Comment Maîtriser l'Analyse de Régression avec Facilité : Guide pour Simplifier l'Analyse | Powerdrill

L'analyse de régression est un pilier fondamental de la recherche académique, permettant aux chercheurs d'étudier les relations entre les variables, de tester des hypothèses et de construire des modèles prédictifs. Ce guide vous accompagnera dans les bases de l'analyse de régression, expliquera en détail des termes spécifiques, et démontrera comment Powerdrill AI peut simplifier votre flux de travail. Que vous analysiez des données d'enquête, meniez des expériences ou travailliez avec de grands ensembles de données, ce guide vous aidera à obtenir des insights significatifs en toute simplicité.
Qu'est-ce que l'analyse de régression ?
L'analyse de régression est un outil statistique puissant qui nous aide à comprendre la relation entre des variables. Essentiellement, elle vise à modéliser et à analyser comment une variable dépendante (également appelée variable de réponse) change en fonction d'une ou plusieurs variables indépendantes (aussi appelées variables prédictives).
L'analyse de régression multiple est utilisée pour comprendre la relation entre une variable dépendante et deux ou plusieurs variables indépendantes. Elle étend le concept de régression linéaire simple, qui n'implique qu'une seule variable indépendante, en permettant l'inclusion de plusieurs facteurs susceptibles d'influencer le résultat.
L'analyse de régression est largement utilisée dans des domaines académiques tels que :
Sciences sociales : Étudier comment le statut socio-économique affecte la réussite éducative.
Sciences de la santé : Analyser l'impact de l'exercice sur la pression artérielle.
Économie : Examiner la relation entre l'inflation et le taux de chômage.
Études environnementales : Étudier comment les variations de température influent sur les rendements des cultures.
Par exemple, prenons le cas d'un chercheur souhaitant comprendre et prédire le revenu annuel des ménages. Ici, le revenu annuel du ménage est la variable dépendante. Les variables indépendantes pourraient être divers facteurs provenant de notre ensemble de données, tels que l'âge du membre principal du ménage, qui pourrait influencer le revenu, car les individus plus expérimentés peuvent gagner des salaires plus élevés. Le niveau d'éducation du membre principal du ménage est également un facteur important ; généralement, ceux ayant un niveau d'éducation plus élevé, comme un doctorat, peuvent occuper des emplois mieux rémunérés par rapport à ceux n'ayant qu'un diplôme de niveau secondaire.
Explication des termes clés
Variable dépendante (Y) : Le résultat ou le phénomène que vous souhaitez expliquer ou prédire.
Variable(s) indépendante(s) (X) : Les facteurs susceptibles d'influencer la variable dépendante.
R-carré (R²) : Une mesure de la façon dont les variables indépendantes expliquent la variabilité de la variable dépendante (allant de 0 à 1, avec des valeurs plus élevées indiquant un meilleur ajustement).
Valeur p : Une mesure statistique qui aide à déterminer la significativité d'une variable indépendante. Une valeur p inférieure à 0,05 est généralement considérée comme significative dans la recherche académique.
Coefficients : Des chiffres représentant la force et la direction de la relation entre chaque variable indépendante et la variable dépendante.
Comment traiter les variables catégorielles / non continues ?
Dans l'ensemble de données donné pour l'analyse du revenu annuel des ménages, il existe plusieurs variables catégorielles telles que "Niveau d'éducation", "Occupation", "Lieu de résidence", "Statut marital", "Statut d'emploi", "Propriété de logement", "Type de logement", "Genre", et "Mode de transport principal". Voici les méthodes courantes pour traiter ces variables catégorielles lors d'une analyse de régression dans Excel et avec Powerdrill AI :
Dans Excel : méthode traditionnelle
Encodage One-Hot
Pour le « niveau d’éducation » : commencez par compter le nombre de catégories uniques. Dans ce cas, il y en a 4 : « Lycée », « Licence », « Master » et « Doctorat ». Créez ensuite 4 nouvelles colonnes. Pour chaque ligne, si le niveau d’éducation est « Lycée », la colonne « Lycée » prendra la valeur 1, tandis que les trois autres colonnes auront la valeur 0.
