Powerdrill AI : N°1 du Benchmark QuALITY

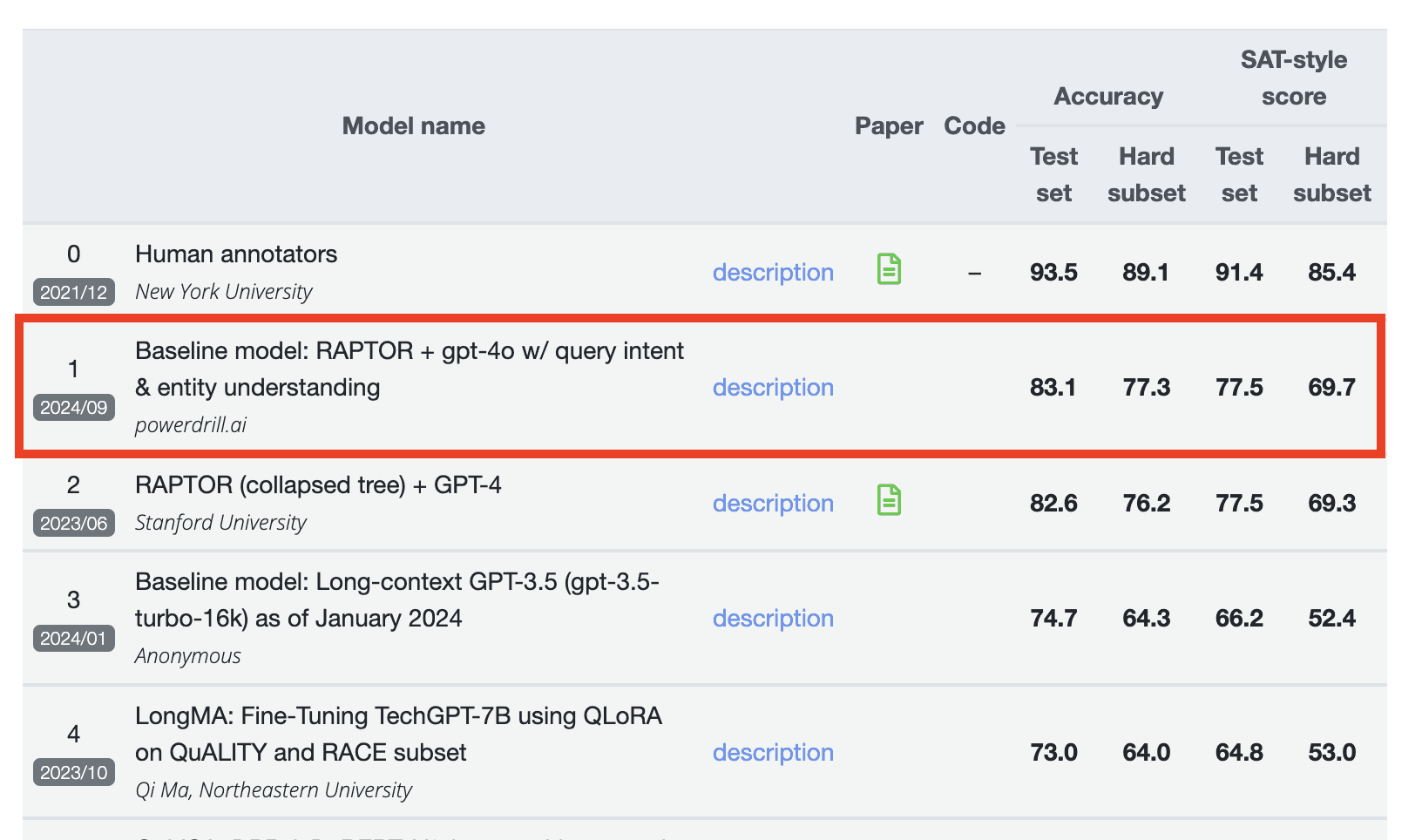
Nous sommes ravis d’annoncer que Powerdrill AI occupe la 1re place du classement du benchmark QuALITY (dernière mise à jour : septembre 2024).
En termes de précision, il a obtenu un score de 83,1 sur l’ensemble de test et 77,3 sur le sous-ensemble difficile.
Pour le score de type SAT, il a atteint 77,5 sur l’ensemble de test et 69,7 sur le sous-ensemble difficile.
Consultez le classement pour plus de détails : https://nyu-mll.github.io/quality
Qu'est-ce que QuALITY?
