カイ二乗検定をPowerdrill AIで手軽に実施する方法

カイ二乗検定は統計分析の基礎となるものであり、研究、社会科学、生物学などの分野で広く利用されています。従来、この検定を行うには、統計的手法やコーディングスキルに関する深い理解が必要でした。しかし、Powerdrill AIのようなツールを使えば、事前の専門知識がない人でも、直感的な対話を通じて正確で信頼性の高いカイ二乗検定を実施できます。このガイドでは、カイ二乗検定について知っておくべきことすべてと、Powerdrillがいかにそのプロセスを簡素化し、学生、研究者、学者にとって利用しやすいものにしているかを紹介します。
カイ二乗検定とは?
カイ二乗検定 (χ²) は、データセット内のカテゴリ変数間に有意な関連性があるかどうかを判断するために使用される統計的手法です。観測されたデータと期待される結果を比較することで、差異が偶然によって生じた可能性を評価します。
基本原理
カイ二乗検定は、データの異なるカテゴリにおける観測度数と、特定の仮説の下での期待度数との比較に基づいています。観測度数と期待度数の二乗差を期待度数で割った値を合計することで、カイ二乗統計量を計算します。カイ二乗統計量の計算式は以下の通りです。
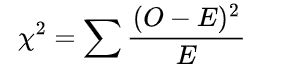
ここで、Oは観測度数を、Eは期待度数を表します。
カイ二乗検定の種類
独立性のカイ二乗検定:
2つのカテゴリ変数が独立しているかどうかを判断するために使用されます。
目的: 2つのカテゴリ変数間に関係があるかどうかを判断するため。一方の変数の出現がもう一方の変数の出現から独立しているかどうかをチェックします。
例: 性別と特定の種類の音楽への好みとの間に関係があるかどうかを調査する場合。「性別と音楽の好みは独立している」が帰無仮説であり、「独立していない」が対立仮説となります。
適合度のカイ二乗検定:
サンプルが母集団の分布と一致するかどうかを判断します。
