回帰分析を簡単にマスターする方法:分析を簡素化するガイド | Powerdrill

回帰分析は学術研究の要であり、研究者が変数間の関係を調査し、仮説を検証し、予測モデルを構築することを可能にします。本ガイドでは、回帰分析の基礎から具体的な専門用語までを詳細に解説し、Powerdrill AIがいかに皆様の作業を効率化できるかを実例を交えてご紹介します。アンケートデータの分析、実験の実施、あるいは大規模なデータセットの処理など、どのような場面においても、本ガイドは有意義な洞察を容易に引き出す助けとなるでしょう。
回帰分析とは?
回帰分析は、変数間の関係を理解する上で役立つ強力な統計的手法です。その核心は、従属変数(目的変数または応答変数とも呼ばれます)が、1つ以上の独立変数(説明変数または予測変数とも呼ばれます)に対してどのように変化するかをモデル化し、分析することにあります。
重回帰分析は、1つの従属変数と2つ以上の独立変数の間の関係を理解するために用いられます。これは、単一の独立変数のみを扱う単純線形回帰の概念を拡張したものであり、結果に影響を与える可能性のある複数の要因をモデルに含めることが可能になります。
回帰分析は、以下のような様々な学術分野で幅広く活用されています。
社会科学: 社会経済的地位が教育達成度にどのように影響するかを探る。
健康科学: 運動が血圧に与える影響を調査する。
経済学: インフレーションと失業率の関係を分析する。
環境学: 気温の変化が作物収量にどのように影響するかを検証する。
例えば、ある研究者が人々の年間世帯収入を理解し、予測したいとします。この場合、年間世帯収入が従属変数となります。独立変数としては、弊社のデータセットから得られる様々な要因が考えられます。例えば、主たる世帯主の年齢は、経験豊富な個人ほど高収入を得る可能性があるため、収入に影響を与えるかもしれません。また、主たる世帯主の学歴も重要な要因です。一般的に、博士号のような高学歴を持つ人々は、高校卒業程度の学歴の人々に比べて高収入の職に就く傾向があります。
