Meilleurs agents de données pour l'analyse et la recherche en novembre 2025

Introduction
La prolifération de l’IA générative a ouvert une nouvelle ère d’automatisation intelligente, avec les “agents de données” d’IA au premier plan de cette transformation. Ces agents, alimentés par des modèles de langage (LLM), peuvent analyser des données de manière autonome, générer des insights et même produire des rapports écrits ou des visualisations. Contrairement aux outils d’analyse traditionnels, ils fonctionnent souvent via des conversations en langage naturel ou un raisonnement en plusieurs étapes, permettant aux utilisateurs de poser des questions et de déléguer des tâches complexes en langage courant (anglais ou autre).
Ce rapport propose une vue d’ensemble des agents de données d’IA polyvalents disponibles sur le marché mondial, en mettant l’accent sur ceux dédiés à l’analyse des données et à la production de rapports de recherche. Nous présentons leurs principales fonctionnalités, avantages, limites, modèles de tarification ainsi que tout classement ou retour d’expérience notable. L’objectif est d’informer les décideurs sur le paysage des outils d’analyse et de reporting pilotés par l’IA dans un futur proche, des frameworks open source aux plateformes prêtes pour l’entreprise.
Powerdrill Bloom (Canvas d’exploration de données orienté IA)
Powerdrill Bloom est une plateforme d’exploration de données “AI-first”, sans code, qui transforme la façon dont les utilisateurs et les équipes interagissent avec les données. Au lieu de s’appuyer sur des requêtes SQL ou des tableaux de bord BI classiques, Bloom propose un canvas interactif piloté par l’IA où il suffit d’importer des feuilles de calcul ou des jeux de données structurés pour obtenir immédiatement des insights guidés, des graphiques générés automatiquement et des rapports prêts à présenter. Bloom simule un écosystème d’agents d’IA spécialisés (pour le nettoyage, l’analyse, la visualisation et le reporting), rendant l’analyse de données jusqu’à 100 fois plus rapide et nettement plus accessible pour les utilisateurs métiers, les analystes et les chercheurs.
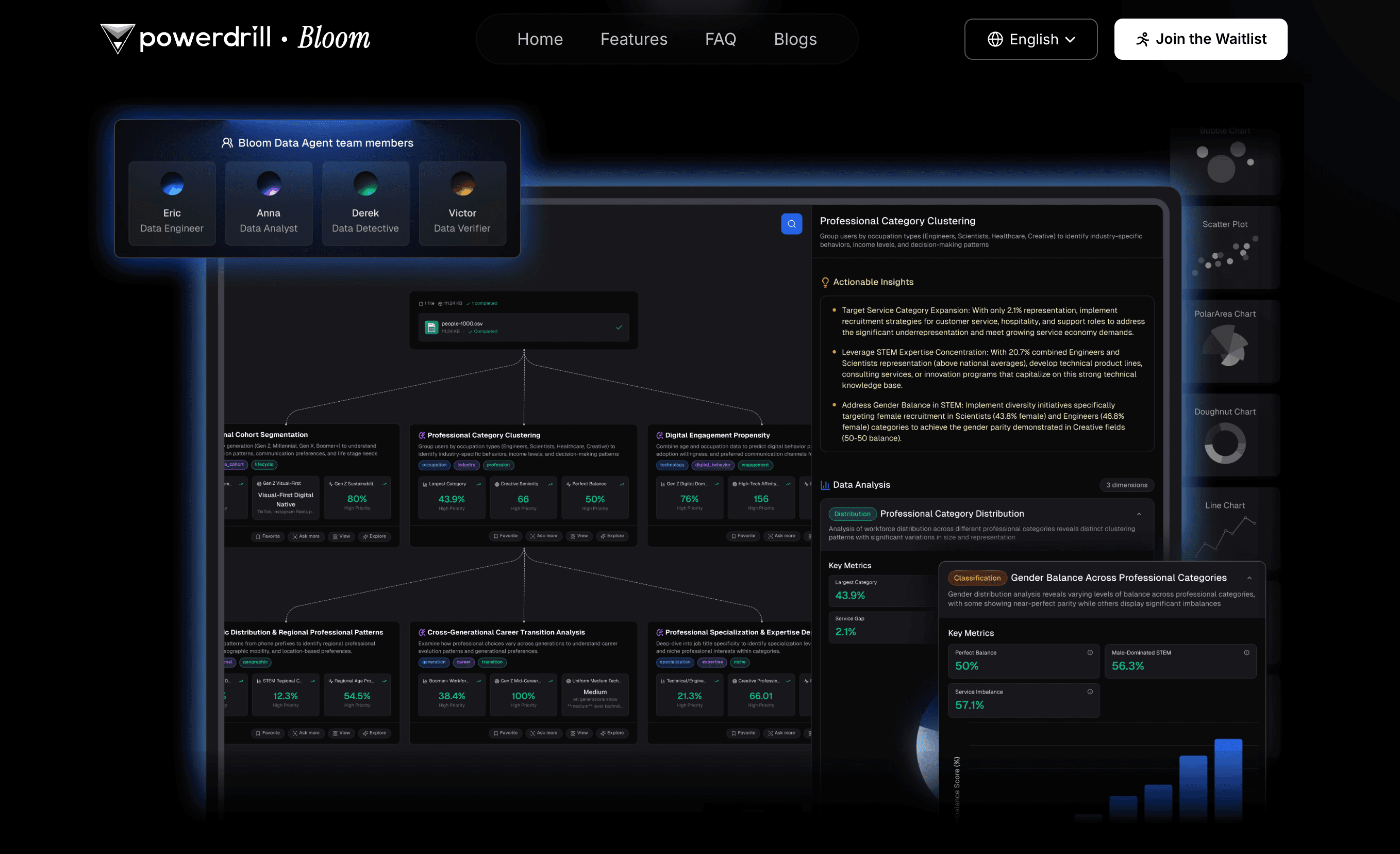
Points forts
Exploration des données sans code : les utilisateurs métier peuvent importer des fichiers Excel ou CSV et commencer à analyser avec des questions en langage naturel, sans connaissances en SQL, Python ou statistiques.
Collaboration multi-agents : l’architecture interne de Bloom repose sur des agents d’IA spécialisés (nettoyage, détection de tendances, visualisation, génération de rapports) pour fournir des insights complets, fiables et exploitables.
Workflow prêt pour la présentation : l’export en un clic vers PowerPoint transforme une analyse brute en présentations professionnelles, comblant le fossé entre insights et communication.
Parcours d’insights guidés : Bloom suggère des axes d’exploration (démographie, comportement, sentiment, etc.) afin d’aider les utilisateurs à révéler des tendances et motifs cachés, même sans point de départ clair.
Compatible entreprise : conçu pour la conformité, la gouvernance et l’observabilité, permettant un déploiement sécurisé à l’échelle de l’organisation.
Points faibles
Produit en phase initiale : Bloom est actuellement en bêta privée (sur invitation), l’accès est donc limité et les fonctionnalités évoluent encore.
Déploiement centré cloud : pratique, mais potentiellement contraignant pour les organisations nécessitant un contrôle strict des données en local.
Courbe d’apprentissage du canvas : certains utilisateurs peuvent avoir besoin de temps pour s’habituer à l’interface visuelle par cartes, différente des tableaux de bord traditionnels.
Tarification
Powerdrill Bloom propose une tarification simple, basée sur l’usage, avec un plan gratuit pour démarrer et un plan Pro pour une exploration IA avancée et une productivité accrue.
