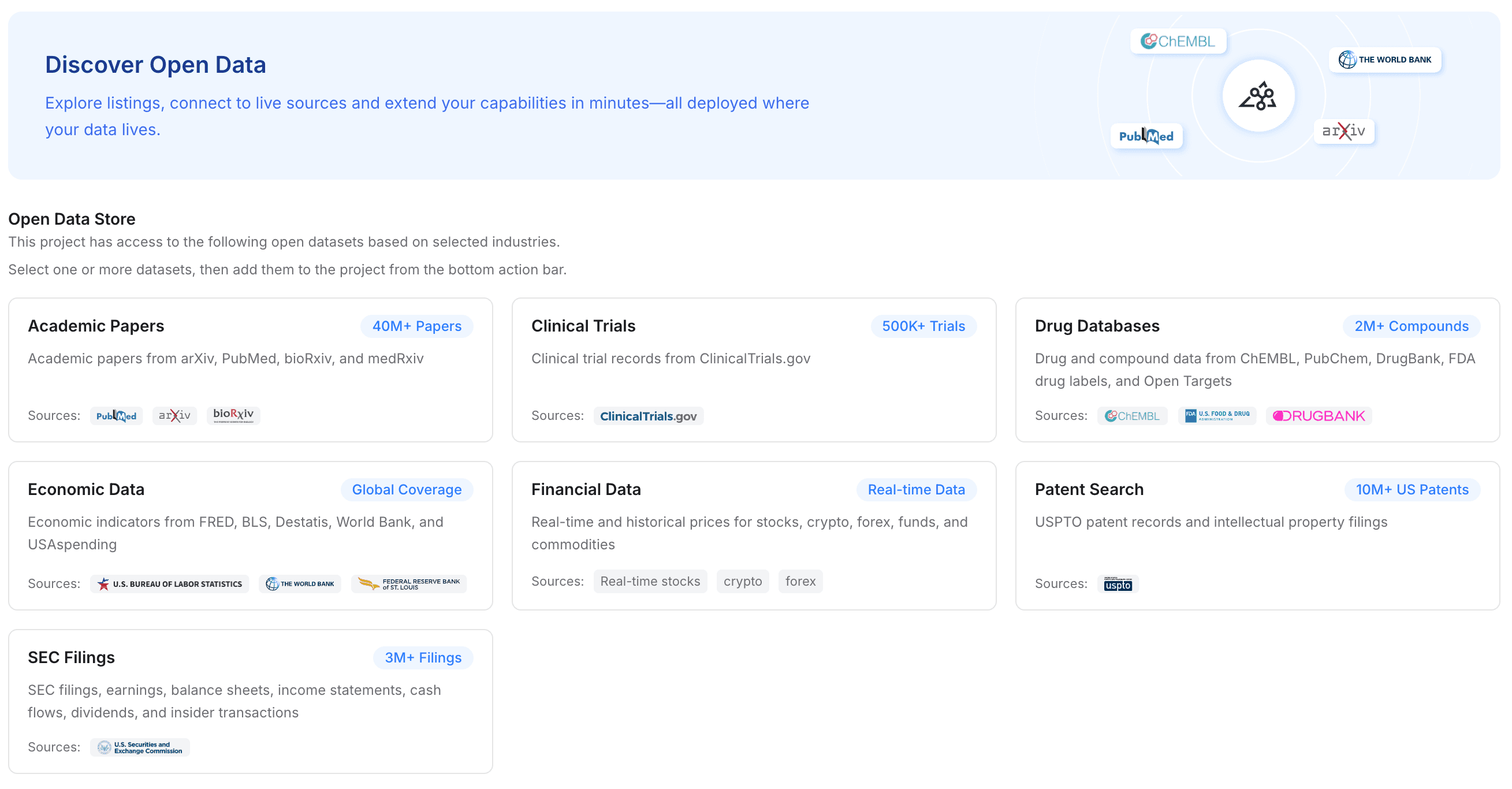
第 3 步:添加开放行业数据以增强您的项目
通常,在切换到新智能体时,你希望它表现得比上一个更好。MemoryLake 允许你将个人上下文与更广泛的行业知识相结合。
点击将“开放数据”添加到你的项目中。
从免费的可用行业数据集中选择,以立即增强你项目的领域知识。
根据你选择的行业,公开文档会强调可访问的数据集,包括学术论文、临床试验、药物数据库、经济数据、金融数据、专利检索和 SEC 申报文件。
迁移价值:这能让你的新智能体更快变得有用。你不必花几个小时教新模型行业标准,而是直接把高度结构化、领域专用的记忆注入工作流。
第 4 步:将 MemoryLake 连接到您的工具和工作流
最后一步是将这个持久记忆层连接到你的新 AI 智能体。
进入 API 设置,并选择或创建你自己的 API 密钥。
用于自动化配置:根据文档化的设置流程,你通常可以使用自动化设置命令。例如,如果你正在迁移到 OpenClaw,你可以复制集成指南并直接粘贴到 OpenClaw 中。该智能体会自动安装所需插件,完成配置,并重启其网关。
用于其他工具:MemoryLake 支持通过插件或一键安装与 ChatGPT、Claude、OpenClaw、Hermes Agent 以及其他工具集成(通常只需运行一个命令)。
用于自定义工作流:你也可以通过 API 或 MCP 风格(模型上下文协议)连接实现程序化集成。
迁移价值:这就是你实现跨智能体记忆的方式。你的新代理会立即访问与旧智能体完全相同的文件、笔记和上下文。你无需重建提示词,并将工作流重置降至零。
迁移 AI 工作流时应避免的常见错误
把聊天记录当作记忆:下载你的 ChatGPT 历史记录的
.txt文件并上传到 Claude,效果不会太好。无结构的聊天日志会稀释上下文。你需要的是结构化、具备文档感知能力的记忆系统。按工具逐个迁移:如果你把自定义指令设置在 Claude 内部,那么这些指令就被困在 Claude 里。应把系统提示词、重复性规则和关键项目上下文保留在一个工具无关的层中。
忽视数据安全:迁移数据时,请确保你使用的记忆层符合你的隐私和合规要求,尤其是在处理法律或金融文档时。
这种迁移方式最适合谁
对于任何以文档为主或以连续性为主的 AI 工作流,采用可复用的记忆层都非常值得推荐。此方法尤其适用于:
