AIを活用した量的研究のためのデータ分析 | Powerdrill AI

学術分野でも専門分野でも、根拠に基づいた結論を導き出す上で量的研究は不可欠です。しかし、そのプロセスは時に overwhelming (圧倒的)なものとなりがちです。生データには大幅なクリーニングが必要なことが多く、複雑な統計手法には高い精度が求められます。ここに、Powerdrillが登場します。これは、量的研究プロセスのあらゆる段階を簡素化し、強化するために設計されたAI搭載ソリューションです。
Powerdrillは単なるツールではなく、あなたの研究の道のりにおけるパートナーです。そのAIを活用した機能は、時間を節約し、エラーを減らし、統計の専門知識の有無にかかわらず、誰もが量的研究にアクセスできるようにします。Powerdrillがあなたに適しているかどうかを知りたいですか?実際の動作を確認するには、このビデオをご覧ください。
量的研究の課題
量的研究は数値データに焦点を当て、統計的手法を用いて仮説を検証したり、パターンを特定したりします。強力な手法である一方で、この方法論には以下のような重要な課題が伴います。
データクレンジング: 生データが完璧であることは稀です。多くの場合、欠損値、外れ値、または不整合な書式設定が含まれており、これらが結果を歪める可能性があります。これらの問題を手作業で特定し、対処することは、時間がかかるだけでなく、ヒューマンエラーも発生しやすいものです。
統計手法の理解: 回帰分析、t検定、分散分析(ANOVA)といった手法を適用するには、推測統計学の深い理解が必要です。多くの学生や若手研究者はこれらの概念を理解するのに苦労し、適用や解釈においてエラーを犯しやすくなります。
