Comment automatiser les rapports de données depuis Excel avec Powerdrill AI

Introduction
La création manuelle de rapports de données à partir d’Excel peut être une tâche frustrante et chronophage. Elle implique souvent le traitement de grandes bases de données, l’exécution de calculs répétitifs et la mise en forme minutieuse des tableaux et graphiques. Ces tâches sont non seulement fastidieuses, mais aussi sujettes aux erreurs humaines, ce qui peut nuire à la qualité des décisions.
Grâce aux avancées de l’IA, le reporting de données a été transformé, permettant aux utilisateurs de se concentrer sur l’analyse plutôt que sur le travail manuel. Dans ce guide, nous verrons comment Powerdrill simplifie la création de rapports à partir de fichiers Excel en un seul clic.
Comprendre le reporting automatisé de données
Qu’est-ce que le reporting automatisé de données ?
Le reporting automatisé de données consiste à utiliser des technologies avancées, telles que l’intelligence artificielle (IA) et le machine learning, pour rationaliser le processus de création de rapports structurés et pertinents à partir de données brutes. Contrairement aux méthodes traditionnelles qui reposent fortement sur les calculs et la mise en forme manuels, l’automatisation permet aux organisations de :
Gagner du temps : générer des rapports en quelques minutes, réduisant ainsi les heures consacrées au travail manuel.
Améliorer la précision : minimiser les risques d’erreurs humaines dans les calculs et l’interprétation des données.
Assurer la cohérence : maintenir l’uniformité des structures et formats de rapports.
Obtenir des insights : exploiter l’IA pour détecter tendances, motifs et anomalies souvent invisibles à l’œil nu.
En intégrant le traitement du langage naturel et le machine learning, les outils de reporting automatisé peuvent également interpréter des ensembles de données complexes, recommander les visualisations les plus pertinentes et personnaliser les rapports selon les besoins spécifiques. Cela en fait un atout précieux pour les entreprises souhaitant améliorer leur efficacité et leur prise de décision.
Outils populaires de reporting automatisé
Powerdrill : offre des fonctionnalités complètes d’analyse et de reporting pilotées par l’IA.
Tableau : se concentre sur les visualisations interactives, mais nécessite une configuration manuelle.
Microsoft Power BI : propose des capacités de reporting robustes, mais l’automatisation peut demander une courbe d’apprentissage.
Guide étape par étape pour automatiser le reporting de données avec Powerdrill
Pour que toutes les informations soient accessibles à tous, nous utilisons un jeu de données public de la Banque mondiale. Vous pouvez télécharger ce jeu de données via le lien suivant : https://datacatalog.worldbank.org/search/dataset/0038015?version=10