目的: 観測されたデータセットが、正規分布、ポアソン分布、二項分布などの特定の理論的分布に従っているかどうかをテストするため。
例: 1時間あたりの来店客数がポアソン分布に従っているかどうかをチェックする場合。「データが仮説されたポアソン分布に従っている」が帰無仮説であり、「従っていない」が対立仮説となります。
同一性のカイ二乗検定:
カテゴリ変数の分布が異なる母集団やグループで同じであるかどうかをテストするために使用されます。
目的: カテゴリ変数の分布が異なる母集団やグループ間で同じであるかどうかをテストするため。
例: 異なる民族グループ間の血液型の分布を比較する場合。「血液型の分布はすべての民族グループで同じである」が帰無仮説であり、「グループ間で分布に違いがある」が対立仮説となります。
カイ二乗検定をいつ使用するか
カイ二乗検定は、以下のような場合に使用できます。
カテゴリデータの分析時: データが性別、好み、教育レベルなどのカテゴリに分類されている場合。
関係性の検証時: 2つの変数間に関係があるかどうかをテストしたい場合(例:年齢層と製品の好み)。
比率の確認時: 観測度数が期待度数と一致するかどうかを確認したい場合。
前提条件
データはカテゴリデータであること。
サンプルサイズが十分大きいこと。
観測値は独立していること。
各カテゴリの期待度数が5以上であること。
適用シナリオ
医学研究: リスク因子と疾患発生の関連性を分析するために使用できます。例えば、喫煙と肺がんの間に相関関係があるかどうかや、異なる治療法の有効性を比較する際などです。
社会科学研究: 社会現象に関する調査において、教育レベルと所得レベルの関係、あるいは異なる年齢層間での政治的態度の違いといった変数間の関係を分析できます。
市場調査: 消費者の特性と消費行動の関連性を理解するのに役立ちます。例えば、性別と特定の製品への好みの間に関連があるか、あるいは異なる地域で様々なブランドの市場シェアが均等に分布しているかを分析する際などです。
カイ二乗検定の実施方法
カイ二乗検定の実施にはいくつかのステップが含まれます。カイ二乗検定を計算するための一般的な手順は以下の通りです。