ソフトウェアの習熟度: SPSS、Stata、Rといった一般的な統計ソフトウェアは、習得に時間と労力がかかることがよくあります。これらのツールを使いこなすことは、特に技術的なバックグラウンドが限られている人々にとっては、とっつきにくい場合があります。
時間のかかる分析: 統計手法に精通している人にとっても、手動または半手動で分析を行うことは、特に大規模なデータセットや複数の検定を行う場合、数時間から数日かかることがあります。
可視化の課題: 生データを、正確でかつ魅力的なグラフや図に変換することは、多くの研究者が習得に苦労するスキルです。不適切な可視化は、結果の誤解を招いたり、インサイトを効果的に伝えられなかったりする可能性があります。
結果の解釈: 統計的有意性が常に実践的な関連性に直結するわけではありません。研究者は、自分たちの発見が現実世界で何を意味するのかを解釈するのに苦労することが多く、曖昧または不完全な結論に至りがちです。
レポート作成と執筆: 論文発表やプレゼンテーションのために研究結果を要約するには、複雑なデータを明確で実用的なインサイトに統合する必要があります。多くの研究者は、特に厳格な書式設定や文字数制限がある場合、これを最も困難な作業の一つだと感じています。
再現性と透明性: 研究結果の再現性と透明性を確保することは、学術コミュニティや科学コミュニティでますます重視されています。手法、データセット、分析プロセスの詳細な記録を維持することは不可欠ですが、時間の制約から見過ごされがちです。
これらの各ステップには、技術的な専門知識と時間の両方が求められますが、いずれも不足しがちなリソースです。