Sinon, vous pouvez simplement visiter notre discover channel pour simplifier votre processus de test. Avec cette méthode, vous n’avez pas besoin de suivre les étapes ci-dessous : il vous suffit de cliquer sur le bouton Générer le rapport de données.
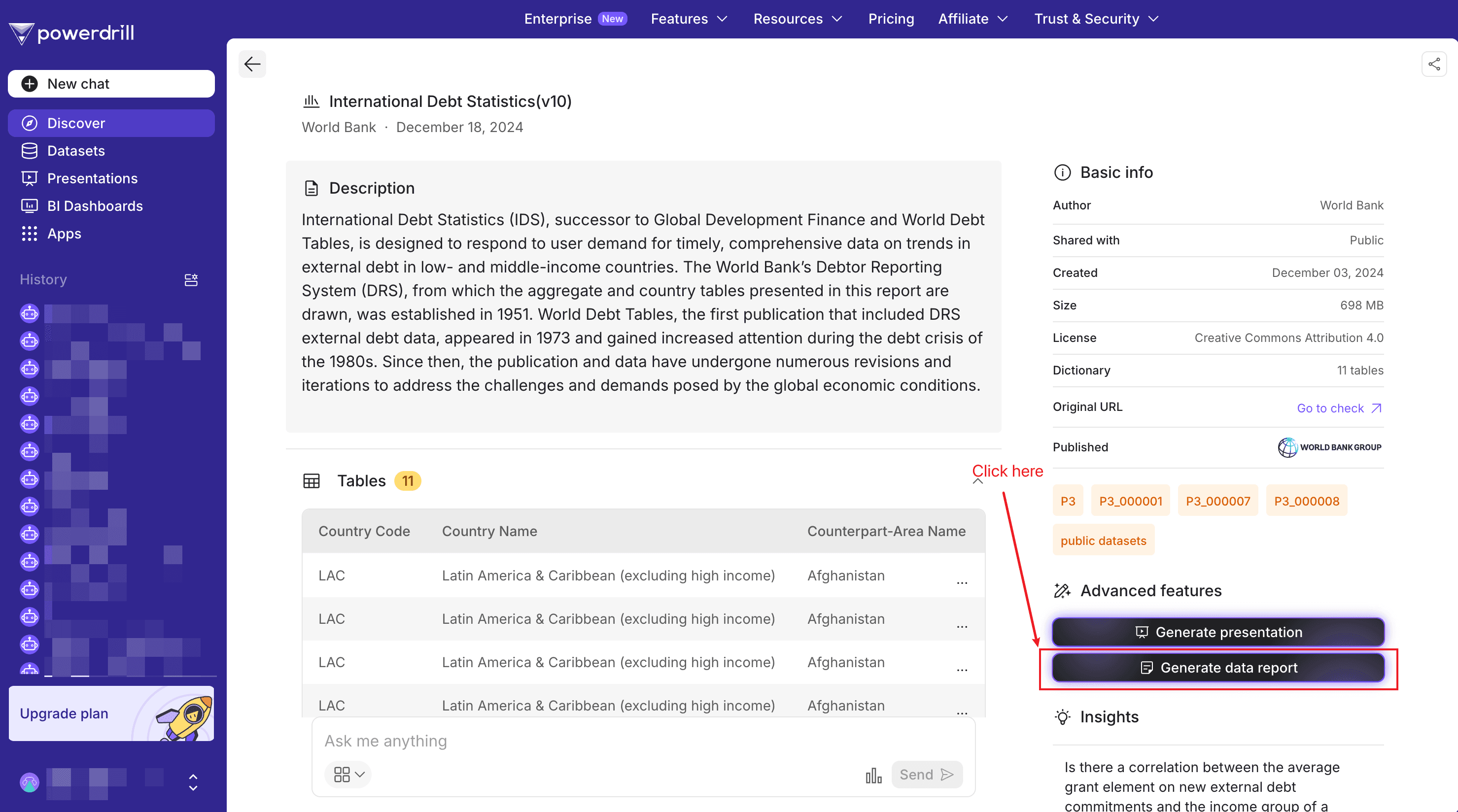
Étape 1. Téléchargez vos données Excel
Après vous être connecté à Powerdrill, localisez l'agent Générateur de Rapports de Données IA , cliquez sur Commencer et téléchargez vos fichiers Excel.
Vous pouvez télécharger jusqu'à 10 fichiers Excel/CSV/TSV à la fois. Dans cet exemple d'ensemble de données, nous téléchargeons 5 fichiers.
Étape 2. Attendez la complétion du reporting
Attendez 1 à 2 minutes, puis votre rapport de données est prêt à être emporté.

FAQ
Puis-je utiliser Powerdrill avec plusieurs fichiers ?
Oui, Powerdrill permet de téléverser jusqu’à 10 fichiers Excel, CSV ou TSV simultanément.
Quels types d’insights puis-je générer ?
Powerdrill fournit des insights sur les tendances, les distributions et les indicateurs clés adaptés à votre jeu de données.
L’outil convient-il aux utilisateurs non techniques ?
Absolument ! L’interface intuitive de Powerdrill et son automation pilotée par l’IA le rendent facile à utiliser pour tous.
Conclusion
Les capacités IA de Powerdrill vous permettent de transformer facilement des données brutes en insights exploitables. En automatisant le reporting de données, vous pouvez supprimer les tâches manuelles, réduire les erreurs et vous concentrer sur la prise de décision. Commencez dès aujourd’hui avec Powerdrill et révolutionnez votre manière de gérer le reporting de données !
Si vous souhaitez consulter les détails du rapport, veuillez voir la pièce jointe ci-dessous.
Pièce jointe : Vue d’ensemble complète de la dette internationale et des indicateurs économiques
Voici le résumé du contenu extrait du rapport.
Quels sont les codes de séries les plus courants associés à chaque code pays dans le fichier IDS_Country-SeriesMetaData.csv ?
Analyse des codes de séries
Regroupement des données : le jeu de données a été regroupé par « Code pays » et « Code série » pour compter les occurrences.
Séries les plus fréquentes : le Code série le plus fréquent pour chaque code pays a été identifié.
Insights visuels
Représentation en histogramme : un histogramme illustre la fréquence des codes de séries pour chaque pays.
Code série dominant : le graphique met en évidence les codes de séries les plus courants dans différents pays.
Conclusion et principaux enseignements
Code série le plus courant : le code série « Population, total » est le plus fréquent dans tous les pays.
Indicateur clé : les données de population constituent un indicateur clé, collecté de manière cohérente dans le jeu de données, soulignant son importance dans les efforts mondiaux de collecte de données.
