Redéfinir la Recherche d’Informations dans les Bases de Données Structurées grâce aux Modèles de Langage Étendu

Thème central
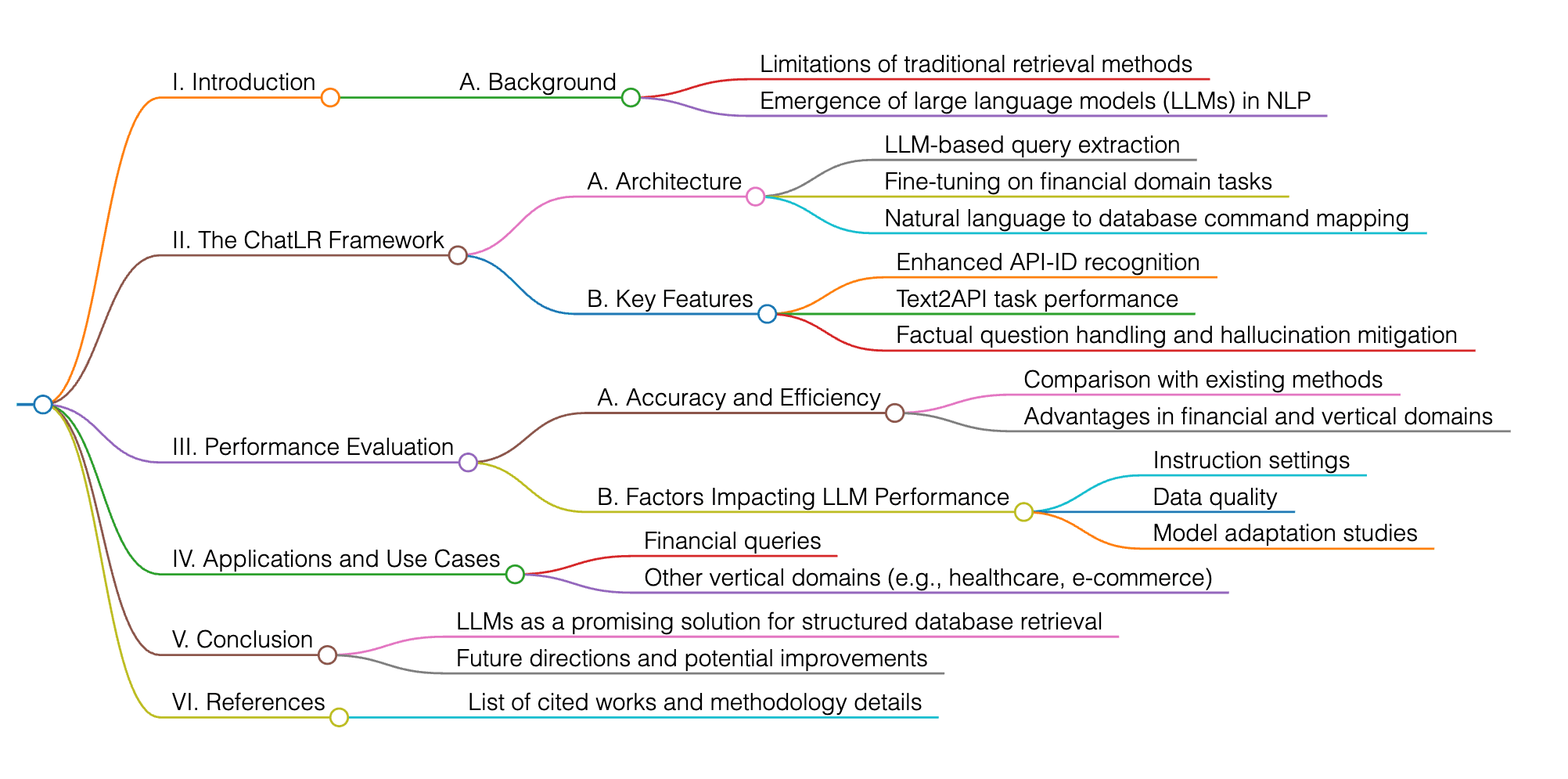
Cet article présente ChatLR, un cadre d’amélioration de la recherche d’informations qui optimise l’accès aux bases de données structurées grâce aux modèles de langage étendu (LLM). Il surmonte les limites des méthodes traditionnelles en exploitant les LLM pour l’extraction précise de requêtes et le fine-tuning sur des tâches du domaine financier.