QuALITY (Question Answering with Long Input Texts) est un jeu de données conçu pour évaluer la compréhension de documents longs par les modèles, en particulier lorsqu’ils doivent traiter des contextes beaucoup plus longs que ce que les modèles actuels peuvent gérer. Les passages sont en anglais et ont en moyenne environ 5 000 tokens. Contrairement à certains autres jeux de données où les questions sont créées à partir de résumés ou d’extraits, les questions de QuALITY sont rédigées et validées par des contributeurs ayant lu l’intégralité du passage.
Un aspect clé de QuALITY est que seulement la moitié des questions peuvent être répondues par des annotateurs travaillant sous contrainte de temps, ce qui montre que la lecture en diagonale ou la recherche de mots-clés ne suffit pas pour obtenir de bons résultats. Cela rend le jeu de données particulièrement difficile et vise à favoriser le développement de modèles capables d’une compréhension profonde plutôt que d’une simple extraction superficielle.
Les modèles de référence (baseline) obtiennent des performances faibles sur cette tâche, avec une précision d’environ 55,4 %, bien en dessous de la performance humaine à 93,5 %. Le jeu de données comprend également un sous-ensemble difficile (QuALITY-HARD), composé de questions particulièrement complexes.
Critères d'évaluation pour la liste QuALITY

Les classements sont déterminés en évaluant la précision sur l’ensemble du jeu de test. Cela signifie que la position d’un participant dépend de la justesse de ses réponses à toutes les questions, et non à un sous-ensemble seulement.
La précision est calculée en divisant le nombre total de réponses correctes par le nombre total d’exemples du jeu de test, ce qui fournit une mesure simple de la performance globale.
Le score de type SAT est un peu plus complexe. Il commence par le nombre de réponses correctes fournies par un participant. Pour décourager les réponses aléatoires, la formule déduit un tiers de point pour chaque réponse incorrecte. Cette pénalité encourage une réflexion plus précise. En revanche, les réponses non données—c’est-à-dire lorsque le participant choisit de ne pas répondre—n’impactent pas le score, car elles ont un poids nul. Enfin, le score ajusté est divisé par le nombre total d’exemples pour normaliser le résultat et obtenir un score final reflétant la performance globale.