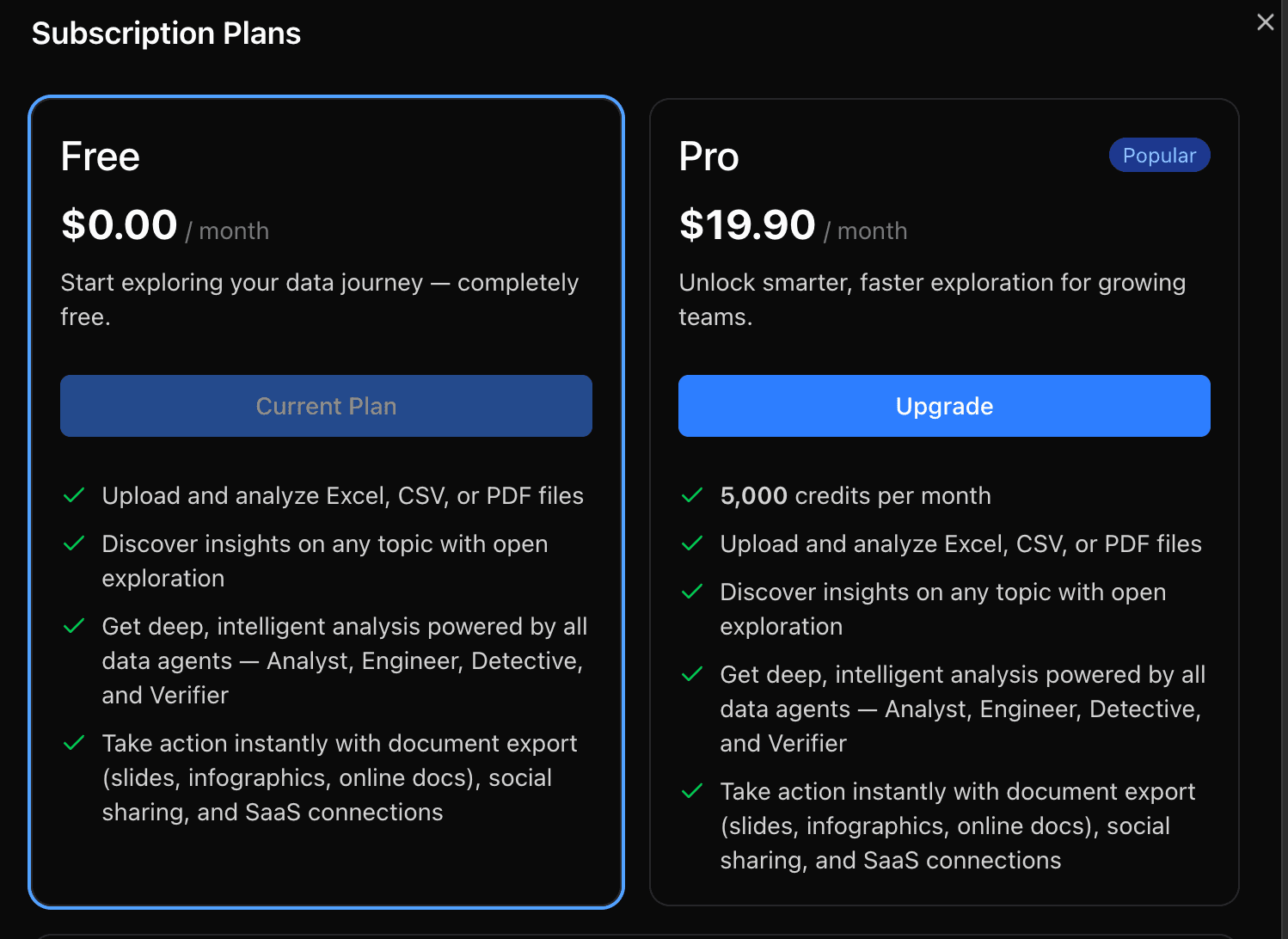
Classement du produit / Popularité
Dynamique d’adoption : depuis son lancement en 2025, Bloom attire l’attention des analystes métier, des product managers et des chercheurs comme une alternative “AI-first” aux outils de BI et d’analytique traditionnels.
Intérêt entreprise & académique : Bloom est testé au sein de grandes entreprises et universités, avec déjà plus de 1,1 million d’utilisateurs utilisant les produits Powerdrill AI en production.
Positionnement sur le marché : bien qu’encore en bêta, Bloom s’impose comme l’une des principales alternatives à Manus et aux outils de BI classiques, notamment pour les équipes recherchant des processus data-to-presentation plus rapides et pilotés par l’IA.
LAMBDA (Large Model Based Data Agent)
LAMBDA est un framework open source d’analyse de données, sans code, basé sur une architecture multi-agents et exploitant des LLM pour rendre l’analyse de données complexe accessible via le langage naturel. Développé par des chercheurs en IA, il simule une équipe d’agents spécialisés (par exemple “Data Finder”, “Insight Generator”, “Result Summarizer”) collaborant pour répondre aux questions posées sur des jeux de données importés. Dans la pratique, l’utilisateur peut importer des données structurées (CSV, Excel, etc.) et poser des questions en langage courant ; les agents de LAMBDA vont alors analyser les données, exécuter les traitements nécessaires et fournir des réponses accompagnées d’explications.
Points forts
Exploration des données sans code : permet aux non-programmeurs d’analyser des données simplement en posant des questions en langage naturel, ce qui réduit fortement la barrière d’entrée dans les contextes de recherche et d’enseignement.
Raisonnement multi-agents : l’architecture interne répartit les tâches entre plusieurs agents (recherche de données, génération d’insights, synthèse), améliorant la profondeur et l’interprétabilité des analyses.
Open source et personnalisable : publié sous licence de recherche, LAMBDA peut être auto-hébergé et étendu. Les utilisateurs peuvent l’intégrer avec des LLM puissants comme GPT-4 pour un meilleur raisonnement, ou utiliser des modèles ouverts si la confidentialité est cruciale.
Support de données flexible : optimisé pour les données tabulaires et compatible avec divers formats (CSV, feuilles de calcul) courants en entreprise et en recherche scientifique.
Points faibles
Maturité : en tant que projet issu de la recherche (sorti en 2024), LAMBDA n’est pas aussi abouti ou convivial que des solutions commerciales et peut nécessiter une configuration technique et une maîtrise de Python.
Dépendance au LLM : la qualité et la vitesse d’analyse reposent sur le modèle de langage sous-jacent ; utiliser des modèles premium (ex. GPT-4) peut être coûteux ou exiger un accès API, tandis que des modèles plus faibles réduisent la précision.
Interface limitée : l’absence d’une interface graphique avancée (souvent ligne de commande ou UI basique) peut rebuter certains utilisateurs métier.
Tarification
Coût : LAMBDA est gratuit et open source, sans licence. Les éventuels coûts proviennent des appels API externes (ex. OpenAI) ou des ressources de calcul à fournir.
Exigences de calcul : l’exécution avec de grands modèles peut nécessiter un GPU performant ou une instance cloud, ce qui représente un coût implicite de déploiement.
Classement / Popularité
Intérêt académique et communautaire : présenté dans un article académique mi-2024, LAMBDA suscite l’intérêt des chercheurs et passionnés de data science. Bien que non commercial, son approche agentique unique est souvent citée dans les discussions sur l’analyse de données pilotée par l’IA. Il ne se mesure pas via des parts de marché traditionnelles, mais son dépôt open source et sa publication sont largement référencés.
LangChain
LangChain est un framework open source très populaire permettant de créer des applications et agents d’IA personnalisés capables d’analyser, transformer et raisonner sur des données. Plutôt qu’un produit destiné aux utilisateurs finaux, LangChain fournit une boîte à outils orientée développeurs permettant de “chaîner” des LLM avec divers outils (bases de données, API, fonctions Python, etc.) au sein de workflows complexes.
Par exemple, un développeur peut créer un agent avec LangChain qui récupère des données de ventes depuis une base, détecte des anomalies, appelle une API externe pour enrichissement, puis résume les résultats en langage naturel. LangChain est devenu la norme de facto pour ceux qui prototypent des comportements avancés d’agents IA.
Points forts
Intégration hautement flexible : LangChain s’intègre avec un large écosystème d’outils et de modèles. Les développeurs peuvent connecter des bases SQL, des dataframes Pandas, la recherche web ou d’autres modèles ML, ce qui permet aux agents de traiter des sources et actions très variées.
Gestion de la mémoire et du contexte : prise en charge intégrée du contexte conversationnel et de la mémoire long terme (ex. bases vectorielles), afin de maintenir des échanges prolongés ou des analyses itératives sans perdre les informations précédentes.
Communauté active : l’un des frameworks IA les plus populaires, avec des dizaines de milliers d’étoiles GitHub et une large communauté de contributeurs. Résultat : mises à jour rapides, documentation riche et nombreux templates communautaires (environ 78k stars fin 2024).
Cas d’usage en production : de nombreuses start-ups et grandes entreprises utilisent LangChain pour construire assistants analytiques et chatbots IA. Sa flexibilité est validée dans des cas réels, de la recherche financière au support client.
Points faibles
Nécessite des compétences en code : LangChain est un framework, pas une solution prête à l’emploi. Les utilisateurs non techniques auront du mal à l’utiliser directement. Il convient mieux aux développeurs ou data engineers capables d’écrire du Python.
Complexité et surcharge : peut introduire de la complexité ou un overhead pour des tâches simples. Ses couches d’abstraction peuvent compliquer le débogage et un “chain” mal conçu peut devenir inefficace ou erroné. Très adapté au prototypage, mais parfois moins optimal pour du code de production ultra optimisé.
Dépendance à la qualité du LLM : comme tout outil piloté par LLM, la qualité dépend du modèle et des prompts utilisés. LangChain ne corrige pas les limites fondamentales des modèles (p. ex. exactitude factuelle), et nécessite d’ajouter récupération ou vérification si besoin.
Tarification
Coût : le framework LangChain est gratuit et open source (licence MIT). Aucun coût direct. Les dépenses proviennent surtout de l’infrastructure et des appels API utilisés par les agents (API OpenAI, serveurs cloud, etc.).
Offre entreprise optionnelle : l’équipe propose LangSmith pour le suivi d’expériences et le debugging, avec une tarification éventuelle, tandis que la bibliothèque principale reste gratuite.
Classement / Popularité
Adoption dans l’industrie : probablement le framework d’agents IA le plus populaire depuis 2023, souvent en tête des listes d’outils de développement IA. Son nombre élevé d’étoiles (près de 80k) et son classement parmi les projets open source majeurs de 2024 témoignent de sa forte adoption.