研究人员和分析师:他们需要在不同推理模型之间持续访问数十篇学术论文或财务报告。
创始人和产品团队:他们使用不同的专用 AI 智能体迭代产品规格、市场研究和代码库。
金融、法律、生物技术和咨询领域的专业人士:在这些场景中,丢失细微的项目上下文或先前的分析结论可能会破坏整个工作流。
结论
依赖单一 AI 智能体完成所有事情的时代正在结束。随着任务变得越来越专门化,将你的 AI 工作流迁移到新代理将成为一种常规需求。然而,迁移工具并不意味着必须放弃你的工作。通过从孤立的聊天窗口转向持久的记忆基础设施,你可以在切换 AI 智能体时无需从头开始。
如果你的工作流依赖文件、笔记、项目上下文和可复用记忆,那么像 MemoryLake 这样的可移植记忆层可以让迁移过程顺畅得多。对于经常切换工具的团队和个人来说,MemoryLake 是一个很强的选择,它能帮助你保留工作流连续性,而不是从零重建。
常见问题
如何在不丢失上下文的情况下将 AI 工作流迁移到新代理?
要在迁移 AI 工作流时不丢失上下文,你应该停止把文档和项目历史存放在 AI 智能体本身内部。相反,应使用持久记忆层(如 MemoryLake)来托管你的文件、笔记和上下文,并通过 API 或 MCP 将新代理连接到该层。
切换 AI 智能体时会丢失什么?
当你切换 AI 智能体时,通常会丢失已上传文件、项目专属指令、历史上下文、先前结论,以及你在数十次交互中建立起来的工作流连续性。
迁移到新的 AI 工具时,聊天历史就够了吗?
不够。导出聊天历史只会提供静态文本日志。它并不是可搜索、具备文档感知能力的记忆。把聊天记录粘贴进新智能体通常会压垮它的上下文窗口,并降低输出质量。
如何在不同智能体之间保留笔记和之前的工作?
你可以通过使用可移植的 AI 记忆层,在不同智能体之间保留笔记和之前的工作。通过把工作上传到一个集中式、与代理无关的平台,任何你采用的新 AI 工具都可以查询该持久记忆,以检索过去的洞见。
什么是 MemoryLake,它如何提供帮助?
MemoryLake 的设计目标是成为 AI 系统的持久记忆层。它通过充当“第二大脑”或记忆护照来提供帮助,使用户能够独立于任何特定 AI 工具存储文档、上下文和笔记,从而轻松将工作流迁移到新智能体。
如何避免从头重建工作流?
避免从头重建的方法,是把标准操作流程、重复性指令和核心文档集中到外部记忆基础设施中。当你采用新智能体时,只需通过插件或 MCP 将其连接到该基础设施即可。