仮説の定式化
帰無仮説 (H₀): 検定対象の変数間に有意な関連性や差がないと仮定します。例えば、分割表における独立性の検定では、H₀は行変数と列変数が独立しているという仮説です。
対立仮説 (H₁): 帰無仮説の反対です。有意な関連性や差があると主張します。
分割表の作成 (該当する場合)
カテゴリデータを扱う場合は、データを分割表に整理します。行は一方のカテゴリ変数、列はもう一方のカテゴリ変数を表します。表の各セルには、対応するカテゴリの組み合わせの観測度数Oが含まれます。
期待度数Eの計算
帰無仮説が真であるという仮定の下で、分割表の各セルについて期待度数を計算します。r行c列の分割表における期待度数Eᵢⱼの計算式はEᵢⱼ = (i行目の合計 × j列目の合計) / 総サンプルサイズ です。ここで、Rᵢはi行目の合計、Cⱼはj列目の合計、Nは総サンプルサイズを表します。
カイ二乗統計量χ²の計算
χ² = Σᵢⱼ[(Oᵢⱼ − Eᵢⱼ)² / Eᵢⱼ] の式を使用します。表の各セルについて、観測度数Oᵢⱼと期待度数Eᵢⱼの差を計算し、その差を二乗し、期待度数で割ります。そして、これらの値をすべてのセルで合計します。
自由度dfの決定
カイ二乗検定の自由度は、データの構造に依存します。分割表の場合、df = (行数 − 1) × (列数 − 1) です。適合度検定の場合、df = カテゴリ数 − 推定されたパラメータ数 − 1 です。
p値または臨界値の特定
p値: 統計ソフトウェアまたはカイ二乗分布表を使用して、計算されたχ²統計量と自由度に対応するp値を見つけます。p値は、帰無仮説が真であると仮定した場合に、計算されたχ²統計量と同等か、より極端なχ²統計量が得られる確率です。
臨界値: 与えられた自由度と選択された有意水準(一般的にα=0.05または0.01)について、カイ二乗分布表で臨界値を調べます。
意思決定
p値が有意水準αより小さい場合、帰無仮説を棄却し、有意な関連性または差があると結論付けます。計算されたχ²統計量が臨界値より大きい場合も、同様に帰無仮説を棄却します。そうでない場合、帰無仮説を棄却しません。