Avis d’experts : les développeurs louent sa polyvalence, tout en notant qu’il est surtout idéal pour le prototypage plutôt que pour des workflows de production ultra rationalisés. Globalement, il est considéré comme un kit fondamental pour construire des data agents personnalisés.
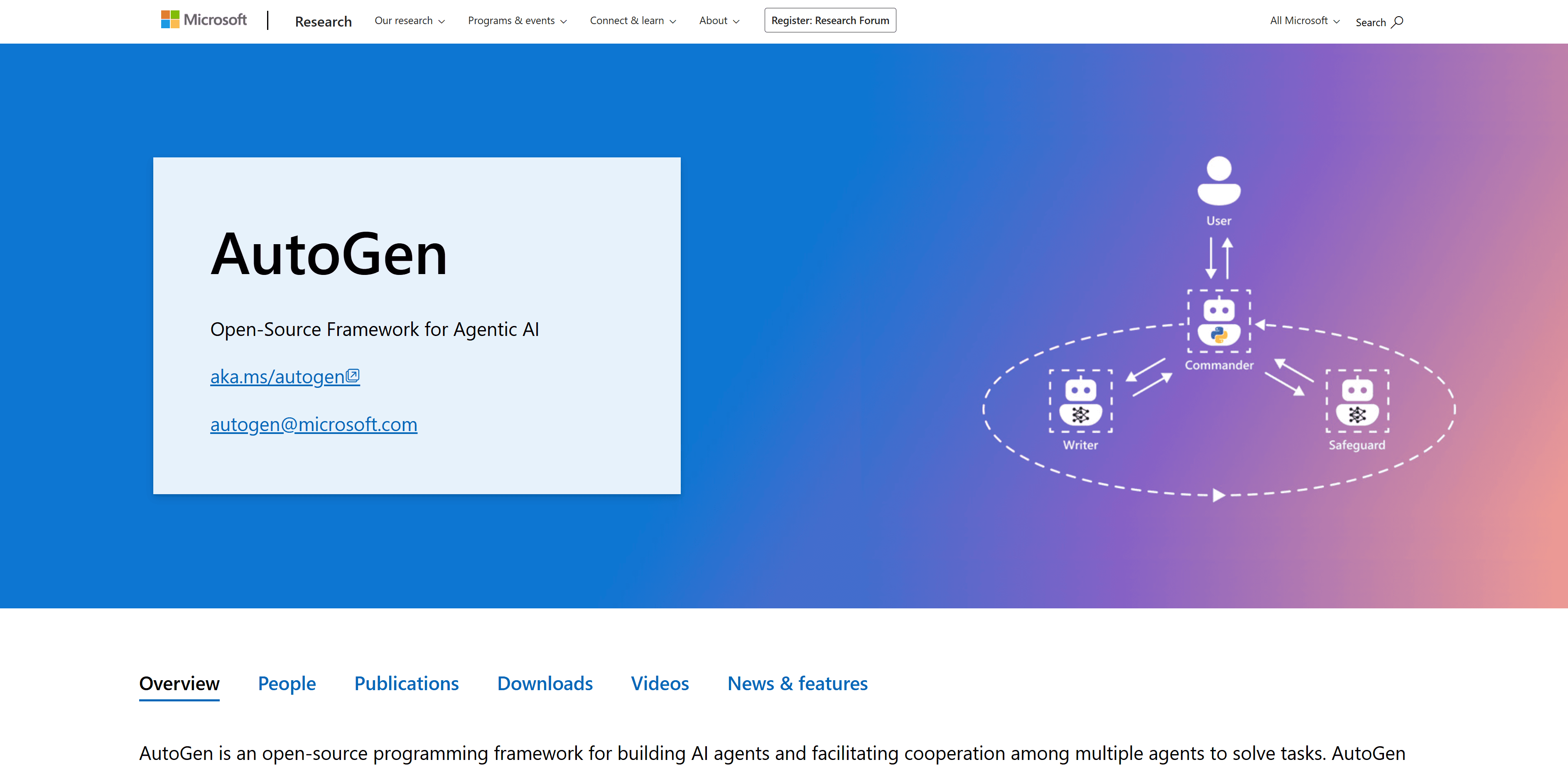
Microsoft AutoGen
Microsoft AutoGen est un framework open source développé par Microsoft pour créer des systèmes d’IA multi-agents capables de collaborer sur des tâches complexes. AutoGen permet de définir plusieurs agents spécialisés (par ex. Data Analyst Agent, Coding Agent, Quality Checker Agent, etc.) qui peuvent dialoguer entre eux afin de résoudre différentes parties d’un même problème.
Cette approche est particulièrement puissante pour les workflows d’analyse de données : un agent peut nettoyer les données, un autre produire des analyses ou des visualisations, tandis qu’un troisième rédige le rapport — le tout de manière autonome et coordonnée. Il s’agit essentiellement d’un framework « d’orchestration d’agents » basé sur des LLM, issu de Microsoft Research.
Points forts
Collaboration multi-agents : AutoGen prend en charge nativement les conversations entre agents. Cette approche modulaire permet d’optimiser chaque agent pour une sous-tâche (ex. génération de code Python, interprétation des résultats), fournissant des résultats plus précis et mieux structurés.
Écosystème Microsoft & intégration Azure : issu de Microsoft, il s’intègre naturellement avec les services Azure (dont Azure OpenAI pour GPT-4, etc.). Microsoft a annoncé un Azure AI Agent Service qui fonctionne avec AutoGen pour faire évoluer les agents en contexte entreprise—un atout majeur pour les organisations déjà sur Azure.
Open source et extensible : disponible sur GitHub, avec des scénarios d’exemples et une architecture conçue pour être étendue : vous pouvez ajouter des outils personnalisés ou connecter vos propres sources de données et APIs.
Puissant pour les workflows complexes : souvent considéré comme l’un des frameworks les plus performants pour des pipelines analytiques à étapes multiples (nettoyage, vérification croisée, analyse, rapport). La structure en rôles réduit les erreurs dans les raisonnements multi-étapes.
Points faibles
Orienté développeurs : comme LangChain, AutoGen nécessite du code. Pas d’interface prête à l’emploi : il faut écrire des scripts Python pour définir les agents et leurs comportements. Usage réservé aux équipes techniques.
Communauté encore jeune : apparu fin 2023, AutoGen dispose d’une communauté plus petite que LangChain, avec moins de tutos et d’échanges, ce qui peut compliquer le support (la documentation Microsoft aide néanmoins).
Surcharge liée au multi-agents : faire tourner plusieurs agents LLM qui dialoguent peut devenir coûteux et lent. Si chaque étape appelle une API, les coûts et la latence augmentent. Pour des tâches simples, cela peut être excessif.
Tarification
Coût : le framework est gratuit. Les coûts principaux proviennent des appels LLM (Azure OpenAI ou OpenAI API) et de l’infrastructure éventuelle pour l’orchestration.
Services Azure : l’usage du Azure AI Agent Service ou d’autres composants Azure peut entraîner des frais liés à Azure. Les tarifs Azure OpenAI s’appliquent (ex. GPT-4) selon la consommation.
Classement / Popularité
Outil émergent : AutoGen est reconnu parmi les nouveaux frameworks d’agents IA les plus prometteurs et figure dans plusieurs listes des meilleurs outils d’agents pour 2025. Moins célèbre que LangChain, mais bénéficiant de la crédibilité Microsoft. L’intégration continue dans Azure montre son importance stratégique.
Performances : très apprécié dans les milieux experts pour ses “équipes d’agents modulaires”. Pour les organisations ayant des pipelines analytiques complexes, c’est une option robuste permettant de reproduire une équipe data (analyste, ingénieur, relecteur) en agents IA travaillant ensemble.
BabyAGI
BabyAGI est un agent IA open source léger, issu de la communauté des développeurs comme une expérimentation autour de l’exécution autonome de tâches. Malgré son nom ambitieux (AGI = Artificial General Intelligence), BabyAGI est essentiellement un script Python qui utilise un LLM pour créer, prioriser et exécuter des tâches en boucle.
Il s’est fait connaître en 2023 comme l’un des premiers exemples d’“agent IA” capable d’affiner ses actions de manière itérative. Pour l’analyse de données ou la recherche, BabyAGI peut être configuré pour, par exemple, partir d’un objectif de recherche, le découper en tâches (collecte des données, analyse, synthèse des résultats), exécuter chaque étape avec l’aide d’un LLM et s’ajuster en fonction des résultats obtenus.
Points forts
Simplicité et créativité : le code de BabyAGI est minimal et facile à adapter. Cette simplicité permet de prototyper rapidement des agents autonomes sans framework lourd, et favorise l’expérimentation sur l’enchaînement de tâches et les boucles de rétroaction.
Boucle d’apprentissage itérative : BabyAGI suit une boucle planification → exécution → apprentissage. Après chaque tâche, il évalue le résultat et peut générer de nouvelles tâches ou ajuster l’objectif. Pour certains travaux de recherche ou d’analyse dont le chemin n’est pas défini à l’avance, cette approche peut révéler des pistes qu’un script statique manquerait.
