Data Facts : analyse complète des tendances du diagnostic du cancer du sein et de l’importance des variables

Ce jeu de données met en évidence les tendances et la dynamique du diagnostic du cancer du sein, en intégrant des informations détaillées sur la répartition des cas malins et bénins, l’analyse des variables, la visualisation des données et la modélisation prédictive.
À partir de l’analyse de ces données sur le cancer du sein avec Powerdrill, examinons les principaux enseignements et tendances liés au diagnostic et à l’importance des variables dans la prédiction des résultats du cancer du sein.
À partir de ce jeu de données, Powerdrill identifie et analyse les métadonnées, puis propose les requêtes pertinentes suivantes :
1. Distribution globale
Quelle est la répartition des cas malins (diagnostic = 1) et bénins (diagnostic = 0) dans le jeu de données sur le cancer du sein ?
Quelles sont la moyenne, la médiane, l’écart-type, le minimum, le maximum et les quartiles pour chaque variable ?
En quoi les distributions de chaque variable diffèrent-elles entre les cas malins et bénins ? Observe-t-on des différences significatives au niveau des moyennes et des écarts-types ?
2. Analyse des variables
Quelles variables présentent des différences significatives entre les cas malins et bénins ? Utiliser des tests t ou des tests non paramétriques pour la comparaison.
Quelle est la corrélation entre chaque variable et le résultat du diagnostic (diagnostic) ? Calculer les coefficients de corrélation de Pearson ou de Spearman.
Quelles variables sont les plus importantes pour prédire le résultat du diagnostic ? Évaluer l’importance des variables à l’aide de modèles de régression linéaire ou de régression logistique.
3. Visualisation des données
Tracer des histogrammes ou des courbes de densité pour chaque variable afin d’illustrer la distribution des cas malins et bénins.
Utiliser des diagrammes en boîte (box plots) pour représenter la distribution des valeurs de chaque variable et comparer les différences entre les cas malins et bénins.
Créer des graphiques de paires (pair plots) pour visualiser les relations et les schémas de distribution entre les différentes variables.
Utiliser des cartes thermiques (heatmaps) pour afficher la matrice de corrélation entre les variables.
4. Réduction de dimension
Réaliser une analyse en composantes principales (ACP) et visualiser les deux premières composantes principales. Évaluer si elles permettent de distinguer efficacement les cas malins et bénins.
Calculer la proportion de variance expliquée par chaque composante principale afin de déterminer le nombre de composantes nécessaires pour expliquer la majeure partie de la variance.
Utiliser des techniques de réduction de dimension non linéaires, telles que t-SNE ou UMAP, pour explorer plus en profondeur la structure et la distribution des données.
5. Modélisation prédictive
Utiliser des modèles de régression logistique pour prédire le résultat du diagnostic et évaluer leurs performances à l’aide des métriques suivantes : exactitude, précision, rappel et score F1.
Tester des modèles d’arbres de décision pour la prédiction du diagnostic et comparer leurs performances à celles de la régression logistique.
Utiliser des modèles d’ensemble tels que les forêts aléatoires ou les arbres de gradient boosting, puis comparer leurs performances à celles des modèles individuels.
Évaluer la capacité de généralisation de chaque modèle à l’aide de la validation croisée afin de sélectionner le modèle le plus performant.
6. Sélection des variables
Utiliser l’importance des variables issue des forêts aléatoires pour identifier les variables les plus déterminantes dans le résultat du diagnostic.
Appliquer la méthode d’élimination récursive des variables (Recursive Feature Elimination, RFE) afin de sélectionner le sous-ensemble optimal de variables.
Utiliser une régularisation L1 (Lasso) pour la sélection des variables et évaluer l’efficacité des variables retenues.
7. Analyse des valeurs aberrantes
Identifier les valeurs aberrantes pour chaque variable à l’aide de diagrammes en boîte ou de la méthode de l’intervalle interquartile (IQR).
Analyser l’impact des valeurs aberrantes sur la distribution globale et les performances des modèles, et déterminer s’il est pertinent de les supprimer ou de les ajuster.
Utiliser des méthodes de clustering, telles que K-means ou DBSCAN, pour détecter d’éventuelles valeurs aberrantes dans les données.
8. Analyse par groupes
Regrouper les données selon différentes variables (par exemple, mean_radius, mean_texture) et analyser la moyenne et l’écart-type de ces variables au sein de chaque groupe.
Utiliser des diagrammes en boîte groupés ou des graphiques en violon pour comparer les distributions des variables entre les différents groupes.
Analyser les interactions entre les variables, notamment l’effet combiné de plusieurs variables sur le résultat du diagnostic.
Utiliser des tests du khi carré ou une analyse de la variance (ANOVA) afin d’évaluer l’association entre les variables groupées et le résultat du diagnostic.
Distribution globale
Répartition des cas malins et bénins
Cas malins (diagnostic = 1) : 212 cas
Cas bénins (diagnostic = 0) : 357 cas
Statistiques descriptives pour chaque variable
mean_radius :
Moyenne : 14,13
Écart-type : 3,52
Minimum : 6,98
Maximum : 28,11
mean_texture :
Moyenne : 19,29
Écart-type : 4,30
Minimum : 9,71
Maximum : 39,28
mean_perimeter :
Moyenne : 91,97
Écart-type : 24,30
Minimum : 43,79
Maximum : 188,50
mean_area :
Moyenne : 654,89
Écart-type : 351,91
Minimum : 143,50
Maximum : 2501,00
mean_smoothness :
Moyenne : 0,10
Écart-type : 0,01
Minimum : 0,05
Maximum : 0,16
Statistiques descriptives pour l’ensemble des variables
Moyenne : La moyenne globale des variables est de 130,17, avec un écart-type élevé de 259,33, ce qui indique une forte variabilité entre les moyennes des différentes variables.
Médiane : La médiane globale des variables est de 111,77, également associée à un écart-type élevé (217,59), suggérant une grande hétérogénéité dans la tendance centrale des variables.
Écart-type : L’écart-type moyen des variables est de 64,09, reflétant une dispersion des données variable selon les variables.
Minimum : La moyenne des valeurs minimales est de 34,01, certaines variables présentant un minimum aussi bas que 0,00.
Quartiles (Q1 et Q3) : Le premier quartile (Q1) présente une moyenne de 87,24, tandis que le troisième quartile (Q3) atteint une moyenne de 154,25, illustrant l’étendue des 50 % centraux des données.