カイ二乗検定の計算例
具体的な例を用いて計算プロセスを分解してみましょう。
例: 独立性の検定
性別と飲料の好み(紅茶 vs コーヒー)の間に関連性があるかを判断するために200人を調査しました。データは以下の通りです。
紅茶 (Tea) | コーヒー (Coffee) | 合計 (Total) | |
|---|---|---|---|
男性 (Male) | 80 | 20 | 100 |
女性 (Female) | 40 | 60 | 100 |
合計 (Total) | 120 | 80 | 200 |
ステップ1: 期待度数の計算
各セルについて:
期待度数 = (行の合計 × 列の合計) / 総計
男性-紅茶の場合:
期待度数 = (100 × 120) / 200 = 60
男性-コーヒーの場合:
期待度数 = (100 × 80) / 200 = 40
すべてのセルについて、この計算を続けます。
紅茶 (Tea) | コーヒー (Coffee) | |
|---|---|---|
男性 (Male) | 60 | 40 |
女性 (Female) | 60 | 40 |
ステップ2: 式の適用
χ² = Σ[(O – E)² / E] の式を使用します。
男性-紅茶: (80 - 60)² / 60 = 20² / 60 = 400 / 60 = 6.67
男性-コーヒー: (20 - 40)² / 40 = (-20)² / 40 = 400 / 40 = 10.00
女性-紅茶: (40 - 60)² / 60 = (-20)² / 60 = 400 / 60 = 6.67
女性-コーヒー: (60 - 40)² / 40 = 20² / 40 = 400 / 40 = 10.00
χ² = 6.67 + 10.00 + 6.67 + 10.00 = 33.34
ステップ3: χ²と臨界値の比較
