Préparation des données : Glossaire complet 2025
Shein·

La préparation des données est le processus de transformation des données brutes en un format propre, organisé et structuré, adapté à l’analyse, à la modélisation ou à d’autres tâches basées sur les données. Elle comprend plusieurs étapes visant à améliorer la qualité des données, garantir leur cohérence et les rendre pertinentes pour l’usage prévu. En corrigeant les erreurs, les valeurs manquantes ou les incohérences de format, la préparation des données transforme des données chaotiques en une ressource précieuse pour obtenir des insights fiables et faciliter la prise de décision.

La première étape consiste à rassembler les données brutes provenant de toutes les sources pertinentes. Cela peut inclure des systèmes internes comme des bases de données et des feuilles de calcul, des sources externes telles que des API ou un stockage cloud, voire des entrées en temps réel provenant de capteurs et d’objets connectés (IoT). Dans certains cas, les données peuvent également être saisies manuellement. Il est essentiel d’identifier les sources pertinentes pour vos objectifs spécifiques et de s’assurer que tous les points de données nécessaires sont capturés sans redondance ni lacune.
Une fois les données collectées, il faut les examiner attentivement. Cela implique d’analyser la structure (lignes, colonnes, types de données), d’identifier l’étendue des valeurs et de repérer les problèmes précoces tels que les entrées manquantes, les doublons ou les valeurs aberrantes. Cette étape permet d’évaluer si les données sont exploitables telles quelles ou si un travail supplémentaire est nécessaire avant l’analyse.
Le nettoyage des données corrige les problèmes identifiés lors de l’inspection et peut inclure :
Suppression des doublons pour éviter des résultats biaisés.
Correction des erreurs, comme les fautes de frappe dans les noms ou les formats de date incorrects.
Gestion des valeurs manquantes par imputation (remplissage basé sur la logique ou la moyenne) ou suppression.
Gestion des valeurs aberrantes pour éviter que des données extrêmes ne faussent l’analyse.
Avec des données propres, l’étape suivante consiste à les transformer en une structure adaptée à l’analyse ou à la modélisation. Les transformations typiques incluent :
Normalisation des valeurs pour uniformiser les différentes échelles.
Agrégation des données en indicateurs résumés (ex. : ventes moyennes par région).
Encodage des variables catégorielles (comme “Oui/Non” ou catégories de couleur) en formats numériques.
Restructuration des colonnes ou fusion/scission des champs pour correspondre au format souhaité.
Lorsque l’on travaille avec des données provenant de plusieurs systèmes — par exemple, combiner les ventes issues d’un CRM avec le trafic web d’une plateforme analytique — il est crucial d’intégrer toutes les sources dans un jeu de données unique. Cette étape peut nécessiter d’aligner les schémas, de résoudre les conflits (différents formats de date) et de joindre les enregistrements via des identifiants uniques. Une intégration correcte fournit une vue globale et assure la cohérence entre les sources.
Avant l’analyse ou la modélisation, la validation est essentielle. Cela consiste à :
Vérifier que toutes les transformations ont été correctement appliquées.
Contrôler l’exhaustivité et l’intégrité du jeu de données.
S’assurer que les données correspondent aux objectifs du projet, aux règles métier ou aux exigences de recherche.
La validation agit comme un dernier contrôle qualité pour confirmer que tout est prêt à être utilisé.
La dernière étape consiste à stocker le jeu de données préparé dans un environnement sécurisé et accessible. Cela peut être une base de données relationnelle, un entrepôt de données cloud ou un système de fichiers partagé, selon les outils et besoins de l’équipe. Un stockage approprié permet de récupérer facilement les données pour l’analyse, les rapports ou l’utilisation dans des tableaux de bord et modèles.
Des données précises et cohérentes sont indispensables pour prendre de bonnes décisions. La préparation des données élimine les erreurs et les incohérences, offrant ainsi une base fiable pour l’analyse et la prise de décision.
Des données bien préparées réduisent le temps que les analystes et data scientists consacrent à corriger des problèmes. Ils peuvent ainsi se concentrer sur la génération d’insights et la création de valeur, accélérant l’ensemble du processus analytique.