Dans la liste finale QuALITY, le classement est basé sur deux composantes principales : la précision et le score de type SAT. Chacune de ces composantes est évaluée à la fois sur le jeu de test complet et sur le sous-ensemble difficile. Il est important de souligner que Powerdrill AI a excellé dans tous les aspects, surpassant des modèles de Stanford University, Northeastern University, et d’autres, en obtenant le score le plus élevé dans chaque partie de l’évaluation. Pour référence, un score de 0 représente la valeur de référence du benchmark.
Cette performance exceptionnelle de Powerdrill AI souligne ses capacités supérieures à traiter les tâches définies dans l’évaluation QuALITY.
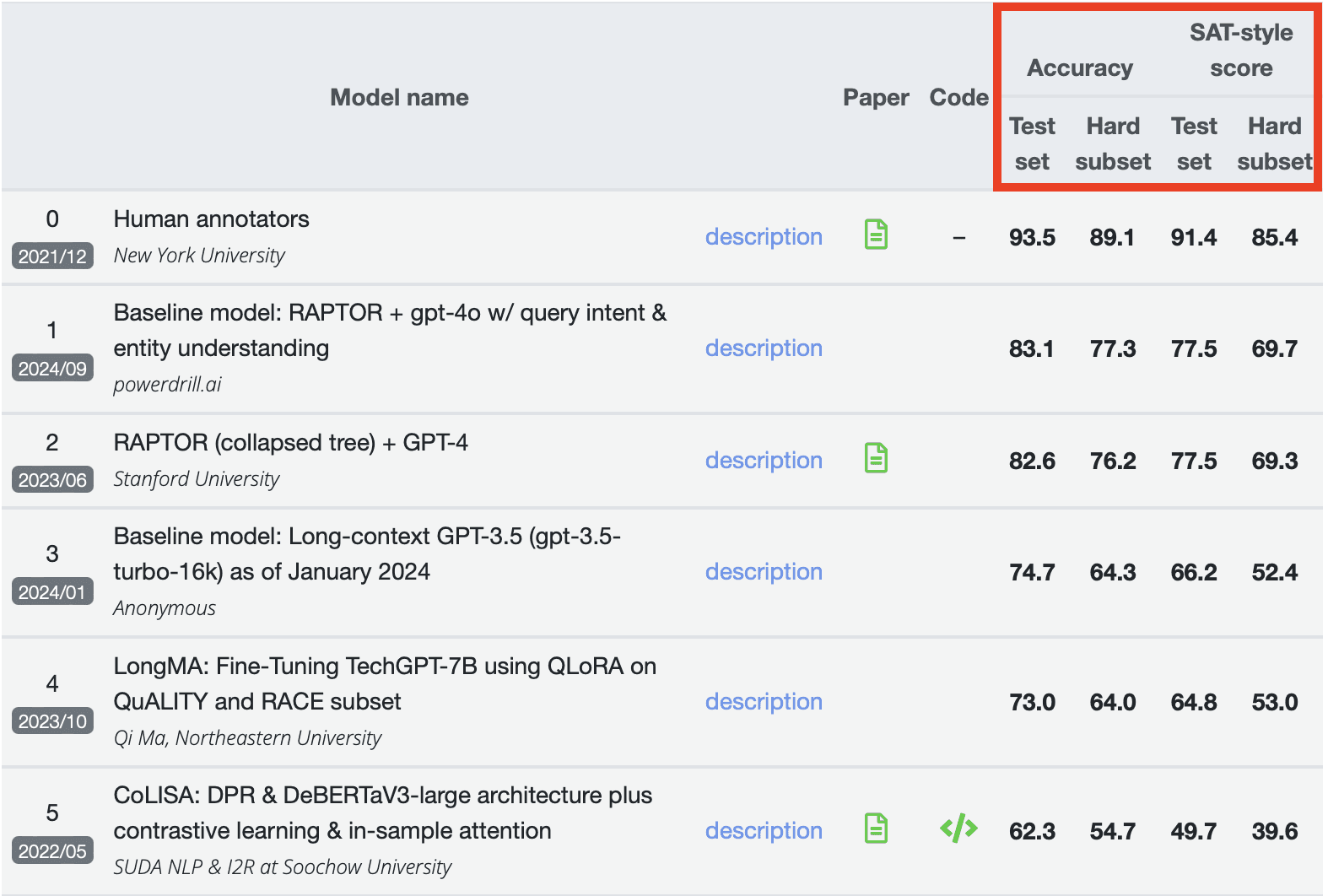
Le jeu de test est une partie du jeu de données mise de côté pour évaluer la performance d’un modèle après l’entraînement. Il contient généralement des exemples que le modèle n’a pas vus lors de l’entraînement ou de la validation. L’objectif est de mesurer la capacité du modèle à généraliser sur de nouvelles données non vues. Les métriques de performance telles que la précision, le rappel, la justesse, et d’autres sont calculées en fonction des performances du modèle sur ce jeu de test.
Le sous-ensemble difficile est une partie du jeu de test qui contient des exemples particulièrement complexes ou difficiles à traiter pour le modèle. Il peut s’agir de cas où les distinctions entre classes sont subtiles, où les données sont plus bruitées, ou où le modèle a historiquement des difficultés. La performance sur ce sous-ensemble est souvent analysée séparément pour comprendre comment le modèle se comporte dans des conditions plus exigeantes et pour identifier les domaines nécessitant une amélioration.
Pourquoi Powerdrill AI occupe la première place
Powerdrill AI est un système sophistiqué conçu pour traiter efficacement des requêtes complexes. Il excelle dans l’analyse des entrées utilisateur et l’optimisation du processus de récupération d’informations grâce à des algorithmes avancés, garantissant la fourniture rapide d’informations précises et pertinentes. Ce système s’adapte à différents contextes, offrant une expérience utilisateur fluide et efficace.
RAPTOR est un système de récupération innovant basé sur des arbres qui améliore la connaissance paramétrique des grands modèles de langage en intégrant des informations contextuelles à plusieurs niveaux d’abstraction. Il utilise des techniques de regroupement récursif et de synthèse pour construire une structure arborescente hiérarchique, synthétisant les informations à travers différentes sections du corpus de récupération. En partant du bas vers le haut, RAPTOR regroupe des blocs de texte et génère des résumés, créant un arbre multi-couches où les nœuds feuilles contiennent le texte original et les nœuds supérieurs représentent les informations résumées.