自由度 df = (行数 - 1) × (列数 - 1) = (2 - 1) × (2 - 1) = 1
df = 1、α = 0.05 のカイ二乗分布表を使用すると、臨界値は3.84です。 33.34 > 3.84 であるため、帰無仮説を棄却します。これは、性別と飲料の好みには関連性があることを示しています。
p値とは?
定義
p値とは、帰無仮説が真であるという前提の下で、観測されたサンプル結果またはそれよりも極端な結果が得られる確率です。カイ二乗検定においては、観測データと理論データとの間に差がない(すなわち、帰無仮説が真である)と仮定した場合に、計算されたカイ二乗統計量およびそれよりも極端な値が得られる確率を指します。
計算原理
カイ二乗検定におけるp値の計算は、カイ二乗分布に基づいています。カイ二乗統計量χ²が計算された後、自由度とカイ二乗分布の確率密度関数に基づいてp値が決定されます。自由度は、データの分類やサンプルサイズなどの要因に依存します。一般的に言えば、自由度が大きいほど、カイ二乗分布曲線は右にシフトし、同じカイ二乗値に対応するp値は異なる場合があります。計算されたカイ二乗統計量と自由度から、統計ソフトウェアまたはカイ二乗分布表を参照することで、対応するp値を見つけることができます。
p値の機能と重要性
機能と重要性
証拠の強さの指標: p値は、サンプルデータが帰無仮説をどの程度支持または反対しているかを示す指標となります。p値が小さいほど、帰無仮説が真であるという前提の下で、現在のサンプル結果またはそれよりも極端な結果が得られる可能性は低くなります。これは、サンプルデータが帰無仮説に対するより強い証拠を提供していることを意味し、観測データと理論データとの間の差がより有意であることを示します。
意思決定の根拠: 仮説検定では、通常、事前にα(有意水準、例えば0.05または0.01)を設定します。p値はこのαと比較され、意思決定が行われます。もしp値がαより小さい場合、帰無仮説は棄却され、観測データと理論データとの間に有意な差があることが示されます。もしp値がαより大きい場合、帰無仮説は棄却されず、観測データと理論データとの間に差があるという十分な証拠がないことを意味します。