Comment la distribution des groupes de revenus varie-t-elle à travers différentes régions dans l'ensemble de données IDS_CountryMetaData_table_0.csv ?
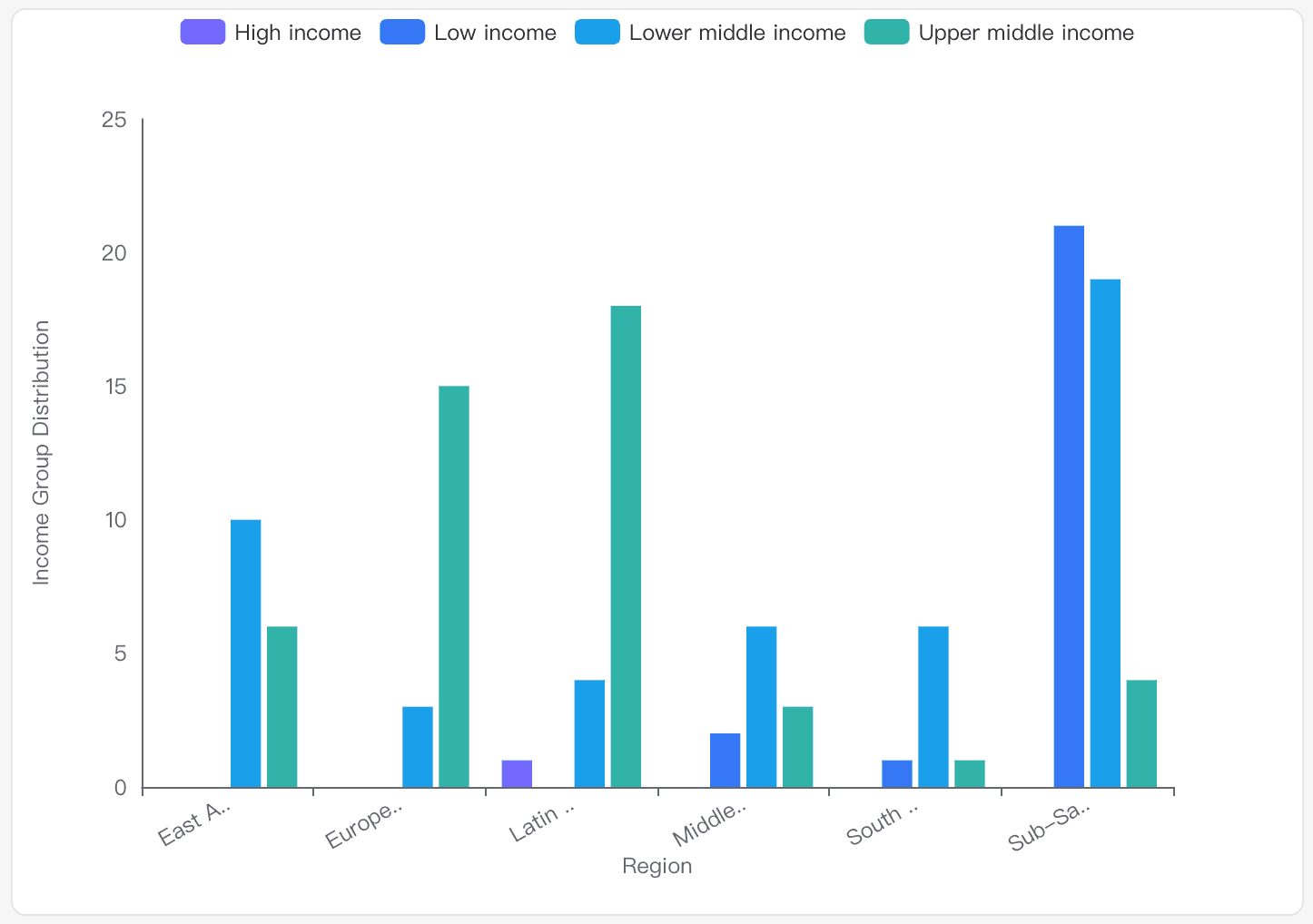
Aperçu
Faible revenu : principalement situé en Afrique subsaharienne et en Asie du Sud. Ce groupe est le plus représenté en Afrique subsaharienne avec 21 occurrences.
Revenu intermédiaire inférieur : réparti dans toutes les régions, avec une représentation importante en Asie du Sud, en Afrique subsaharienne et en Asie de l’Est & Pacifique.
Revenu intermédiaire supérieur : courant en Europe & Asie centrale, Amérique latine & Caraïbes et Asie de l’Est & Pacifique.
Revenu élevé : le moins représenté, avec des occurrences principalement en Amérique latine & Caraïbes.