Maximum : La moyenne des valeurs maximales est de 459,68, avec un écart-type très élevé (1002,50), indiquant que certaines variables possèdent des valeurs maximales nettement supérieures aux autres.
Différences de distribution entre les cas malins et bénins
Cas malins :
Moyenne : la moyenne des moyennes est de 95,34, avec un écart-type de 182,32.
Écart-type : l’écart-type moyen est de 25,31.
Cas bénins :
Moyenne : la moyenne des moyennes est de 188,82, avec un écart-type de 389,20.
Écart-type : l’écart-type moyen est de 66,13.
Différences significatives observées
Des différences significatives sont observées au niveau des moyennes et des écarts-types entre les cas malins et bénins.
Les cas bénins présentent des moyennes plus élevées pour les variables analysées que les cas malins, ce qui peut indiquer des valeurs de caractéristiques globalement plus importantes dans les cas bénins.
L’écart-type est également plus élevé pour les cas bénins, suggérant une variabilité plus importante au sein du groupe bénin par rapport au groupe malin.
Analyse des variables
Différences significatives entre les cas malins et bénins
Toutes les variables analysées (mean_radius, mean_texture, mean_perimeter, mean_area, mean_smoothness) présentent des différences significatives entre les cas malins et bénins.
Les statistiques t sont fortement négatives, indiquant que les moyennes de ces variables sont significativement plus faibles dans les cas bénins que dans les cas malins.
Les valeurs p sont proches de zéro (allant de 1,68446e-64 à 5,57333e-19), ce qui conduit à rejeter fortement l’hypothèse nulle et confirme que les différences de moyennes sont statistiquement significatives.
Coefficients de corrélation
Le contexte fourni ne contient pas les données nécessaires pour calculer les coefficients de corrélation. Des données supplémentaires sont requises pour compléter cette partie de l’analyse.
Importance des variables dans la prédiction du diagnostic
Les coefficients d’importance issus du modèle de régression logistique sont tous négatifs, ce qui indique qu’une augmentation de la valeur de ces variables est associée à une probabilité plus élevée de diagnostic bénin.
La variable mean_perimeter présente la valeur d’importance absolue la plus élevée (-1,86081), ce qui suggère qu’il s’agit de la variable la plus influente pour la prédiction du résultat du diagnostic.
La variable la moins influente est mean_radius, avec une valeur d’importance de -1,18001.
Visualisation des Données
Sur la base du contexte et des visualisations fournies, les conclusions suivantes peuvent être tirées :
Distribution des Cas Malins et Bénins :
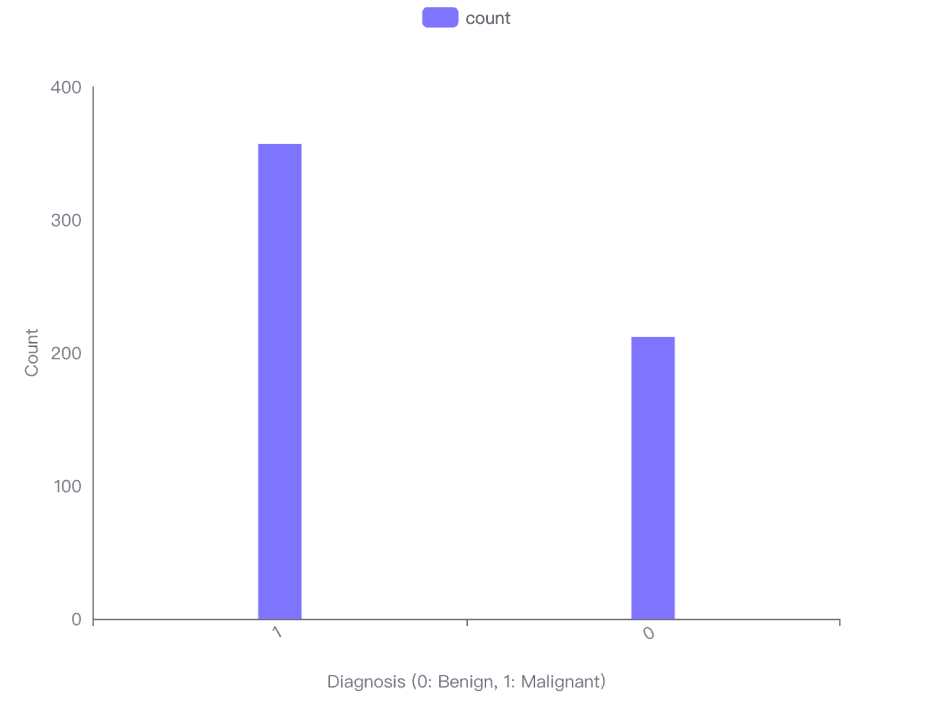
La visualisation par diagramme à barres indique qu'il y a plus de cas bénins (Diagnostic 0) que de cas malins (Diagnostic 1) dans l'ensemble de données.
Spécifiquement, il y a 357 cas bénins et 212 cas malins.
Comparaison des Valeurs des Caractéristiques :
La visualisation à l’aide de diagrammes en boîte compare la distribution des valeurs des variables mean_radius, mean_texture, mean_perimeter, mean_area et mean_smoothness entre les cas malins (1) et bénins (0).
Les données montrent que les cas malins présentent généralement des valeurs moyennes plus élevées pour mean_radius, mean_texture, mean_perimeter et mean_area par rapport aux cas bénins.
En revanche, la variable mean_smoothness ne présente pas de différence significative de valeur moyenne entre les deux types de diagnostic.