例
例えば、ある薬が効果的かどうかを研究するカイ二乗検定において、帰無仮説は「薬は効果がない」(すなわち、薬剤群と対照群の回復率に差がない)とします。データを収集して計算した結果、カイ二乗値に対応するp値が0.02であったとします。もしαを0.05に設定した場合、p値(0.02)がα(0.05)より小さいため、帰無仮説は棄却され、「薬は効果がある」(すなわち、薬剤群と対照群の回復率に有意な差がある)と判断されます。この0.02というp値は、薬が効果がないという仮定の下で、現在のサンプルにおける薬剤群と対照群の回復率の差、およびそれよりも極端な差が得られる確率がわずか2%であることを意味します。
カイ二乗検定のp値を計算する方法
p値は、帰無仮説が真である場合にその結果が観測される確率を示します。Powerdrill AIはp値を直接計算できますが、手動で計算する場合は次のアプローチを使用できます。
χ²を計算する。
自由度dfを特定する。
カイ二乗分布表またはソフトウェアを使用してp値を見つける。
p値 < 有意水準α の場合、帰無仮説を棄却します。
Powerdrill AI: カイ二乗検定計算機
Powerdrill AIは、手動での計算やコーディングの必要性を排除し、カイ二乗検定の全プロセスを効率化します。
Powerdrill AIを使用してカイ二乗検定を実行する方法をデモンストレーションするために、Kaggleの「子供の貧血レベルに影響を与える要因」データセットを利用します。このデータセットは、様々な社会経済的要因と0〜59ヶ月の子供の貧血レベルとの潜在的な関係に関する情報を提供しています。
Powerdrillでカイ二乗検定を使用する方法は次のとおりです。
ステップ1: データセットのアップロード
まず、CSV、XLSXなどのデータファイルをPowerdrillにアップロードします。
Powerdrill AIアカウントにログインします。
データセットアップロードセクションに移動します。