Powerdrillが量的研究をいかに簡素化するか
PowerdrillはAIを活用して、データ分析プロセスを自動化し、最適化します。それぞれの課題にどのように対処するかを詳しく見ていきましょう。
1. 手間のかからないデータクレンジング
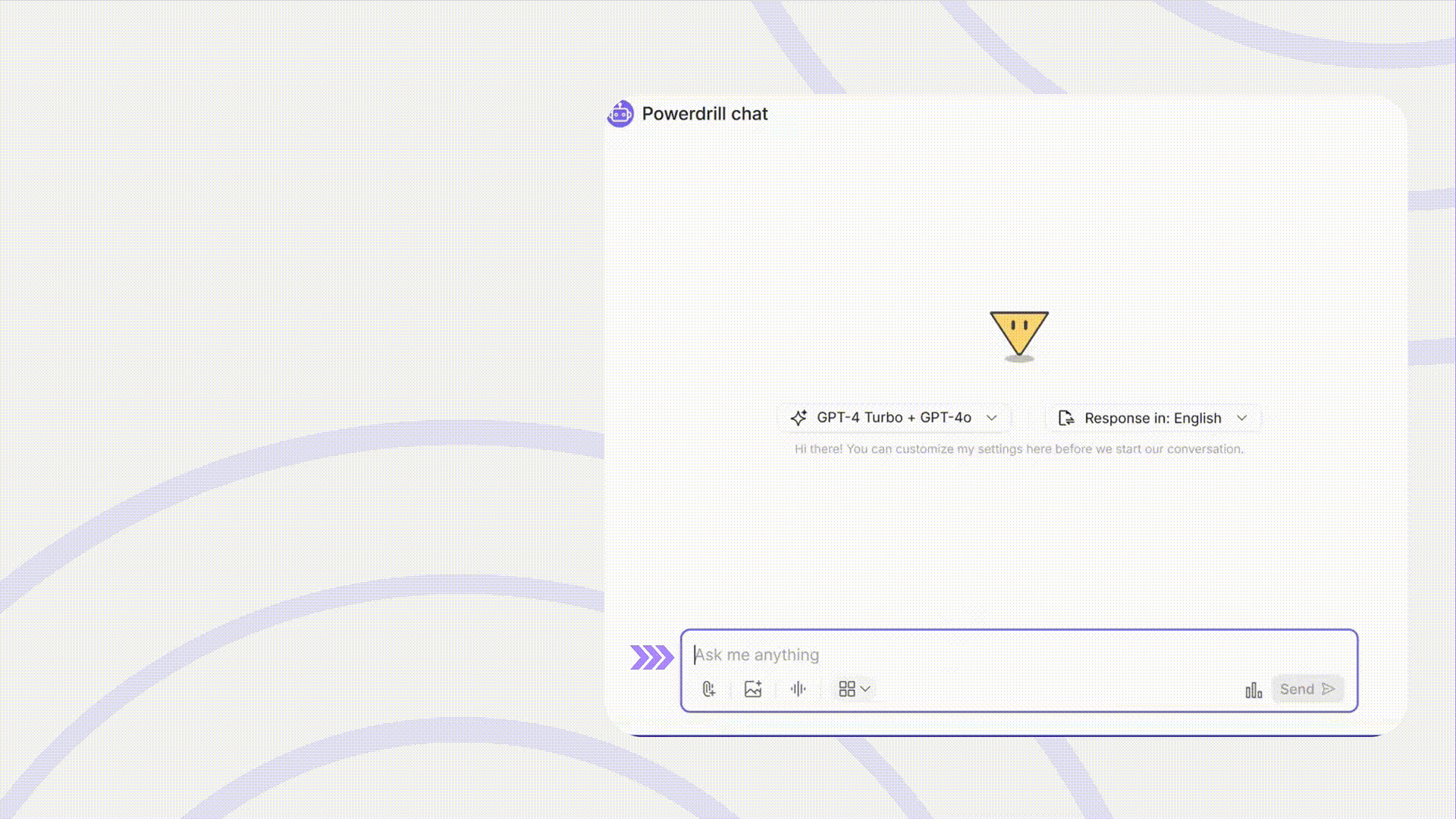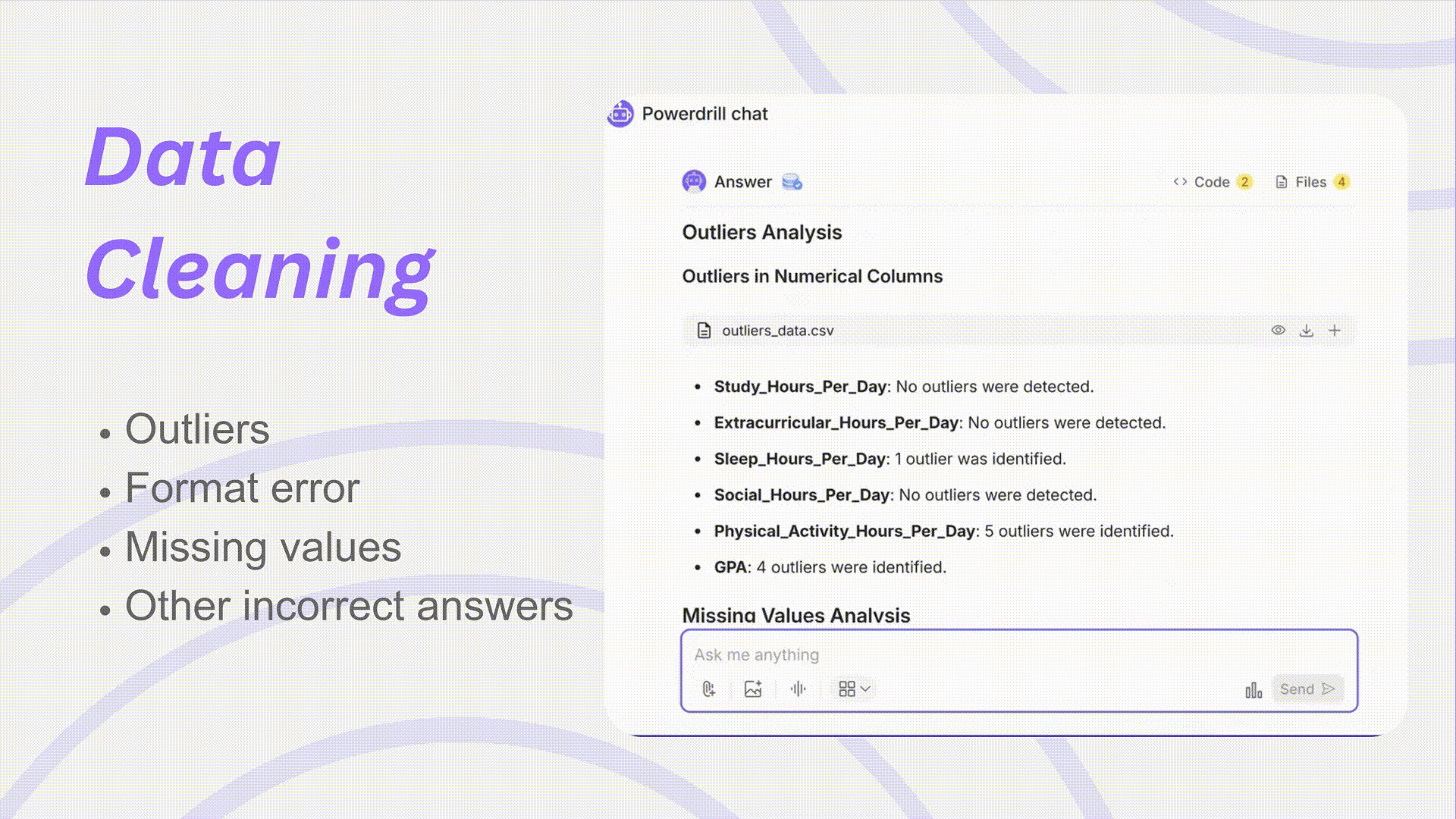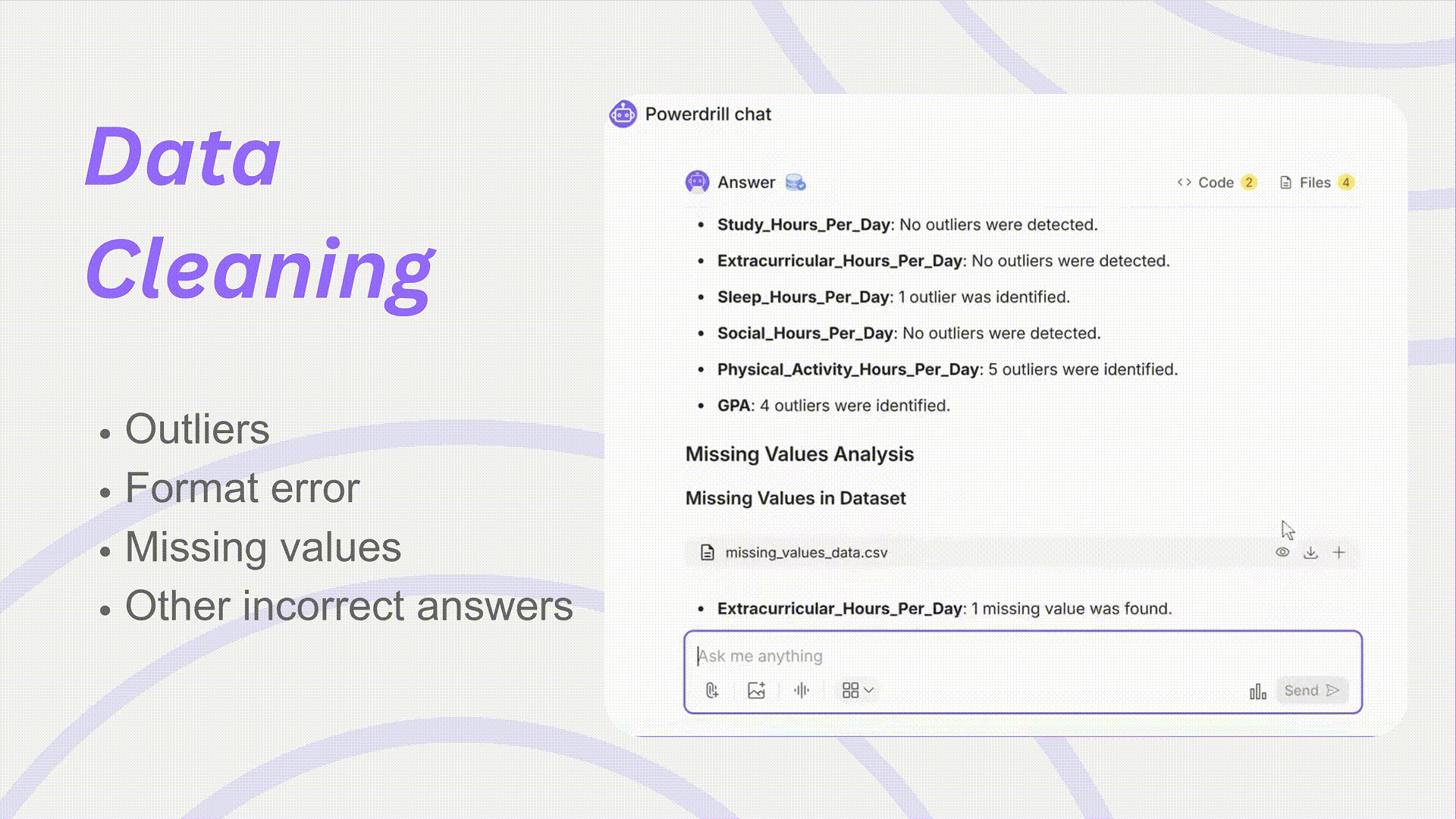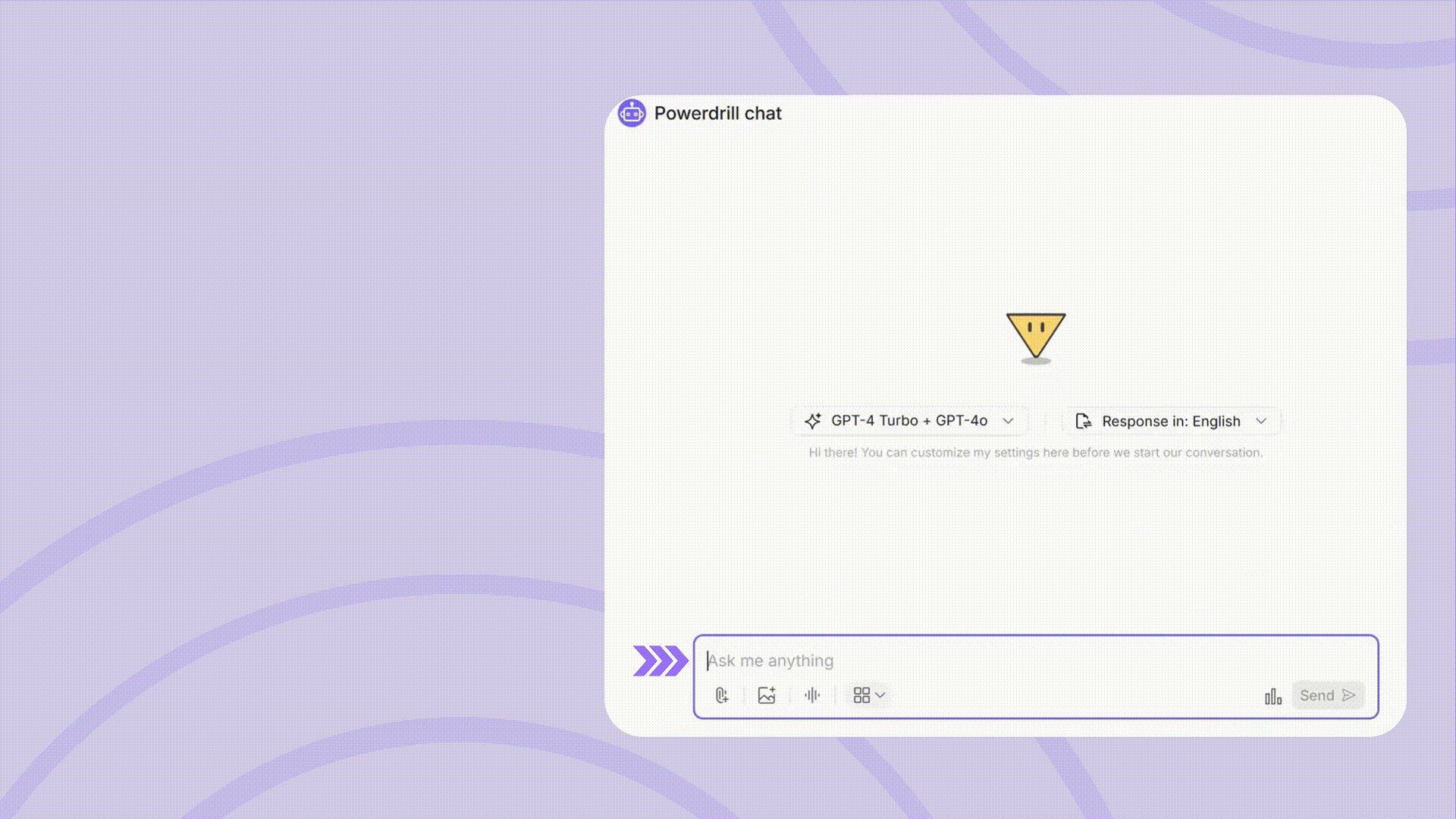
データクレンジングは、信頼できる分析の基礎です。Powerdrillを使用すれば、クリーンアップされ、標準化され、分析準備が整ったデータセットで、自信を持って研究を開始できます。
外れ値検出: 標準から著しく逸脱する値を自動的に特定し、フラグを立てます。これにより、それらの値を除外するか保持するかを決定できます。
欠損値の処理: 平均値補完、高度な予測モデル、またはユーザー定義ロジックなどの手法を用いて欠損値を補完し、分析精度への影響を最小限に抑えます。
書式設定の標準化: 日付、数値、テキスト値の書式が自動的に一貫していることを確認し、手動での調整の必要性をなくし、ヒューマンエラーを最小限に抑えます。
重複データの特定: 重複するエントリを迅速に特定し、処理することで、データの整合性を維持し、時間を節約します。
2. 包括的な記述統計