ChatLR dépasse les méthodes existantes avec une précision élevée, notamment pour la reconnaissance d’API-ID et les tâches Text2API, améliorant ainsi les LLM pour les questions factuelles et réduisant les problèmes d’hallucination.
Le cadre se concentre sur la traduction des requêtes en langage naturel en commandes de base de données précises, renforçant la précision et l’efficacité dans les domaines financiers et d’autres secteurs verticaux. Des études supplémentaires analysent également l’impact des paramètres d’instruction, de la qualité des données et de l’adaptation du modèle sur la performance des LLM dans diverses tâches de traitement du langage naturel (NLP).
Mind Map
TL;DR
Quel problème cet article tente-t-il de résoudre ? S’agit-il d’un nouveau problème ?
Cet article traite des défis liés aux modèles de langage étendu (LLM), en particulier leurs limitations pour intégrer des connaissances à jour et leur tendance à générer des réponses factuellement incorrectes, phénomène connu sous le nom de « hallucination ». Ce problème n’est pas nouveau et persiste dans divers scénarios impliquant les LLM.
Quelle hypothèse scientifique cet article cherche-t-il à valider ?
L’article cherche à valider l’hypothèse selon laquelle l’utilisation d’un nouveau cadre d’augmentation de la recherche nommé ChatLR, qui exploite principalement la puissante capacité de compréhension sémantique des LLM comme moteurs de recherche, peut permettre une recherche d’informations précise et concise, notamment dans le domaine financier.
Quelles nouvelles idées, méthodes ou modèles l’article propose-t-il ? Quelles sont leurs caractéristiques et avantages par rapport aux méthodes précédentes ?
L’article introduit un cadre novateur d’augmentation de la recherche nommé ChatLR, qui utilise les LLM comme récupérateurs d’informations pour améliorer la précision de la recherche. Ce cadre exploite principalement la compréhension sémantique des LLM afin d’obtenir des résultats précis et concis.
De plus, l’article présente un système de recherche et de question-réponse basé sur LLM, adapté au domaine financier, grâce au fine-tuning sur des tâches telles que Text2API et la reconnaissance d’API-ID, démontrant l’efficacité de ChatLR pour répondre aux requêtes des utilisateurs avec une précision globale supérieure à 98,8 %.
Le cadre ChatLR offre plusieurs avantages clés par rapport aux méthodes précédentes :
Il traite le problème d’« hallucination » souvent rencontré dans les LLM en intégrant des techniques de Retrieval-Augmented Generation (RAG), réduisant ainsi la génération de réponses factuellement incorrectes.
ChatLR démontre une précision supérieure, avec une amélioration notable de 62,6 % pour la reconnaissance d’API-ID et près de 83,6 % pour les tâches Text2API, par rapport aux LLM seuls après fine-tuning.
Cette précision accrue résulte d’un processus rigoureux de génération de données et de l’intégration de bases de données structurées spécifiques au domaine financier, garantissant la pertinence et la précision des informations récupérées.
Enfin, la capacité de ChatLR à s’adapter à différents domaines verticaux et scénarios, grâce à l’ajustement des instructions et l’intégration de plusieurs exemples complets de sortie de données, renforce son utilité pratique dans des applications réelles.
Existe-t-il des recherches connexes ? Qui sont les chercheurs notables dans ce domaine ? Quelle est la clé de la solution mentionnée dans l’article ?