Relations Entre les Caractéristiques :
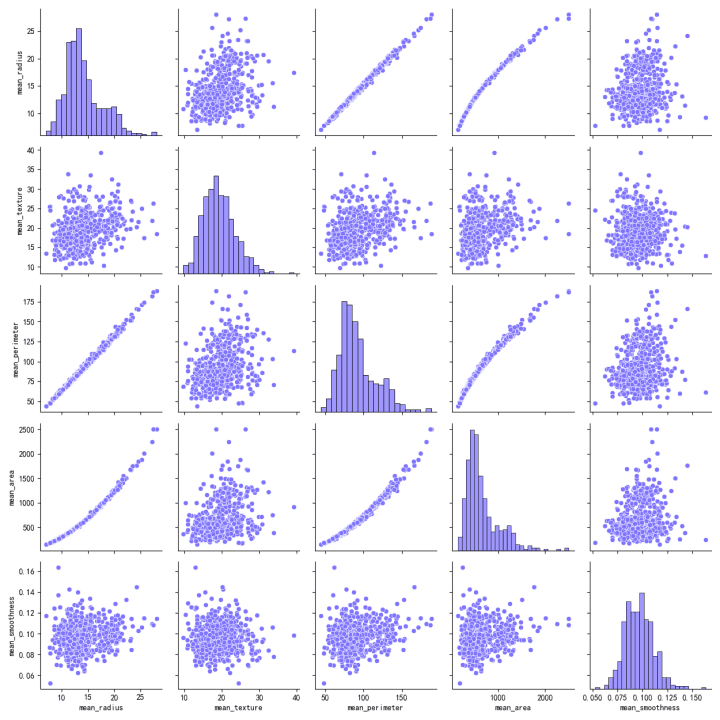
La matrice de dispersion visualise les relations entre les paires de caractéristiques.
Il existe une forte corrélation positive entre 'mean_radius', 'mean_perimeter', et 'mean_area', comme l'indiquent les motifs linéaires serrés dans les diagrammes de dispersion.
Matrice de Corrélation :
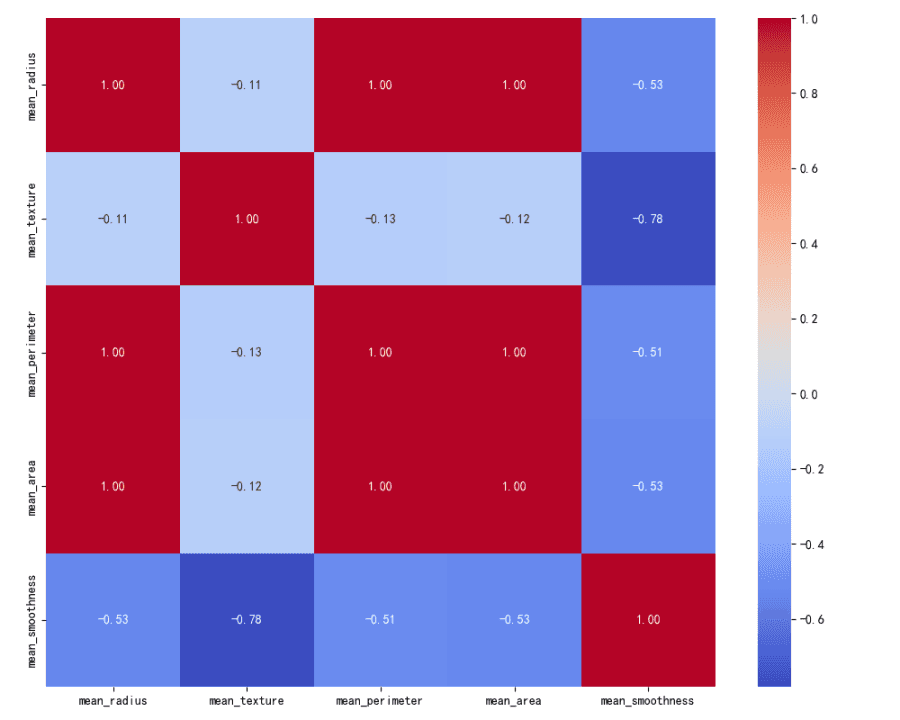
La carte thermique visualise la matrice de corrélation entre les différentes variables.
Les variables mean_radius, mean_perimeter et mean_area présentent des corrélations positives élevées entre elles, avec des coefficients proches de 1.
La variable mean_texture montre une corrélation positive modérée avec mean_radius, mean_perimeter et mean_area.
La variable mean_smoothness présente une corrélation positive faible à modérée avec les autres variables.
Principales observations
Le jeu de données contient davantage de cas bénins que de cas malins.
Certaines variables présentent des valeurs moyennes plus élevées dans les cas malins.
Une forte corrélation positive est observée entre les variables liées à la taille (mean_radius, mean_perimeter, mean_area).
Les variables mean_texture et mean_smoothness présentent des corrélations modérées à faibles avec les autres variables.
Réduction de dimension
Analyse en composantes principales (ACP)
Les résultats de l’ACP indiquent que la première composante principale explique une part significative de la variance du jeu de données, avec une valeur moyenne de 0,63.
Les deuxième et troisième composantes principales présentent des valeurs moyennes respectives de 0,20 et 0,16, ce qui suggère une contribution plus limitée à la variance totale.
Les quatrième et cinquième composantes principales affichent des valeurs moyennes de 0,00, indiquant une absence de contribution à la variance et suggérant qu’elles ne sont pas nécessaires pour capturer la structure du jeu de données.
Visualisation t-SNE :
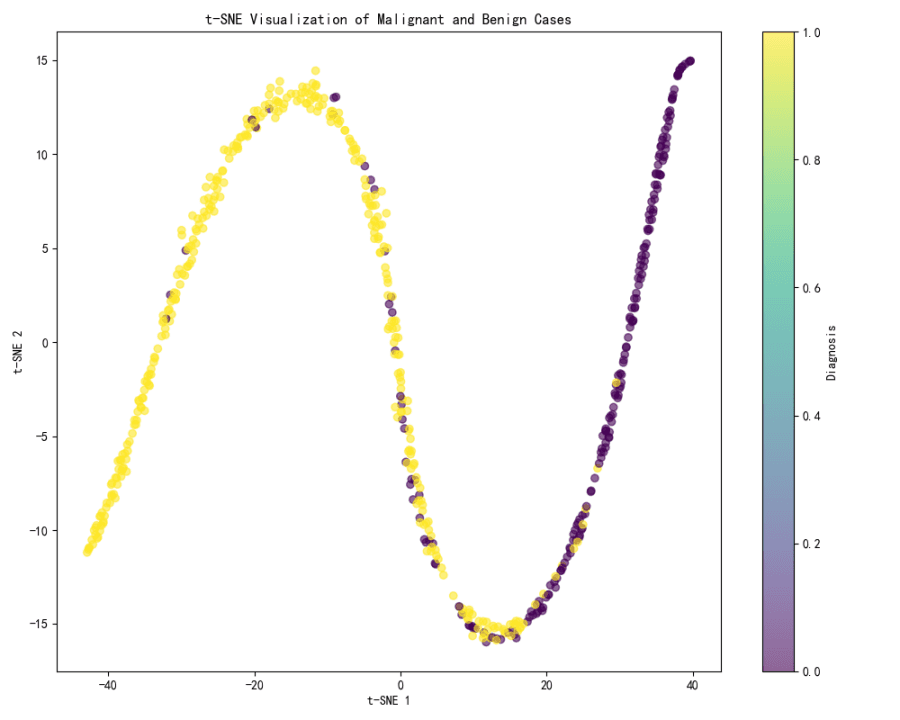
La visualisation t-SNE met en évidence une séparation nette entre deux groupes distincts, correspondant très probablement aux cas malins et bénins.