主要な用語の解説:
従属変数(Y): 説明または予測したい結果や現象。
独立変数(X): 従属変数に影響を与える可能性のある要因。
決定係数(R-squared): 独立変数が従属変数の変動をどれだけうまく説明しているかを示す指標(0から1の範囲で、値が高いほどモデルの適合度が良いことを示します)。
p値(P-value): 独立変数の統計的有意性を判断するのに役立つ統計的尺度。学術研究では、通常p値が0.05を下回ると統計的に有意であると見なされます。
係数(Coefficients): 各独立変数と従属変数の間の関係の強さと方向を表す数値。
カテゴリ変数(非連続変数)の扱い方
年間世帯収入分析のための提供されたデータセットには、「学歴」「職業」「所在地」「婚姻状況」「雇用状況」「持ち家状況」「住居の種類」「性別」「主な交通手段」など、いくつかのカテゴリ変数(質的変数)が含まれています。ここでは、ExcelとPowerdrill AIを使って回帰分析を行う際に、これらのカテゴリ変数を扱う一般的な方法をご紹介します。
Excelでの処理
ワンホットエンコーディング
「学歴」を例にとると、まずユニークなカテゴリの数を数えます。この場合、「高校卒」「学士」「修士」「博士」の4つのカテゴリがあります。次に、新しい列を4つ作成します。各行について、「学歴」が「高校卒」であれば、「高校卒」の列には1が入り、他の3つの列には0が入ります。例えば、A2セルで「学歴」が「学士」の場合、2行目に対応する新しい「学士」の列には1が入り、「高校卒」「修士」「博士」の列には0が入ります。
このプロセスは、すべてのカテゴリ変数に対して繰り返されます。「職業」の場合、医療、教育、テクノロジー、金融、その他など、複数の種類があるため、各種類ごとに新しい列を作成します。ある世帯の「職業」が「テクノロジー」であれば、その行の「テクノロジー」列は1となり、他の職業関連の列は0となります。
