Prédiction des Relations pour la Complétion de Graphes de Connaissances avec les Modèles de Langage Large

Thème Central
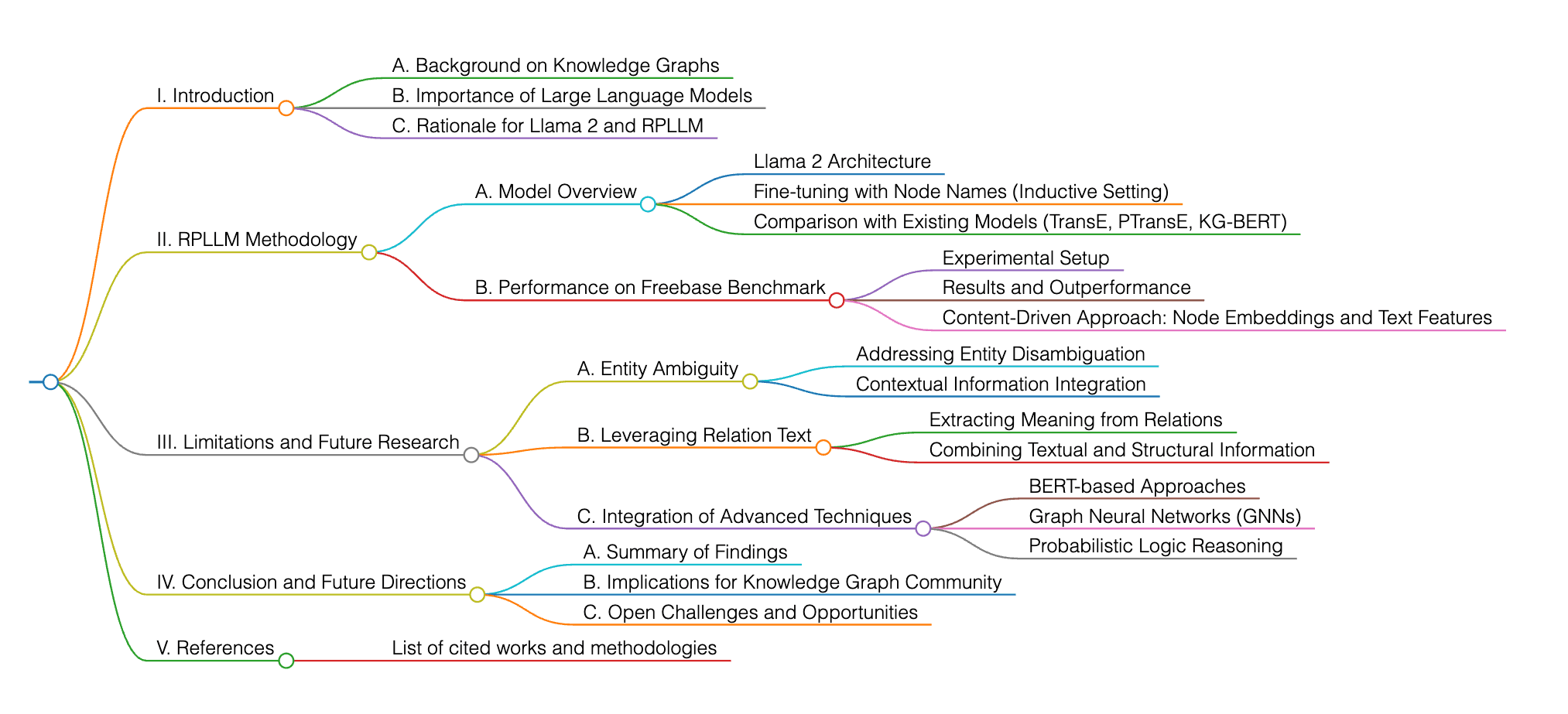
Cet article examine l’utilisation des grands modèles de langage, en particulier Llama 2, pour la complétion de graphes de connaissances, avec un focus sur la prédiction des relations. Il présente RPLLM, qui affine le modèle avec les noms des nœuds afin de gérer des scénarios inductifs, et qui surpasse des modèles existants tels que TransE, PTransE et KG-BERT sur le benchmark Freebase. L’étude met en avant le potentiel des approches basées sur le contenu, utilisant à la fois les embeddings des nœuds et les caractéristiques textuelles, pour améliorer la précision des graphes de connaissances. Les perspectives futures suggèrent de traiter certaines limites, comme l’ambiguïté des entités et l’utilisation des textes de relations, afin d’optimiser davantage les performances. Le domaine continue d’évoluer rapidement, avec des recherches intégrant diverses techniques, notamment BERT, les Graph Neural Networks (GNNs) et le raisonnement logique probabiliste.
carte mentale
TL;DR
Quel problème l’article cherche-t-il à résoudre ? S’agit-il d’un problème nouveau ?
L’article vise à résoudre le problème de l’ambiguïté des entités dans la recherche sur la complétion de graphes de connaissances (KGC). Ce problème entraîne des classements faibles lors des évaluations de modèles et affecte les performances des modèles actuels. Bien que ce ne soit pas un problème nouveau, l’article propose des pistes de recherche futures, telles que l’exploitation des textes de relations dans les triples d’entraînement et l’utilisation des descriptions d’entités pour améliorer les résultats avec un coût computationnel minimal.
Quelle hypothèse scientifique cet article cherche-t-il à valider ?
L’article cherche à valider l’hypothèse selon laquelle les modèles actuels, y compris celui présenté dans l’étude, offrent une performance de pointe dans les tâches de prédiction des relations, comme le montrent les classements de prédiction systématiquement élevés et les améliorations progressives obtenues par les nouvelles études.