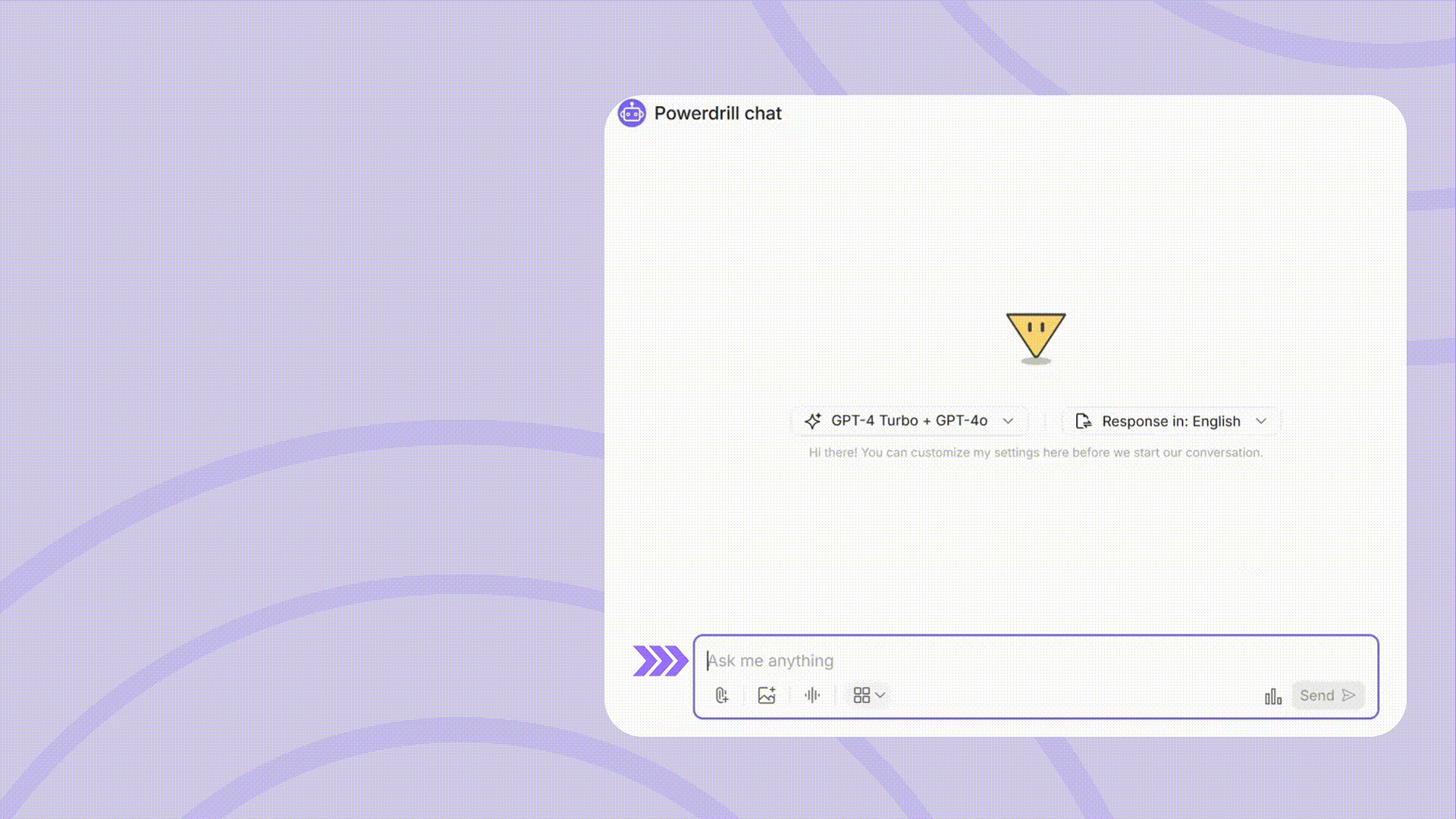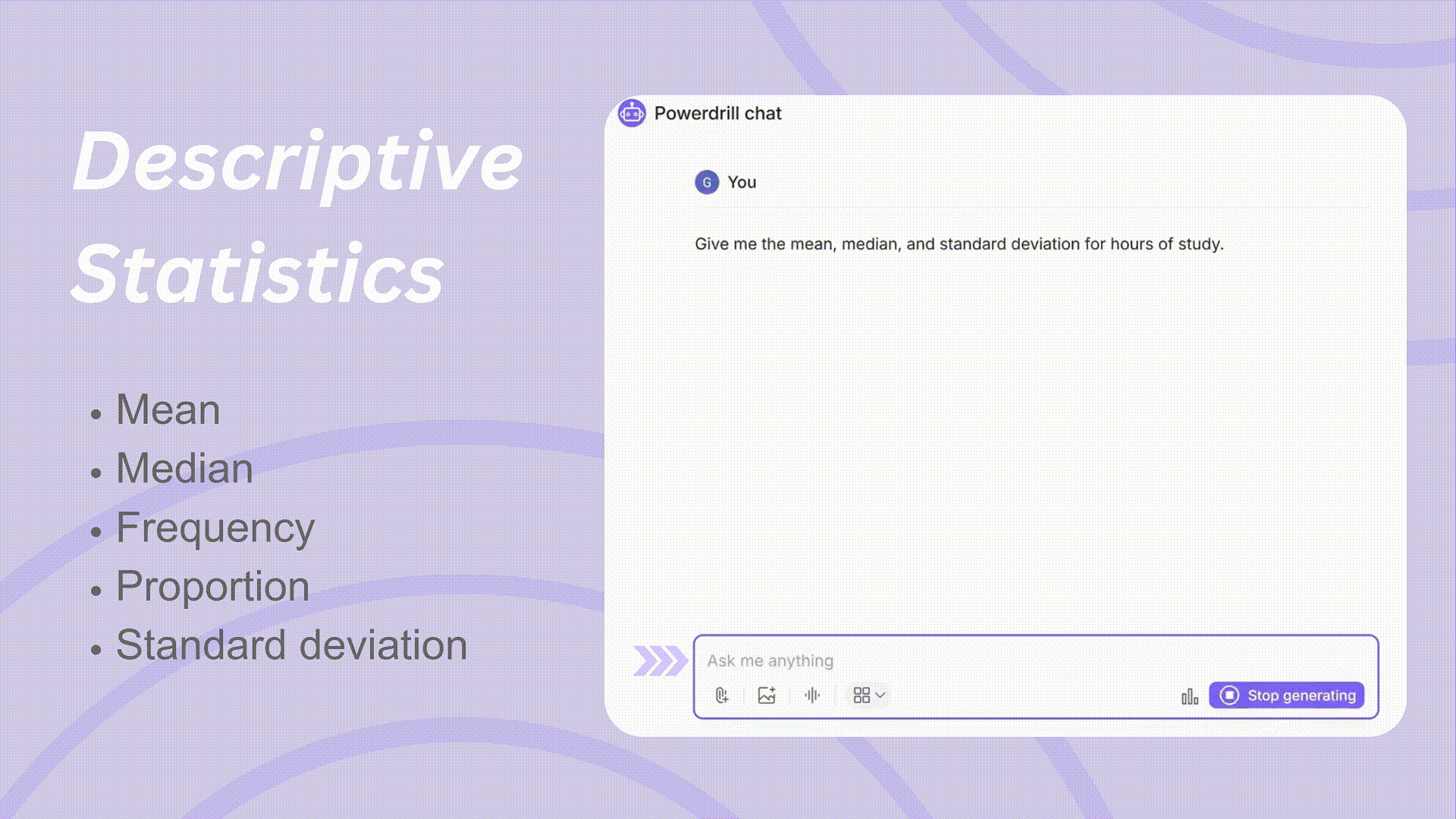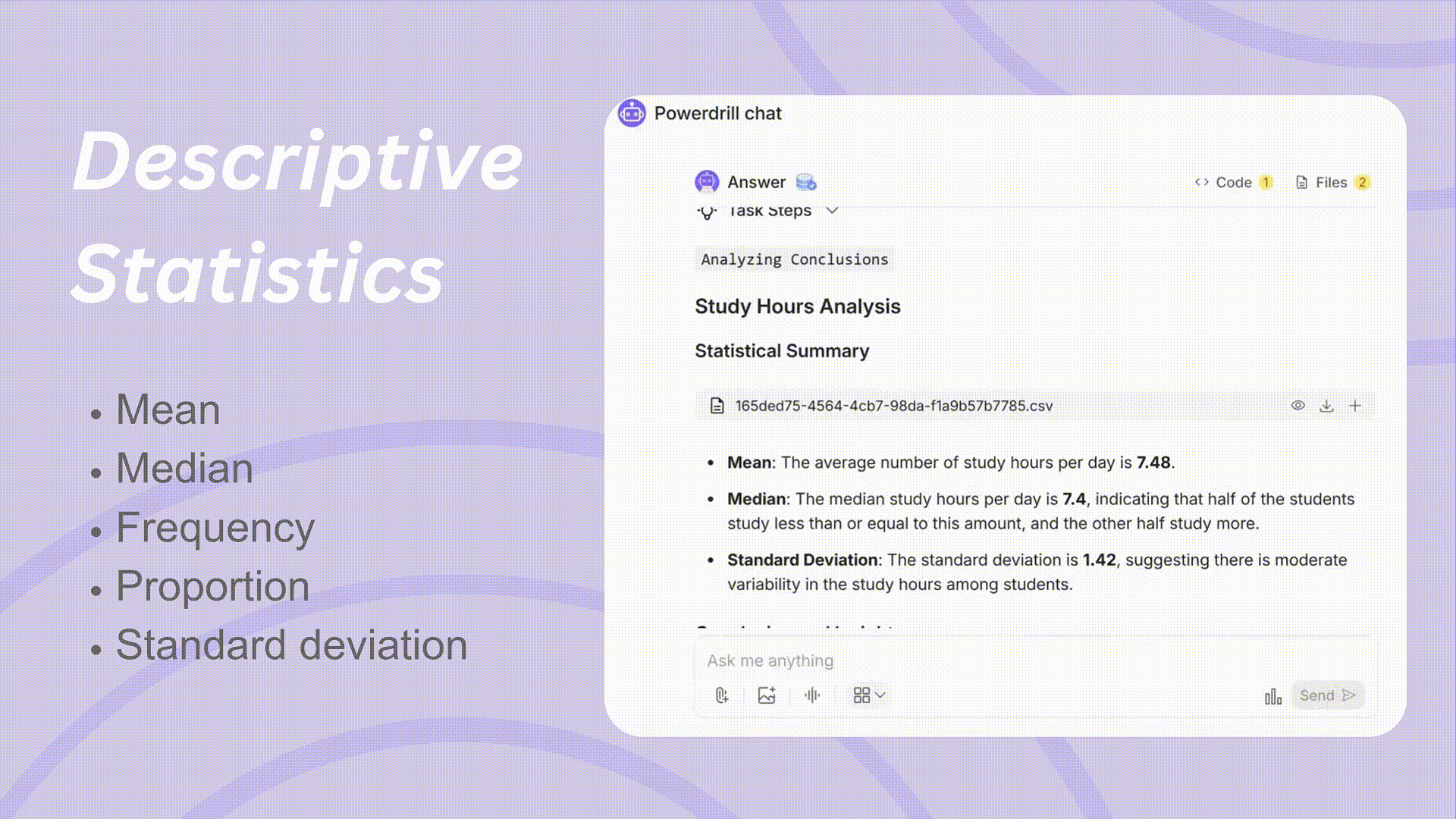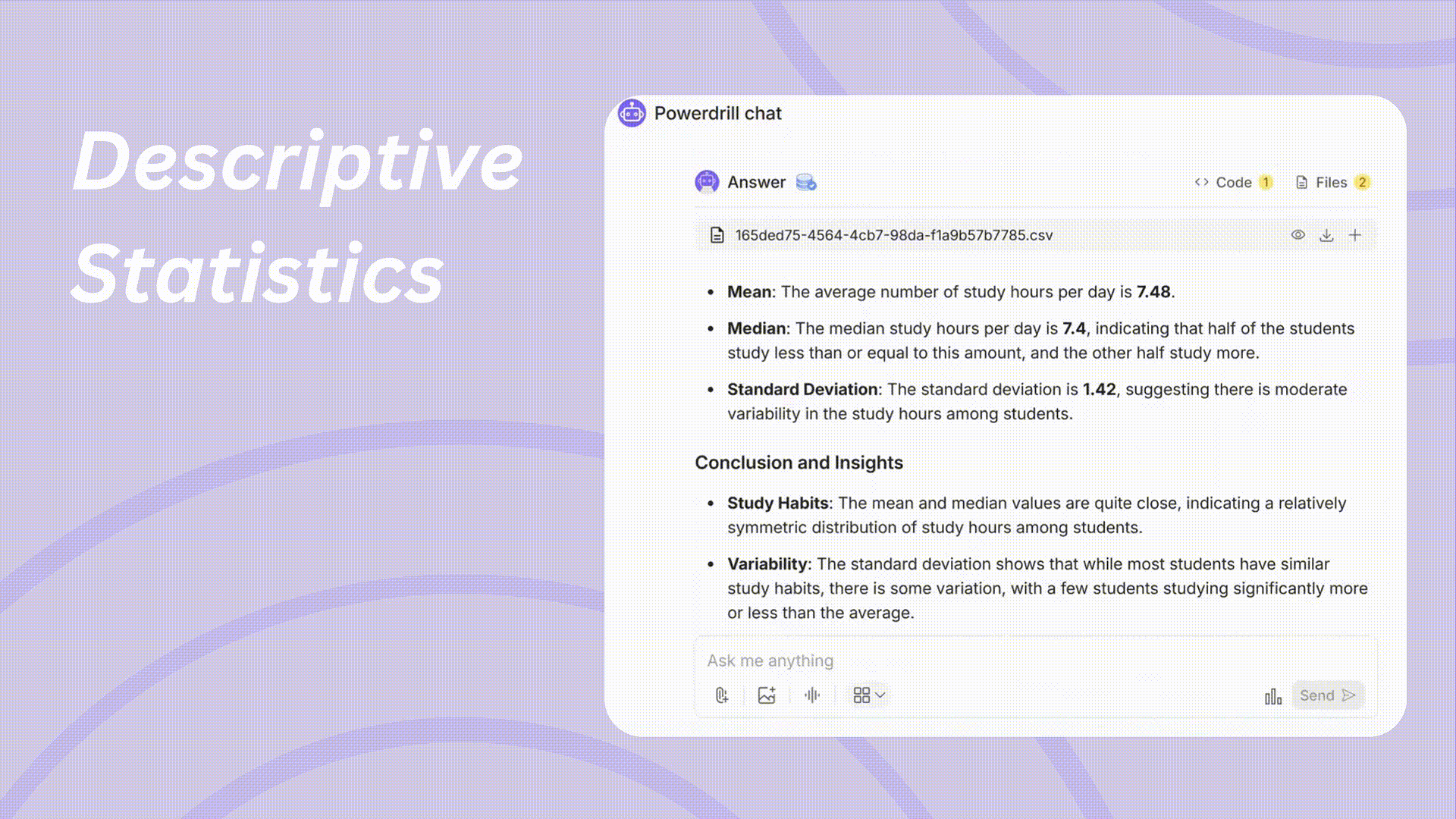
複雑なモデルに深く入る前に、データの基本を理解することが重要です。Powerdrillは、数回のクリックで詳細な要約を提供します。
主要な指標: 平均値、中央値、範囲、標準偏差、分散の詳細な内訳を提供し、データセットの中心傾向とばらつきを包括的に理解することができます。
視覚的要約: ヒストグラム、箱ひげ図、度数分布表を生成し、データ分布と外れ値を明確に視覚化します。
グループ比較: データ内のグループ(例:人口統計学的変数別)を自動的に比較して傾向や違いを特定し、手動計算にかかる時間を大幅に節約します。
相関分析: 相関係数や散布図などの視覚ツールを使用して変数間の関係性を強調表示し、早期にパターンを検出するのに役立ちます。
3. 合理化された仮説検定

推測統計学は量的研究の根幹をなします。Powerdrillは、以下のツールでこれらの複雑な分析を簡素化します。
t検定および分散分析 (ANOVA): 小規模および大規模なデータセットの両方に適した、グループ平均の迅速かつ正確な比較を可能にします。
回帰モデル: 線形回帰、ロジスティック回帰、重回帰分析を提供し、堅牢な結果を保証するためのモデル診断も完備しています。
カイ二乗検定: カテゴリデータの分析を容易にし、変数間の関係性や独立性を判断します。
仮説検定: 研究の問いに対して適切な統計検定(t検定、ANOVA、回帰分析、カイ二乗検定など)を特定するのに役立ちます。プラットフォームは計算を自動化し、主要なインサイトを強調表示することで、ユーザーがエラーや誤解を回避できるようにします。