ワンホットエンコーディングは、カテゴリ変数をバイナリ変数のセットに変換し、回帰モデルがカテゴリ情報を数値として理解し処理できるようにします。各カテゴリは、ユニークなバイナリベクトルで表現されます。
ダミー変数の作成
「所在地」を例にとると、「都市部」「郊外」「地方」の3つのカテゴリがあるとします。ワンホットエンコーディングのように3つの列を作成する代わりに、2つの列を作成します。この場合、「地方」を参照カテゴリとして選択できます。「都市部」の列では、「所在地」が「都市部」であれば値は1となり、「郊外」または「地方」であれば0となります。「郊外」の列では、「所在地」が「郊外」であれば値は1となり、「都市部」または「地方」であれば0となります。
このアプローチは変数の数を減らすため、多数のカテゴリ変数を扱う場合に有益です。例えば、「職業」に多くのカテゴリがある場合、ダミー変数を作成することで、(ワンホットエンコーディングのように)非常に相関の高い変数が多すぎることによって生じる多重共線性などの問題を回避できます。
参照カテゴリを選択することで、他のカテゴリをそれとの相対的な関係で表現できます。回帰モデルは、各非参照カテゴリが参照カテゴリと比較してどのような影響を持つかを推定できるようになります。
Powerdrill AIでの処理:自動処理
Powerdrill AIには、データセット内のカテゴリ変数を自動的に認識できる組み込みアルゴリズムがあります。例えば、「婚姻状況」や「雇用状況」のような変数を含むデータセットをアップロードする際、Excelのように手動でエンコーディングを行う必要はありません。
このAIプラットフォームは、カテゴリ変数をより効率的に処理できるように設計されています。例えば、固有の順序を持つ変数(ただし、今回のデータセットでは、ほとんどのカテゴリ変数に明確な順序はありません)に対しては、順序エンコーディングのような高度な技術を使用する場合があります。順序のない変数に対しては、ワンホットエンコーディングに似た技術や、より高度な機械学習に特化したエンコーディングを内部で利用することができます。