Quelles nouvelles idées, méthodes ou modèles l’article propose-t-il ? Quelles sont leurs caractéristiques et avantages par rapport aux méthodes précédentes ?
L’article introduit l’utilisation des grands modèles de langage (LLMs) pour la complétion de graphes de connaissances, en particulier Llama 2, appliqué à la classification multi-label séquentielle pour les tâches de prédiction de relations. Cette approche atteint de nouveaux scores de référence sur Freebase et des scores équivalents sur WordNet.
De plus, l’article propose :
L’exploitation des descriptions d’entités et des textes de relations dans les triples d’entraînement,
L’exploration de techniques d’échantillonnage négatif,
L’introduction de nouveaux graphes de connaissances d’évaluation pour des scénarios de prédiction de relations plus sophistiqués.
Cette approche se distingue par son utilisation des LLMs pour la prédiction de relations basée sur le texte, offrant des performances compétitives sur Freebase et WordNet, avec des classements de prédiction élevés et constants et des améliorations progressives par rapport aux méthodes précédentes.Existe-t-il des recherches connexes ? Qui sont les chercheurs remarquables sur ce sujet dans ce domaine ? Quelle est la clé de la solution mentionnée dans l'article ?
La recherche actuelle dans le domaine de la Complétion de Graphes de Connaissances (KGC) a montré des avancées significatives, avec des performances à la pointe de la technologie démontrées par divers modèles. Des chercheurs notables dans ce domaine incluent Alqaaidi et Kochut, entre autres. La clé de la solution mentionnée dans l'article réside dans l'utilisation des noms d'entités comme entrée pour le LLM, ce qui implique la tokenisation de texte et l'encodage des tokens en identifiants numériques. Cette approche garantit une mise en œuvre simple et très efficace du modèle, améliorant sa performance dans les tâches de prédiction de relations.
Existe-t-il des recherches connexes ? Quels sont les chercheurs remarquables dans ce domaine ? Quelle est la clé de la solution proposée dans l’article ?
La recherche actuelle sur la complétion de graphes de connaissances (KGC) a montré des progrès significatifs, avec des modèles atteignant des performances de pointe. Parmi les chercheurs remarquables dans ce domaine figurent Alqaaidi et Kochut, entre autres. La clé de la solution proposée dans l’article réside dans l’utilisation des noms d’entités comme entrée pour le LLM, ce qui implique la tokenisation du texte et l’encodage des tokens en identifiants numériques. Cette approche assure une implémentation simple et très efficace, améliorant les performances dans les tâches de prédiction de relations.
Comment les expériences de l’article ont-elles été conçues ?
Les expériences ont été conçues pour évaluer la performance du modèle sur deux benchmarks largement reconnus, FreeBase et WordNet. Le modèle a été affiné avec Llama 2, pré-entraîné avec 7 milliards de paramètres, pour la tâche de prédiction de relations.
Le protocole expérimental comprenait :
L’utilisation de l’échantillonnage négatif dans la tâche LP pour accroître la diversité des données d’entraînement,
L’absence d’échantillonnage négatif dans la tâche RP, en raison des différences fondamentales dans la méthode d’attribution des labels,
L’utilisation du tokenizer de Llama 2 avec une longueur de padding de 50 pour les séquences textuelles des entités,
L’optimisation du modèle avec Adam, avec un taux d’apprentissage de 5e-5.
Quel jeu de données a été utilisé pour l’évaluation quantitative ? Le code est-il open source ?
Le jeu de données utilisé pour l’évaluation quantitative comprend FreeBase et WordNet. Le code du modèle n’est pas explicitement mentionné comme étant open source dans le contexte fourni.
Les expériences et résultats présentés dans l’article fournissent-ils un soutien solide aux hypothèses scientifiques à vérifier ? Veuillez analyser.
Les expériences et résultats présentés dans l’article fournissent un soutien solide aux hypothèses scientifiques à vérifier. L’étude démontre l’efficacité du modèle grâce à des évaluations sur des benchmarks bien établis, tels que FreeBase et WordNet, mettant en avant les performances et capacités du modèle. Les résultats indiquent une performance de pointe et des améliorations dans les tâches de prédiction de relations, validant ainsi les hypothèses formulées par la recherche. Pour fournir une analyse plus précise, des informations supplémentaires sur l’article seraient nécessaires, telles que le titre, les auteurs, la question de recherche, la méthodologie et les principales conclusions. Ces éléments permettraient d’évaluer la qualité des expériences et des résultats par rapport aux hypothèses scientifiques testées.
Quelles sont les contributions de cet article ?
L’article apporte des contributions significatives en démontrant une performance de pointe dans les classements de prédiction et en suggérant de nouvelles directions de recherche pour les tâches de prédiction d’entités. De plus, il introduit l’application des techniques d’échantillonnage négatif pour la tâche RP, ce qui pourrait améliorer les performances du modèle.
Quels travaux peuvent être approfondis ?
Les recherches futures dans le domaine de la complétion de graphes de connaissances (KGC) pourraient se concentrer sur la résolution du problème d’ambiguïté des entités, comme le souligne l’étude. Ce problème a entraîné des classements plus faibles lors de l’évaluation des modèles, indiquant un potentiel d’amélioration.
Les chercheurs pourraient explorer :
L’exploitation des textes de relations dans les triples d’entraînement,
L’utilisation des descriptions d’entités pour améliorer les résultats avec un coût computationnel minimal,
L’introduction de nouveaux scénarios d’évaluation dans les graphes de connaissances afin d’enrichir la littérature et de faire progresser les techniques de prédiction de relations.
En savoir plus
Le résumé ci-dessus a été généré automatiquement par Powerdrill.
Cliquez sur le lien pour consulter la page du résumé et découvrir d’autres articles recommandés.