Communauté et variantes : BabyAGI a déclenché une vague de projets similaires ; de nombreuses variantes communautaires ajoutent mémoire, navigation web, etc. Souvent cité aux côtés d’AutoGPT comme exemple clé d’agent autonome.
Léger : ne nécessite pas d’installation complexe : un environnement Python et une clé API LLM suffisent. Idéal pour le prototypage rapide d’un workflow piloté par IA.
Points faibles
Pas une “AGI” réelle : comme indiqué dans sa documentation, BabyAGI n’est pas une véritable AGI. Il peut tourner en boucle ou produire des tâches triviales sans ingénierie de prompts adéquate. Son raisonnement dépend du modèle et de la logique simple de priorisation.
Usage limité par défaut : par défaut, peu d’intégrations : essentiellement le LLM et une base vectorielle pour la mémoire. Pour l’analyse de données, il faut l’étendre pour charger les données ou appeler des fonctions d’analyse. Sans interface, peu adapté aux non-développeurs.
Stabilité et exactitude : risque de dérive ou de résultats incorrects sans supervision. En contexte critique, une vérification humaine est nécessaire : c’est plus un assistant expérimental qu’un outil d’entreprise fiable.
Tarification
Coût : totalement gratuit et open source. Le coût principal vient de l’usage d’une API LLM (souvent GPT-4), avec des frais par token. Les boucles continues peuvent consommer beaucoup de tokens (et donc de budget).
Calcul : aucun matériel spécifique requis, sauf si vous utilisez des modèles locaux ; fonctionnera partout où Python fonctionne.
Classement / Popularité
Statut viral : devenu viral sur GitHub début 2023, avec des milliers d’étoiles et de nombreuses démonstrations. Fréquemment listé parmi les “agents IA incontournables”.
Usage en recherche / projets : essentiellement utilisé dans des projets expérimentaux ou hackathons. Peu de déploiements à grande échelle en production, mais il a inspiré des successeurs plus avancés. Il reste une preuve de concept importante démontrant la faisabilité des agents à boucle de tâches.
AutoGPT (et les agents inspirés par AutoGPT de Meta)
AutoGPT est un autre exemple précoce d’agent autonome devenu célèbre en 2023. Contrairement à BabyAGI (qui fonctionne comme un processus unique), AutoGPT a été pensé comme un « agent IA capable de s’auto-prompt » : une fois un objectif défini, il génère ses propres sous-objectifs et peut enchaîner l’utilisation d’outils externes pour les atteindre. De nombreuses itérations et variantes sont apparues, notamment des forks communautaires ainsi que des expérimentations menées par les grandes entreprises technologiques. Le terme Meta AutoGPT fait référence aux améliorations et travaux de recherche que Meta (Facebook) a apportés à ce concept. Même si Meta n’a pas publié un « produit AutoGPT » destiné aux utilisateurs finaux, l’entreprise a ouvert le code de modèles de langage (comme LLaMA) et a démontré des capacités d’agents autonomes construits à partir de ces modèles.
Les versions influencées par Meta sont utilisées pour l’analyse de données en plusieurs étapes, la recherche web et l’automatisation de tâches. Cela en fait une base intéressante pour concevoir des pipelines d’analyse ou des assistants de recherche plus complexes, capables de planifier, d’exécuter et d’ajuster leurs actions en fonction des informations découvertes.
Points forts
Automatisation complète des workflows – Les agents de type AutoGPT cherchent à réaliser des tâches de bout en bout avec un minimum d’intervention humaine. Par exemple : « Analyser des tendances climatiques et produire un rapport ». L’agent décompose l’objectif (trouver des sources, analyser, rédiger) et exécute les étapes automatiquement. C’est puissant pour les analyses répétitives ou la génération régulière de rapports.
Utilisation d’outils et exécution de code – Ces agents peuvent choisir et utiliser des outils : appels d’API, exécution de Python, requêtes de bases de données. Ils ne se limitent donc pas à “parler”, mais peuvent agir (récupérer des données, lancer des calculs) pour atteindre un objectif.
Apports de Meta – La recherche de Meta a amélioré l’autonomie sur le raisonnement et la planification. En exploitant les modèles ouverts de Meta (famille LLaMA), les agents peuvent être adaptés à des tâches spécifiques (exploration documentaire interne, nettoyage de données, synthèses). Ils peuvent surtout fonctionner en local ou en cloud privé, ce qui rassure les organisations soucieuses de confidentialité.
Cas d’usage en data & recherche – AutoGPT a été utilisé pour l’automatisation BI et des bots de recherche. Certains développeurs s’en servent pour surveiller des sites concurrents, collecter et synthétiser l’information quotidiennement : un véritable analyste de recherche autonome.
Points faibles
Imprévisibilité – Les agents autonomes peuvent se tromper, tourner en boucle ou produire des résultats hors sujet. Ils demandent une configuration précise (prompts, garde-fous) pour devenir réellement fiables. Dans la pratique, une supervision humaine reste souvent nécessaire.
Consommation de ressources – AutoGPT peut être lourd : multiples processus, navigation web, exécution de code… Cela peut coûter cher en temps et en calcul. Les premières versions étaient souvent lentes et peu rentables au regard du résultat.
Complexité technique – Mettre en place un AutoGPT (avec des outils personnalisés ou sur données privées) n’est pas trivial. Ce n’est pas un produit SaaS clé en main, mais plutôt un projet à configurer correctement (environnement, permissions, intégrations).
Tarification
Coût – Le code AutoGPT est gratuit (open-source). Le coût principal vient des appels à un LLM. AutoGPT s’est fait connaître pour des consommations massives de tokens si on le laissait tourner sans limites.
Accès aux modèles Meta – Les modèles Meta (LLaMA2, etc.) sont gratuits pour la recherche et certains usages commerciaux : on peut donc déployer une version “Meta-AutoGPT” sans coût par requête (mais avec un coût d’hébergement GPU/cloud). Intéressant pour un usage intensif, à condition de gérer l’infrastructure.
Classement / Popularité
Engouement communautaire – AutoGPT a été l’un des projets GitHub les plus populaires de 2023 (plus de 100 000 étoiles en quelques mois). Il a symbolisé l’intérêt massif pour les agents autonomes. On le retrouve dans pratiquement toutes les listes “AI agents à connaître”.
Statut actuel – En entreprise, AutoGPT sert davantage de fondation conceptuelle que de solution prête à l’emploi. Son héritage est majeur (il a inspiré d’autres outils), mais son usage direct reste surtout du côté des passionnés et des projets expérimentaux. Les travaux récents (y compris chez Meta) montrent des versions plus robustes, notamment via un meilleur planing et une autonomie mieux contrôlée.
AgentBuilder.ai
AgentBuilder.ai est une plateforme no-code permettant de créer des agents IA personnalisés capables d’analyser des documents, répondre à des questions et effectuer des analyses de données légères. Elle s’adresse principalement aux utilisateurs métier qui souhaitent déployer des assistants sur leurs données internes (PDF d’entreprise, bases de connaissance, fichiers Excel, etc.) sans écrire de code.
Les utilisateurs peuvent importer leurs documents, définir le comportement et le ton de l’agent en langage naturel, puis le déployer via des interfaces conversationnelles – sur un site web ou dans un portail interne. En résumé, AgentBuilder.ai démocratise la création d’agents IA pour des cas d’usage professionnels quotidiens, sans dépendre de développeurs ou d’infrastructure spécifique.
Points forts
Simplicité sans code : Configuration entièrement par glisser-déposer et pilotée par des invites. Cela permet aux analystes ou aux chefs de produit (pas seulement aux développeurs) de démarrer rapidement un agent IA. Par exemple, on pourrait créer un "Assistant de Rapport de Recherche" qui connaît tous les rapports trimestriels en ne chargeant que ces PDF et en demandant à l'agent de répondre à des questions sur ceux-ci.
Focus sur l'analyse de documents : Il excelle dans la question-réponse sur des documents. La plateforme peut ingérer des PDF, des fichiers Word, des CSV, et plus encore, puis l'agent peut combiner les connaissances de ces sources lorsqu'il répond. Ceci est précieux pour la gestion des connaissances internes ou la synthèse de documents de recherche.
Comportement personnalisable : Grâce à des instructions en langage naturel, les utilisateurs peuvent ajuster la façon dont l'agent répond - son style, son niveau de détail, etc. Cela signifie que les mêmes données sous-jacentes peuvent alimenter un chatbot orienté client avec un ton amical ou un analyste interne avec des détails techniques, juste en modifiant la configuration de l'agent.
Intégration et déploiement : AgentBuilder.ai permet d'intégrer les agents créés dans divers canaux : vous pouvez le placer sur un site Web, dans une discussion Slack ou Microsoft Teams, ou une application interne. Il est construit pour s'intégrer sans trop de tracas, ce qui est excellent pour les organisations souhaitant des victoires rapides (comme un agent d'assistance IA ou un assistant de données interne).