Représentation visuelle
L’histogramme illustre la distribution, mettant en évidence la dominance des groupes à faible revenu dans des régions comme l’Afrique subsaharienne et la prévalence des revenus intermédiaires supérieurs en Europe & Asie centrale.
Analyse détaillée
Asie du Sud : principalement des pays à revenu intermédiaire inférieur.
Europe & Asie centrale : majoritairement des pays à revenu intermédiaire supérieur.
Moyen-Orient & Afrique du Nord : mix de pays à revenu intermédiaire inférieur et supérieur.
Afrique subsaharienne : forte concentration de pays à faible revenu.
Asie de l’Est & Pacifique : mix de pays à revenu intermédiaire inférieur et supérieur.
Amérique latine & Caraïbes : principalement des pays à revenu intermédiaire supérieur, avec quelques pays à revenu élevé.
Conclusion et principaux enseignements
Variations régionales : la distribution des groupes de revenu varie fortement selon les régions, certaines ayant une concentration plus élevée de groupes spécifiques.
Diversité économique : le jeu de données reflète la diversité économique, avec des régions comme l’Afrique subsaharienne comptant davantage de pays à faible revenu, tandis que l’Europe & Asie centrale et l’Amérique latine & Caraïbes comptent davantage de pays à revenu intermédiaire supérieur.
Analyse des facteurs potentiels influençant le timing du « dernier recensement de la population » et des « dernières données commerciales » dans différents pays
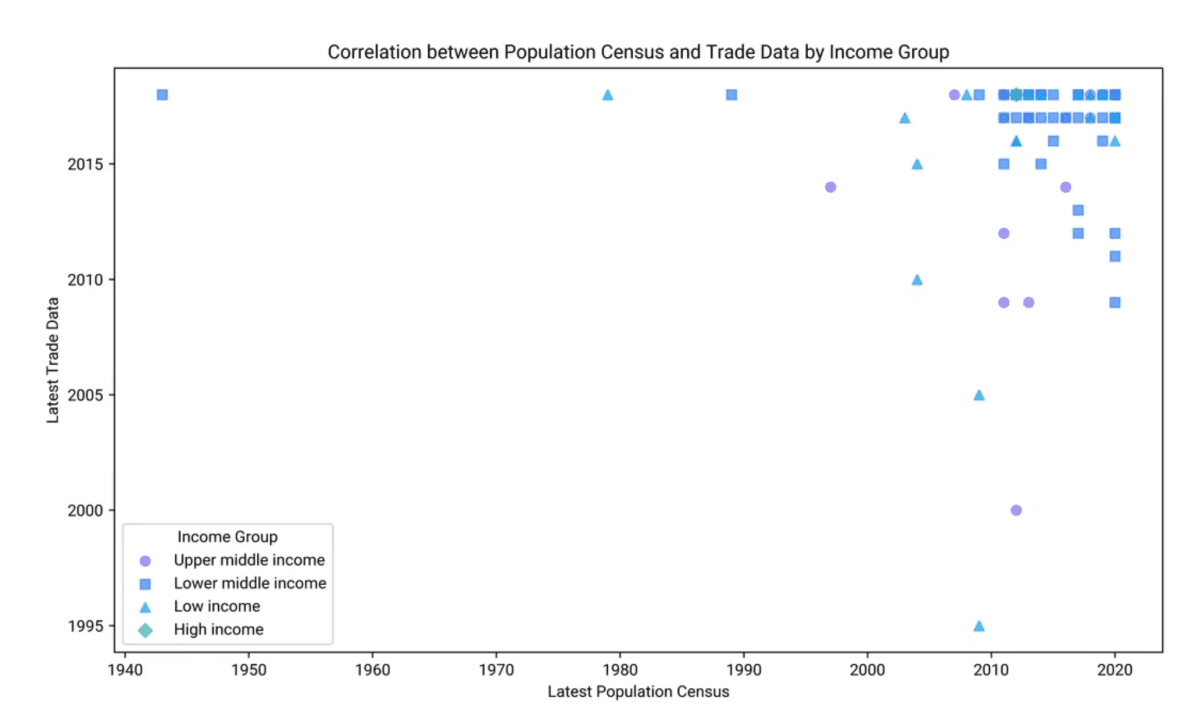
Facteurs influençant le calendrier du dernier recensement de la population
Ressources économiques : les pays disposant de davantage de ressources peuvent réaliser des recensements plus fréquemment, tandis que ceux avec moins de moyens peuvent avoir des calendriers irréguliers.
Stabilité politique : la stabilité permet des recensements réguliers, alors que les conflits peuvent provoquer des retards.
Capacité technologique : les technologies avancées permettent des recensements plus efficaces et plus fréquents.