クリーンアップされたデータファイル(例:CSV形式)をアップロードします。
Powerdrillがデータを同期して処理するのを待ちます。
ステップ2: データクレンジング
分析の前には、欠損値の処理、重複の削除、一貫性の確保のためにデータをクリーンアップすることが重要です。このプロセスには以下が含まれる場合があります。
欠損値やヌル値を適切に処理する。
カテゴリ変数が正しくエンコードされていることを確認する。
関連性のない情報や冗長な情報を削除する。
幸いなことに、Powerdrillはデータクレンジングを自動化できます。
ステップ3: 仮説の定式化
データセットに基づいて、以下のような関係性を仮説として設定できます。
帰無仮説 (H₀): 母親の教育レベルと子供の貧血状態の間に関連性はない。
対立仮説 (H₁): 母親の教育レベルと子供の貧血状態の間に関連性がある。
ステップ4: Powerdrill AIでのカイ二乗検定の実行
Powerdrillのダイアログボックスに、自然言語でクエリを入力します。例えば:
"Analyze the relationship between mothers' education level and children's anemia status using a Chi-squared test." (母親の教育レベルと子供の貧血状態の関係をカイ二乗検定を使って分析してください。)
Powerdrillはこのリクエストを処理し、カイ二乗検定を実行し、カイ二乗統計量、自由度、p値を含む結果を提供します。
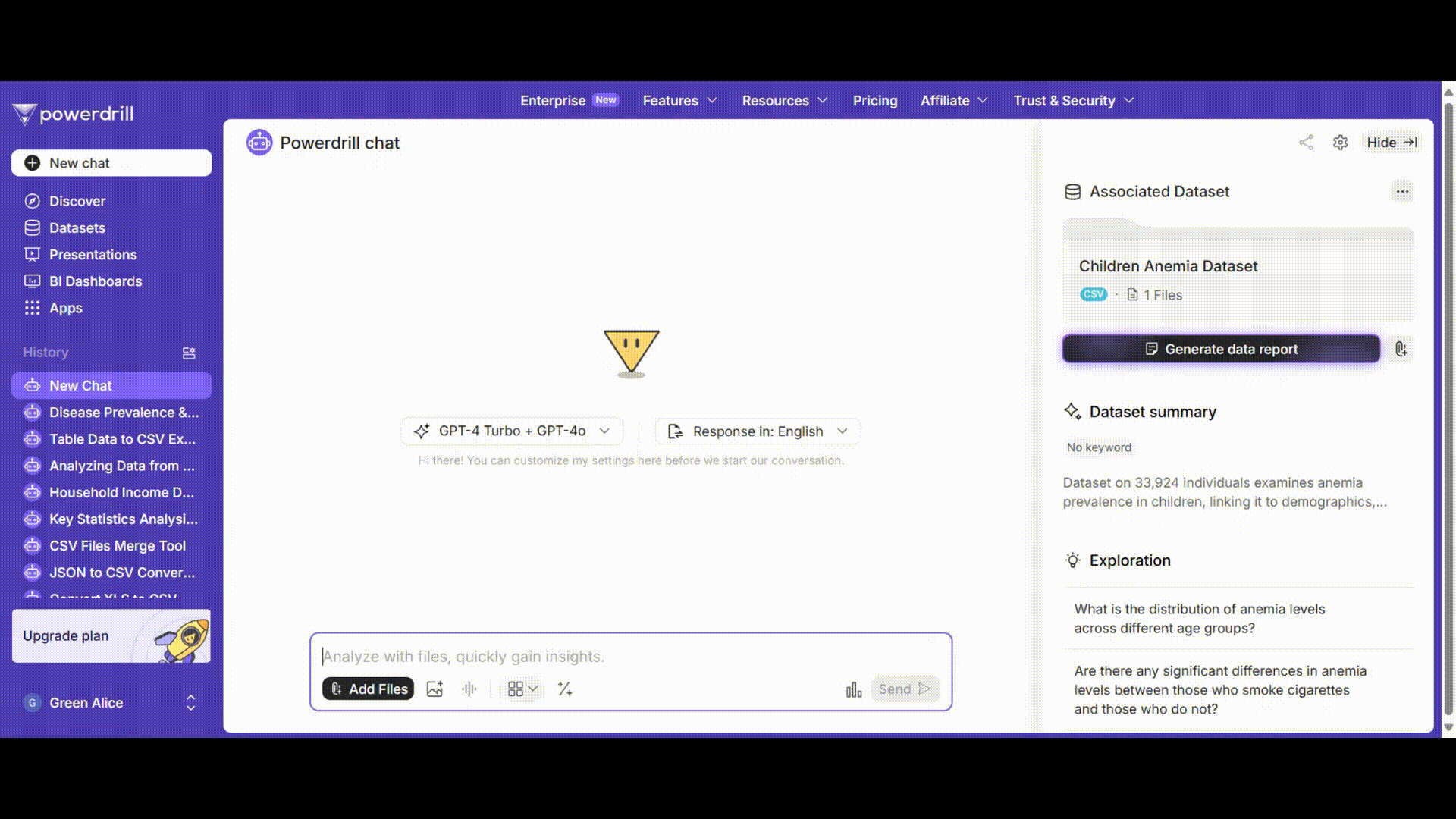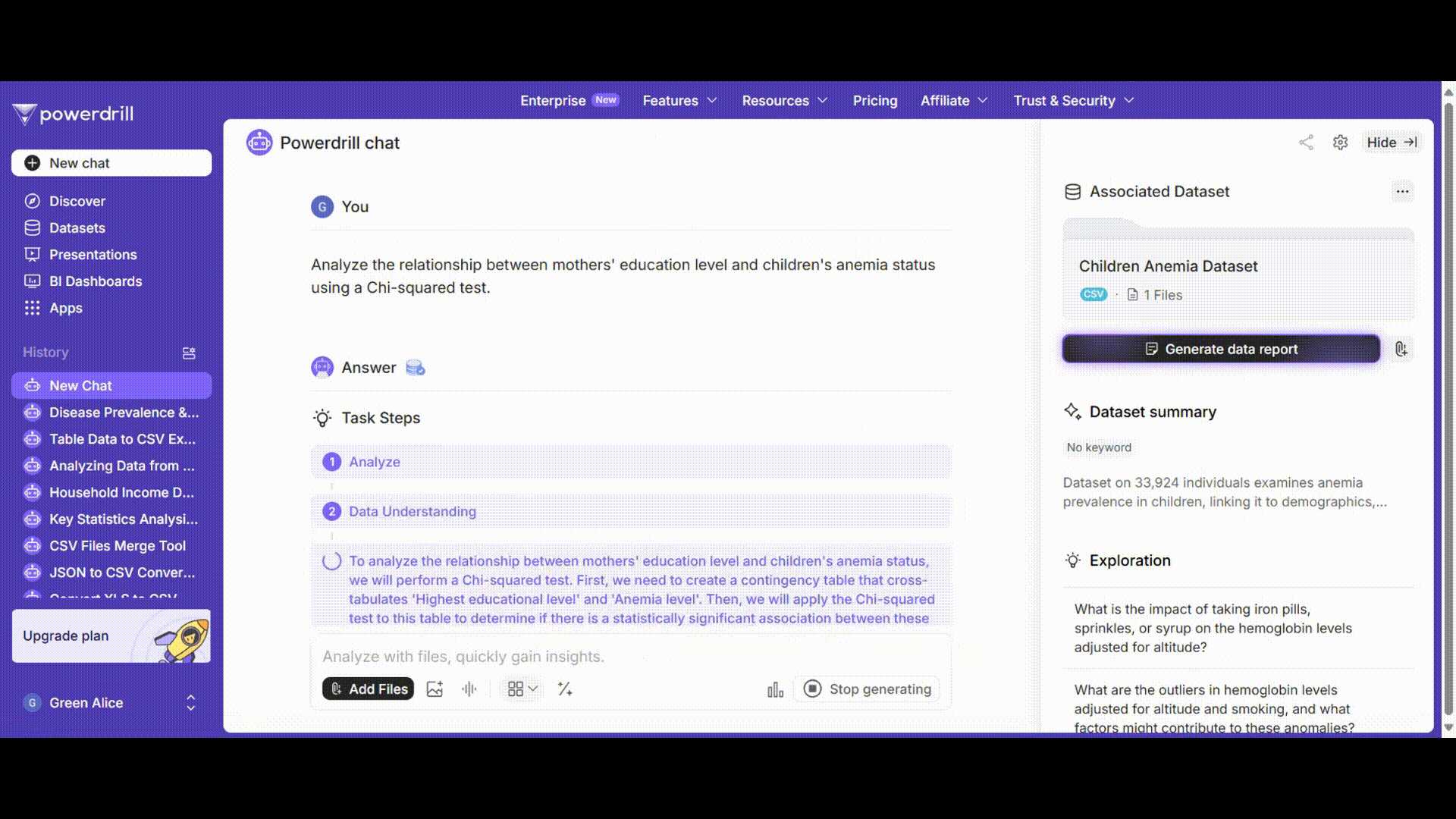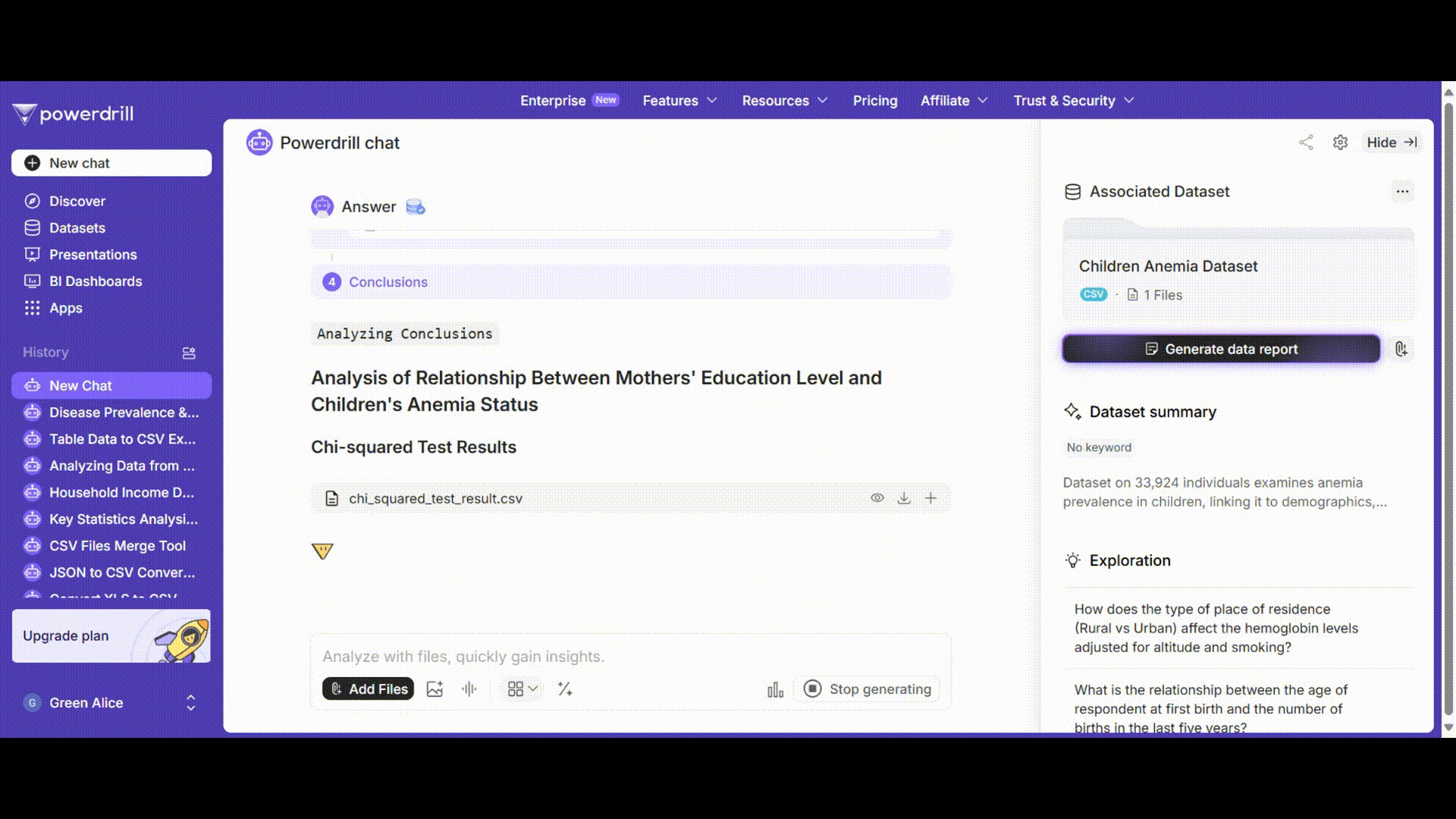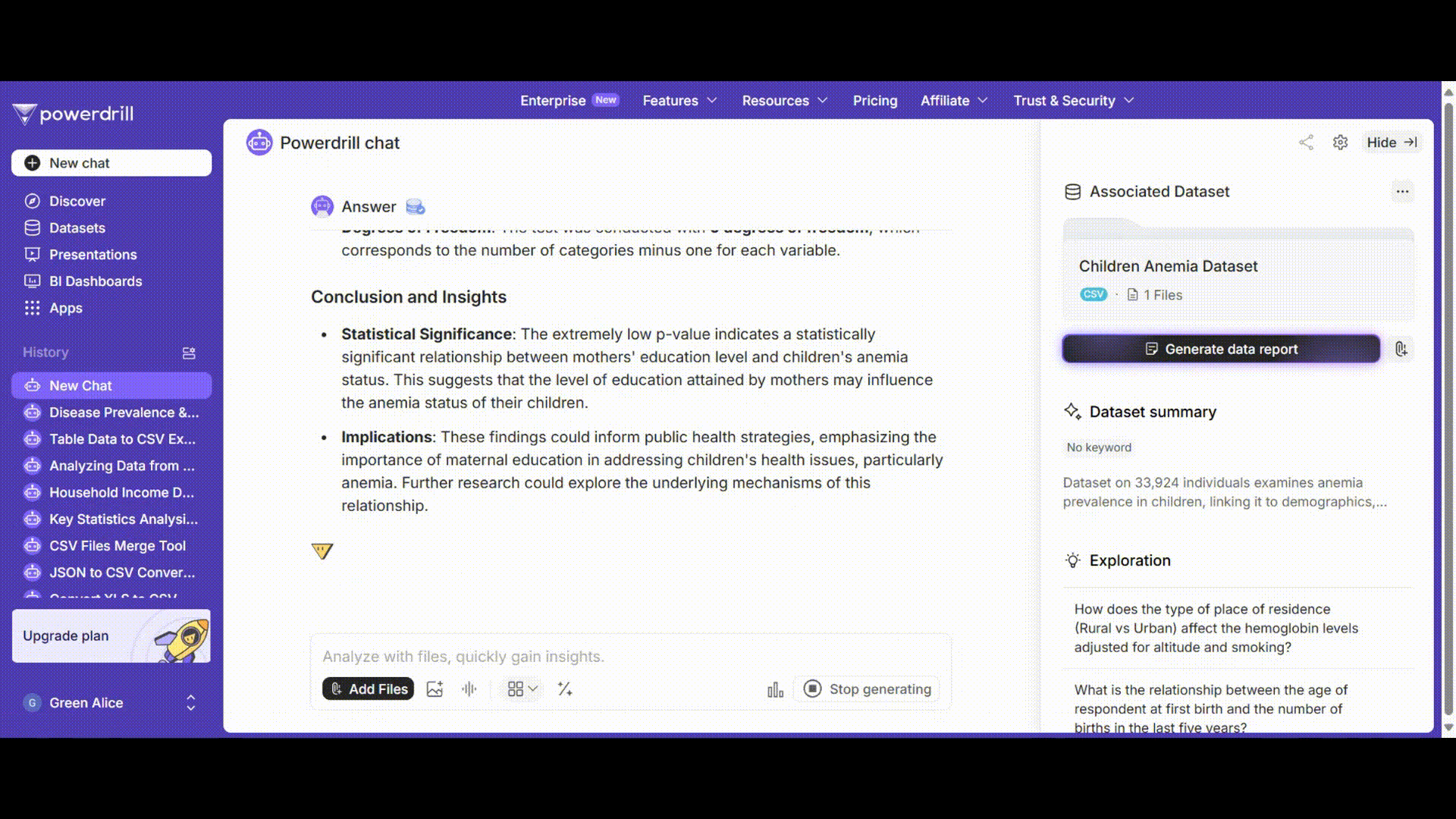
ステップ5: 結果の解釈