これにより、時間と労力を大幅に節約できます。ユーザーはカテゴリ変数のエンコーディングに関する技術的な詳細を気にする必要がありません。
ExcelまたはPowerdrill AIのいずれかでカテゴリ変数を処理した後、それらを回帰分析に使用できます。Excelでは、新しく作成された列(ワンホットエンコーディングまたはダミー変数によるもの)を回帰分析の「X入力範囲」に含めます。Powerdrill AIでは、カテゴリ変数を処理するよう指示するだけで、プラットフォームがアップロードされたデータセットを更新し、これらの変数を適切に処理して分析を実行します。
Excelで重回帰分析を行う方法
Excelは、基本的な回帰分析を行うための広く利用されている使いやすいツールです。年間世帯収入に影響を与える様々な人口統計学的および社会経済的要因に焦点を当てた、弊社の擬似データセットを使用してみましょう。このデータセットには、「年齢」「学歴」「職業」「扶養家族数」などの特徴が含まれており、「年間世帯収入」が従属変数となります。
ステップ1:データの準備
まず、データがクリーンであることを確認します。欠損値がないかチェックしてください。例えば、「年齢」列に欠損値がある場合、それを補完できます。一つの方法は、欠損していないすべての年齢の平均を使用することです。平均は、欠損していない年齢をすべて合計し、欠損していないエントリの数で割ることで計算します。 「職業」のようなカテゴリ変数に欠損値がある場合は、最頻値(最も頻繁に出現する職業)を使用して補完することを検討できます。あるいは、欠損値の数が少ない場合は、欠損値を含む行を削除することを選択してもよいでしょう。
データを正しくフォーマットします。「年齢」や「扶養家族数」のような数値が正しい数値形式になっていることを確認してください。カテゴリ変数については、例えば、すべての「学歴」エントリが「High School」「Bachelor's」「Master's」「Doctorate」のように一貫して正確に記述されていることを確認してください。