Points faibles
Portée de l'analyse : AgentBuilder est axé sur l'analyse de documents et une simple analyse des données. Il peut ne pas gérer des analyses multi-étapes très complexes (comme la fusion d'ensembles de données ou l'exécution d'analyses statistiques compliquées) aussi bien que des cadres basés sur du code. C'est plus pour des questions-réponses interactives et des synthèses que pour des pipelines analytiques complets.
Dépendance aux services cloud : En tant que plateforme (probablement exécutée sur une infrastructure cloud, peut-être même sur Google Cloud compte tenu de l'URL), certaines organisations pourraient avoir des préoccupations concernant la résidence des données ou la sécurité. Télécharger des documents sensibles sur un service tiers pour analyse pourrait être un obstacle dans les industries strictes à moins que le fournisseur ne propose des options sur site ou cloud privé.
Plateforme nouvelle : Étant un outil relativement nouveau dans un espace en évolution rapide, sa longévité et le soutien de la communauté restent incertains. Il n'a pas la grande base d'utilisateurs de projets open-source, et la maturité des fonctionnalités peut être en retard par rapport à des outils d'analyse plus établis.
Tarification
Structure tarifaire : Les prix exacts ne sont pas publiquement détaillés. En général, de telles plateformes peuvent facturer par mois en fonction du nombre d'agents ou du volume de données. Par exemple, il pourrait y avoir des niveaux pour les petites équipes contre l'entreprise. (L'association de la plateforme avec Google Cloud laisse entendre qu'elle pourrait faire même partie des offres de Google ou utiliser l'infrastructure de Google, possiblement avec un abonnement similaire à d'autres services d'IA Google Cloud.)
Disponibilité d'essai : AgentBuilder.ai propose probablement un niveau gratuit ou un essai pour les agents initiaux pour inciter à l'utilisation. Les utilisateurs paient ensuite pour des limites de données plus élevées ou des fonctionnalités plus avancées. Nous recommandons de consulter leur page de tarification directement pour des détails spécifiques, car elle n'était pas indiquée dans nos sources.
Classement / Popularité
Public cible : Ceci est destiné aux startups, PME et départements au sein de grandes entreprises qui ont besoin d'un déploiement AI "à faible friction". Il a été souligné dans des articles sur les tendances en IA comme une solution clé sans code. Bien que ce ne soit pas aussi célèbre que des outils de grandes marques, il creuse une niche.
Reconnaissance : Le guide de Solutions Review sur les meilleurs agents AI pour l'analyse de données a mis en avant AgentBuilder.ai comme une entrée notable, indiquant que les experts voient de la valeur dans son approche. Étant sans code et axé sur des cas d'utilisation pratiques (questions-réponses sur des documents, bots de support client), il a un large attrait. En 2025, il peut être considéré parmi les meilleurs constructeurs d'agents IA conviviaux sur le marché.
DataGPT
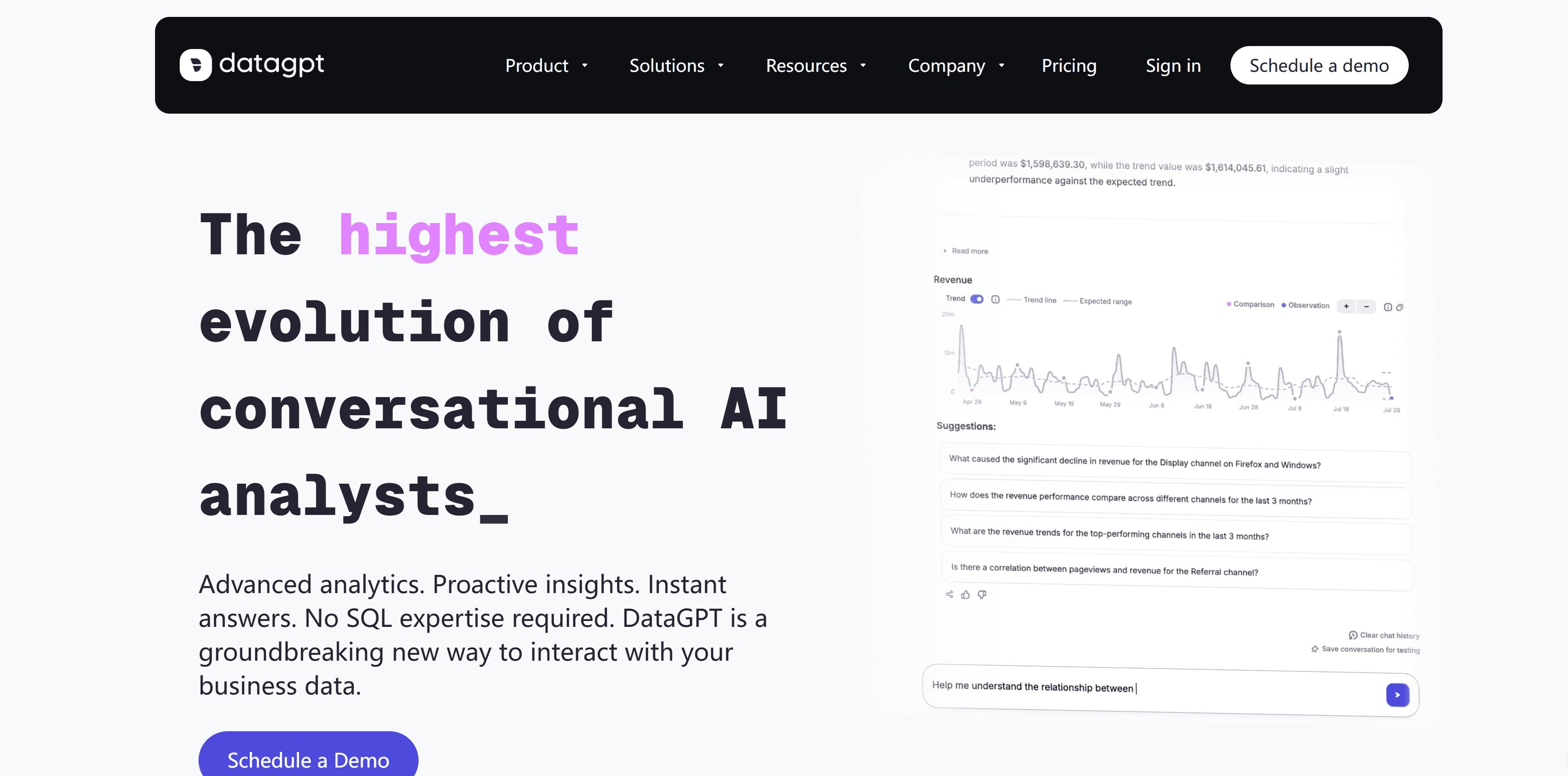
DataGPT est une plateforme commerciale de type « analyste de données conversationnel » qui fournit des analyses avancées et des informations proactives via une interface de chat. La solution se positionne comme « bien plus qu’un simple outil de text-to-SQL », en mettant en avant sa capacité à véritablement comprendre les données métier et à produire une analyse pertinente, et non de simples requêtes. DataGPT se connecte aux données de l’entreprise (bases de données, outils BI, etc.) et permet de poser des questions directement ou de laisser l’IA détecter elle-même des informations intéressantes. Par exemple, on peut demander : « Pourquoi le chiffre d’affaires a-t-il baissé cette semaine ? » et DataGPT va établir un plan d’analyse, effectuer des comparaisons, détecter des anomalies et produire une explication – ce que les outils BI traditionnels ne réalisent généralement pas de façon autonome. En pratique, il fonctionne comme un analyste virtuel capable d’explorer les données, de fournir des commentaires et de générer des visualisations.
Points forts
Raisonnement analytique avancé : Les agents de DataGPT ne se contentent pas de traduire des questions en SQL : ils réalisent un raisonnement multi-étapes (comparaisons, analyses détaillées, etc.). La solution peut gérer des questions de type « pourquoi » (diagnostic) ainsi que des scénarios « what-if » en analysant dynamiquement les facteurs sous-jacents. Cela va nettement plus loin que de nombreux outils d’IA appliqués à la BI qui se limitent à des agrégations basiques.
Insights orientés métier : La plateforme est pensée pour les décideurs. Elle met automatiquement en avant les principaux leviers, anomalies, tendances et corrélations, en tenant compte par exemple de la saisonnalité. Cette génération proactive d’insights permet de gagner un temps considérable en soulignant directement ce qui mérite l’attention (ex : « la conversion est exceptionnellement faible pour cette période »).
Évaluations positives d’experts : Selon des analystes de S&P Global, le moteur analytique propriétaire de DataGPT peut répondre à des questions complexes « plus rapidement et avec davantage de précision que les simples outils text-to-SQL ». Cela suggère une optimisation avancée (caching, requêtes vectorisées, etc.) adaptée aux environnements entreprise.
Intégration et interface : DataGPT s’intègre probablement aux entrepôts de données et outils BI les plus courants. Son interface de chat est intuitive et peut générer des visualisations (graphiques, tableaux) ainsi que des commentaires écrits. Résultat : l’utilisateur obtient une réponse exploitable, illustrée et prête à partager.