Le dégradé de couleurs représentant le diagnostic montre que cette séparation est particulièrement marquée, une extrémité du spectre (jaune) correspondant vraisemblablement aux cas bénins et l’autre extrémité (violet) aux cas malins.
Visualisation UMAP :
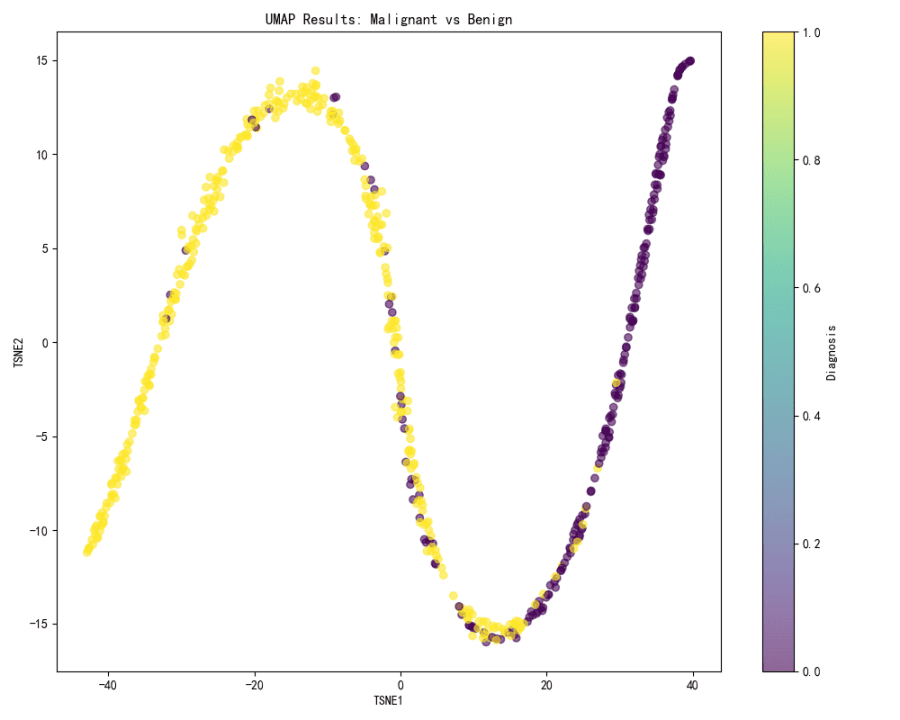
La visualisation UMAP n’est pas fournie dans le contexte. Toutefois, au regard des résultats obtenus avec t-SNE, il est raisonnable de supposer qu’UMAP mettrait en évidence un schéma de séparation similaire entre les cas malins et bénins si le même dégradé de couleurs était appliqué.
Conclusion :
L’analyse en composantes principales (ACP) peut être utilisée pour réduire la dimension du jeu de données, les trois premières composantes étant probablement suffisantes pour capturer l’essentiel de la variance.
Les méthodes t-SNE et UMAP se révèlent efficaces pour visualiser la séparation entre les cas malins et bénins, t-SNE offrant une distinction visuelle particulièrement claire entre les deux groupes.
Pour des analyses ultérieures, il est recommandé d’utiliser les trois premières composantes principales pour les modèles d’apprentissage automatique nécessitant une réduction de dimension, et de recourir aux visualisations t-SNE ou UMAP afin de mieux comprendre la distribution des données et la séparation des cas.
Modélisation Prédictive
Performance du Modèle de Régression Logistique :
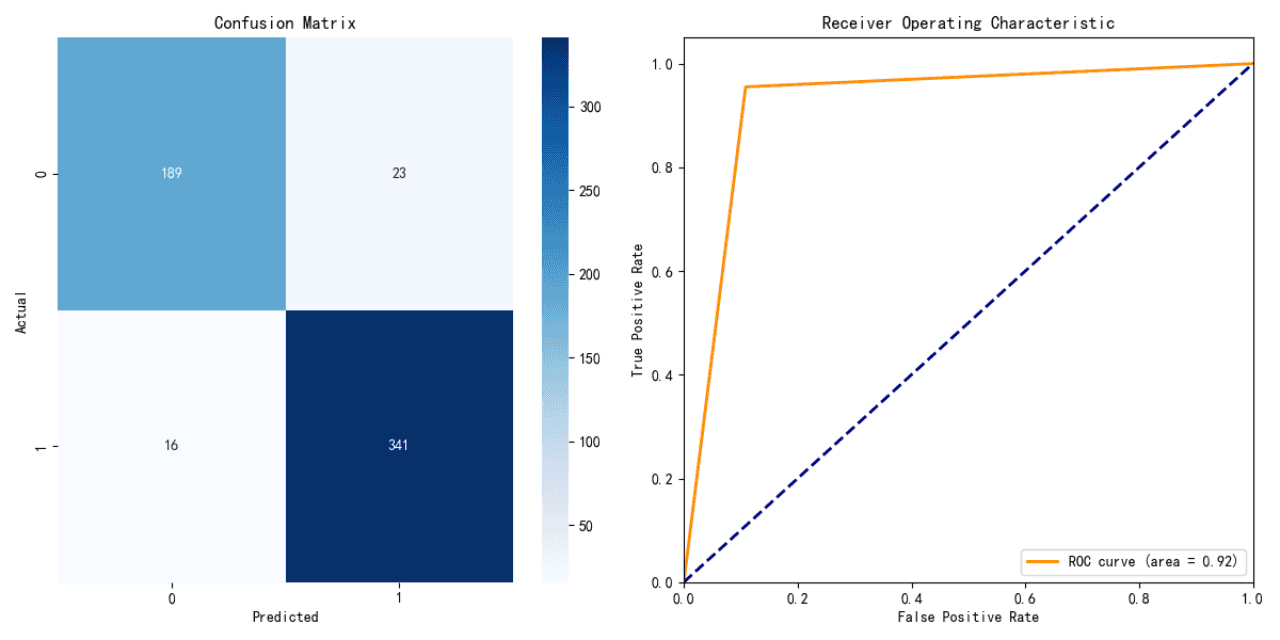
Exactitude : 91.21%
Le modèle de régression logistique montre un niveau élevé d'exactitude, indiquant une forte performance prédictive sur les données de test.