En apprentissage automatique, des données d’entrée propres et homogènes sont essentielles. Une préparation rigoureuse des données permet d’obtenir de meilleurs résultats d’entraînement et des prédictions plus précises des modèles.
Lorsqu’on traite des données issues de différents systèmes, la préparation garantit une intégration fluide dans un jeu de données unique. Cela simplifie les analyses croisées et offre une vision plus complète et cohérente.
Des données de qualité, bien préparées, soutiennent une prise de décision plus rapide et plus intelligente. Elles permettent d’identifier les tendances, de révéler des opportunités et de réduire les risques — un atout stratégique pour toute organisation.
À l’ère des mainframes, les données ont commencé à être stockées électroniquement. La préparation consistait principalement en une saisie manuelle et une validation de base, souvent effectuées par des opérateurs.
L’apparition des bases de données relationnelles et du langage SQL a rendu les données plus accessibles et mieux structurées. Cependant, une grande partie du nettoyage et du formatage restait manuelle.
Avec l’explosion du volume et de la complexité des données, des outils comme Hadoop et Spark ont permis un traitement et une préparation à grande échelle. Ces technologies ont marqué le passage vers l’automatisation et la montée en puissance des architectures distribuées.
Aujourd’hui, l’intelligence artificielle et le machine learning ont révolutionné la préparation des données. Les outils modernes peuvent désormais :
Détecter automatiquement les schémas et anomalies ;
Suggérer des transformations adaptées ;
Automatiser les tâches répétitives.
Cette évolution rend la préparation des données plus rapide, plus fiable et moins sujette aux erreurs humaines — ouvrant la voie à une analyse efficace et pilotée par les insights.
Dans un monde axé sur les données, la préparation des données est devenue une compétence essentielle dans de nombreux métiers. Les analystes de données, les data scientists et les spécialistes de la business intelligence y consacrent une grande partie de leur temps, car la qualité de leurs analyses en dépend directement.
Mais cette compétence ne se limite pas aux profils techniques. Les marketeurs préparent les données clients pour personnaliser leurs campagnes. Les analystes financiers s’appuient sur des enregistrements bien structurés pour établir des budgets et des prévisions fiables. Même les professionnels de santé dépendent de données patient correctement préparées pour poser des diagnostics précis et rédiger des rapports fiables.
De plus en plus d’entreprises reconnaissent aujourd’hui la valeur de la préparation des données et investissent dans des programmes de formation pour développer cette compétence au sein de leurs équipes. Les collaborateurs maîtrisant la préparation des données peuvent extraire plus rapidement des insights, soutenir la prise de décision et contribuer directement à la réussite de l’entreprise — en faisant l’une des compétences les plus recherchées sur le marché du travail moderne.
Imaginons une équipe marketing souhaitant évaluer la réaction des clients à une campagne récente. Elle collecte des données provenant de plusieurs sources :
Plateformes d’e-mails : taux d’ouverture, taux de clics
Réseaux sociaux : métriques d’engagement
Systèmes de ventes : taux de conversion
Pour rendre ces données exploitables, l’équipe commence par les nettoyer — suppression des adresses e-mail invalides, correction des noms mal orthographiés —, puis fusionne toutes les sources en un seul jeu de données. Ensuite, elle transforme les données en calculant les taux de conversion par segment de clientèle et valide l’ensemble pour garantir précision et cohérence avant de lancer l’analyse.
Une entreprise manufacturière souhaite optimiser sa production à l’aide des données issues de capteurs d’équipement. Les données brutes contiennent souvent :
Des relevés de capteurs manquants
Des horodatages incohérents
Le processus de préparation consiste à combler les valeurs manquantes par interpolation, à convertir les horodatages dans un format standard et à intégrer les données des capteurs aux journaux de production. Cela permet de créer un jeu de données complet et fiable, utilisable pour améliorer les performances et l’efficacité des opérations.