Politique et gouvernance : les priorités gouvernementales peuvent dicter la régularité des recensements.
Soutien international : les directives et l’appui d’organisations internationales peuvent influencer le calendrier, surtout dans les pays en développement.
Facteurs influençant le calendrier des dernières données commerciales
Activité économique : un volume commercial élevé nécessite des mises à jour fréquentes des données.
Infrastructure de collecte des données : des systèmes robustes permettent des données plus récentes.
Environnement réglementaire : le respect des accords commerciaux peut affecter la fréquence des données.
Intégration économique mondiale : une forte intégration dans l’économie mondiale peut entraîner une collecte de données plus fréquente.
Capacité statistique : la compétence des offices nationaux à gérer les données influence le calendrier.
Corrélation entre le recensement de la population et le calendrier des données commerciales
Allocation des ressources : des ressources plus importantes peuvent permettre des mises à jour fréquentes à la fois pour le recensement et les données commerciales, créant ainsi une corrélation positive.
Priorisation politique : les pays privilégiant des politiques basées sur les données peuvent synchroniser la collecte des deux types de données.
Avancées technologiques : une gestion efficace des deux types de données peut conduire à un calendrier corrélé.
Influences externes : les exigences internationales peuvent améliorer les processus de collecte des deux types de données.
Niveau de développement économique : les pays développés ont généralement des mises à jour plus régulières, tandis que les pays en développement peuvent ne pas les avoir.
Conclusion et principaux enseignements
Impact des ressources et des politiques : les ressources économiques et les priorités politiques sont des facteurs clés pour déterminer la fréquence et la corrélation des mises à jour de données.
Facteurs technologiques et externes : la technologie avancée et les influences internationales peuvent améliorer la synchronisation des efforts de collecte de données.
Quelles sont les tendances concernant les 'Stocks de dette extérieure, total' Code de Série pour différents pays au fil du temps dans l'ensemble de données IDS_Country-SeriesMetaData.csv ?
Sources de données et estimations
Rapports et estimations nationales : les données de nombreux pays pour 2023 sont basées sur les rapports nationaux ou les estimations du personnel de la Banque mondiale. Par exemple, les données de l’Afghanistan incluent des estimations de la Banque mondiale, tandis que celles de l’Angola proviennent de la Banque nationale d’Angola.
Types de dette incluses
Catégories de dette : le jeu de données distingue entre la dette publique à long terme et garantie publiquement, la dette privée non garantie à long terme et la dette à court terme. Par exemple, les données de l’Argentine incluent à la fois la dette publique à long terme et la dette privée non garantie à long terme.
Contexte historique et ajustements
Restructuration et allègement de la dette : certains pays ont des ajustements historiques en raison d’accords de restructuration de dette, comme les accords du Club de Paris pour le Burundi ou l’allègement de la dette dans le cadre des initiatives HIPC et MDRI.
Participation aux initiatives d’allègement de la dette
Debt Service Suspension Initiative (DSSI) : plusieurs pays ont participé au DSSI en 2020 et 2021, ce qui a impacté les niveaux de dette déclarés.
Tendances régionales et par groupe économique
Variations selon le groupe de revenu : les tendances varient significativement selon les régions et les groupes de revenu, les pays à faible revenu participant souvent davantage aux initiatives d’allègement de la dette.
Tendances spécifiques par pays
Chine et Éthiopie : les données de la Chine reposent sur les estimations de la Banque mondiale et les rapports nationaux, tandis que celles de l’Éthiopie reflètent la réduction de la dette grâce aux initiatives HIPC et MDRI.
Limitations et exclusions des données
Données incomplètes : certains pays présentent des données partielles ou des exclusions, comme l’Irak, qui ne dispose pas de données sur la dette privée non garantie à long terme.
Conclusion et principaux enseignements
Sources de données mixtes : les tendances montrent un mélange de dépendance aux rapports nationaux, aux estimations de la Banque mondiale et aux initiatives internationales d’allègement de la dette.
Variabilité selon les régions : il existe des variations significatives dans les tendances de la dette extérieure selon les régions et les groupes de revenu, influencées par les conditions économiques et les accords historiques.
Quelle est la distribution des 'Groupes de Revenus' à travers différentes 'Catégories de Prêt' dans l'ensemble de données IDS_CountryMetaData_table_0.csv ?