ステップ2:分析ツールパックの使用
分析ツールパックが有効になっていない場合は、有効にする必要があります。「ファイル」>「オプション」>「アドイン」に進みます。「分析ツール」を選択し、「設定」をクリックします。「分析ツール」の横にあるチェックボックスをオンにし、「OK」をクリックします。
有効にしたら、「データ」タブに移動し、「データ分析」をクリックします。「データ分析」ダイアログボックスで、「回帰」を選択します。
ステップ3:パラメータの設定
回帰ダイアログボックスにて:
Y入力範囲: 「年間世帯収入」のデータ範囲を「Y入力範囲」ボックスに入力します。例えば、データがN2からN10001までの場合、「$N2:N$10001」と入力します。
X入力範囲: 「年齢」「学歴」「扶養家族数」などの独立変数の範囲を「X入力範囲」ボックスに入力します。Excelは「学歴」のようなカテゴリデータに対してダミー変数を作成することがあります。
「ラベル」にチェック: 列見出しがある場合、このボックスにチェックを入れることで、Excelが回帰出力で変数名を認識するのに役立ちます。
信頼水準: 必要に応じて信頼水準を設定します。デフォルトは95%です。
出力オプション: 回帰結果の出力範囲を選択します。新しいワークシートまたは既存のワークシート内の空き領域に設定できます。
「残差」にチェック: 残差は、観測値と予測値の差を示します。残差が大きい場合、モデルがその点で正確に予測できていない可能性があります。これらはモデルの品質を評価する上で重要です。
「標準化残差」にチェック: 外れ値をより効果的に検出するのに役立ちます。絶対標準化残差が特定のしきい値(例:3)を超える値は、外れ値である可能性が高いです。
「残差プロット」にチェック: 独立変数と残差の関係を示します。プロットにパターンがある場合、モデルが誤って指定されている可能性を示唆します。このオプションは、潜在的な問題の診断に役立ちます。