Dans le domaine de l’augmentation de la recherche et de la recherche d’informations utilisant les modèles de langage étendu (LLM), certains chercheurs se démarquent, notamment Mingzhu Wang, Yuzhe Zhang, Qihang Zhao, Juanyi Yang et Hong Zhang. Ces chercheurs ont contribué au développement de cadres comme ChatLR, qui exploitent les LLM pour une recherche d’informations précise et concise dans les bases de données structurées.
La clé de la solution présentée dans l’article repose sur le concept de Retrieval-Augmented Generation (RAG). Cette approche améliore les LLM en incorporant des connaissances externes récupérées à partir d’un corpus, guidant le processus de raisonnement lors de la génération. En combinant les connaissances récupérées avec la requête, les LLM sont mieux équipés pour fournir des réponses précises aux questions factuelles, dépassant les limites liées à la dépendance exclusive aux connaissances paramétrées stockées dans le modèle.
Comment les expériences de l’article ont-elles été conçues ?
Les expériences ont été conçues en effectuant un fine-tuning sur plusieurs modèles de langage de pointe (LLM) pré-entraînés en chinois, en utilisant un jeu de données annoté de 10 000 articles de presse chinois. Les résultats expérimentaux ont montré que tous les modèles présentaient une grande capacité d’alignement des labels après fine-tuning, avec Chinese-Alpaca obtenant les scores Rouge les plus élevés sur l’ensemble de test.
Le processus de fine-tuning a impliqué l’optimisation du temps d’entraînement et de l’utilisation de la mémoire grâce à une technique de fine-tuning très efficace appelée LoRA, tout en entraînant simultanément le modèle pour la reconnaissance d’API-ID et les tâches Text2API sur un jeu de données totalisant 70 000 instances.
Quel jeu de données a été utilisé pour l’évaluation quantitative ? Le code est-il open source ?
Le jeu de données utilisé pour l’évaluation quantitative n’est pas mentionné explicitement dans les contextes fournis. Cependant, le code utilisé pour l’évaluation est open source, comme l’indique la mention du fine-tuning du cadre ChatLR et de l’obtention d’une précision plus élevée sur les ensembles de test.
Les expériences et résultats présentés dans l’article apportent-ils un bon soutien aux hypothèses scientifiques à vérifier ? Analyse.
Les expériences et résultats présentés dans l’article fournissent un fort soutien aux hypothèses scientifiques à vérifier. L’étude a réalisé des expériences de fine-tuning sur plusieurs modèles de langage étendu (LLM) de pointe pour des tâches de résumé de texte en chinois. Les résultats ont montré une grande capacité d’alignement des labels après fine-tuning, avec le modèle Chinese-Alpaca obtenant les scores Rouge les plus élevés sur l’ensemble de test.
De plus, le modèle ChatLR, basé sur le modèle fondamental Chinese-Alpaca, a démontré une précision globale en récupération d’informations dépassant 98,8 %. Ces résultats indiquent un alignement réussi avec les hypothèses scientifiques et valident l’efficacité du cadre proposé pour répondre aux requêtes des utilisateurs.
Quelles sont les contributions de cet article ?
L’article introduit un nouveau cadre d’augmentation de la recherche nommé ChatLR (LLM Retrieval with Chat), qui exploite les LLM pour les opérations de recherche, spécifiquement conçu pour les requêtes factuelles dans les bases de données structurées, améliorant significativement la précision de récupération des connaissances liées aux requêtes.
Le cadre permet une recherche précise et efficace d’informations pertinentes dans les bases de données structurées en traduisant les requêtes en langage naturel en commandes de recherche de base de données précises, facilitant la généralisation à différents domaines verticaux grâce à la modification du contenu pertinent.
Quels travaux peuvent être approfondis ?
Des travaux futurs peuvent viser à élargir les types de bases de données compatibles et à explorer une approche intégrative permettant de fusionner les tâches de requête provenant de bases de données structurées et non structurées, afin d’optimiser l’utilisation des connaissances externes dans les requêtes factuelles basées sur les connaissances.
En savoir plus
Le résumé ci-dessus a été généré automatiquement par Powerdrill.
Cliquez sur le lien pour voir la page de résumé et d'autres documents recommandés.