4. プロフェッショナルレベルの可視化
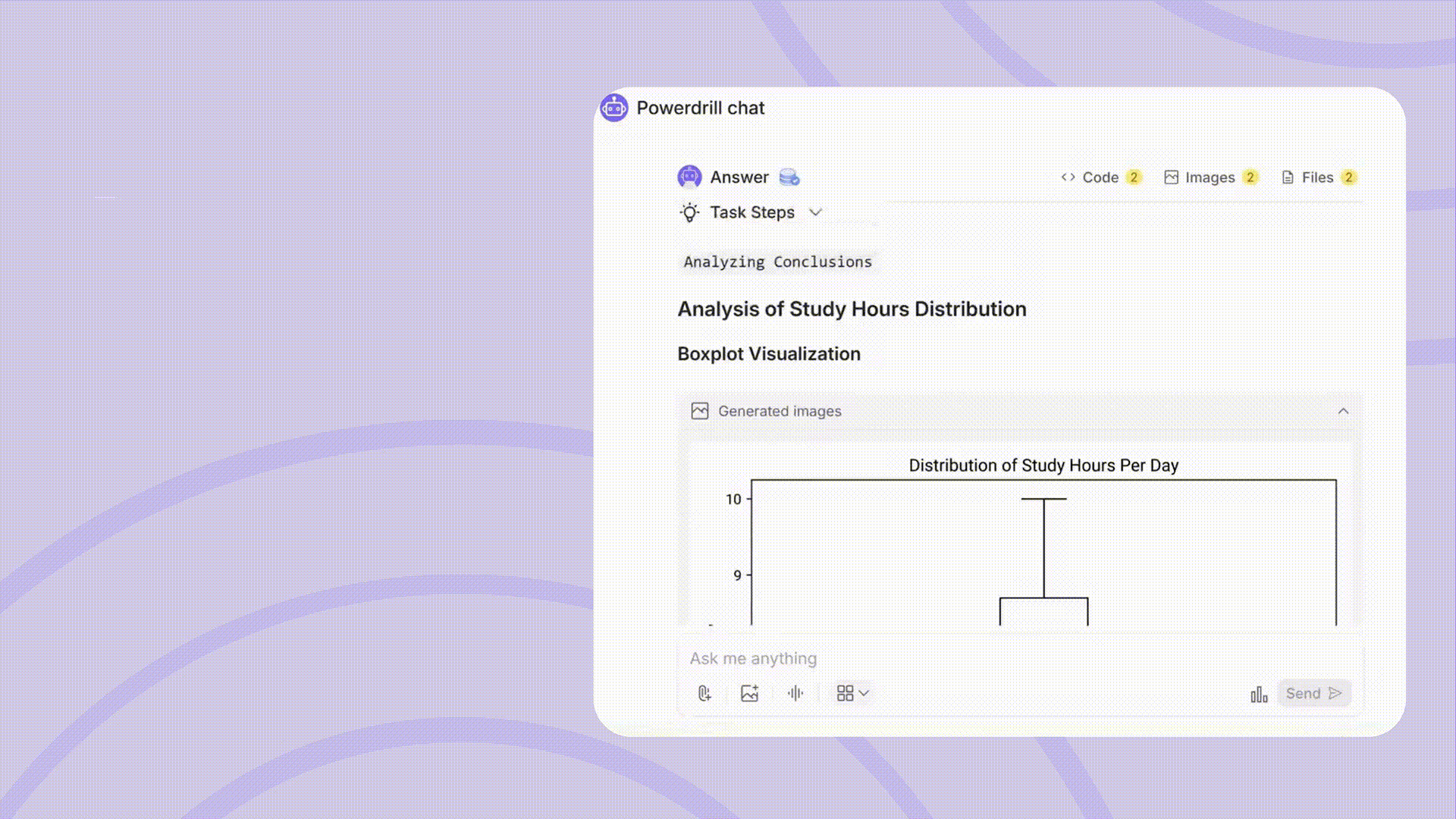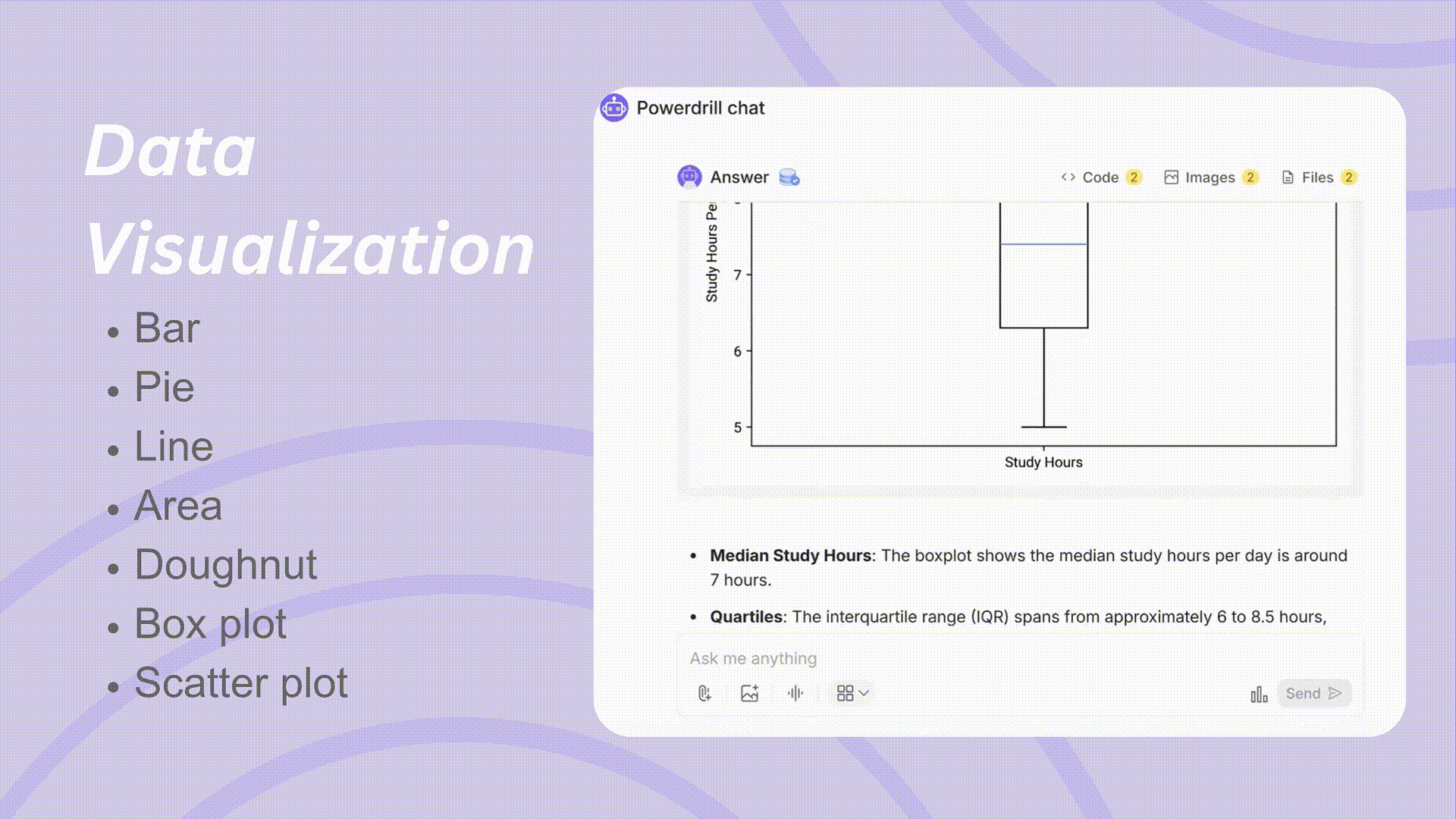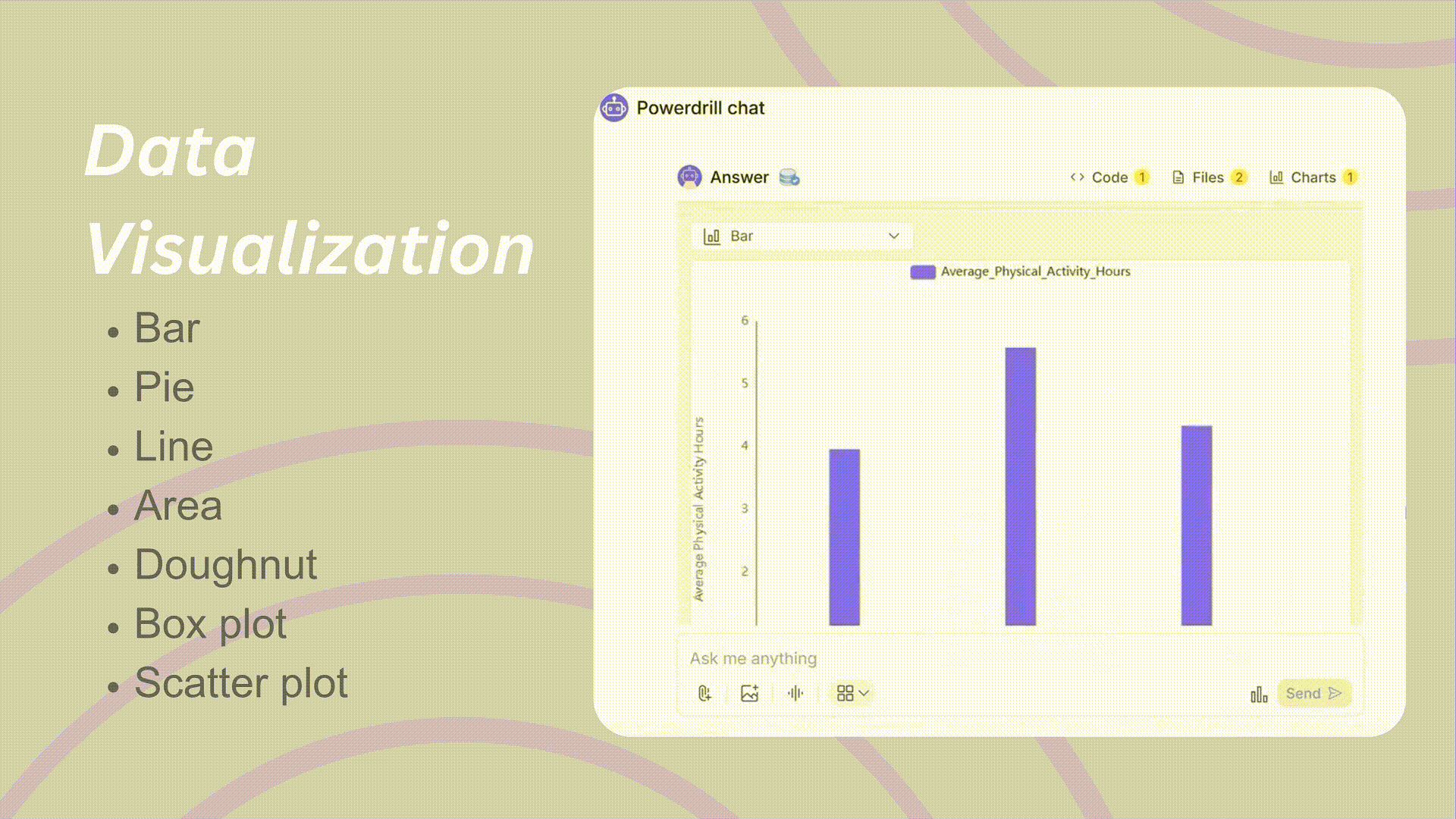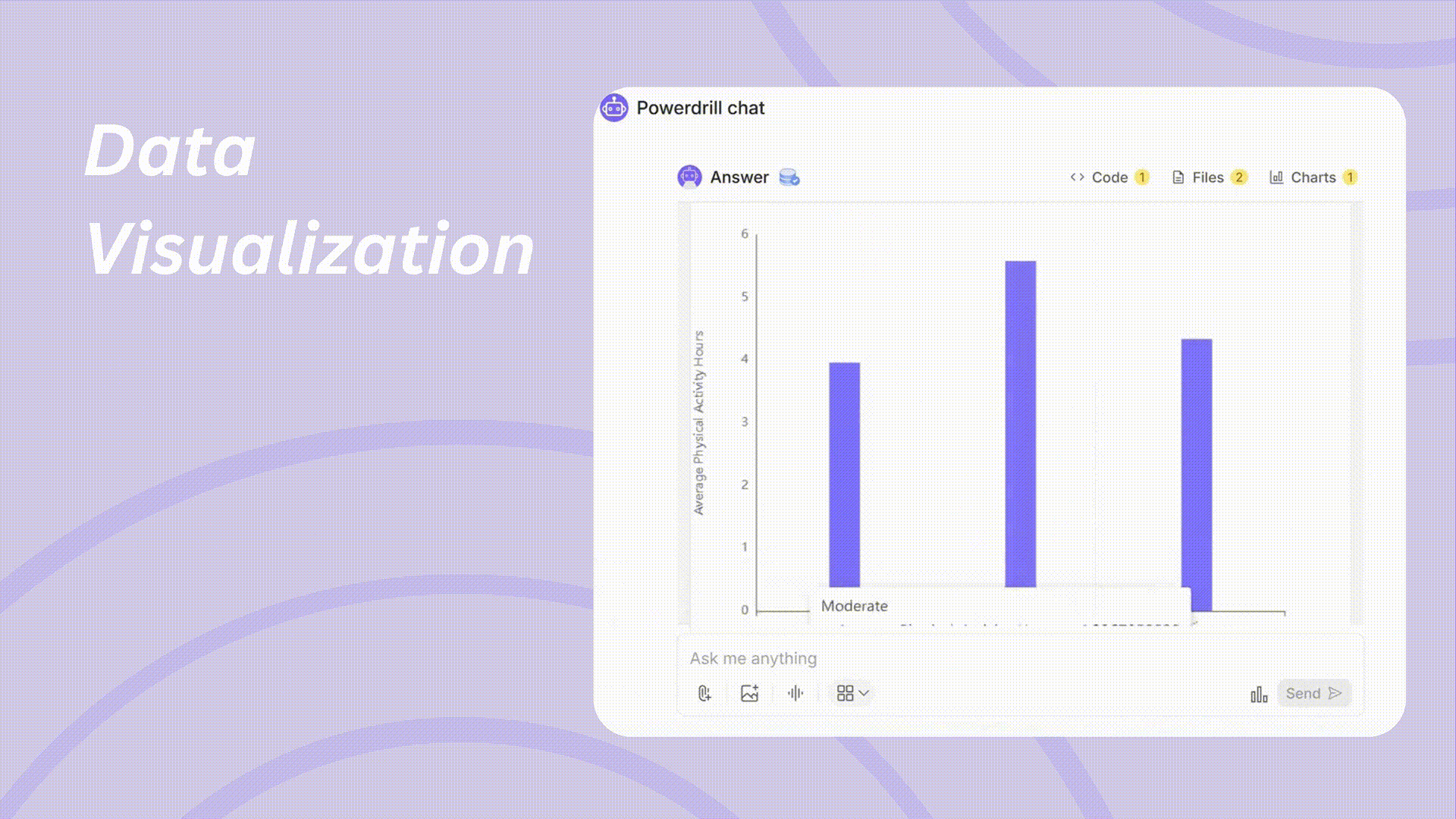
可視化はデータを理解し、研究結果を効果的に伝えるために不可欠です。Powerdrillは最小限の労力で高品質なビジュアルを作成できます。
多様なグラフの種類: 棒グラフ、円グラフ、散布図、折れ線グラフ、箱ひげ図など、さまざまなデータタイプと分析ニーズに適したグラフを提供します。
インタラクティブ機能: 動的なフィルタリング、ズーム、カスタマイズが可能で、特定のオーディエンスやプレゼンテーションスタイルに合わせてビジュアルを調整できます。
カスタマイズ可能なデザイン: 学術、企業、または出版の基準に合わせて、色やグラフの種類を変更できます。
エクスポートオプション: 高解像度形式(PNG)でビジュアルをエクスポートでき、レポートやプレゼンテーションにシームレスに統合できます。
5. 自動レポート作成
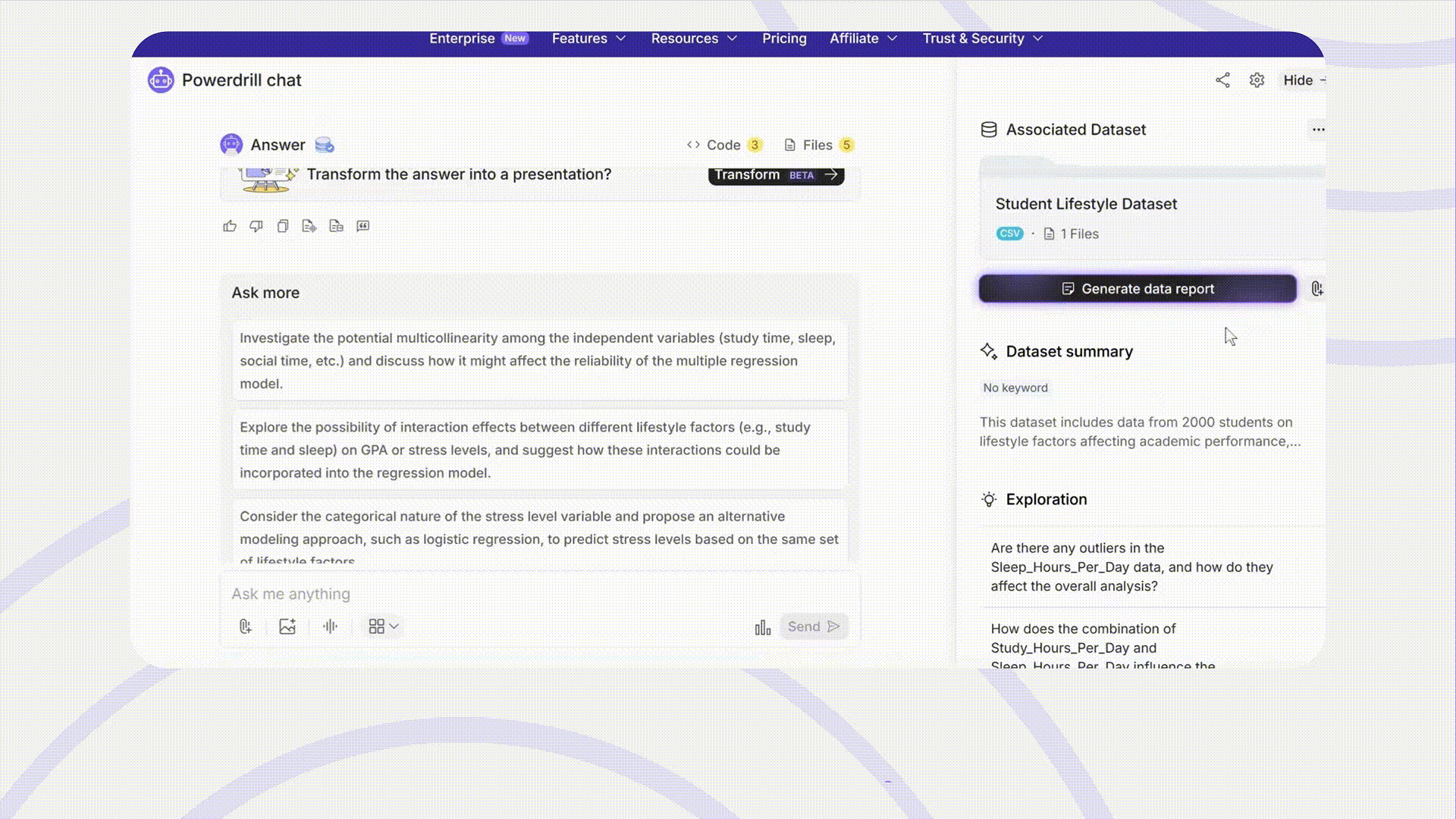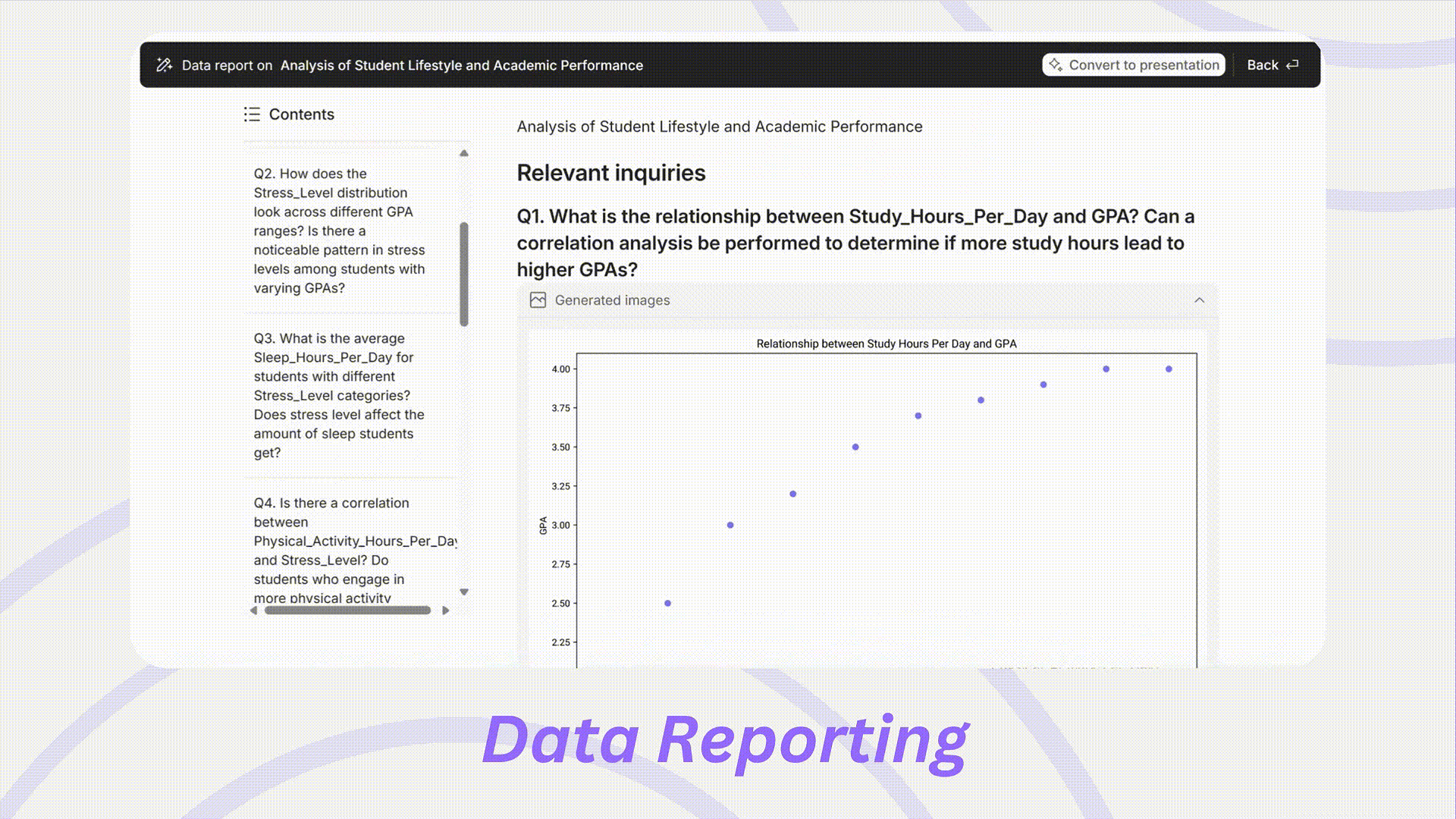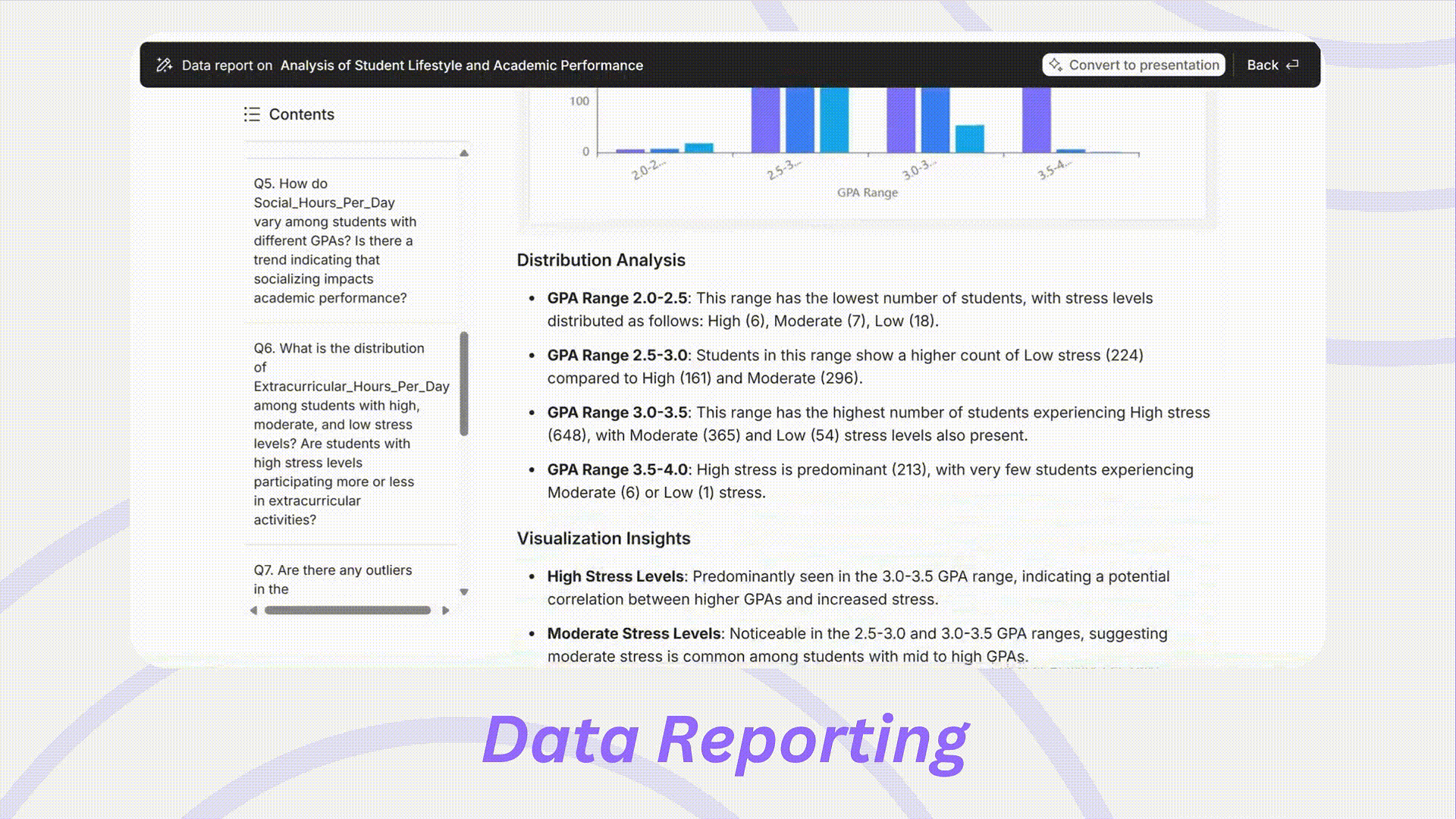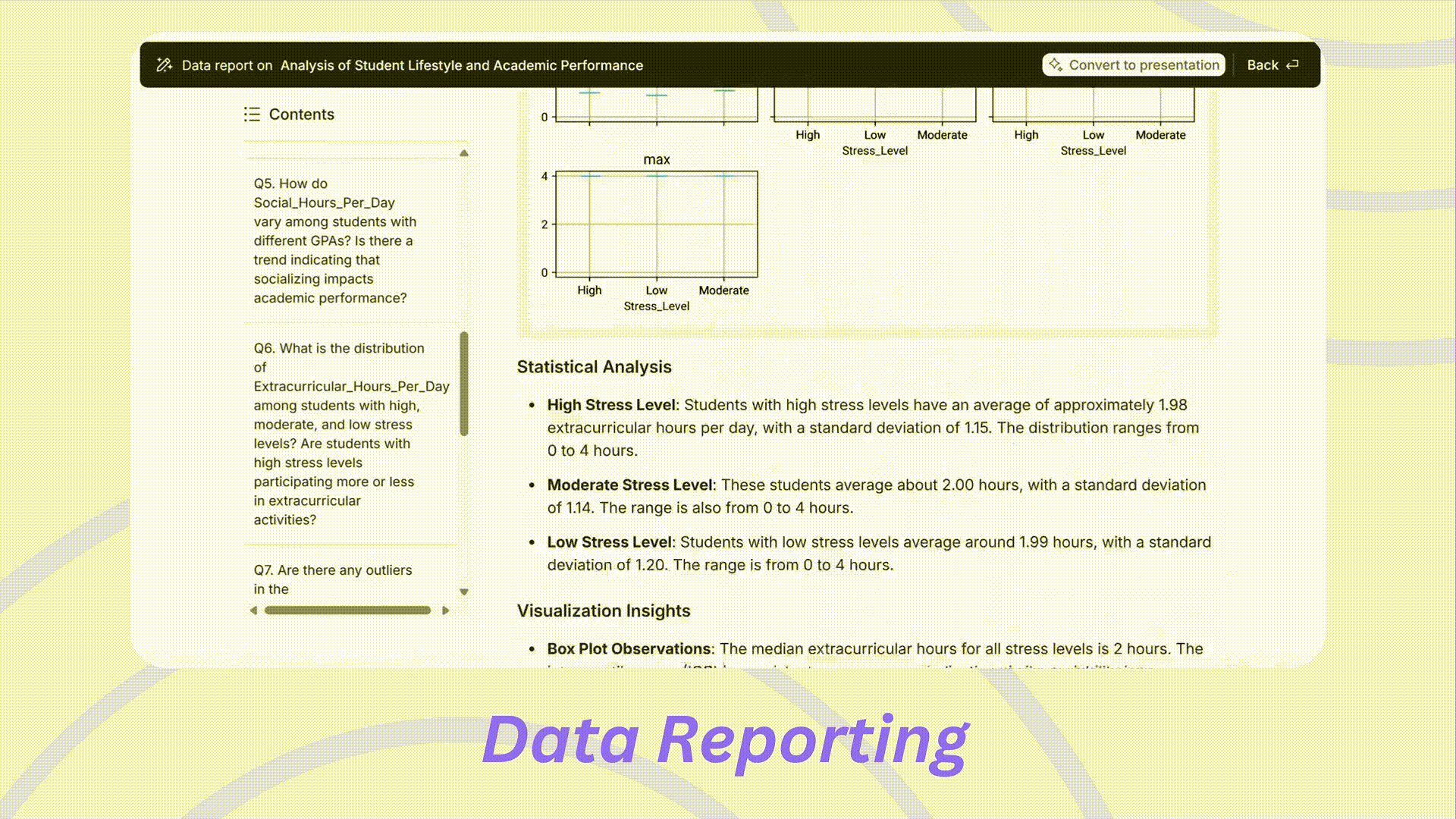