「回帰直線プロット」にチェック: 実際値と予測値を視覚的に比較します。データ点が予測線から広範囲に散らばっている場合、モデルの適合度が低い可能性があります。このオプションは、モデル全体の適合度を評価するのに役立ちます。
ステップ4:結果の分析
「OK」をクリックすると、Excelは包括的な結果のセットを生成します。これには、各変数の係数が含まれます。例えば、「年齢」の係数は、他のすべての変数が一定であると仮定した場合、年齢が1年増加するごとに「年間世帯収入」がどれだけ変化すると予想されるかを示します。標準誤差、t統計量、p値、そして決定係数(R-squared)の値も提供されます。決定係数(R-squared)の値は、独立変数が「年間世帯収入」の変動をどれだけうまく説明しているかを示します。1に近い値は、より良い適合度を示します。
AIで重回帰分析を実行する方法
Powerdrill AIは、回帰分析のプロセスを簡素化し、向上させるための優れたプラットフォームです。引き続き、年間世帯収入に関する弊社の擬似データセットを使用します。
ステップ1:データのアップロード
powerdrillにアクセスしてください。ユーザーフレンドリーなインターフェースにより、データセットを簡単にアップロードできます。お使いのコンピュータまたはDropboxクラウドから、データファイル(CSV、Excelなどの一般的な形式)をアップロードできます。
ステップ2:回帰分析タスクの選択
データセットをアップロードした後、特定の分析要件に応じて、分析の目標や研究の意図をAIに伝える必要があります。これにより、AIは回帰分析モデルを構築できるようになります。このプロセス中、AIはパーソナルリサーチアシスタントのように機能し、知りたい情報を何でも話し合うことができます。
同時に、AIは自動で質問を生成し、データセット内の変数間の内部関係を素早く見極めるのに役立ちます。