Un établissement d’enseignement souhaite évaluer les résultats de ses étudiants à partir de données telles que :
Les registres de présence
Les notes aux examens
Les travaux remis
Les étapes de préparation comprennent la suppression des doublons d’élèves, le calcul des moyennes par matière et l’intégration des données pour identifier des schémas — par exemple, la corrélation entre la présence et la performance académique. Cette approche aide les enseignants à prendre des décisions éclairées pour améliorer les résultats d’apprentissage.
Lorsqu’il s’agit de préparer les données pour l’analyse, disposer des bons outils peut tout changer. Du nettoyage à la transformation, en passant par l’intégration et la validation, ces plateformes facilitent et accélèrent l’ensemble du processus de préparation des données. Voici un aperçu des outils les plus utilisés aujourd’hui dans ce domaine :
Powerdrill est une plateforme moderne d'exploration de données alimentée par l'IA conçue pour une analyse rapide et intuitive. Contrairement aux moteurs SQL traditionnels, Powerdrill permet de poser des questions en langage naturel et d’obtenir instantanément des visualisations pertinentes à partir de feuilles de calcul ou de bases de données — sans écrire une seule ligne de code.
Cet outil est idéal pour les utilisateurs métier et les analystes qui souhaitent accéder rapidement à des insights sans compétences techniques avancées. Il simplifie la préparation des données en détectant automatiquement les schémas, en corrigeant les incohérences et en aidant à structurer les données pour l’analyse grâce à une interface conversationnelle.
Alteryx est une plateforme d’analyse de données largement adoptée, réputée pour sa facilité d’utilisation. Grâce à une interface de type drag-and-drop, les utilisateurs peuvent connecter, nettoyer, enrichir et transformer les données issues de multiples sources — sans compétences en programmation.
Elle est particulièrement utile pour les profils techniques comme non techniques, offrant l’automatisation des tâches répétitives et la compatibilité avec une grande variété de formats, de bases de données et de services cloud. Alteryx est très prisé dans des domaines comme le marketing, la finance ou les opérations, où les équipes doivent préparer rapidement des données pour des rapports ou tableaux de bord.
Trifacta exploite le machine learning pour aider les utilisateurs à préparer des ensembles de données volumineux et complexes. La plateforme identifie automatiquement les types de données, met en évidence les erreurs et suggère des transformations adaptées, facilitant ainsi le nettoyage et la structuration des données de manière efficace.
Son interface visuelle et ses recommandations intelligentes en font un excellent choix pour les équipes travaillant avec des données non structurées ou désordonnées. Désormais intégrée à Google Cloud sous le nom Cloud Dataprep, Trifacta reste une solution de référence pour une préparation des données intuitive et optimisée par l’intelligence artificielle.
Talend est une plateforme open source puissante dédiée à l’intégration et à la préparation des données. Elle prend en charge un large éventail de sources — bases de données, services cloud, API — et permet de créer des flux de travail complexes pour nettoyer, transformer et intégrer les données à grande échelle.
Talend se distingue particulièrement dans les environnements d’entreprise où les données doivent circuler de manière sécurisée et cohérente entre différents systèmes. La solution est disponible en version gratuite open source, ainsi qu’en éditions commerciales offrant des fonctionnalités avancées et des capacités cloud natives.
IBM DataStage est un outil d’intégration de données hautes performances, conçu pour répondre aux besoins de préparation complexes et à grande échelle. Il permet aux organisations de créer, d’automatiser et de gérer des pipelines de données dans des environnements hybrides et multicloud.
Grâce à ses puissantes fonctions de transformation, à la gestion des flux en temps réel et au contrôle de la qualité des données, DataStage est idéal pour les entreprises manipulant de grands volumes de données structurées. Il s’intègre parfaitement à l’écosystème de données et d’IA d’IBM, offrant une solution robuste pour les infrastructures de données d’entreprise.
Le choix du bon outil de préparation des données dépend avant tout de vos besoins : facilité d’utilisation, évolutivité, automatisation ou assistance par l’IA. Des plateformes légères comme Powerdrill, adaptées aux utilisateurs métiers, aux solutions robustes comme IBM DataStage, pensées pour les grandes entreprises, il existe aujourd’hui une solution pour chaque étape de votre parcours analytique.