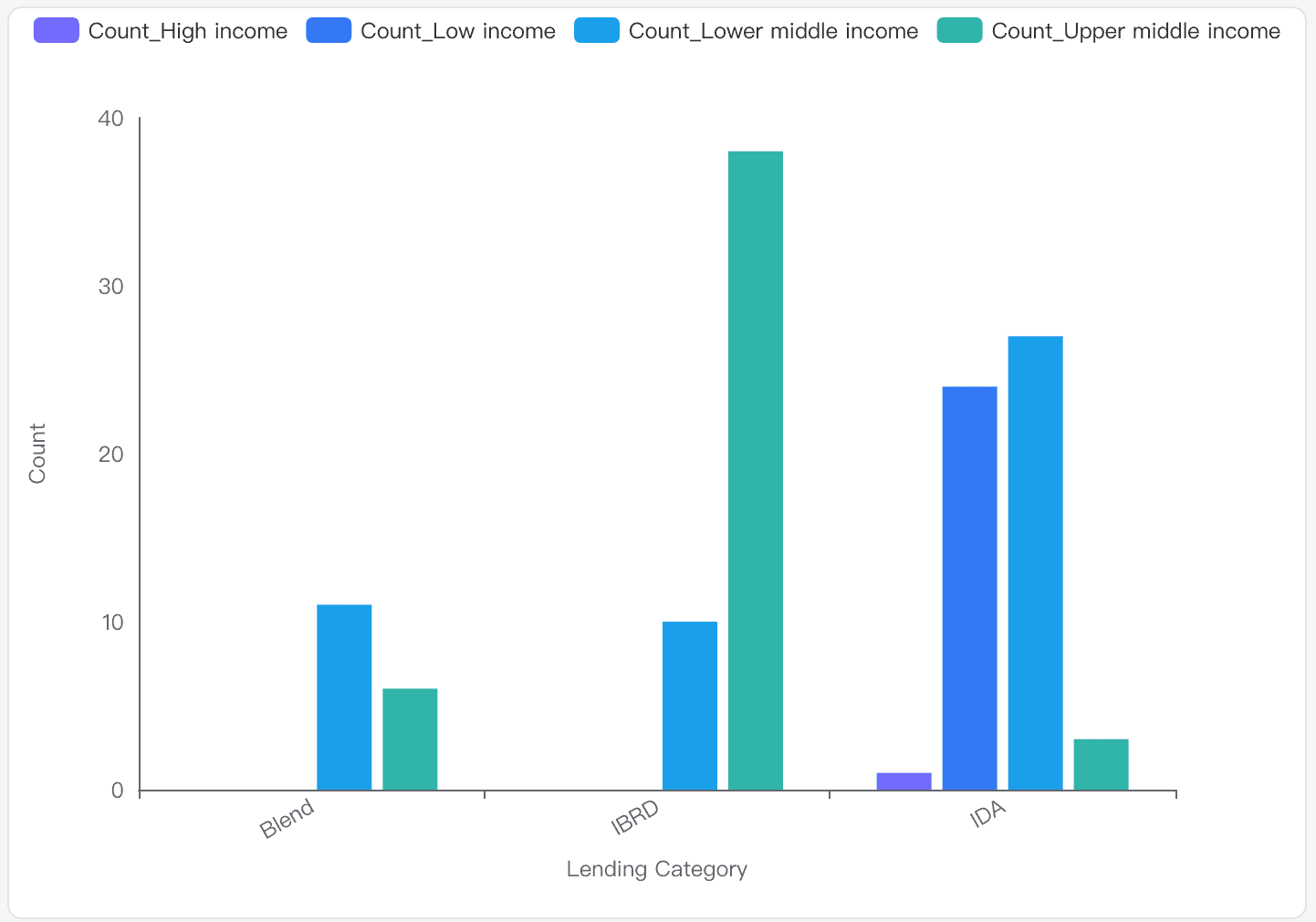
Analyse des données
Groupes de revenu : le jeu de données comprend « Haut revenu », « Faible revenu », « Revenu intermédiaire inférieur » et « Revenu intermédiaire supérieur ».
Catégories de prêts : les catégories sont IDA, Blend et IBRD.
Statistiques de comptage : les effectifs varient de 1 à 38, avec une moyenne de 15.
Insights visuels
IDA : se compose principalement des groupes faible revenu et revenu intermédiaire inférieur.
IBRD : inclut principalement les pays à revenu intermédiaire supérieur.
Blend : présente un mélange des groupes revenu intermédiaire inférieur et revenu intermédiaire supérieur.
Répartition détaillée
IDA :
Faible revenu : 24
Revenu intermédiaire inférieur : 27
Revenu intermédiaire supérieur : 3
Haut revenu : 1
IBRD :
Faible revenu : 0
Revenu intermédiaire inférieur : 10
Revenu intermédiaire supérieur : 38
Haut revenu : 0
Blend :
Faible revenu : 0
Revenu intermédiaire inférieur : 11
Revenu intermédiaire supérieur : 6
Haut revenu : 0
Conclusion et principaux enseignements
Catégorie IDA : sert principalement les pays à faible revenu et revenu intermédiaire inférieur.