研究結果の要約は、最も手間のかかる作業の一つになりがちです。Powerdrillは、提出やプレゼンテーションの準備ができた包括的なレポートを生成します。
エグゼクティブサマリー: データセットの内容とデータの全体的な文脈を明確に説明することに焦点を当てており、ユーザーがその目的と構造を素早く理解するのに役立ちます。
可視化: グラフやその他の視覚補助をレポートに直接統合し、ユーザーが結果をより直感的に解釈できるようにし、プレゼンテーションの質を高めます。
要約されたインサイト: データから導き出された主要なインサイトを提供し、ナラティブを構築し、主要な発見を効果的に強調するのを容易にします。
6. 比類のないデータセキュリティ
研究において、データのプライバシーとセキュリティは最重要事項です。Powerdrillは厳格なセキュリティプロトコルに準拠しています。
暗号化標準: すべてのデータは保存中および転送中に暗号化され、不正アクセスから保護されます。
アクセス制御: ユーザー固有のアクセス設定を提供し、プロジェクトを閲覧または編集できるユーザーを定義できます。
コンプライアンス認証: GDPR、HIPAA、その他の規制基準に準拠しており、機密性の高い研究データにも適しています。
7. 生産性向上を目的とした追加機能
Powerdrillは、従来のデータ分析ツールを超える機能を提供します。
公開データセットリソース: ユーザーがプロジェクトや研究のために様々な公開データセットにアクセスできるように支援します。これらのデータセットは、研究、データ分析、機械学習、その他のデータ駆動型タスクに利用できます。