Points faibles
Orienté entreprise (coût & complexité) : DataGPT vise clairement les grandes entreprises (démonstrations, intégrations personnalisées). Cela implique généralement un coût élevé et un déploiement plus complexe. Les petites organisations pourraient trouver la solution disproportionnée si elles ne disposent pas d’équipes data importantes.
Mise en place non « self-service » : Contrairement à une solution SaaS simple où il suffit de déposer un CSV, DataGPT nécessite une connexion à vos bases de données et implique souvent une intervention IT. Ce processus peut ralentir l’adoption dans les structures moins techniques.
Plateforme propriétaire : En tant que solution fermée, elle dépend du fournisseur pour les mises à jour et évolutions. La transparence est moindre et les fonctionnalités non disponibles devront être demandées ou attendre la roadmap du produit.
Tarification
Abonnement entreprise : Aucune grille publique : l’accès se fait via démonstration, ce qui laisse supposer un modèle tarifaire personnalisé selon le nombre d’utilisateurs, les volumes de données et les fonctionnalités. On peut estimer des coûts équivalents aux grandes plateformes BI, souvent plusieurs milliers de dollars par mois pour une entreprise de taille moyenne.
Cloud ou on-premise : On ignore si une version on-premise existe. Si la solution est uniquement cloud, le coût pourrait inclure stockage et volumes de requêtes. Une version privée implique généralement des frais supplémentaires.
ROI potentiel : La promesse repose sur l’automatisation des analyses et la réduction des tâches répétitives. Le retour sur investissement dépendra de la capacité à réellement remplacer ou accélérer les analyses manuelles internes.
Classement / Popularité
Acteur émergent : DataGPT est encore récent mais s’est démarqué en allant plus loin que les simples fonctionnalités d’IA présentes dans certains outils BI. Plusieurs publications le présentent comme une approche « révolutionnaire » dans l’interaction avec les données métier.
Adoption : Aucun chiffre public sur le nombre d’utilisateurs, mais l’appui d’analystes comme S&P Global renforce sa crédibilité. L’intérêt devrait croître en 2025 auprès des entreprises data-driven.
Concurrence : DataGPT se positionne face aux éditeurs historiques qui renforcent leurs modules IA (Tableau, Power BI Copilot) ainsi qu’aux nouveaux venus spécialisés dans l’analytique conversationnelle. Sa capacité à produire des insights réellement pertinents sera déterminante pour s’imposer comme une solution de référence.
DeepSeek Agent
Vue d’ensemble : DeepSeek Agent est un framework open-source d’agents autonomes issu de l’un des projets chinois les plus avancés en matière de modèles de langage (initiative DeepSeek). Il est conçu pour des tâches longues et fortement axées sur les données, telles que la veille de marché, l’analyse financière quantitative ou encore l’intelligence concurrentielle. DeepSeek Agent combine de grands modèles de langage avec l’utilisation d’outils et une mémoire persistante, à l’image de solutions occidentales comme AutoGPT, tout en étant optimisé par l’équipe DeepSeek pour la scalabilité et les entrées multimodales. Il a gagné en visibilité entre 2024 et 2025 comme alternative locale en Asie pour créer des agents de recherche autonomes capables de conduire des analyses complexes de manière auto-dirigée.

Points forts
Autonomie et exécution longue : DeepSeek est conçu pour gérer des tâches complexes sur de longues périodes, sans intervention humaine. Par exemple, un agent DeepSeek peut surveiller en continu l’actualité financière, mettre à jour une base de connaissances, effectuer une analyse de sentiment et signaler des variations importantes – un enchaînement qui exige un traitement itératif permanent.
Multimodalité et richesse des outils : La plateforme prend en charge plusieurs types d’entrées (texte, code, PDF, graphiques) et peut effectuer du web browsing, analyser des fichiers, exécuter du code ou appeler des API. Un seul agent peut ainsi lire un rapport PDF, en extraire des chiffres, lancer des calculs en Python puis produire un résumé, couvrant l’ensemble d’un flux de recherche.
Modèles de raisonnement avancés : L’agent s’appuie sur les modèles maison de DeepSeek, tels que DeepSeek-VL (vision-langage) ou DeepSeek-Coder (programmation). Ces modèles spécialisés peuvent offrir des performances élevées dans leurs domaines (par exemple l’analyse financière ou le codage) par rapport à des modèles plus généralistes.
Adoption dans la finance : Des gestionnaires de fonds quantitatifs et des développeurs en Chine utilisent déjà DeepSeek Agent pour des agents de recherche ou de trading autonomes. Cette utilisation dans des contextes sensibles témoigne de sa flexibilité et de sa capacité à traiter de grands volumes de données et des logiques complexes.
Points Faibles
Langue et communauté : Une partie importante du développement et des échanges communautaires autour de DeepSeek est en chinois. Les utilisateurs non sinophones peuvent rencontrer une barrière linguistique au niveau de la documentation ou du support. L’adoption mondiale pourrait en pâtir tant que les ressources en anglais ne se développent pas.
Exigences matérielles : Le fonctionnement d’agents autonomes multimodaux s’appuyant sur de grands modèles et de longs contextes demande souvent des ressources de calcul considérables (GPU, mémoire). Cela peut freiner les petites équipes n’ayant pas accès à une infrastructure adaptée.
Mise en place complexe : En tant que framework, DeepSeek Agent requiert des compétences techniques : installation des modèles, intégration d’outils, ingénierie de prompts. Ce n’est pas une solution “clé en main”, mais plutôt un moteur puissant à configurer.
Tarification
Coût : DeepSeek Agent est open-source et donc gratuit à utiliser. Les modèles DeepSeek peuvent également être ouverts, mais leur exécution peut nécessiter du matériel spécifique ou, dans le cas d’une version hébergée, entraîner des coûts d’accès API.
Infrastructures : Il faut prévoir un investissement dans le calcul. Pour de l’analyse financière, par exemple, un serveur doté d’un GPU performant peut représenter plusieurs centaines de dollars par mois en cloud.
Support : Il n’est pas clair qu’un service d’accompagnement payant soit proposé. À ce stade, l’écosystème semble surtout porté par la communauté.
Classement / Popularité
Impact régional : DeepSeek est considéré comme l’un des projets d’agents LLM les plus avancés en Chine. Dans la conversation mondiale sur les agents autonomes, il se distingue comme une alternative crédible hors de la sphère occidentale, régulièrement mentionnée aux côtés d’AutoGPT et de BabyAGI dans les analyses internationales.
Innovation audacieuse : Certains commentaires d’experts soulignent que DeepSeek montre que l’innovation en IA n’est pas réservée aux géants technologiques : « DeepSeek prouve que l’innovation appartient aux acteurs audacieux, pas seulement aux plus grands ». Pour un public spécialisé (analystes quantitatifs, chercheurs IA), le projet est très respecté, même s’il ne s’agit pas d’un produit commercial grand public.
Convergence AI – Proxy 1.0
Proxy 1.0 de Convergence AI est un agent autonome expérimental conçu pour agir comme un « proxy » du comportement humain sur le web. En d’autres termes, Proxy peut naviguer sur des sites, cliquer sur des liens, remplir des formulaires et collecter des données sur Internet comme le ferait un utilisateur – mais piloté par l’IA. Il a été créé pour permettre l’automatisation complète de tâches impliquant des interactions web, telles que la veille concurrentielle, le web scraping ou la recherche d’informations en temps réel. Contrairement aux chatbots classiques qui se limitent à répondre avec du texte issu d’une base de connaissances statique, Proxy 1.0 agit sur le web en direct : il peut parcourir des pages et effectuer des actions, ce qui en fait un assistant web polyvalent.
Points forts
Interaction web de type humain : Proxy ne se contente pas de récupérer des données via des API ; il simule réellement un utilisateur dans un navigateur. Il peut gérer du contenu dynamique, naviguer à travers des pages de connexion ou des formulaires, et collecter des informations qui ne sont pas accessibles par de simples requêtes. Cela ouvre un large éventail de cas d’usage (par ex. surveiller les prix des concurrents en visitant réellement leurs sites et en en extrayant les données).
Agent de navigation polyvalent : Il n’est pas limité à un domaine précis. On peut lui donner une instruction en langage naturel du type : « Collecte les derniers tarifs produits de ces 5 sites concurrents et résume les différences », et Proxy tentera d’exécuter toute la séquence de manière autonome. C’est en quelque sorte un robot web doté d’un cerveau LLM, capable de s’adapter à diverses tâches en temps réel.
Collecte de données en temps réel : Parce qu’il travaille sur des sites vivants, il peut obtenir des informations à jour. C’est crucial pour la veille de marché ou les activités de recherche où les données changent fréquemment (sites d’actualités, réseaux sociaux, informations boursières, etc.). Les outils BI traditionnels basés sur des données statiques risquent d’être en retard dans ces situations.
Modèle “open-weights” : Convergence a publié une version « Proxy Lite » en open-weights (un modèle réduit de 3B) sur HuggingFace, démontrant une certaine ouverture. Cela permet aux développeurs d’expérimenter une version de Proxy localement et favorise l’amélioration par la communauté.