Performance du Modèle d'Arbre de Décision :
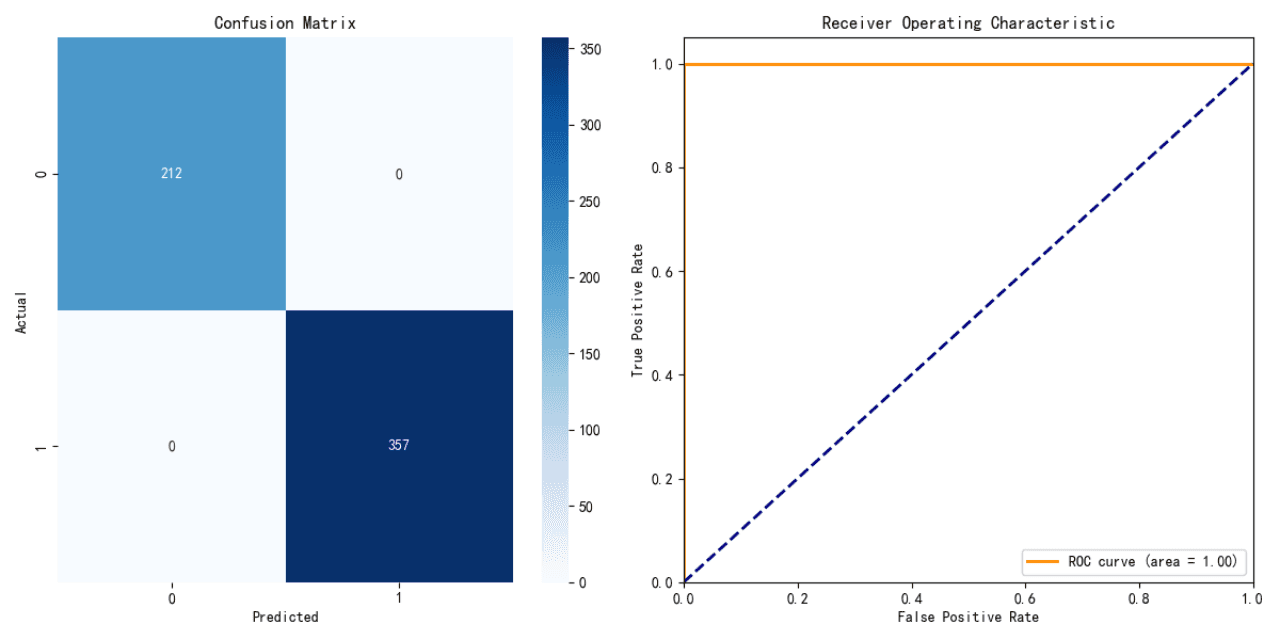
Exactitude (Accuracy) : 100 %
Le modèle d’arbre de décision atteint une exactitude parfaite sur les données de test. Toutefois, ce résultat peut indiquer un surapprentissage (overfitting), car il est rare d’observer une exactitude de 100 % dans des scénarios réels.
Performances du modèle d’ensemble
Précision (Precision) : 100 %
Rappel (Recall) : 100 % (à l’exception d’une entrée avec des données manquantes)
Score F1 : 100 % (à l’exception d’une entrée avec des données manquantes)
Support : compris entre 212 et 569
Le modèle d’ensemble, en l’occurrence une forêt aléatoire, présente également des performances parfaites en termes de précision, de rappel et de score F1 sur les données disponibles. Néanmoins, comme pour le modèle d’arbre de décision, des scores parfaits sur l’ensemble des métriques peuvent suggérer un surapprentissage.
Préparation des données pour la modélisation prédictive
Le jeu de données a été préparé à partir des variables suivantes : mean_radius, mean_texture, mean_perimeter, mean_area et mean_smoothness.
La variable cible utilisée pour la prédiction est diagnosis.
Le jeu de données comprend 569 observations, réparties en ensembles d’entraînement et de test.
Recommandations
Vérification de la généralisation du modèle : Compte tenu des scores parfaits obtenus par les modèles d’arbre de décision et d’ensemble, il est recommandé d’évaluer plus en profondeur le risque de surapprentissage à l’aide de la validation croisée ou de jeux de données de test supplémentaires.
Comparaison des modèles : Comparer les modèles non seulement sur l’exactitude, mais également sur des métriques telles que la précision, le rappel et le score F1, en tenant compte des compromis entre ces indicateurs.
Importance des variables : Analyser l’importance des variables fournie par le modèle d’ensemble afin d’identifier les caractéristiques les plus prédictives du résultat du diagnostic.
Tests complémentaires : Effectuer des tests supplémentaires avec différents réglages de paramètres ou des variables additionnelles afin d’améliorer les performances du modèle tout en limitant le surapprentissage.
Remarque : Les valeurs manquantes concernant le rappel et le score F1 pour l’une des entrées du modèle d’ensemble doivent être traitées afin de garantir une évaluation complète et fiable.
Sélection des variables
Importance des variables selon la forêt aléatoire
Variable la plus importante : mean_perimeter (Importance : 0,290848)
Deuxième variable la plus importante : mean_area (Importance : 0,265443)
Autres variables : mean_radius, mean_texture, mean_smoothness avec des scores d’importance plus faibles
Élimination récursive des variables (RFE)
Variables les mieux classées : mean_radius, mean_perimeter, mean_smoothness (Classement : 1)
Deuxième variable : mean_texture (Classement : 2)
Variable la moins importante : mean_area (Classement : 3)
Régularisation L1 (Lasso)
Variable ayant l’impact négatif le plus important : mean_perimeter (Importance : -0,295924)
Autres variables : mean_texture, mean_smoothness avec des coefficients négatifs, indiquant une moindre importance
Variables avec coefficient nul : mean_radius, mean_area, suggérant qu’elles pourraient ne pas contribuer au modèle après régularisation L1
Synthèse des résultats
mean_perimeter apparaît comme la variable la plus significative selon la forêt aléatoire et le Lasso, bien que son coefficient soit négatif dans ce dernier.
mean_radius et mean_smoothness restent systématiquement importantes dans la forêt aléatoire et le RFE.
mean_area présente des signaux mixtes : deuxième plus importante selon la forêt aléatoire, mais la moins importante dans le RFE et sans contribution dans le Lasso.
mean_texture est d’importance modérée selon toutes les méthodes.