AIによるレコメンデーション: データに基づいて最適な統計検定、可視化タイプ、または分析アプローチを提案します。
継続的な更新: ユーザーフィードバックと進化する研究ニーズに基づいて、新機能や更新を定期的に導入しています。
多言語対応: 複数の言語でインターフェースとドキュメントを提供し、世界中のユーザーが利用できるようにしています。
モバイル対応: モバイルデバイスから結果の確認、データの分析、チャットの継続が可能です。
Powerdrillの包括的な機能スイートは、データ準備から最終レポート作成まで、研究プロセスのあらゆる段階が効率性、正確性、および使いやすさのために最適化されていることを保証します。研究を始めたばかりの学生であろうと、複雑なデータセットに取り組むベテラン研究者であろうと、Powerdrillは量的分析における最高のパートナーとなるでしょう。
今日から研究を加速させましょう

量的研究は overwhelming (圧倒的)である必要はありません。Powerdrillを使えば、煩雑なデータセットのクリーンアップから、実用的なインサイトの生成まで、プロセスのあらゆるステップに自信を持って取り組むことができます。
データ分析に時間を取られることなく、今日からPowerdrillで研究を始め、あなたの研究を成果に変えましょう。
よくある質問 (FAQ)
量的研究とは何ですか?
量的研究とは、データを定量化し、統計分析を適用して意味のある結論を導き出すことに焦点を当てた調査手法です。アンケート、実験、その他の構造化された方法を通じて数値データを収集し、それを分析してパターン、関係性、または傾向を特定します。このアプローチは、社会科学、自然科学、ビジネスなどの分野で広く使用されています。