データがアップロードされると、Powerdrill AIは変数を検出できます。弊社のデータセットでは「年間世帯収入」である従属変数を指定する必要があります。その後、「年齢」「学歴」「職業」「職務経験」など、回帰モデルに含めたい独立変数を選択することができます。
Powerdrill AIは、様々なデータタイプを最小限の手動操作で処理できる十分な知能を備えています。
ステップ3:モデルの学習と結果
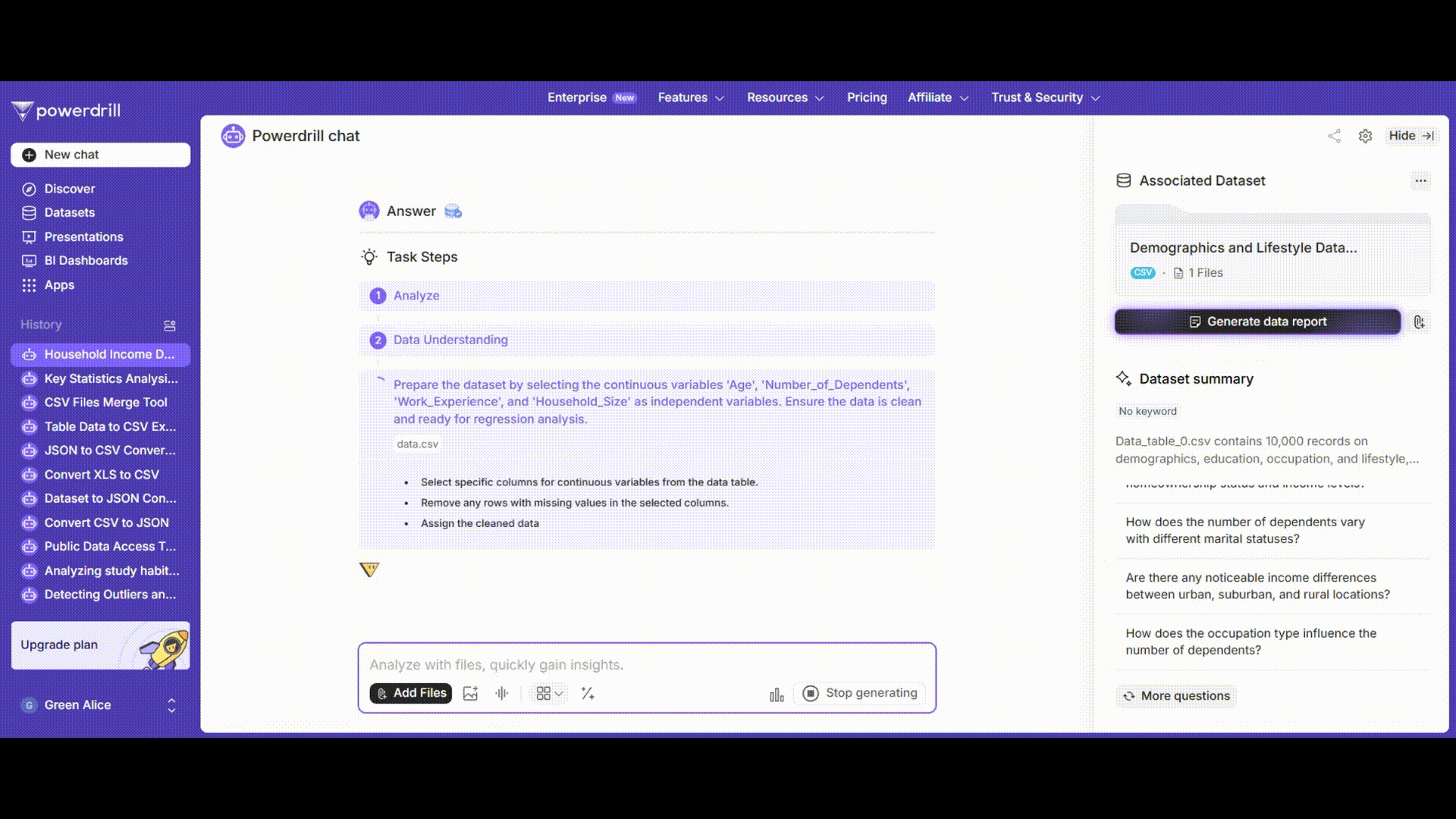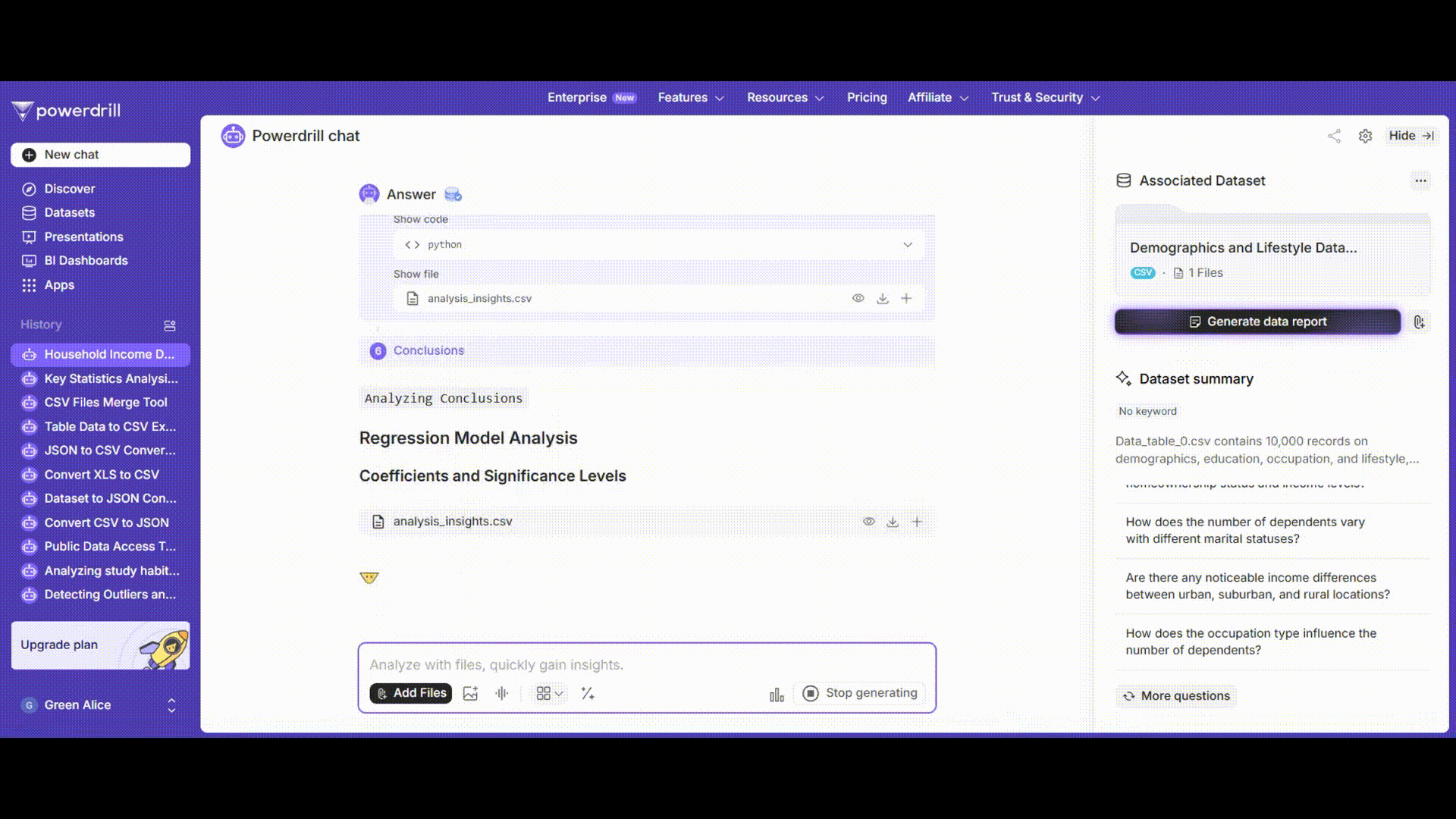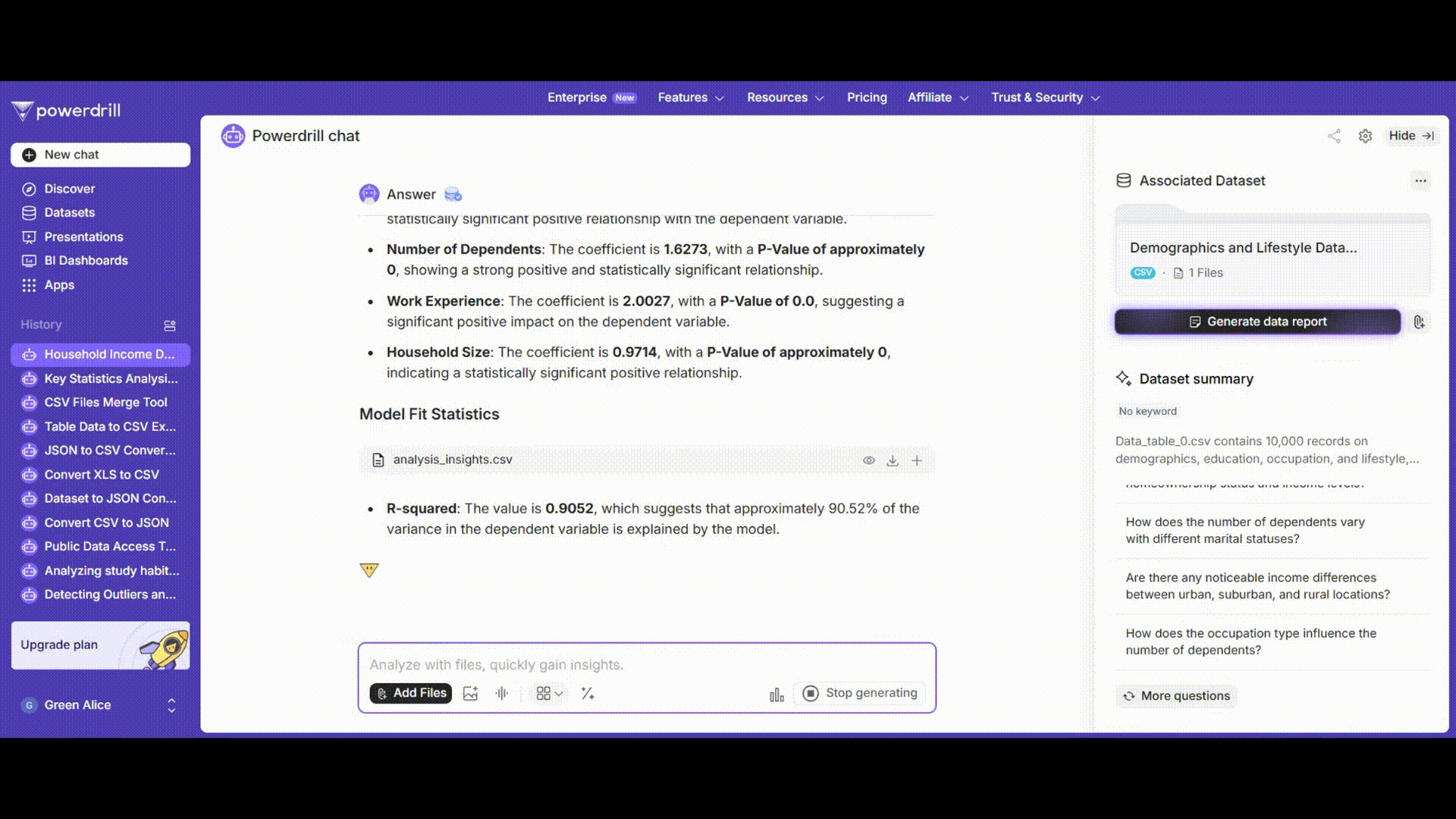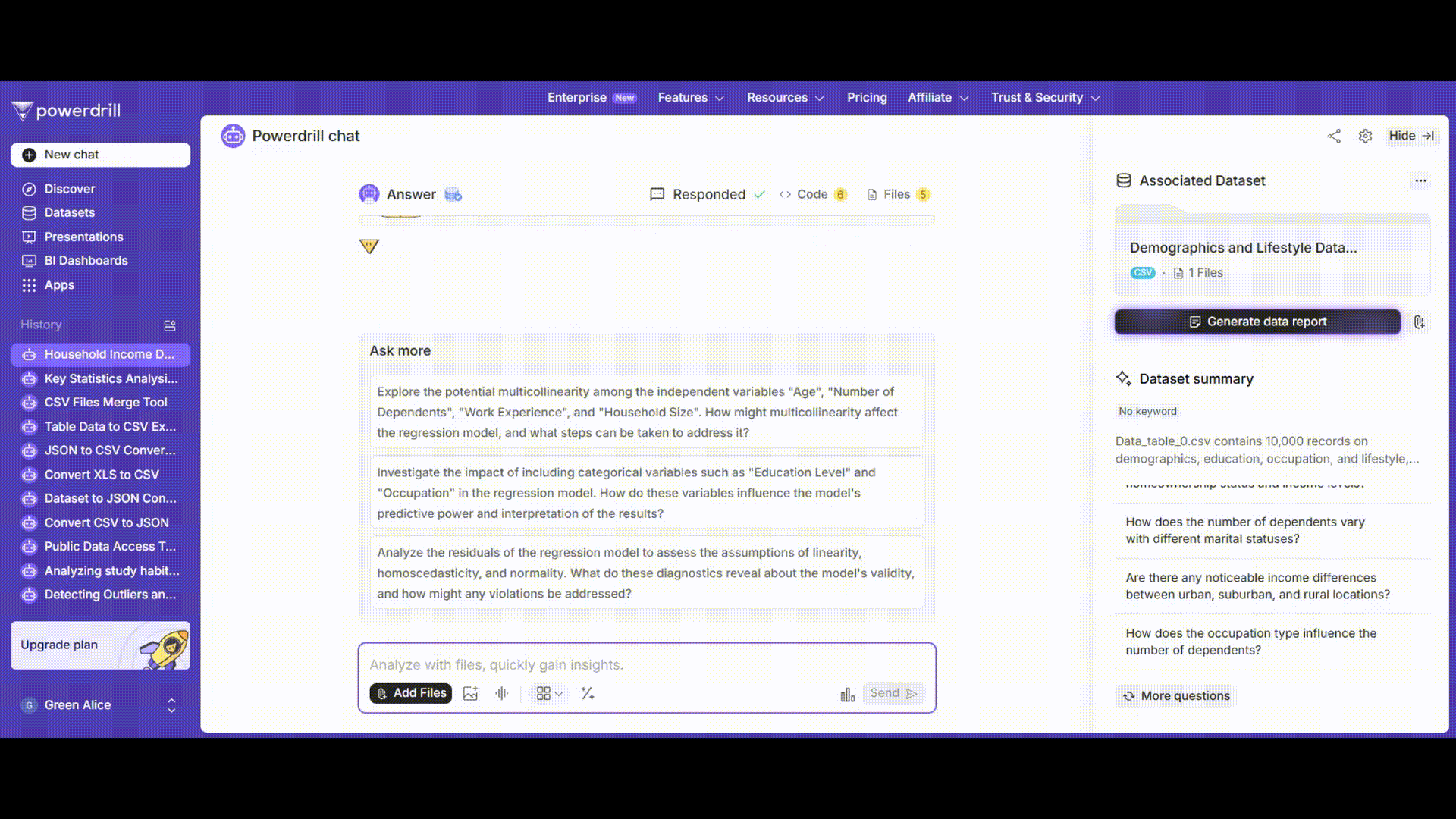
Powerdrill AIは、高度な機械学習アルゴリズムを使用して回帰分析を実行します。モデルを迅速に学習させ、詳細な結果を提供します。
結果には、従来の回帰係数とその有意水準だけでなく、視覚化も含まれます。例えば、年間世帯収入の実際値と予測値の散布図が表示され、モデルのパフォーマンスを視覚的に評価するのに役立ちます。予測値が実際値にどれだけ近く追従しているかを簡単に確認できます。
Powerdrill AIは、従来のツールよりも複雑なデータタイプをよりスムーズに処理することもできます。変数間の関係をより包括的な方法で分析できます。例えば、単純なExcel回帰では見過ごされがちな、「職務経験」と「年間世帯収入」の間に非線形な関係があるかどうかを迅速に特定できます。
Powerdrillで研究を強化する
データ分析の世界を探求し始めたばかりの初心者の方も、経験豊富な研究者の方も、回帰分析は極めて重要なツールです。Excelは基本的な回帰分析の出発点としては良いですが、Powerdrill AIのようなプラットフォームは、特に複雑なデータセットを扱う際に、より高度で効率的かつユーザーフレンドリーな方法で回帰分析を実行することができます。