Points faibles
Caractère expérimental : Proxy 1.0 est explicitement présenté comme expérimental. Une couverture précoce par TechRadar a souligné qu’il « se targuait de pouvoir effectuer plusieurs tâches en ligne », mais comme pour tout agent de première génération, les résultats peuvent être variables. Il peut cliquer au mauvais endroit ou se retrouver bloqué face à des mises en page inattendues. La robustesse reste un défi face à la diversité du web.
Questions éthiques et de conformité : Un agent qui explore et interagit avec des sites pourrait involontairement enfreindre des conditions d’utilisation ou extraire des données qui ne devraient pas l’être. Les entreprises doivent l’utiliser de manière responsable (ne pas saturer les sites, respecter le robots.txt, etc.). Il existe aussi un risque d’accéder involontairement à des contenus protégés par connexion ou de déclencher des mesures anti-bot.
Consommation de ressources : Simuler un navigateur contrôlé par une IA est coûteux. Cela peut impliquer l’exécution d’un navigateur headless et d’un LLM simultanément. C’est probablement plus lent et gourmand qu’un simple appel API. Pour une extraction de données à grande échelle, un scraper spécialisé restera plus efficace. Proxy se démarque davantage lorsque la flexibilité prime sur l’efficacité brute.
Tarification
Coût : Le Proxy complet de Convergence AI est vraisemblablement disponible via leur plateforme ou leurs modèles. « Proxy Lite » est gratuit (il suffit de disposer de la puissance de calcul nécessaire). Le modèle complet ou le service pourraient être proposés via une API ou un abonnement, mais les détails restent limités. Convergence AI semblant être une structure de petite taille, il est possible que ce soit présenté comme une expérimentation gratuite destinée à démontrer leurs capacités.
Besoins en calcul : Faire tourner Proxy avec une IA de type GPT-4 engendre ces coûts API, en plus du fonctionnement du navigateur automatisé. En utilisant leur modèle open-weights, le coût dépendra de l’infrastructure serveur mise en place.
Classement / Popularité
Attention médiatique : Proxy 1.0 a fait les gros titres de blogs technologiques en tant qu’« agent IA qui prend le contrôle de votre souris et de votre clavier » d’une certaine façon. Il a été comparé à l’agent « Operator » (non public) d’OpenAI, certains estimant que Proxy le surpassait lors des démonstrations. Ce type de couverture montre qu’il est perçu comme à la pointe des capacités des agents IA.
Base d’utilisateurs : Probablement encore limitée — essentiellement des passionnés et développeurs IA. Ce n’est pas encore un outil professionnel mainstream. Néanmoins, son concept influence clairement la direction prise par les agents IA. On peut imaginer de futurs produits commerciaux intégrant des capacités similaires d’interaction web. Le travail de Convergence AI offre un aperçu de cet avenir, ce qui lui a valu une place dans les listes des meilleurs agents IA pour 2025.
Microsoft Power BI (avec Microsoft 365 Copilot dans Excel et Power BI)
Microsoft Power BI est l’une des plateformes de Business Intelligence les plus utilisées au monde, reconnue depuis des années pour la richesse de ses visualisations et de ses capacités de reporting. Ces dernières années, Microsoft a intégré l’IA dans l’ensemble de Power BI — depuis les requêtes en langage naturel (Power BI Q&A permet de poser des questions en anglais courant) jusqu’aux visualisations IA (analyse des facteurs clés, détection d’anomalies), dans une logique d’« analytics augmentée ». En 2023, Microsoft a lancé Microsoft 365 Copilot, un assistant IA pour toute la suite Office, incluant Copilot dans Excel et dans Power BI, afin d’améliorer fortement l’analyse de données et l’automatisation des rapports. Copilot dans Excel peut analyser un jeu de données, détecter des tendances ou des valeurs atypiques, créer des formules, générer automatiquement des graphiques ou même proposer une première analyse rédigée en langage naturel. Quant à Copilot dans Power BI (désormais intégré à la nouvelle plateforme Microsoft Fabric), il peut générer des rapports entiers ou des éléments de tableau de bord à partir de simples instructions. Cela revient, pour les utilisateurs de Power BI, à disposer d’un assistant-analyste de données polyvalent directement dans leurs outils habituels.
Points Forts
Intégration transparente avec Microsoft 365 : Copilot peut transférer des analyses d’Excel vers PowerPoint, générer des diapositives, résumés, mises en forme, etc., comme le ferait un analyste humain. Grâce à Microsoft Graph, il exploite le contexte et les données internes de l’entreprise, ce qui rend l’analyse plus pertinente pour les utilisateurs professionnels.
Langage naturel et interface conversationnelle : On peut simplement demander : « Explique la baisse des ventes au T4 par région ». Copilot interroge les données, produit une analyse narrative et ajoute des visuels si nécessaire. Cela abaisse fortement la barrière d’entrée : même les non-analystes peuvent obtenir des insights avancés via une simple conversation.
Plateforme BI leader du marché : Power BI bénéficie déjà d’une adoption massive, avec sécurité, gouvernance et connecteurs de données robustes. Copilot vient s’intégrer sur une base mature et fiable. L’écosystème Microsoft facilite l’adoption avec peu de friction pour les organisations déjà équipées.
Confiance et sécurité enterprise-grade : Copilot pour Microsoft 365 s’appuie sur les garanties de sécurité Microsoft (données dans le tenant, conformité, confidentialité). Pour de nombreuses entreprises, cela inspire davantage confiance que des outils émergents fournis par des startups.
Points Faibles
Coût élevé : Microsoft 365 Copilot est un add-on facturé 30 $/utilisateur/mois en plus des licences existantes. À grande échelle, cela représente un budget conséquent. L’adoption nécessitera une justification claire en termes de ROI productivité.
Exactitude perfectible : Copilot peut mal interpréter les données ou générer des formules incorrectes. L’utilisateur doit relire et valider, surtout pour des rapports sensibles. Pour les utilisateurs non experts, cela peut représenter un risque d’erreurs.
Préparation des données toujours nécessaire : Si les données source sont désorganisées, Copilot ne résoudra pas magiquement la qualité ou la modélisation. L’assistant facilite l’analyse, mais ne remplace pas un data engineer ni une gouvernance des données solide.
Tarification
Microsoft 365 Copilot : 30 $ par utilisateur et par mois (engagement annuel). Pour les grandes entreprises, cela représente un coût additionnel potentiellement élevé si l’on souhaite équiper plusieurs milliers de collaborateurs. En contrepartie, la licence inclut Copilot dans l’ensemble des applications Microsoft 365 (Word, Excel, PowerPoint, Outlook, Teams et Power Platform), et pas seulement Excel.
Licences Power BI : Power BI peut être sous licence par utilisateur (environ 10 $/mois pour Pro, plus pour Premium par utilisateur) ou par capacité. L’accès aux fonctionnalités Copilot dans Power BI pourrait nécessiter un niveau de licence spécifique (probablement Power BI Pro en plus de la licence Microsoft 365 Copilot).
Alternatives gratuites : Pour des usages limités, Power BI propose déjà certaines fonctionnalités IA intégrées (comme Q&A) sans Copilot. Toutefois, les capacités véritablement conversationnelles et la génération automatique de rapports sont propres à Copilot, sans offre gratuite équivalente.
Classement / Popularité
Leader du marché : Microsoft Power BI est reconnu comme un leader du Magic Quadrant de Gartner pour l’analytique et la BI depuis de nombreuses années, y compris en 2024. Sa large adoption et son intégration dans l’écosystème Microsoft 365 renforcent sa position. Selon Gartner (2024), Microsoft bénéficie d’une part de marché fortement établie et d’une innovation continue, ce qui en fait un choix naturel pour beaucoup d’organisations.
Adoption de Copilot : Les retours initiaux des entreprises pilotes sont très positifs et considèrent Copilot comme un accélérateur significatif de productivité. Microsoft fait état d’une forte demande. Si ces bénéfices se confirment à grande échelle, Copilot pourrait consolider davantage la domination de Power BI sur le marché.
Avis des experts : Dans le domaine de la BI, la capacité pour une IA de rédiger des rapports ou de faire émerger des insights automatiquement est perçue comme une avancée majeure. L’exécution de Microsoft est observée de près : si Copilot tient ses promesses, les autres acteurs devront proposer des fonctionnalités équivalentes d’agents IA dans leurs propres plateformes.
Salesforce Tableau (Einstein GPT dans l’Analytics)
Tableau, aujourd’hui propriété de Salesforce, est une autre plateforme de BI et de visualisation de données de premier plan, reconnue pour son interface conviviale et ses visuels particulièrement riches. Salesforce a progressivement intégré son IA Einstein à Tableau (et à son offre analytique plus large, auparavant appelée Einstein Analytics puis Tableau CRM) afin de créer de véritables assistants analytiques dopés à l’IA. En 2023, Salesforce a annoncé Einstein GPT, qui apporte l’IA générative dans l’ensemble de ses produits – y compris la possibilité, pour les utilisateurs de Tableau, de générer des visualisations, de poser des questions en langage naturel, et même d’obtenir des explications générées par l’IA directement à partir de leurs graphiques. Certaines fonctionnalités préexistaient déjà, comme Ask Data (requêtes en langage naturel dans Tableau), tandis que des nouveautés telles que Explain Data font émerger automatiquement des explications possibles sur des valeurs ou anomalies observées. À l’horizon 2025, la vision de Salesforce est que l’utilisateur puisse véritablement dialoguer avec ses données dans Tableau, un peu comme avec ChatGPT, mais en s’appuyant sur les données de son entreprise, de manière sécurisée et contextuelle.

