
简介
从 OpenClaw 迁移到像 Hermes Agent 这样的新环境,通常是希望升级 AI 能力的团队迈出的令人兴奋的一步。然而,一旦你决定切换,很快就会遇到一个令人沮丧的障碍:你的新代理完全是空白的。
在 现代 AI 工作流 中,在不丢失上下文的情况下切换 AI 工具,是最大的挑战之一。AI 智能体的智能不仅仅来自其底层基础模型;它来自你上传的文档、它学到的偏好,以及你在数百次交互中积累起来的特定上下文。
如果你想在不从头重启项目的情况下从 OpenClaw 迁移到 Hermes Agent,你就需要一个用于 AI 工作流连续性的策略。本指南将解释为什么标准迁移方法会失败,实际会在迁移过程中丢失什么,以及如何使用可移植记忆层来保持你的工作完整无损。
快速答案:如何从 OpenClaw 迁移到 Hermes Agent
要在不丢失工作流或记忆的情况下从 OpenClaw 迁移到 Hermes Agent,你应避免依赖手动复制粘贴或基础聊天历史导出。相反,最有效的方法是使用 可移植 AI 记忆层 将你的数据与特定代理解耦。
以下是确保工作流连续性的最佳流程:
提取核心上下文: 从 OpenClaw 中收集你经常使用的文档、进行中的研究和结构化笔记。
集中到持久记忆层中: 将这些文件(PDF、Word、Excel)上传到像 MemoryLake 这样的工具无关记忆基础设施中。
用相关数据集丰富内容: 添加行业特定的开放数据(例如学术论文或财务申报文件),以填补任何上下文空白。
将记忆连接到 Hermes Agent: 使用 API 密钥、插件或模型上下文协议(MCP),将这层持久记忆直接路由到 Hermes Agent,让它立即访问你过去的工作流。
为什么迁移 AI 智能体比看起来更难
切换工具通常意味着把数据从 A 点搬到 B 点。但 AI 智能体不会像传统数据库那样对待数据。在大多数 AI 平台中,记忆和上下文都被严重地隔离在特定聊天会话或专有工作区中。
当你决定迁移到 Hermes Agent 时,你迁移的不只是文件;你是在迁移理解。如果你的工作流依赖于 AI 知道法律案件的背景、代码库的架构决策,或每周报告的格式规则,那么切换到新工具通常意味着把这种理解重置为零。“切换工具”和“保持连续性”在技术上是完全不同的两项挑战。
典型 OpenClaw → Hermes Agent 迁移中会丢失什么
当用户尝试直接迁移时,他们往往低估了自己留下的那些看不见的工作量。若没有适当的迁移策略,你很可能会丢失:
上传的文档和文件: 你提供给 OpenClaw 用于支撑其回答的所有 PDF、CSV 和内部文档。
先前上下文和细微差别: 代理围绕你的项目目标所积累的细微指令和背景知识。
工作流记忆: 代理在处理你特定类型请求时学会采取的连续步骤。
结构化知识: 之前会话中生成的结论、摘要和综合笔记。