Par exemple, si en cellule A2 le niveau d’éducation est « Licence », alors la colonne « Licence » correspondante à la ligne 2 aura la valeur 1, et les colonnes « Lycée », « Master » et « Doctorat » auront la valeur 0.
Ce processus est répété pour toutes les variables catégorielles. Pour « Profession », puisqu’il existe plusieurs catégories comme « Santé », « Éducation », « Technologie », « Finance » et « Autres », une nouvelle colonne est créée pour chaque type. Si la profession d’un ménage est « Technologie », la colonne « Technologie » aura la valeur 1 pour cette ligne, et toutes les autres colonnes liées à la profession auront la valeur 0.
L’encodage One-Hot transforme une variable catégorielle en un ensemble de variables binaires, permettant au modèle de régression de traiter les informations catégorielles sous forme de données numériques. Chaque catégorie est représentée par un vecteur binaire distinct.
Création de variables fictives (Dummy Variables)
Pour « Localisation » : supposons trois catégories — « Urbain », « Périurbain » et « Rural ». Au lieu de créer trois colonnes comme avec l’encodage One-Hot, seules deux colonnes sont créées. La catégorie « Rural » peut être choisie comme catégorie de référence.
Dans la colonne « Urbain », si la localisation est « Urbain », la valeur est 1 ; si elle est « Périurbain » ou « Rural », la valeur est 0.
Dans la colonne « Périurbain », si la localisation est « Périurbain », la valeur est 1 ; si elle est « Urbain » ou « Rural », la valeur est 0.
Cette approche permet de réduire le nombre de variables, ce qui est particulièrement utile lorsque l’on travaille avec un grand nombre de variables catégorielles. Par exemple, si la variable « Profession » comporte de nombreuses catégories, l’utilisation de variables fictives peut limiter les problèmes de multicolinéarité liés à un trop grand nombre de variables fortement corrélées, comme c’est le cas avec l’encodage One-Hot.
En choisissant une catégorie de référence, les autres catégories sont interprétées relativement à celle-ci. Le modèle de régression peut ainsi estimer l’effet de chaque catégorie non référente par rapport à la catégorie de référence.
Avec Powerdrill AI : gestion automatique
Powerdrill AI intègre des algorithmes capables de reconnaître automatiquement les variables catégorielles dans un ensemble de données. Par exemple, lors du téléchargement d’un jeu de données contenant des variables telles que « Statut marital » ou « Statut d’emploi », aucune étape d’encodage manuel n’est nécessaire, contrairement à Excel.
La plateforme d’IA est conçue pour traiter les variables catégorielles de manière plus efficace. Elle peut utiliser des techniques avancées comme l’encodage ordinal pour les variables présentant un ordre intrinsèque (même si, dans notre jeu de données, la majorité des variables catégorielles ne possède pas d’ordre clair). Pour les variables sans ordre, Powerdrill AI peut appliquer des méthodes similaires à l’encodage One-Hot ou des encodages plus avancés propres au machine learning, en arrière-plan.
Cette automatisation permet un gain de temps et d’efforts considérable. Les utilisateurs n’ont pas à se soucier des détails techniques liés à l’encodage des variables catégorielles.
Une fois les variables catégorielles traitées, que ce soit dans Excel ou avec Powerdrill AI, elles peuvent être utilisées directement dans l’analyse de régression. Dans Excel, les nouvelles colonnes créées (via l’encodage One-Hot ou les variables fictives) sont incluses dans la plage X d’entrée de l’analyse de régression. Avec Powerdrill AI, il suffit d’indiquer à la plateforme de traiter les variables catégorielles ; celle-ci met automatiquement à jour le jeu de données importé et réalise l’analyse en appliquant la méthode de traitement la plus appropriée.
Comment réaliser une analyse de régression multiple dans Excel ?
Excel est un outil largement accessible et convivial pour effectuer des analyses de régression de base. Utilisons notre jeu de données synthétique, qui se concentre sur différents facteurs démographiques et socio-économiques influençant le revenu annuel des ménages. Le jeu de données comprend des variables telles que « Âge », « Niveau d’éducation », « Profession », « Nombre de personnes à charge », etc., avec le « Revenu annuel du ménage » comme variable dépendante.