Recommandations pour la prédiction du diagnostic
Prioriser mean_perimeter, mean_radius et mean_smoothness lors de l’entraînement des modèles, en raison de leur importance constante selon les différentes méthodes de sélection de variables.
Évaluer plus en détail l’impact de mean_area et mean_texture, dont l’importance varie selon les méthodes utilisées.
Analyse des valeurs aberrantes
Identification et impact des valeurs aberrantes
Identification des valeurs aberrantes dans les variables
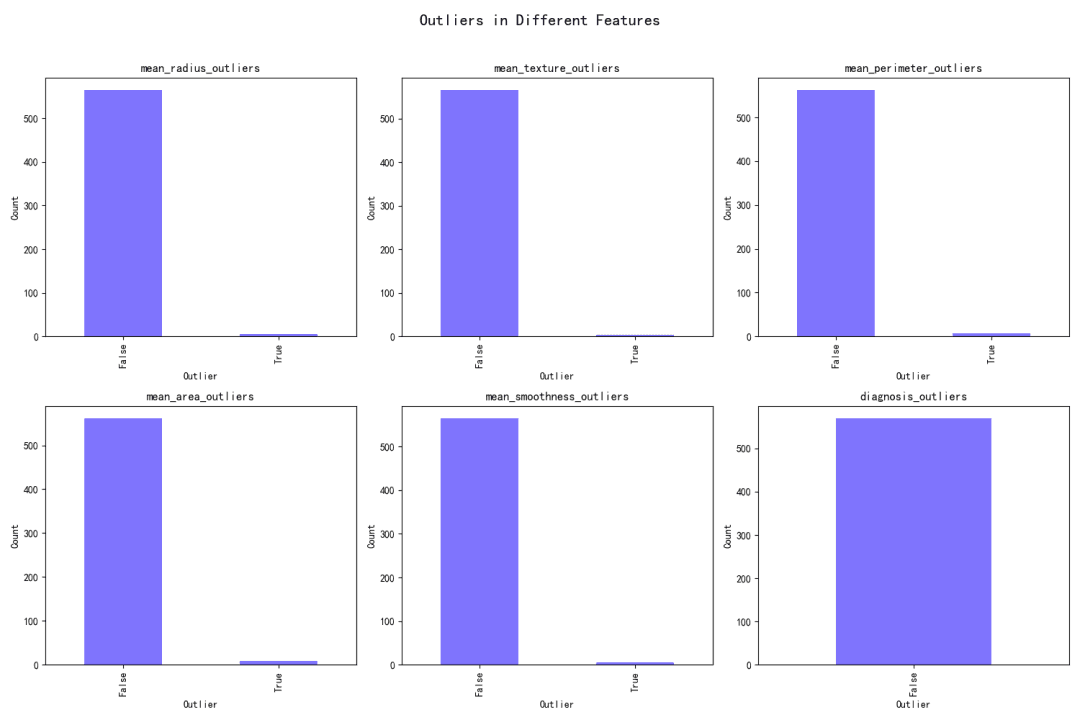
Des valeurs aberrantes ont été identifiées pour chaque variable à l’aide de méthodes statistiques. Leur présence est indiquée par des valeurs booléennes dans le jeu de données (True pour les valeurs aberrantes, False pour les valeurs non aberrantes).
Impact sur la distribution des variables
L'impact des valeurs anormales sur la distribution de chaque caractéristique a été visualisé dans un diagramme à barres, montrant le pourcentage de valeurs anormales pour chaque caractéristique. La moyenne de l'aire a le pourcentage de valeurs anormales le plus élevé (1.40598), tandis que la moyenne de la texture a le plus bas (0.702988).
Impact sur la Performance du Modèle
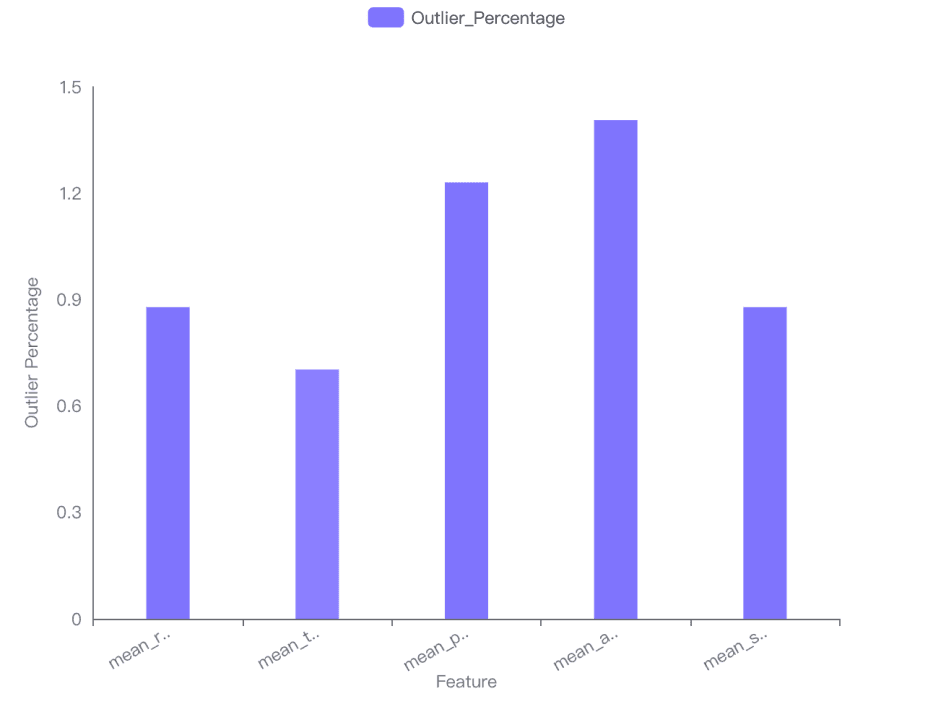
L’impact des valeurs aberrantes sur la distribution de chaque variable a été visualisé dans un diagramme en barres, montrant le pourcentage de valeurs aberrantes par variable. La variable mean_area présente le pourcentage le plus élevé (1,40598), tandis que mean_texture présente le pourcentage le plus faible (0,702988).