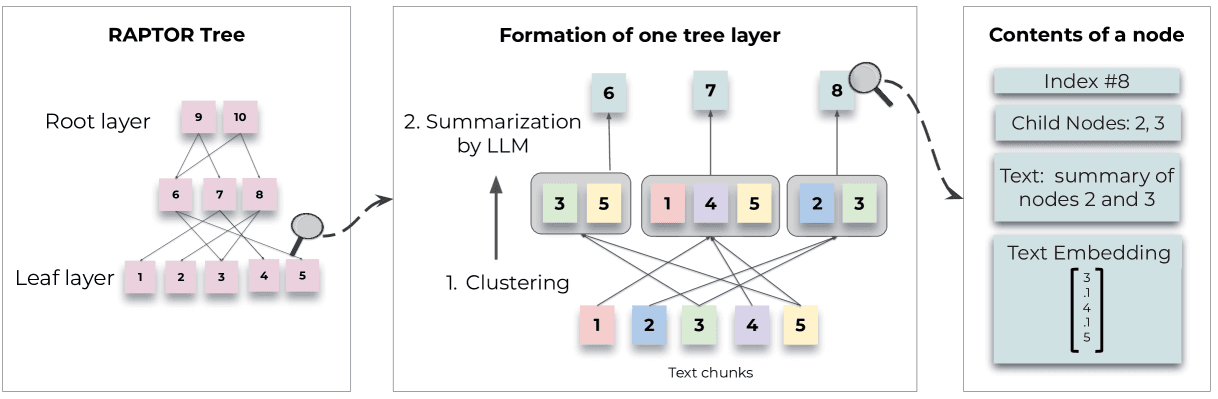
Powerdrill AI exploite l’indexation RAPTOR pour récupérer des blocs d’information plus raffinés, améliorant ainsi le raisonnement et les réponses dans les tâches de génération augmentée par récupération (RAG).
Powerdrill AI décompose d’abord les requêtes utilisateur en un plan multi-étapes. Cette décomposition permet au système de traiter les requêtes complexes étape par étape, garantissant que chaque étape est exécutée avec précision.
Pour chaque étape du plan multi-étapes, les entités clés sont extraites de la requête. Ces entités sont essentielles car elles permettent de faire correspondre la requête avec les informations les plus pertinentes de la base de données ou du document, améliorant la précision de la récupération des données nécessaires.
Pour optimiser davantage le processus, Powerdrill AI implémente un modèle de réévaluation (rerank). Ce modèle filtre les blocs d’information non essentiels à la réponse de la requête. En éliminant ces éléments non pertinents, le système évite de traiter des contextes trop longs, réduisant ainsi les coûts et améliorant les performances en diminuant la latence.
Dans l’ensemble, Powerdrill AI se concentre sur un traitement des requêtes précis et efficace, en gérant soigneusement la décomposition des requêtes, l’extraction des entités et la récupération des données.
Les prochaines étapes de Powerdrill AI
La récente performance de Powerdrill AI, qui occupe désormais la 1re place du benchmark QuALITY pour le Question Answering avec textes longs, marque un moment clé pour la plateforme. Cette reconnaissance souligne la précision inégalée de Powerdrill AI dans la compréhension et la réponse aux requêtes complexes, notamment lorsqu’il s’agit de textes longs et détaillés. Le benchmark QuALITY, réputé pour ses cas de test difficiles, évalue la capacité des modèles à comprendre des passages étendus et répondre avec exactitude, un défi nécessitant des capacités avancées de compréhension et de traitement sophistiqué. En surpassant ses concurrents, Powerdrill AI a démontré sa supériorité pour gérer des scénarios de données réelles, consolidant ainsi sa position de leader dans l’interprétation des requêtes assistée par IA.
Cette réussite valide non seulement l’efficacité des stratégies et technologies sous-jacentes à Powerdrill AI, mais ouvre également la voie à son développement futur. Grâce à cette réalisation, Powerdrill AI est bien positionné pour étendre ses capacités, affinant ses modèles pour traiter des tâches encore plus complexes avec une efficacité accrue. À l’avenir, l’accent sera probablement mis sur l’optimisation de la latence, la réduction des coûts, et l’amélioration de la capacité du système à traiter des textes encore plus longs et détaillés.
Ce succès stimulera l’innovation continue, permettant à Powerdrill AI de maintenir sa position de leader dans le traitement des requêtes basé sur l’IA et d’étendre ses applications dans divers domaines.
Essayez-le dès maintenant : /