ÉTAPE 1 : Préparation des données
Commencez par vérifier que vos données sont propres. Identifiez les valeurs manquantes. Par exemple, s’il manque des valeurs dans la colonne « Âge », vous pouvez les remplacer, notamment en utilisant l’âge moyen calculé à partir des valeurs non manquantes. Pour ce faire, additionnez tous les âges disponibles et divisez le total par le nombre d’observations valides.
Pour une variable catégorielle comme « Profession », vous pouvez utiliser le mode (la catégorie la plus fréquente) pour combler les valeurs manquantes. Si le nombre de valeurs manquantes est faible, il est également possible de supprimer les lignes concernées.Assurez-vous que les données sont correctement formatées. Les variables numériques telles que « Âge » et « Nombre de personnes à charge » doivent être au format numérique. Pour les variables catégorielles, vérifiez la cohérence de la saisie, par exemple que toutes les valeurs du « Niveau d’éducation » sont correctement orthographiées : « Lycée », « Licence », « Master » ou « Doctorat ».
ÉTAPE 2 : Utilisation de l’outil d’analyse de données
Si le complément Outils d’analyse n’est pas activé, vous devez l’activer. Allez dans « Fichier » > « Options » > « Compléments ». Sélectionnez « Outils d’analyse », puis cliquez sur « Atteindre ». Cochez « Outils d’analyse » et cliquez sur « OK ».
Une fois activé, accédez à l’onglet « Données » et cliquez sur « Analyse de données ». Dans la boîte de dialogue qui s’ouvre, sélectionnez « Régression ».
ÉTAPE 3 : Ajustement des paramètres
Dans la boîte de dialogue Régression :
Plage Y d’entrée : indiquez la plage correspondant aux données du « Revenu annuel du ménage » dans le champ « Plage Y d’entrée ». Par exemple, si les données vont de N2 à N10001, saisissez $N$2:$N$10001.
Plage X d’entrée : saisissez les plages des variables indépendantes telles que « Âge », « Niveau d’éducation », « Nombre de personnes à charge » dans le champ « Plage X d’entrée ». Excel peut créer automatiquement des variables fictives pour les variables catégorielles comme le « Niveau d’éducation ».
Étiquettes : cochez cette option si vos données comportent des en-têtes de colonnes. Cela permet à Excel de reconnaître les noms des variables dans les résultats de la régression.
Niveau de confiance : définissez le niveau de confiance souhaité ; la valeur par défaut est de 95 %.
Plage de sortie : choisissez l’emplacement des résultats de la régression, soit dans une nouvelle feuille de calcul, soit dans une zone vide de la feuille existante.
Résidus : cochez cette option pour afficher les résidus, qui représentent la différence entre les valeurs observées et les valeurs prédites. Des résidus élevés indiquent que le modèle peut manquer de précision pour certaines observations et sont essentiels pour évaluer la qualité du modèle.
Résidus standardisés : ils facilitent la détection des valeurs aberrantes. Des résidus standardisés dont la valeur absolue dépasse un certain seuil (par exemple 3) sont généralement considérés comme des outliers.
Graphiques des résidus : ils montrent la relation entre les variables indépendantes et les résidus. La présence d’un motif structuré peut indiquer une mauvaise spécification du modèle. Cette option est utile pour diagnostiquer d’éventuels problèmes.
Graphiques d’ajustement linéaire : ils comparent visuellement les valeurs observées et les valeurs prédites. Si les points sont largement dispersés autour de la droite prédite, le modèle peut présenter un ajustement insuffisant. Cette option permet d’évaluer la qualité globale de l’ajustement.