AIを活用した回帰分析の手軽さとパワーを体験したい方は、ぜひpowerdrill.aiにアクセスしてください。今すぐデータをアップロードして、データに隠された洞察を解き放ちましょう。ビジネスデータ、科学研究データ、その他のあらゆる種類のデータを分析する場合でも、Powerdrillは正確で有意義な結果を迅速に得るのに役立ちます。
今すぐ始めましょう!Powerdrillにアクセスしてデータをアップロード!
サンプルデータセットの紹介
本記事で使用されているデータセットは、年間世帯収入に影響を与える要因を理解することに焦点を当てています。データ分析をダウンロードして練習するには、こちらのページからアクセスできます。
この擬似データセットは、年間世帯収入に影響を与える様々な人口統計学的および社会経済的要因をシミュレートしています。探索的データ分析、予測モデリング、および異なる特徴と収入レベル間の関係の理解に利用できます。
これには、広範な人口統計学的および社会経済的変数が含まれています。
主たる世帯主の「年齢」は、職務経験やライフステージが収入に与える潜在的な影響を捉えています。
「学歴」は、高校卒業から博士号まで、異なる教育水準がどのように様々な収入レベルにつながるかを示しています。
「職業」は、医療、教育、テクノロジー、金融など、それぞれ異なる収入の可能性を持つ様々な分野を詳細に示しています。
「扶養家族数」は、家族構成が可処分所得にどのように影響するかを反映しています。
「所在地」(都市部、郊外、地方)は、労働市場や生活費における地域差を考慮しています。
「職務経験」(年数)、「婚姻状況」、「雇用状況」、「世帯規模」、「持ち家状況」、「住居の種類」、「性別」、そして「主な交通手段」はすべて、年間世帯収入との複雑な関係に独自の側面を加えています。
この豊富なデータセットは、世帯収入を決定する上で重要な要因とその相対的な重要性を明らかにするための、詳細な回帰分析を可能にします。