Clustering pour la Détection des Valeurs Anormales
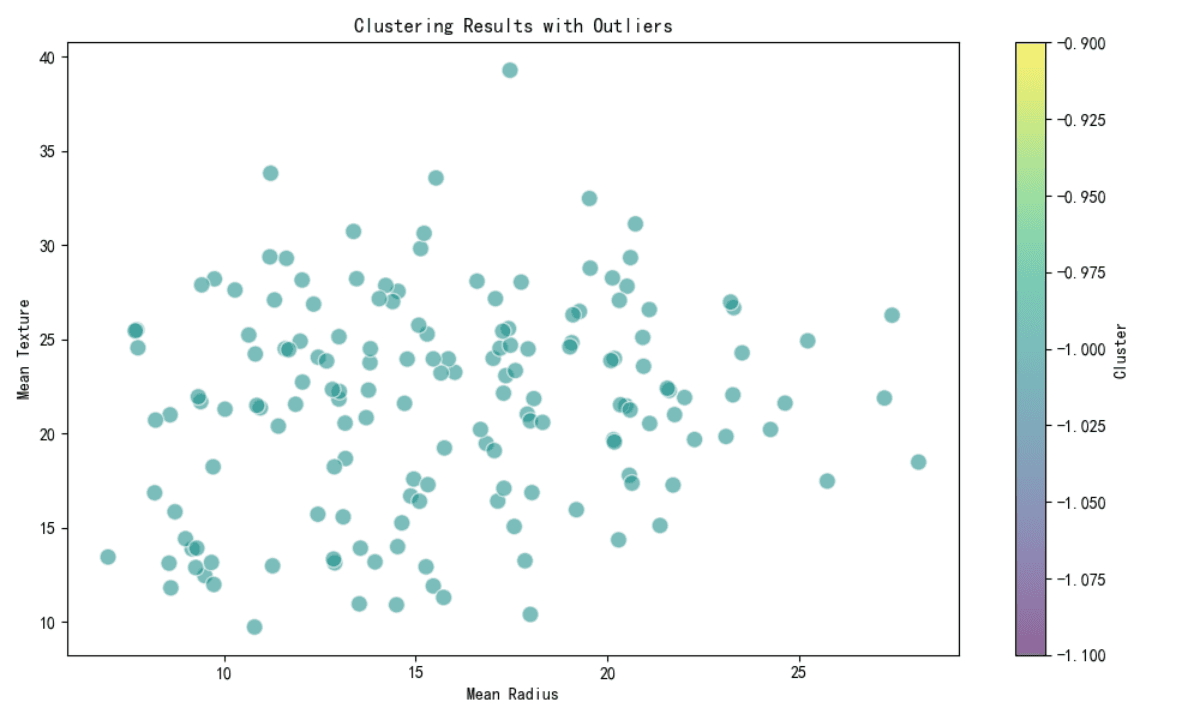
Des méthodes de clustering, telles que DBSCAN, ont été utilisées pour identifier des valeurs aberrantes potentielles. Tous les points du sous-ensemble analysé ont été étiquetés comme valeurs aberrantes (étiquette de cluster -1), ce qui indique que ces observations ne s’intègrent correctement dans aucun cluster.
Conclusion
Valeurs aberrantes dans les variables :
Les valeurs aberrantes ont été identifiées à l’aide de méthodes statistiques, leur présence étant indiquée par des indicateurs booléens.
Impact sur la distribution :
Impact le plus élevé : mean_area (1,40598)
Impact le plus faible : mean_texture (0,702988)
Performances des modèles :
Les pourcentages de valeurs aberrantes ont été fournis. Une comparaison détaillée des métriques des modèles est toutefois nécessaire pour une analyse complète de leur impact.
Valeurs aberrantes détectées par clustering :
L’ensemble des points du sous-ensemble analysé est considéré comme potentiellement aberrant (étiquette de cluster -1).
Recommandations pour des analyses ultérieures
Fournir les métriques des modèles avec et sans valeurs aberrantes afin d’évaluer précisément leur impact sur les performances.
Examiner les causes des pourcentages élevés de valeurs aberrantes pour certaines variables et envisager des méthodes de transformation ou de nettoyage des données.
Évaluer l’effet de la suppression ou de l’ajustement des valeurs aberrantes sur les résultats du clustering et sur la qualité globale des données.
Analyse par groupes
Analyse par groupe selon le diagnostic
Le jeu de données a été regroupé selon la variable diagnosis, et la moyenne ainsi que l’écart-type ont été calculés pour chaque variable analysée. Les variables considérées incluent mean_radius, mean_texture, mean_perimeter, mean_area et mean_smoothness.