ÉTAPE 4 : Analyse des résultats
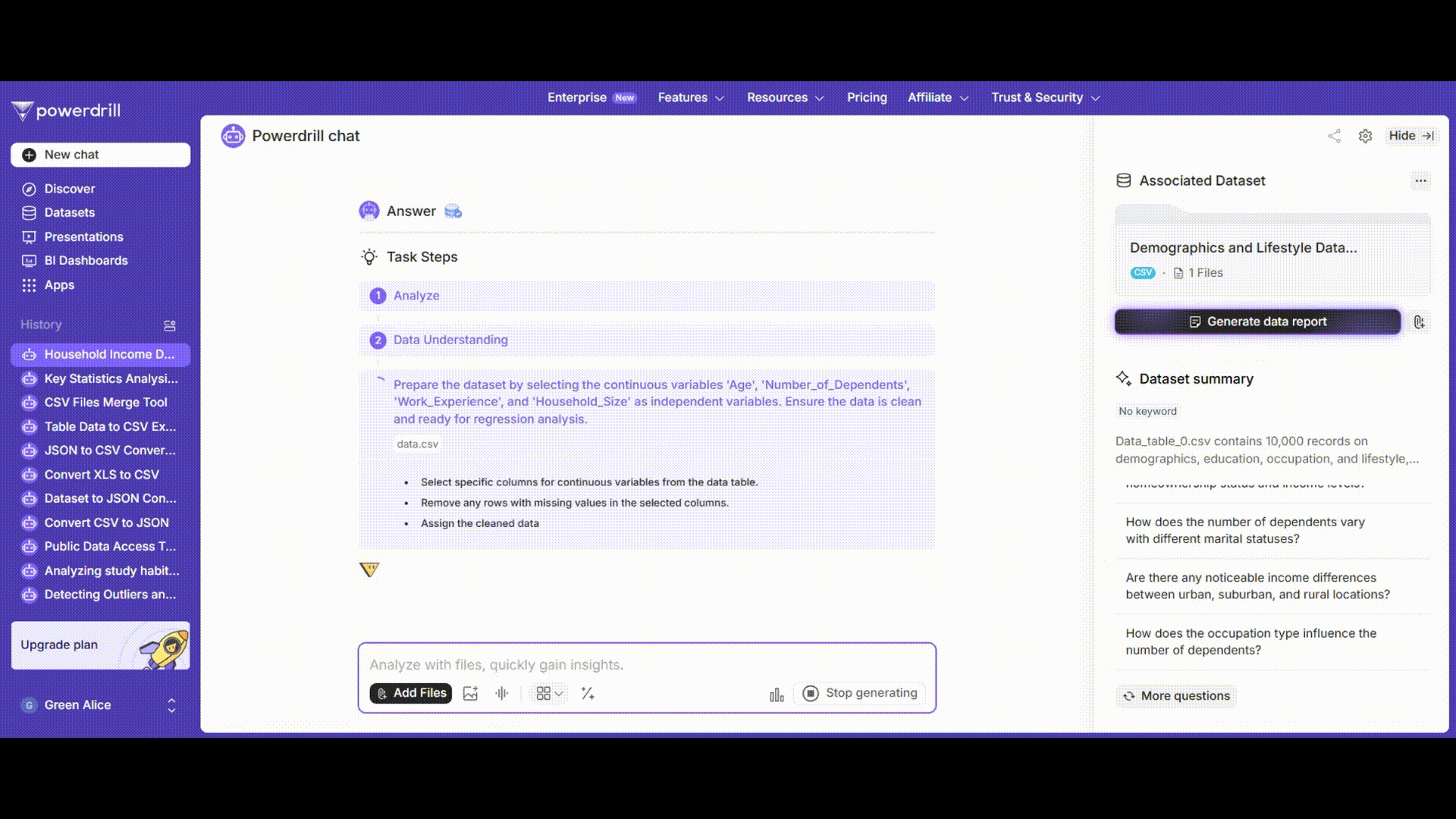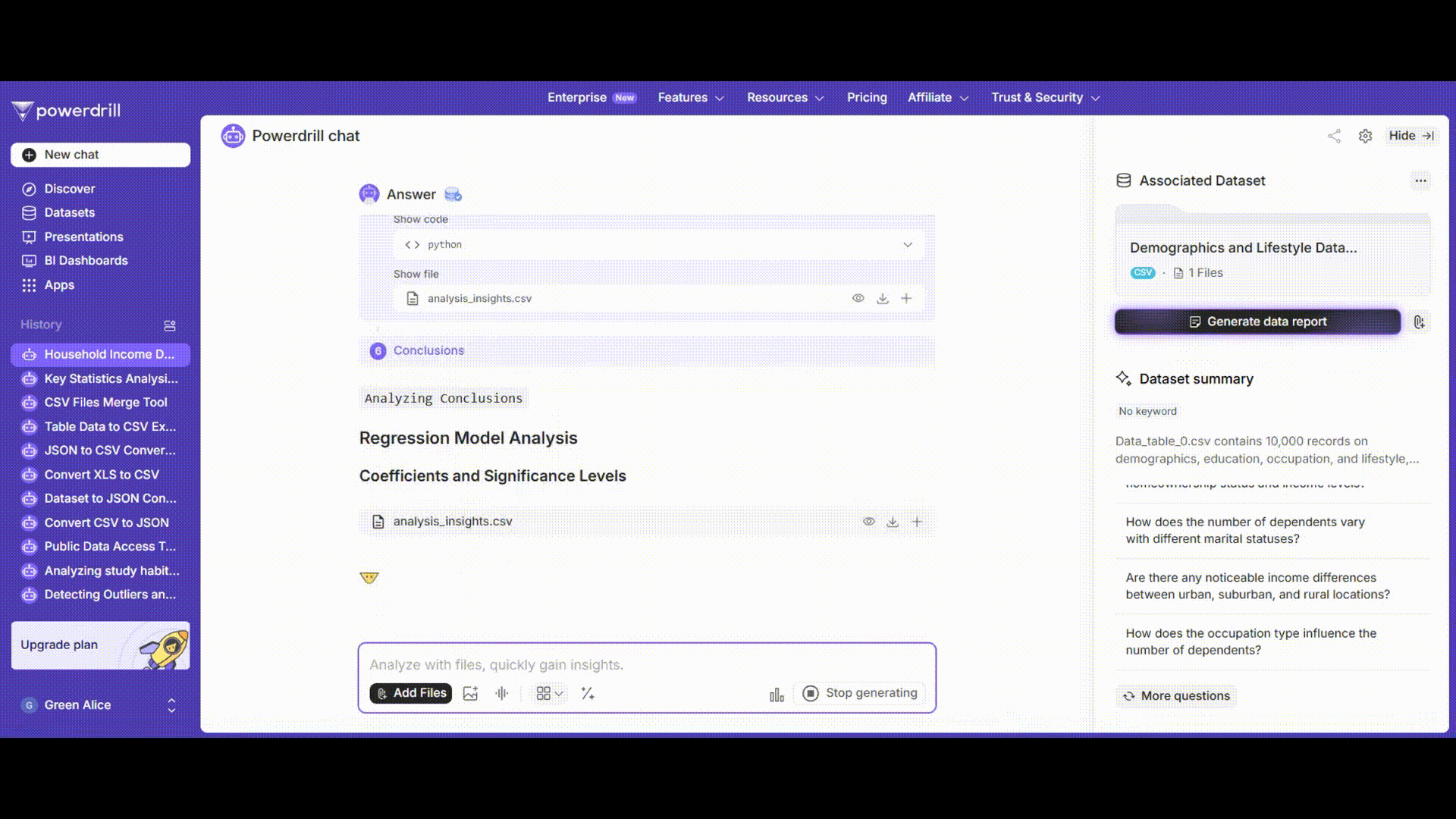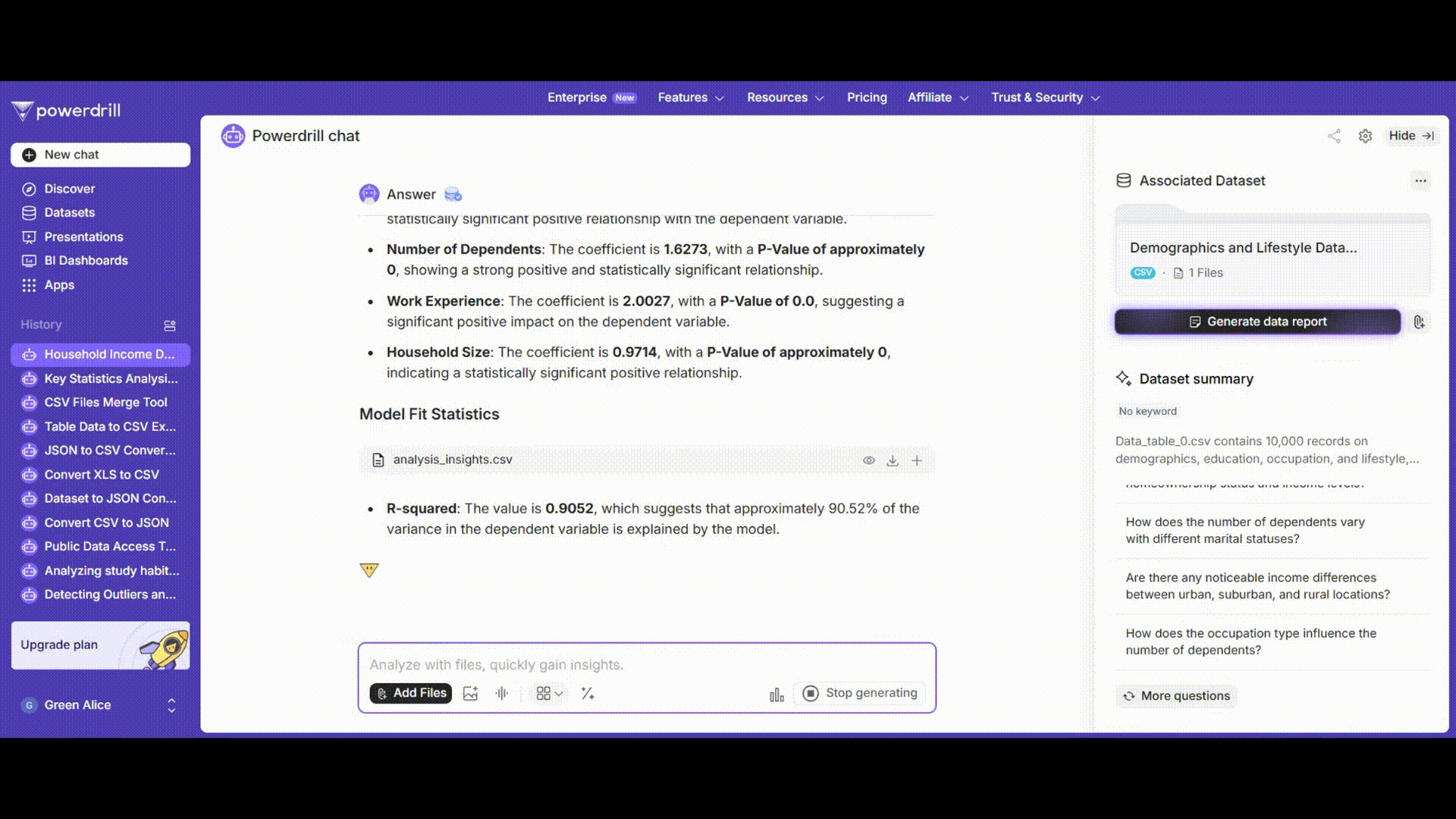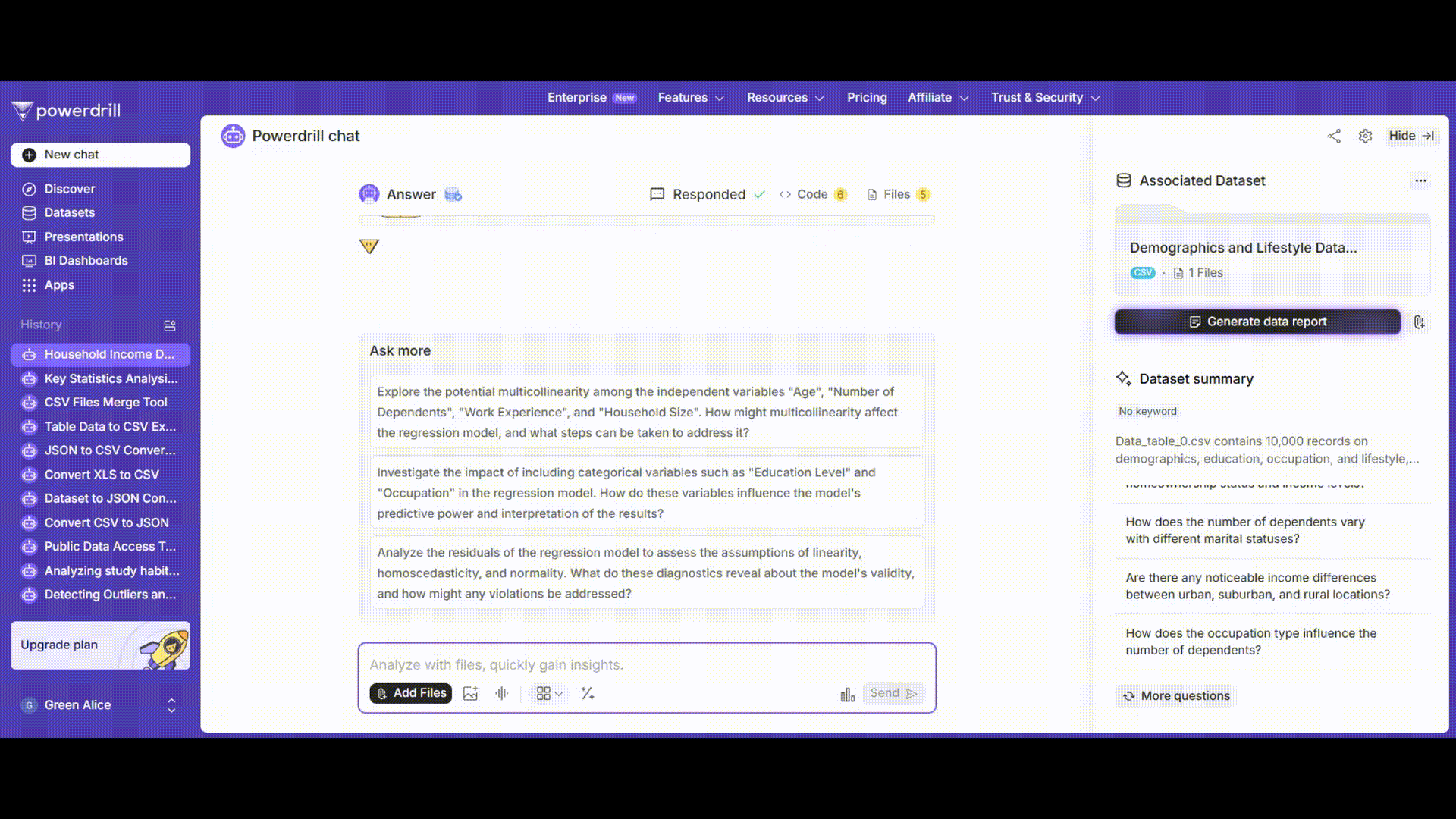
Après avoir cliqué sur « OK », Excel génère un ensemble complet de résultats. Ceux-ci incluent les coefficients pour chaque variable. Par exemple, le coefficient associé à « Âge » indique de combien le revenu annuel du ménage est censé varier pour une augmentation d’un an de l’âge, toutes choses égales par