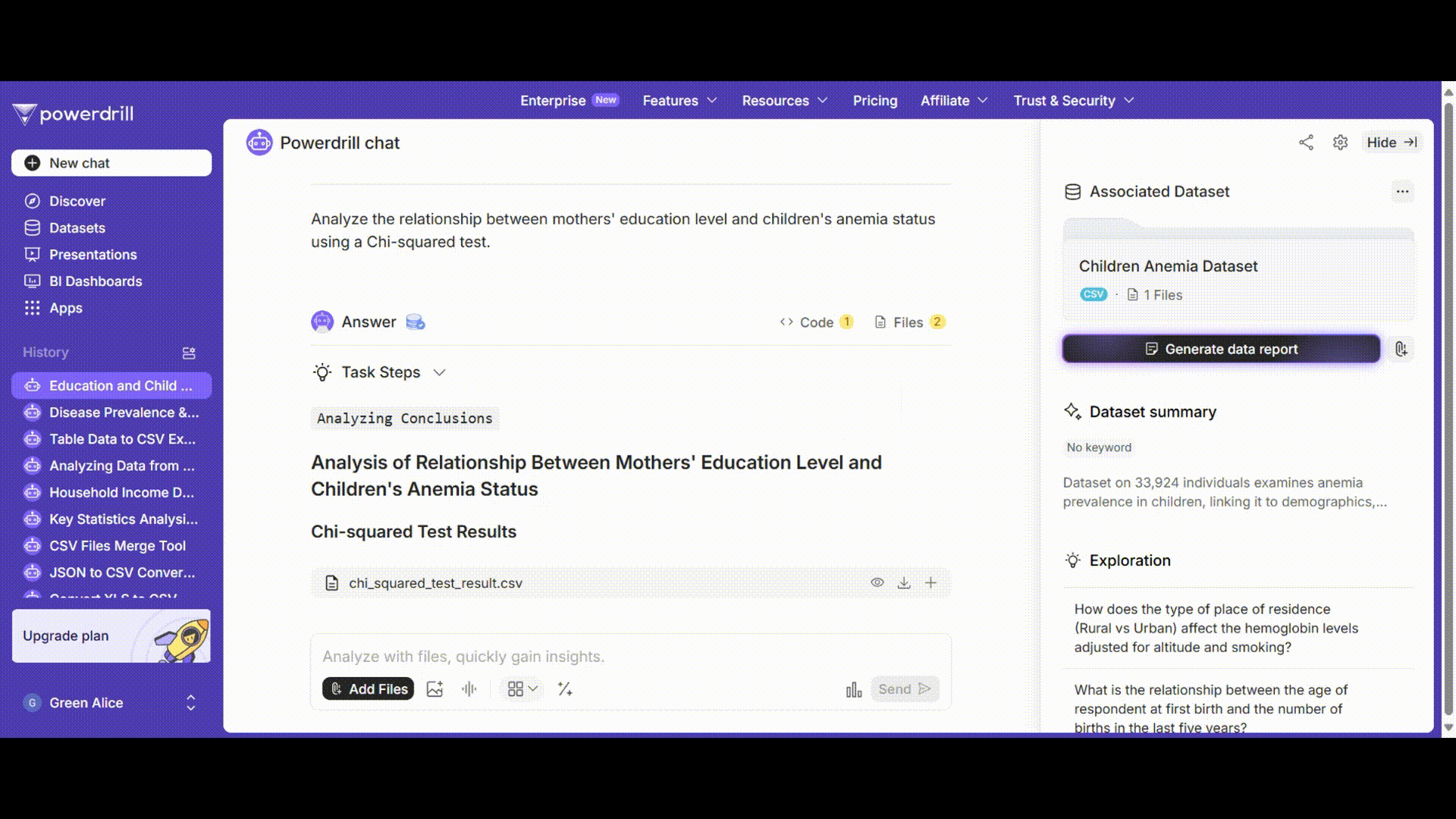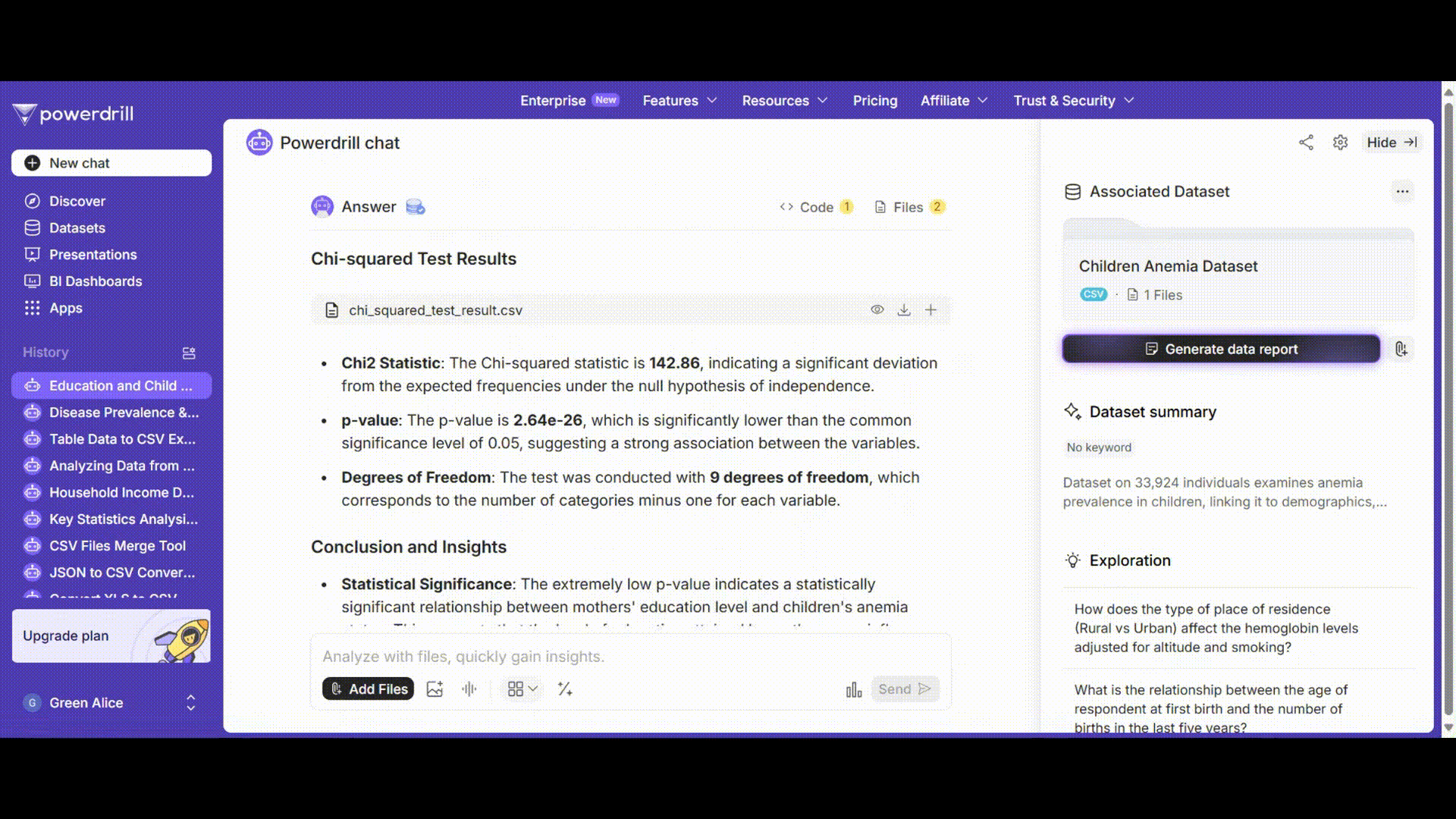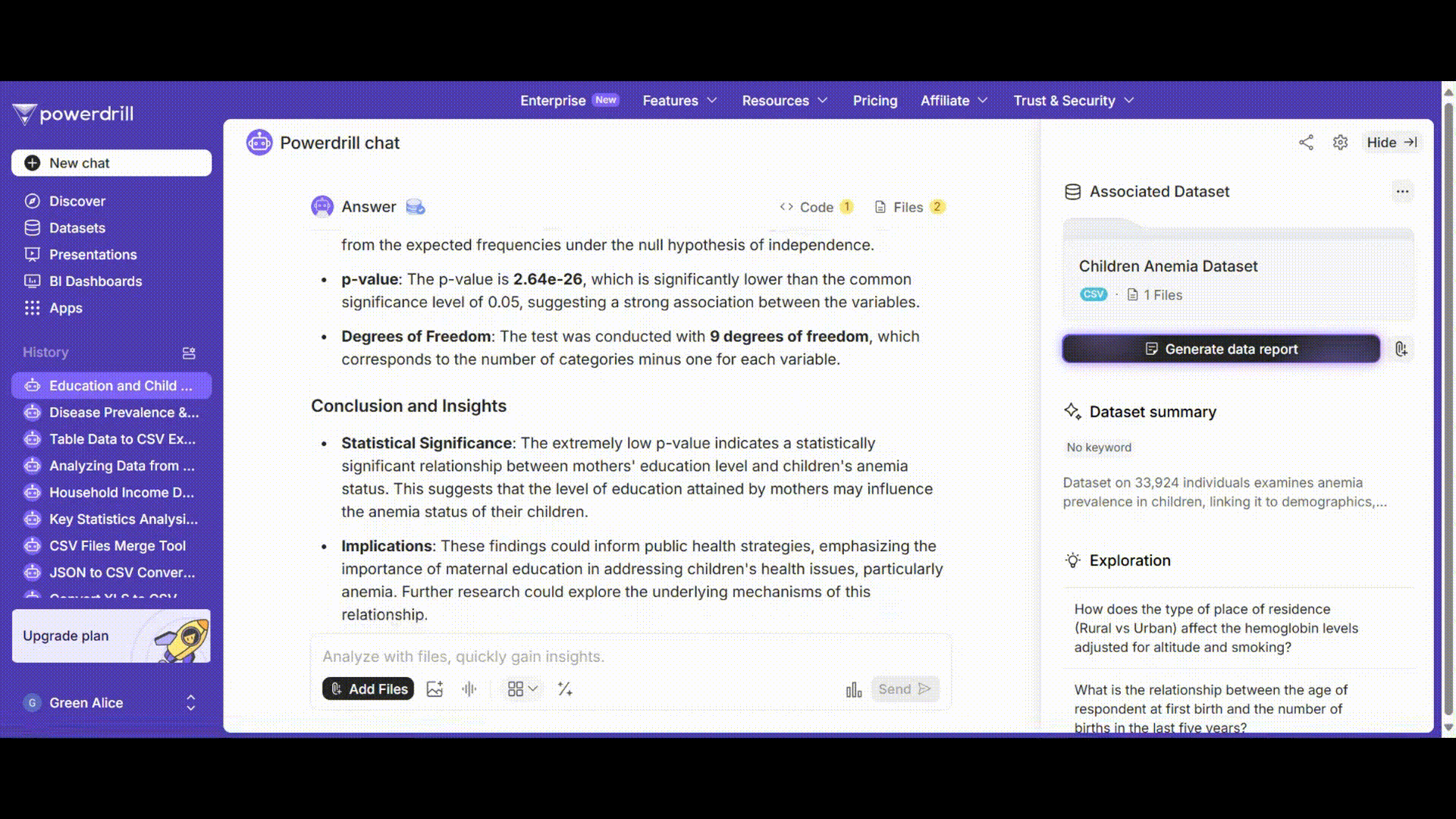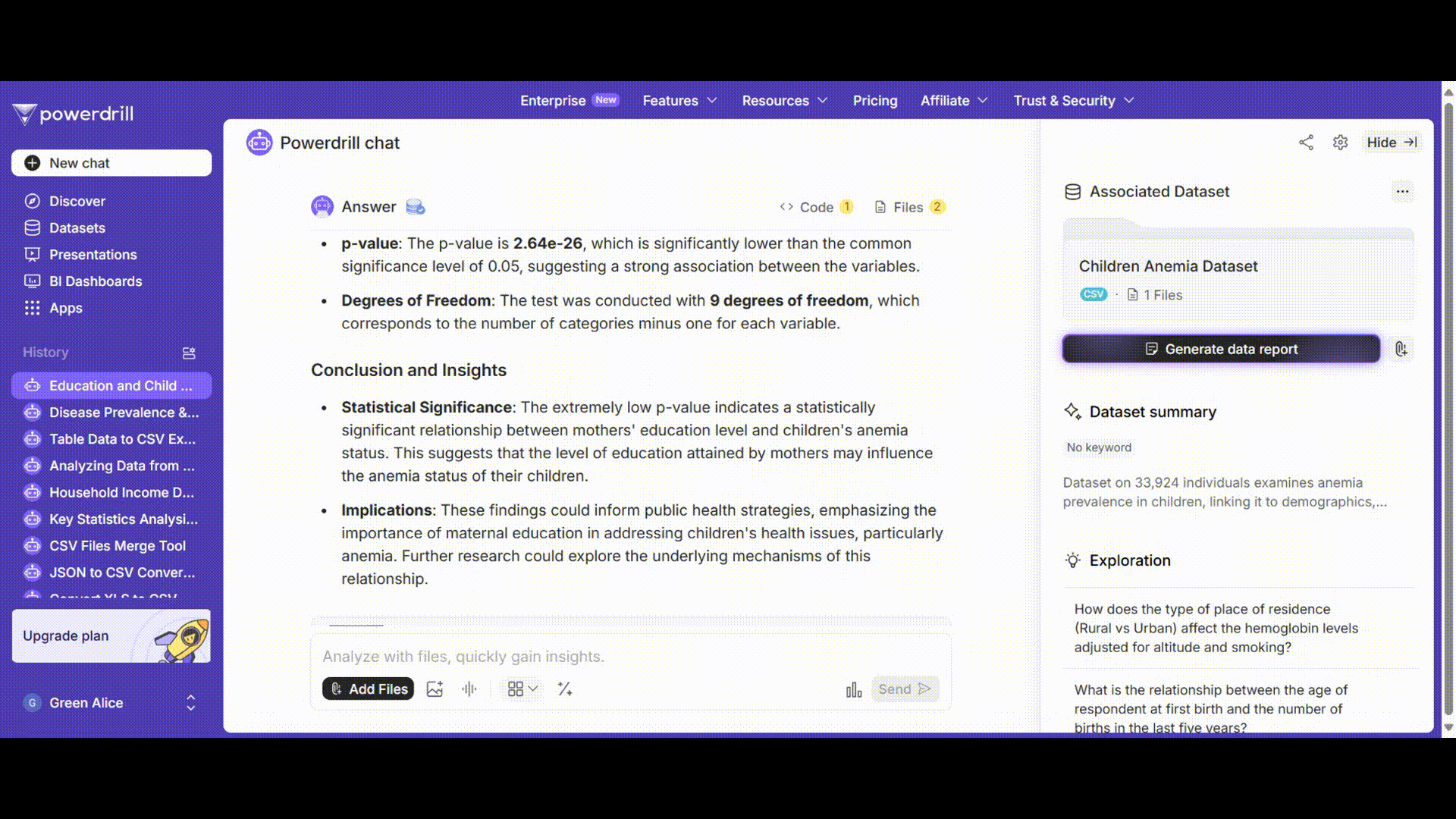
Powerdrillは結果を解釈とともに表示します。例えば:
カイ二乗統計量 χ²: 142.86
自由度 df: 9
p値: 2.64e-26 (<0.05)
有意水準αを0.05とした場合、p値がαより小さいため、帰無仮説を棄却します。これは、母親の教育レベルと子供の貧血状態の間に有意な関連性があることを示しています。
これらの手順に従うことで、Powerdrill AIを効果的に使用して「子供の貧血レベルに影響を与える要因」データセットでカイ二乗検定を実行できます。このプロセスは複雑な統計分析を簡素化し、高度なコーディングや統計の専門知識を必要とせずに利用可能にします。
今すぐ時間を節約しましょう!
データ分析を簡素化する準備はできましたか?今すぐPowerdrillを試して、カイ二乗検定のような高度な統計テストを誰にでもアクセスしやすいものにしましょう。データセットをアップロードし、質問を入力するだけで、すぐに洞察を得ることができます。
よくある質問
Powerdrillを使用するために統計の知識は必要ですか?
いいえ、Powerdrillはすべての人向けに設計されています。データをアップロードし、自然言語で質問するだけで使えます。
Powerdrillは大規模なデータセットに対応できますか?
はい、Powerdrillは何百万行ものデータセットを処理し、効率的に結果を提供できます。
どのような種類のファイルをアップロードできますか?
PowerdrillはCSV、XLSX、TSVなど、様々なファイル形式をサポートしています。
Powerdrillの計算は信頼できますか?
もちろんです。Powerdrillは使用されたPythonコードとデータソースを表示することで、完全な透明性を提供しています。