任务历史: 已经尝试过什么、什么失败了,以及下一步是什么的连续脉络。
为什么常见迁移方法会失效
大多数用户会试图用蛮力完成 AI 迁移。以下是最常见的手动方法通常无法保留工作流的原因:
1. 手动复制粘贴和提示词填塞
试图把你在 OpenClaw 中最好的提示词和过往对话复制出来,再粘贴到 Hermes Agent 中,并不是一个可扩展的工作流。提示词填塞——把无穷无尽的背景文本塞进每一个新提示词里——会消耗你的 token 限额、增加成本,而且经常会让新代理感到困惑。
2. 导出零散笔记
把聊天记录导出为文本文件或 JSON 可能会让你觉得自己拥有了数据,但这对 Hermes Agent 没什么帮助。过去对话的原始文本转储,对于新的代理来说,在实时场景下解析和有效使用都极其困难。
3. 逐个重新上传文件
如果你在 OpenClaw 里有几十份参考文档,手动把它们重新上传到 Hermes Agent 会很繁琐。更糟糕的是,如果将来你再次切换代理,你还得把这件一模一样的苦差事重复一遍。
解决方案:迁移到可移植 AI 记忆层
要停止在使用 AI 工具时反复从头开始,你需要转变思路。与其试图把记忆迁移进新代理,不如把记忆完全移出代理本身。
这就是可移植 AI 记忆层概念发挥作用的地方。像 MemoryLake 这样的工具旨在充当 AI 系统的持久记忆基础设施。它不仅仅是聊天历史记录器或基础文件上传器;公开文档将其定位为跨工具、模型和代理的“第二大脑”或“记忆护照”。
借助持久记忆层,你的文档、上下文和先前工作会存放在一个集中式、受治理的枢纽中。无论你使用 OpenClaw、Hermes Agent、Claude 还是 ChatGPT,代理只需接入这个记忆层,就能检索到它所需要的准确内容。
使用 MemoryLake 保留工作流和记忆:分步指南
如果你正计划迁移到 Hermes Agent,下面是一份实用的分步指南,说明如何使用 MemoryLake 来确保工作流连续性并防止数据丢失。
第 1 步:创建项目并上传你的历史数据
第一步是从 OpenClaw 的孤岛中拯救出你的上下文。在 MemoryLake 中,你会 创建一个专用项目,它将作为这项特定工作流的持久归宿。
操作:点击 MemoryLake 中的附件按钮,上传你之前在 OpenClaw 中使用的源文档。
详细信息:它支持 PDF、Word、Excel 和 Markdown 等格式。MemoryLake 会自动分析并结构化这些内容,以供 AI 检索。
外部来源:如果你的 OpenClaw 工作流依赖实时数据,你可以使用文件部分直接连接外部数据源。
为什么这很重要:与其把文件上传到 Hermes Agent 里让它们再次被困住,不如将它们上传到可重复使用的层中。
第 2 步:在 Playground 中测试上下文