Préparez l'ensemble de données que vous souhaitez télécharger. Cliquez sur le « Télécharger » bouton sous la boîte de dialogue pour télécharger votre fichier. Une fois le téléchargement terminé, vous serez dirigé vers la page d'analyse des données.
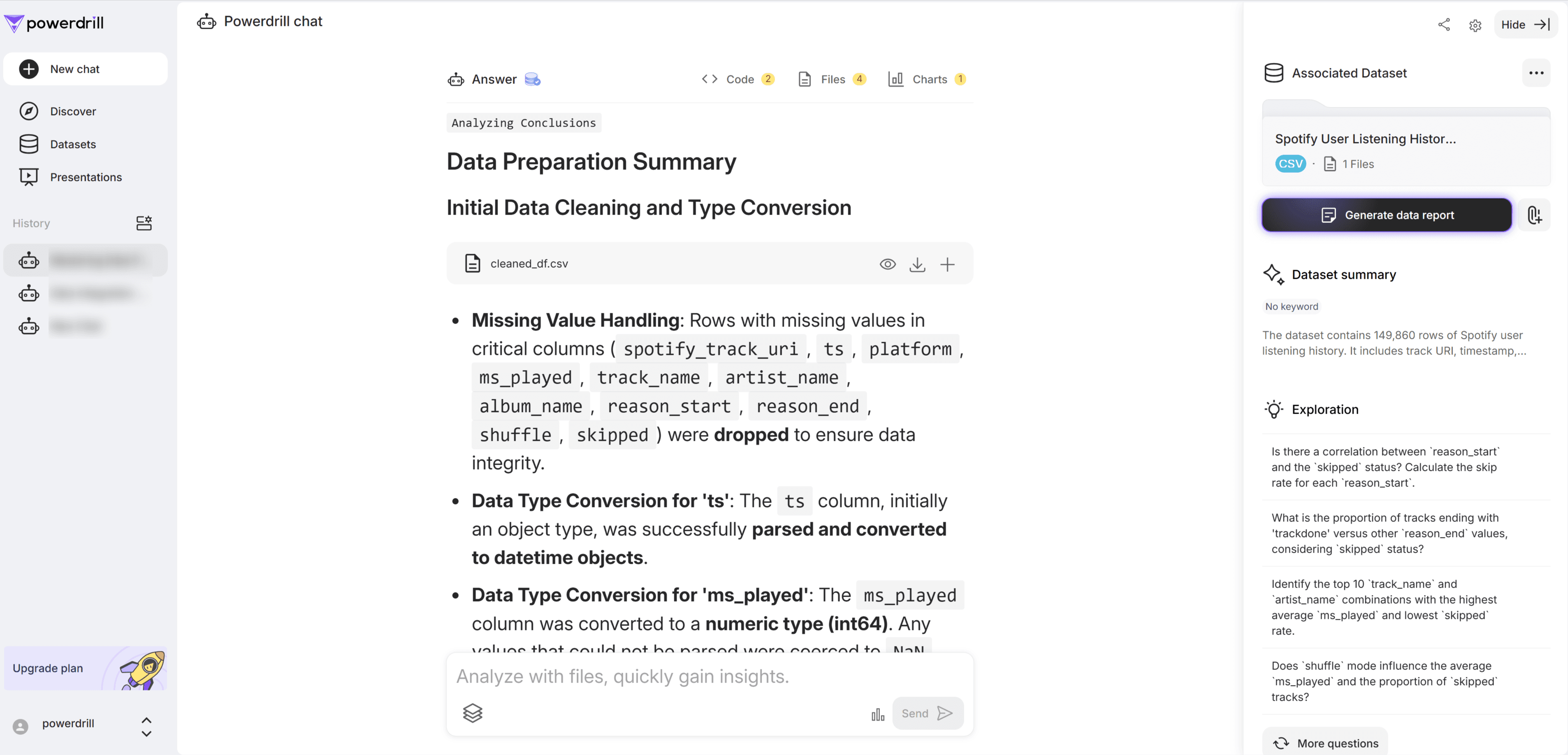
Dans la boîte de dialogue, saisissez une description claire de votre demande de préparation des données — par exemple : « Aide-moi à préparer mes données. » Ensuite, cliquez sur Envoyer. Powerdrill commencera automatiquement à traiter votre demande.