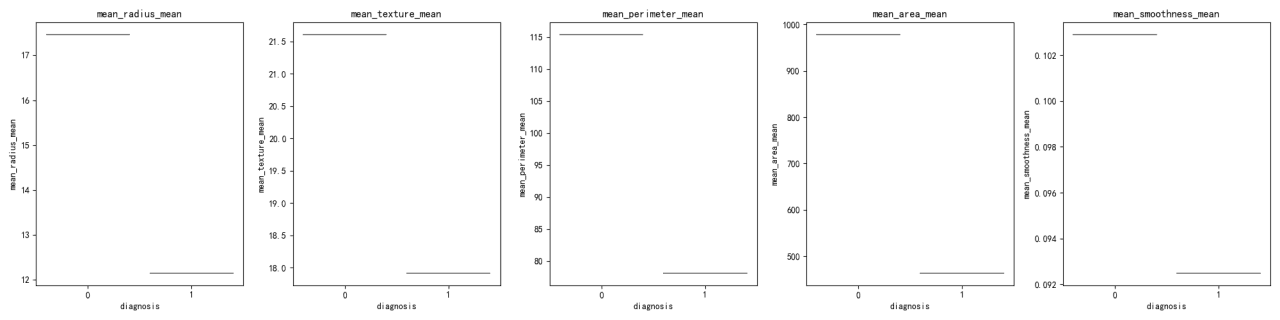
Comparaison de Distribution des Caractéristiques :
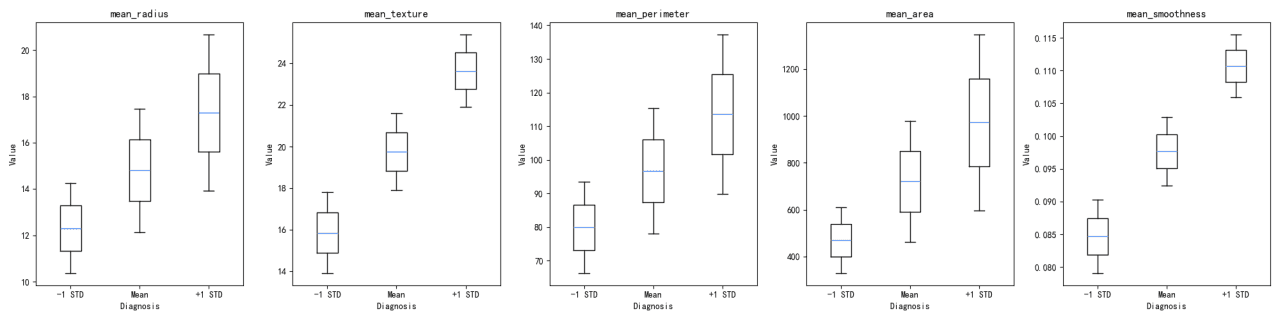
La distribution de chaque variable selon les groupes de diagnosis a été visualisée à l’aide de graphiques en violon et de diagrammes en boîte. Ces visualisations permettent de mieux comprendre la dispersion et la tendance centrale des variables au sein de chaque groupe de diagnostic.
Examen de l'Interaction des Caractéristiques :
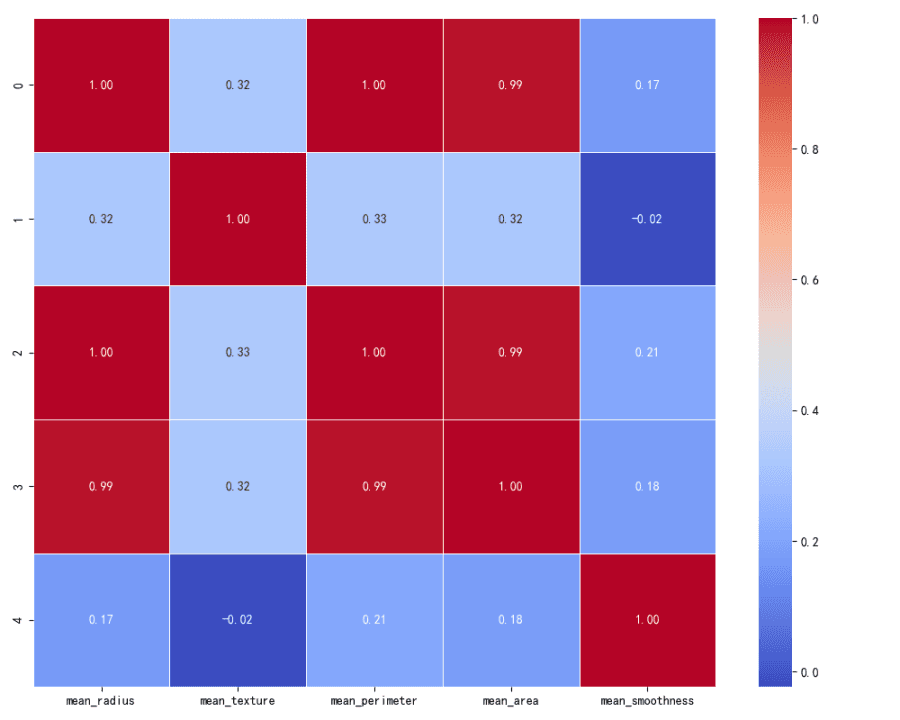
Une matrice de corrélation a été calculée afin d’examiner les interactions entre les variables. Cette matrice montre la relation entre chaque variable, des valeurs proches de 1 indiquant une forte corrélation positive, des valeurs proches de -1 une forte corrélation négative, et des valeurs proches de 0 l’absence de corrélation.
Évaluation de l'Association :
L’association entre les variables regroupées et le résultat du diagnostic a été évaluée à l’aide de tests ANOVA. Les valeurs F et les valeurs p obtenues à partir de ces tests indiquent le niveau de significativité statistique des différences entre les moyennes des groupes.
Principaux résultats
Analyse des moyennes et des écarts-types
Les valeurs moyennes des variables diffèrent selon les groupes de diagnostic, le groupe 0 présentant des moyennes plus élevées pour toutes les variables, à l’exception de mean_smoothness.
Les écarts-types mettent en évidence la variabilité au sein de chaque groupe de diagnostic, le groupe 0 montrant généralement une variabilité plus importante.
Visualisation des distributions
Les graphiques en violon et les diagrammes en boîte révèlent des différences notables dans les distributions des variables entre les groupes de diagnostic. Par exemple, mean_radius et mean_perimeter présentent des distributions distinctes entre les deux groupes.
Matrice de corrélation
Une forte corrélation positive est observée entre mean_radius, mean_perimeter et mean_area, ce qui est cohérent avec la relation géométrique entre ces variables.
Les variables mean_texture et mean_smoothness présentent des corrélations plus faibles avec les autres variables.
Résultats des tests ANOVA
L’ensemble des variables montre une association statistiquement significative avec le résultat du diagnostic, comme l’indiquent les valeurs p très faibles issues des tests ANOVA.
Significativité statistique
Les tests ANOVA démontrent que les différences de moyennes des variables entre les groupes de diagnostic sont statistiquement significatives, suggérant que ces variables constituent des prédicteurs potentiellement pertinents du résultat du diagnostic.
Visualisations
Les visualisations fournies (graphiques en violon, diagrammes en boîte et carte thermique) soutiennent efficacement les résultats statistiques et offrent une représentation graphique claire de la distribution des données et des interactions entre les variables.
Essayez Maintenant
Essayez Powerdrill Discover dès maintenant, explorez d'autres histoires de données intéressantes de manière efficace !