在你把工作流完全交给 Hermes Agent 之前,你需要确认你的记忆是完整的,并且可以被准确检索。
操作:打开 MemoryLake Playground 并开始查询你的项目。
详细信息:提出你以前会向 OpenClaw 提出的同样复杂的问题。
为什么这很重要:这可确保你的文档上下文和历史知识已被正确解析,并准备好供下一个代理调用。
第 3 步:使用开放数据丰富你的项目
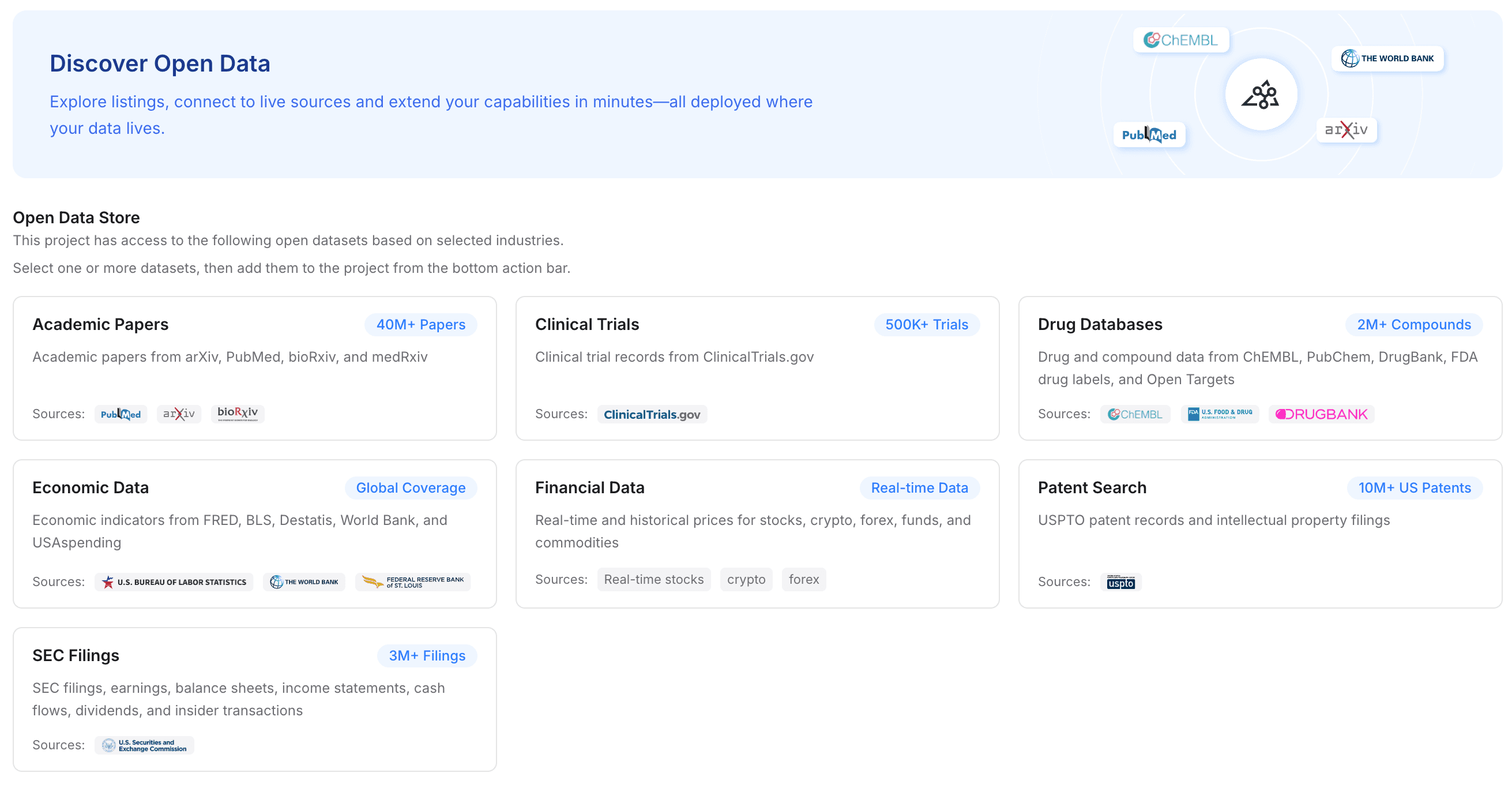
迁移是提升代理能力的绝佳时机。MemoryLake 让你能够用更广泛的行业知识来补充私人上传内容。
操作:导航到开放数据选项,并向你的项目添加相关行业数据集。
详细信息:根据你的领域,你可以让这层记忆访问学术论文、临床试验、药品数据库、经济数据、金融数据、专利检索或 SEC 文件。
为什么这很重要:这会立即提升 Hermes Agent 的基础智能。与其只依赖你旧的 OpenClaw 文件,Hermes Agent 现在将拥有由权威公共数据增强的具备文档感知能力的记忆。
第 4 步:将 MemoryLake 连接到你的工具和工作流
这是完成迁移的关键步骤。现在你会将这层持久记忆接入 Hermes Agent(如果需要的话,也可以妥善弃用你的 OpenClaw 设置)。
操作:在 MemoryLake 中生成一个 API 密钥。
无缝集成的详细信息:MemoryLake 支持一键安装和自动化配置。例如,公开文档强调,你可以复制设置指南并粘贴到 OpenClaw 中;系统会自动安装插件,完成配置,并重启网关。
连接到 Hermes Agent:你可以使用一条命令行安装插件,或者通过模型上下文协议(MCP)或 API 集成直接将其集成到 Hermes Agent 中。MemoryLake 旨在与 OpenClaw、Hermes Agent、ChatGPT 和 Claude 无缝集成。
为什么这很重要:你的新 Hermes Agent 会立即被注入你所有的先验知识。工作流会在你离开的地方继续。
应避免的常见迁移错误
把记忆当作事后补救:等到你已经完全迁移到 Hermes Agent 之后,才意识到自己缺少关键上下文。务必要在全面切换之前先提取并集中你的数据。
把聊天日志与记忆混为一谈:将你在 OpenClaw 中 50 页的聊天历史导出为 PDF 并喂给 Hermes Agent,会导致上下文窗口臃肿。你需要的是具备文档感知能力的记忆系统,而不是原始对话记录。
依赖本地文件:把参考 PDF 保存在本地桌面文件夹里,意味着你会不断地把它们拖放到 Hermes Agent 的聊天界面中。基于 API 的持久层要高效得多。
此迁移方法的最佳适用场景
使用持久 AI 记忆层来弥合工具之间的鸿沟,尤其适合:
文档密集型工作流:高度依赖厚重 PDF、法律合同或财务报告的工作流。