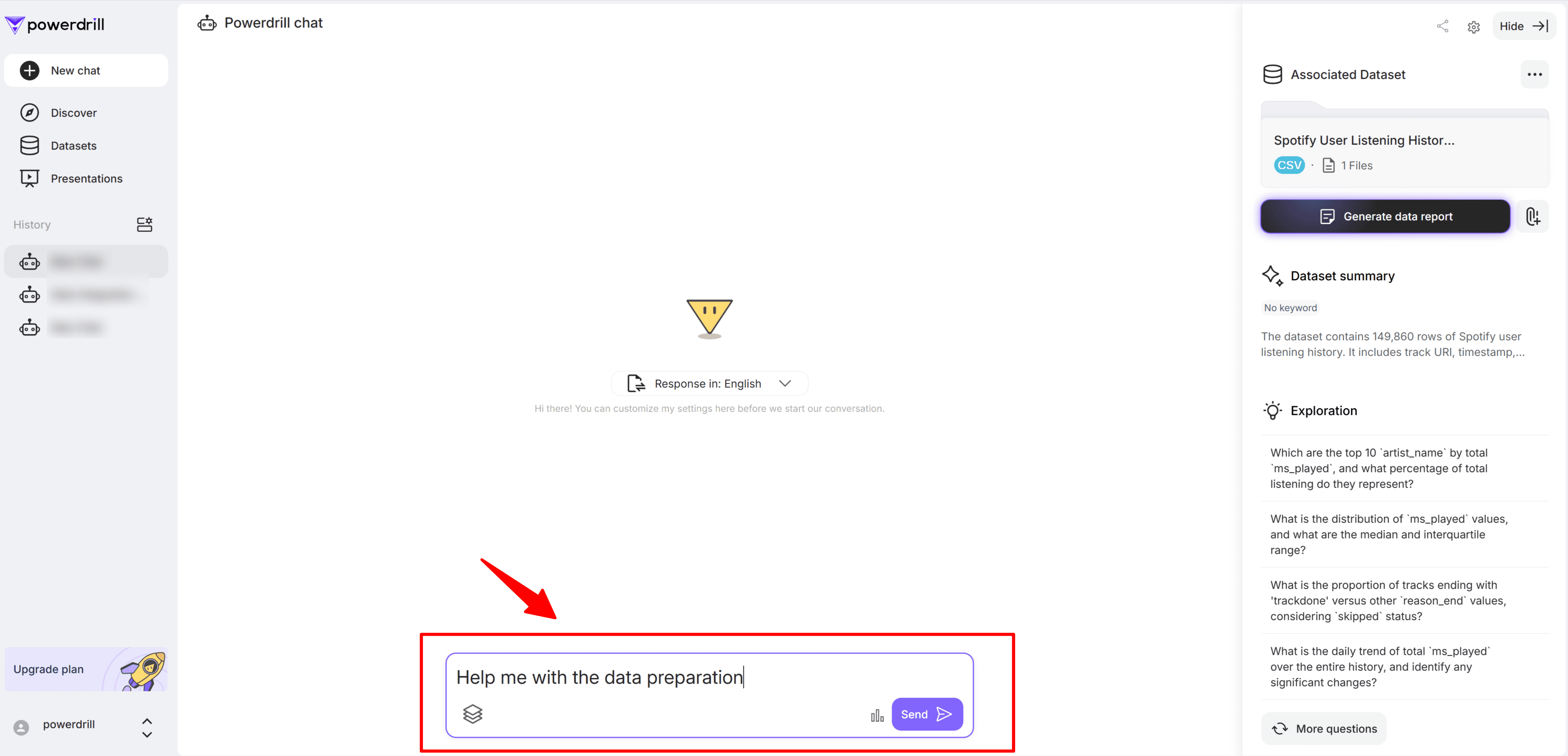
Une fois l’opération terminée, Powerdrill renvoie un jeu de données unifié. L’outil explique comment les valeurs manquantes ont été traitées, confirme le processus de préparation et prépare vos données pour des analyses plus approfondies.