記述統計とは何ですか?
記述統計とは、データセットの基本的な特徴を要約し、記述するための統計ツールです。中心傾向の尺度(平均値、中央値、最頻値)、ばらつき(範囲、標準偏差)、分布(度数、歪度)など、データに関する簡単な要約を提供します。記述統計は、研究者がさらに分析を進める前に、データの全体的な特徴を理解するのに役立ちます。
推測統計とは何ですか?
推測統計は、データを記述するだけでなく、標本に基づいて母集団に関する予測や推論を行うものです。仮説検定、信頼区間、回帰分析などの手法が含まれます。推測統計は、観察されたパターンが統計的に有意であるかどうかを判断し、手元のデータを超えて結論を導き出すために使用されます。
記述統計と推測統計の違いは何ですか?
記述統計はデータを要約し整理し、その特徴の明確な概要を提供します。対照的に、推測統計はデータを分析して、より大きな母集団に関する予測や結論を導き出します。記述統計が「何であるか」を扱うのに対し、推測統計は「何が起こりうるか」または「何が起こりそうか」に焦点を当てます。
アンケートの量的データを分析する方法は?
アンケートの量的データを分析するには、いくつかのステップがあります。
データクレンジング: 欠損値、重複、または不整合に対処し、データセットを確認しクリーンアップします。
記述分析: 度数、パーセンテージ、平均などの尺度を使用してデータを要約します。
推測分析: カイ二乗検定や回帰モデルなどの統計検定を適用して、関係性を探索し、仮説を検証します。
可視化: グラフや図を作成して、結果を視覚的に提示します。
解釈: 分析から意味のある結論を導き出し、レポートや論文で発見を明確に伝えます。