ailleurs. Les erreurs standards, les statistiques t, les valeurs p ainsi que la valeur R² sont également fournies. La valeur R² indique dans quelle mesure les variables indépendantes expliquent la variation du revenu annuel du ménage. Une valeur proche de 1 correspond à un meilleur ajustement du modèle.
Comment réaliser une analyse de régression multiple avec l’IA ?
Powerdrill AI est une plateforme performante qui permet de simplifier et d’optimiser le processus d’analyse de régression. Nous poursuivons ici avec notre jeu de données synthétique portant sur le revenu annuel des ménages.
ÉTAPE 1 : Téléchargement des Données
Allez sur powerdrill. L'interface conviviale vous permet de télécharger facilement votre ensemble de données. Vous pouvez télécharger votre fichier de données (dans des formats courants comme CSV, Excel) depuis votre ordinateur ou le cloud Dropbox.
ÉTAPE 2 : Sélection de la Tâche de Régression
Après le téléchargement du jeu de données, vous devez communiquer vos objectifs d’analyse et vos intentions de recherche à l’IA en fonction de vos besoins spécifiques, afin de lui permettre de mettre en place un modèle d’analyse de régression. Au cours de ce processus, l’IA agit comme un assistant de recherche personnel, avec lequel vous pouvez interagir et discuter librement des informations que vous souhaitez explorer.
Parallèlement, l’IA génère automatiquement des questions, ce qui vous aide à identifier rapidement les relations internes entre les variables du jeu de données.