Catégorie IBRD : dominée par les pays à revenu intermédiaire supérieur.
Catégorie Blend : un mélange équilibré des groupes revenu intermédiaire inférieur et revenu intermédiaire supérieur.
Y a-t-il des différences notables dans la méthodologie du 'Système des Comptes Nationaux' utilisée par les pays dans différentes régions dans l'ensemble de données IDS_CountryMetaData_table_0.csv ?
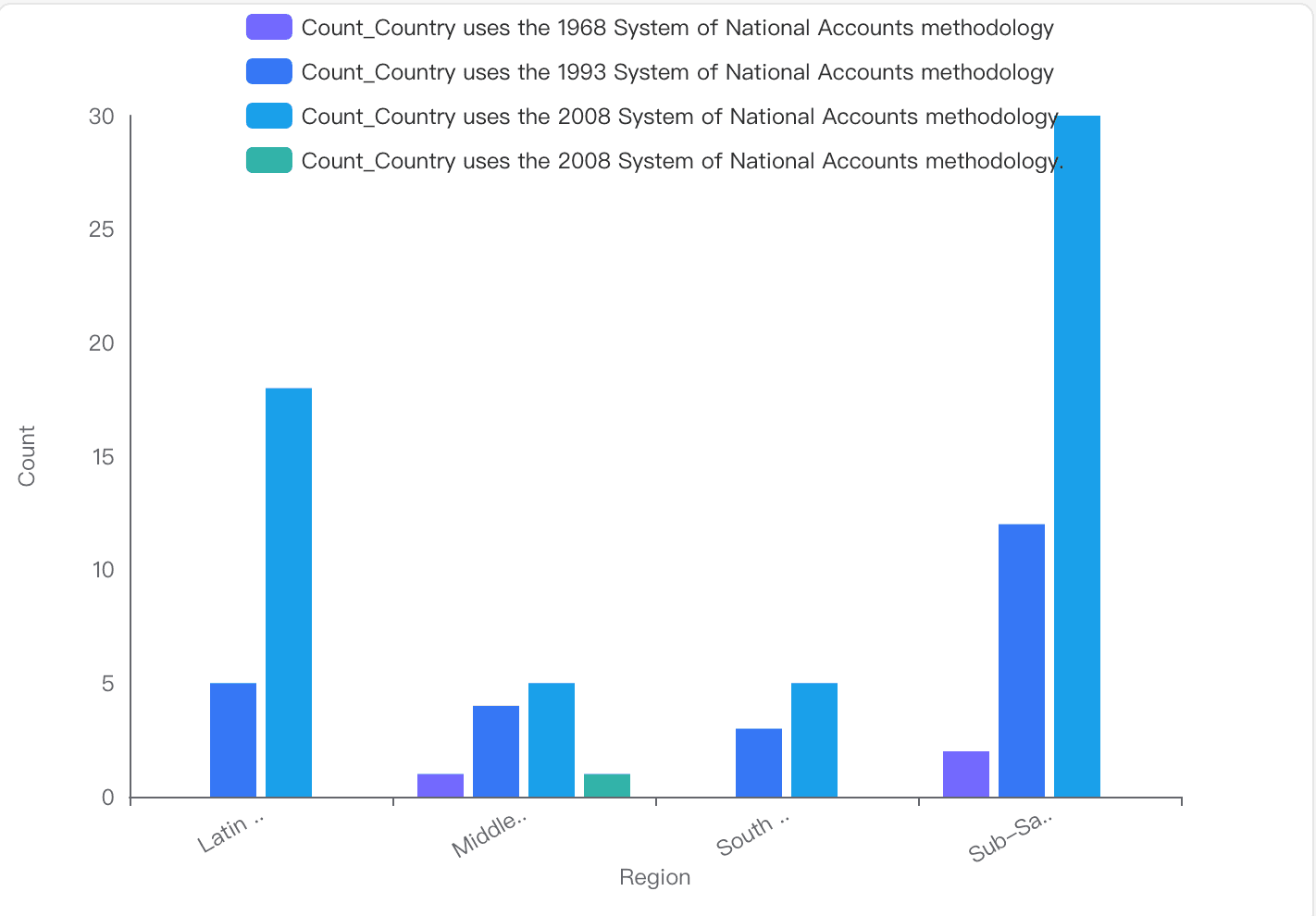
Répartition par méthodologie
Système de comptabilité nationale 1993 (SCN 1993) : utilisé par des pays de différentes régions, notamment Asie du Sud, Afrique subsaharienne et Asie de l’Est & Pacifique.
Système de comptabilité nationale 2008 (SCN 2008) : principalement utilisé en Europe & Asie centrale, Amérique latine & Caraïbes, et Asie de l’Est & Pacifique.