研究团队:花费数周构建文献综述、且在尝试新基础模型时不能丢失这些上下文的团队。
多代理用户:希望用 Hermes Agent 进行编码、用 OpenClaw 进行初稿撰写、并用 Claude 进行编辑的用户——所有工具共享同一份记忆护照。
创始人和高管:为了追求最佳性能而经常切换 AI 工具、但又需要其运营上下文保持稳定的领导者。
结论
从 OpenClaw 迁移到 Hermes Agent,并不一定意味着要丢掉数周的上下文、从头开始研究,或者重新上传无尽的 PDF 文件夹。你在迁移过程中感受到的摩擦,并不是新代理的问题——而是 AI 记忆当前被隔离存放的方式所带来的问题。
通过转向一种让你的数据独立于工具存在的模式,你就能在任何时候升级 AI 助手,而无需为丢失的生产力付出代价。
如果你的工作流高度依赖文档、项目上下文和可复用智能,MemoryLake 值得评估。它让你能够在不后退的情况下迁移工具。对于经常切换模型或代理的团队来说,采用像 MemoryLake 这样的可移植记忆层,是保持工作流连续性的有力选择,它能让你的新 AI 系统准确接手旧系统未完成的工作。
常见问题
如何在不丢失上下文的情况下从一个 AI 智能体迁移到另一个?
要在迁移时不丢失上下文,应避免完全依赖手动复制提示词。相反,应提取你的基础文档和指令,将它们上传到可移植 AI 记忆层中,然后通过 API 或 MCP 集成将这层记忆连接到你的新代理。
切换 AI 工具时通常会丢失什么?
切换 AI 工具时,用户通常会丢失上传的参考文档、持续中的任务历史、AI 已学到的关于其偏好的结构化知识,以及在多次会话中形成的特定工作流习惯。
在不同 AI 助手之间切换时,聊天历史就够了吗?
不够。原始聊天历史对于新的 AI 助手来说很难有效解析。粘贴很长的聊天记录会迅速消耗 token 限额,而且常常会降低 AI 的性能。你需要的是结构化、可检索的记忆,而不是简单的文本日志。
如何在不同工具之间保留文档和工作流记忆?
你可以通过使用工具无关的记忆基础设施来跨工具保留文档。将你的 PDF、Excel 文件和上下文存放在一个集中层中,而不是放在某个特定代理的专有存储里,这样你采用的任何新工具都可以查询同一数据源。
MemoryLake 是什么,它如何帮助迁移?
MemoryLake 是面向 AI 系统的持久记忆层。它通过充当可复用的“第二大脑”来帮助迁移。根据其设置流程,你可以将文档和上下文存储在 MemoryLake 中,然后直接将其连接到 Hermes Agent 或 OpenClaw 等平台,从而确保无缝的跨工具连续性。
如何避免从头重建 AI 工作流?
要避免重建工作流,应将你的数据与 AI 执行环境解耦。建立一个持久知识库来保存你的提示词、规则和参考文件,然后把这些数据路由到你当前正在使用的任何 AI 智能体中。