Une fois les données importées, Powerdrill AI est capable de détecter les variables. Vous devez alors définir la variable dépendante — dans notre cas, le « Revenu annuel du ménage ». Ensuite, vous pouvez sélectionner les variables indépendantes à inclure dans le modèle de régression, telles que « Âge », « Niveau d’éducation », « Profession », « Expérience professionnelle », etc.
Grâce à son intelligence intégrée, Powerdrill AI peut gérer différents types de données avec un minimum d’interventions manuelles.
ÉTAPE 3 : Entraînement du Modèle et Résultats
Powerdrill AI utilise des algorithmes avancés de machine learning pour réaliser l’analyse de régression. Il entraîne rapidement le modèle et fournit des résultats détaillés.
Les résultats incluent non seulement les coefficients de régression traditionnels et leurs niveaux de significativité, mais également des visualisations. Par exemple, la plateforme peut afficher un graphique de dispersion comparant les valeurs réelles et les valeurs prédites du revenu annuel des ménages, ce qui permet d’évaluer visuellement la performance du modèle. Il devient ainsi facile de vérifier si les valeurs prédites suivent de près les valeurs observées.
Par ailleurs, Powerdrill AI gère les types de données complexes de manière plus efficace que les outils traditionnels. Il analyse les relations entre les variables de façon plus approfondie. Par exemple, il peut identifier rapidement l’existence de relations non linéaires entre « Expérience professionnelle » et le revenu annuel du ménage, qui pourraient passer inaperçues dans une analyse de régression classique réalisée sous Excel.
Donnez plus de puissance à vos recherches avec Powerdrill
Que vous soyez débutant dans l’univers de l’analyse de données ou chercheur expérimenté, l’analyse de régression est un outil essentiel. Si Excel constitue un bon point de départ pour des analyses de régression simples, des plateformes comme Powerdrill AI offrent une solution plus avancée, plus efficace et plus intuitive, en particulier pour le traitement de jeux de données complexes.
Si vous souhaitez découvrir la puissance et la simplicité de l’analyse de régression assistée par l’IA, rendez-vous sur powerdrill.ai. Téléversez vos données dès aujourd’hui et révélez les insights cachés qu’elles contiennent. Qu’il s’agisse de données commerciales, de données issues de la recherche scientifique ou de tout autre type de données, Powerdrill AI vous aide à obtenir des résultats précis et exploitables en un temps réduit.
Commencez dès aujourd’hui ! Visitez Powerdrill et importez vos données.
Introduction au jeu de données d’exemple
Le jeu de données utilisé dans cet article vise à comprendre les facteurs qui influencent le revenu annuel des ménages. Vous pouvez le télécharger et vous entraîner à l’analyse de données via cette page.
Ce jeu de données synthétique simule divers facteurs démographiques et socio-économiques ayant un impact sur le revenu annuel des ménages. Il peut être utilisé pour l’analyse exploratoire des données, la modélisation prédictive et l’étude des relations entre les différentes variables et les niveaux de revenu.
Il couvre un large éventail de variables démographiques et socio-économiques.
« Âge » du membre principal du ménage : reflète l’impact potentiel de l’expérience professionnelle et du stade de vie sur le revenu.
« Niveau d’éducation » : montre comment les différents niveaux de formation, du lycée au doctorat, peuvent conduire à des niveaux de revenu distincts.
« Profession » : inclut des secteurs tels que la santé, l’éducation, la technologie et la finance, chacun présentant des potentiels de rémunération différents.
« Nombre de personnes à charge » : indique comment la structure familiale influence le revenu disponible.
« Localisation » (urbaine, périurbaine, rurale) : prend en compte les différences régionales en matière de marché du travail et de coût de la vie.
Des variables supplémentaires telles que l’expérience professionnelle (en années), le statut marital, le statut d’emploi, la taille du ménage, le statut de propriété du logement, le type de logement, le genre et le mode de transport principal contribuent également à la complexité de la relation avec le revenu annuel des ménages.
Ce jeu de données riche permet de mener des analyses de régression approfondies afin d’identifier les facteurs significatifs et d’évaluer leur importance relative dans la détermination du revenu des ménages.