Système de comptabilité nationale 1968 (SCN 1968) : moins courant, mais toujours en usage dans des régions comme le Moyen-Orient & Afrique du Nord.
Insights visuels
Afrique subsaharienne : un nombre significatif de pays utilisent le SCN 2008, certains continuant avec les versions 1993 et 1968.
Amérique latine & Caraïbes : adoption principalement du SCN 2008, reflétant une uniformité dans la méthodologie la plus récente.
Moyen-Orient & Afrique du Nord : mélange de méthodologies, certains pays utilisant encore les versions plus anciennes comme le SCN 1968.
Conclusion et principaux enseignements
Adoption diversifiée : il existe des différences notables dans l’adoption des méthodologies SCN selon les régions, reflétant les niveaux variables de développement économique et de capacité statistique.
Prédominance du SCN 2008 : bien que largement adopté, les versions plus anciennes comme le SCN 1993 et 1968 restent en usage dans certaines régions, soulignant les défis de la mise à jour des systèmes statistiques à l’échelle mondiale.
Comment la 'Méthode d'Agrégation' varie-t-elle à travers différents 'Sujets' dans l'ensemble de données IDS_SeriesMetaData_table_0.csv ?
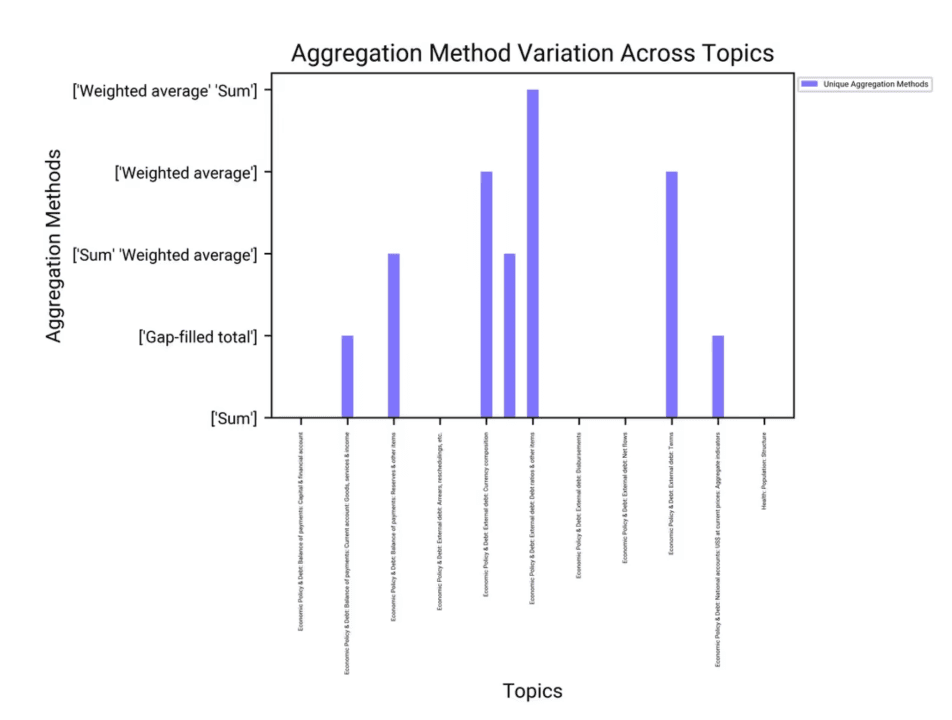
Analyse des méthodes d’agrégation
Somme : c’est la méthode d’agrégation la plus couramment utilisée pour divers sujets, y compris les politiques économiques et les questions liées à la dette.
Moyenne pondérée : employée pour des sujets spécifiques comme la dette extérieure et la composition monétaire.
Total complété par interpolation (Gap-filled Total) : appliqué aux sujets liés à la balance des paiements et aux comptes nationaux.
Insights visuels
Distribution : l’histogramme montre que la méthode Somme est prédominante pour la plupart des sujets, ce qui souligne sa large applicabilité.
Méthodes spécifiques : certains sujets, comme la dette extérieure et la composition monétaire, utilisent la Moyenne pondérée, illustrant la nécessité d’une agrégation plus nuancée dans ces domaines.
Conclusion et principaux enseignements
Prédominance de la méthode Somme : largement utilisée, elle est adaptée à l’agrégation de données dans de nombreux sujets économiques et liés à la santé.
Méthodes spécialisées : l’usage de la Moyenne pondérée et du Total complété par interpolation pour certains sujets montre une approche personnalisée de l’agrégation, reflétant la nature spécifique des données dans ces domaines.