Points forts
Fonctionnalités d’analytics augmentées : Tableau propose des insights automatisés comme Explain Data, qui utilise des méthodes statistiques pour identifier les facteurs influençant une donnée. Avec Einstein Discovery (désormais intégré), la plateforme peut réaliser automatiquement des analyses de tendances et même des modèles prédictifs sur les jeux de données, suggérant des enseignements à l’utilisateur. Ces fonctions jouent le rôle d’“analystes intégrés” surveillant en permanence les données.
Intégration Einstein GPT : Grâce à l’IA générative, les utilisateurs peuvent obtenir des résumés narratifs de leurs tableaux de bord et poser des questions de suivi en langage naturel pour affiner un graphique. Par exemple, « Ventile par région et par année » permet d’ajouter instantanément ces dimensions à la visualisation. Cela améliore nettement l’expérience pour les utilisateurs non techniques.
Excellence en visualisation : Comme Tableau est déjà reconnu pour la qualité de ses visuels, l’agent IA s’appuie fortement sur cet atout : au lieu de seulement expliquer un insight, il le montre via un graphique pertinent ou une mise en évidence. L’association d’analytique visuelle et de commentaires IA rend les insights plus faciles à interpréter.
Écosystème Salesforce : L’intégration à Salesforce renforce les capacités analytiques. L’IA peut s’appuyer sur les données CRM ou des signaux externes fournis par Salesforce. Salesforce met également l’accent sur une IA “fiable” et orientée entreprise. Les clients Salesforce profitent ainsi plus facilement des fonctionnalités d’IA analytique dans leur environnement existant.
Points faibles
Complexité des licences : La tarification des fonctionnalités IA chez Salesforce peut être complexe et coûteuse. Certaines capacités peuvent nécessiter une licence CRM Salesforce ou une licence Einstein supplémentaire, en plus de Tableau. Par exemple, Einstein Discovery a longtemps été un add-on séparé.
Moins présent dans le “buzz” IA : Bien que très puissant, Tableau a parfois été perçu comme plus lent que Microsoft à adopter une expérience IA conversationnelle. En 2025, la plateforme rattrape son retard, mais Power BI et ThoughtSpot ont fait davantage de bruit dans les premiers temps de l’IA générative.
Préparation des données : Comme partout, l’IA ne peut fonctionner que sur des données correctement préparées dans Tableau. Si les sources ne sont pas bien structurées, l’IA est limitée. Cela implique toujours un travail humain (Tableau Prep, etc.), indépendamment des avancées IA.
Tarification
Tarifs Tableau : Tableau propose un modèle par rôle (Viewer, Explorer, Creator). Les fonctionnalités d’IA comme Ask Data sont disponibles pour les licences supérieures (souvent Explorer et plus). Einstein Discovery (capacités ML avancées) peut être un add-on ou inclus dans certaines offres (ex-Tableau CRM). Aucune tarification publique détaillée pour Einstein GPT en Analytics, mais on peut s’attendre à une facturation spécifique ou un packaging premium (probablement via Tableau Cloud).
Coût Einstein GPT : Salesforce a communiqué des tarifs autour de l’IA Einstein dans le CRM (~50 $/utilisateur/mois) ; pour l’Analytics, cela pourrait être intégré ou facturé à part. En général, Salesforce tend à monétiser les fonctionnalités IA, à l’image de Microsoft.
Comparatif global : Tableau est souvent considéré comme plus coûteux que Power BI. Par exemple, Creator tourne autour de 70 $/utilisateur/mois, contre 10 $ pour Power BI Pro. Si les fonctionnalités IA nécessitent des licences haut de gamme, le coût peut être élevé – mais les organisations exigeantes en analytique estiment fréquemment que l’investissement se justifie.
Classement / Popularité
Position sur le marché : Tableau reste un Leader historique de la BI. Dans le Magic Quadrant Gartner 2024, Salesforce (Tableau) figure parmi les solutions de référence, aux côtés de Microsoft, Qlik, etc. La plateforme est saluée pour la richesse de ses capacités visuelles et son adoption massive en entreprise.
Réception des nouveautés : Des fonctionnalités comme Pulse (expérience augmentée lancée en 2023) ont été mises en avant comme des avancées majeures pour les utilisateurs. L’arrivée de GPT dans Tableau maintient la compétitivité face à Microsoft. ThoughtSpot, considéré comme visionnaire, pousse également Salesforce à accélérer sur l’IA.
Avis utilisateurs : Tableau obtient généralement des évaluations élevées (souvent 4,4+ / 5 sur Gartner Peer Insights, équivalent à Spotfire). Les utilisateurs apprécient particulièrement la facilité de création de visuels. Les fonctionnalités IA sont relativement récentes, mais les retours initiaux suggèrent qu’une fois déployées à grande échelle, elles pourraient améliorer significativement la productivité, aussi bien pour les créateurs de dashboards que pour leurs consommateurs.
ThoughtSpot
ThoughtSpot est une plateforme analytique moderne qui a été pionnière dans l’approche de l’analytique pilotée par la recherche. Sa notoriété tient à une barre de recherche semblable à Google grâce à laquelle les utilisateurs peuvent saisir des questions sur leurs données (par ex. : « Chiffre d’affaires total par gamme de produits en Europe en 2024 ») et obtenir instantanément des réponses sous forme de graphiques ou de tableaux. Ces dernières années, ThoughtSpot a fortement investi dans l’IA : la solution a introduit un moteur IA (SpotIQ) capable de détecter automatiquement des insights (anomalies, corrélations), puis a intégré l’IA générative (avec ThoughtSpot Sage, qui embarque des modèles GPT-3.5/4 pour permettre des questions encore plus naturelles et la génération de commentaires narratifs). En 2024, Gartner a fait entrer ThoughtSpot dans le quadrant des Leaders, ce qui reflète sa montée en puissance. ThoughtSpot est largement utilisée dans les grandes entreprises pour l’analytique en libre-service et propose également des capacités solides d’analytique embarquée.
Points forts
Expérience de recherche en langage naturel : L’interface de ThoughtSpot est extrêmement intuitive. N’importe quel utilisateur peut saisir une question en langage naturel et la plateforme génère automatiquement la réponse à partir des données, en choisissant la meilleure visualisation. Cela démocratise vraiment l’analyse de données auprès d’un large public métier.
Insights automatisés (SpotIQ) : SpotIQ exécute automatiquement des dizaines de requêtes pour faire ressortir des éléments intéressants (par exemple : « Saviez-vous que les ventes dans le Nord-Est ont augmenté de 30 % le mois dernier ? »). C’est comme avoir un analyste junior qui explore continuellement les données pour vous.
Performance et passage à l’échelle : ThoughtSpot repose sur un moteur de calcul en mémoire très performant, ce qui permet d’obtenir des temps de réponse très rapides, même sur des ensembles de données massifs. Conçue pour l’échelle entreprise (jusqu’à des milliards de lignes), la solution maintient des réponses quasi instantanées essentielles pour l’expérience de recherche interactive.
Usage innovant des LLM : Grâce à ThoughtSpot Sage (intégration GPT), les utilisateurs peuvent poser des questions complexes et obtenir des réponses narrées, parfois multi-étapes. ThoughtSpot se connecte directement aux principaux data warehouses cloud (Snowflake, BigQuery, etc.), garantissant que les réponses de l’IA sont basées sur les données gouvernées et actualisées.
Points faibles
Personnalisation visuelle : Historiquement, l’accent mis sur la recherche a rendu ThoughtSpot moins flexible dans la création de visualisations très personnalisées comparée à Tableau ou Power BI. Les graphiques sont générés automatiquement et pour des tableaux de bord complexes, certains utilisateurs complètent encore avec d’autres outils. Des améliorations ont été apportées, notamment un SDK avancé, mais la perception demeure chez certains.
Coût : ThoughtSpot est relativement onéreux. L’édition Team commencerait autour de 95 $/mois (probablement par utilisateur) et l’offre Essentials autour de 1 250 $/mois pour 20 utilisateurs (environ 62 $/utilisateur). Ces tarifs sont supérieurs à de nombreuses plateformes BI. Même si ThoughtSpot argumente que moins d’utilisateurs ont besoin d’une licence complète, le budget reste un sujet important.
Courbe d’apprentissage pour les usages avancés : Si la recherche est simple, la préparation des données et le data modeling demandent de l’expertise. Un schéma bien conçu est nécessaire pour que l’IA interprète correctement les questions. Si les données sont mal structurées, les résultats peuvent être confus. Il faut donc souvent l’intervention de data engineers.
Tarification
Offres : Les informations publiques indiquent une édition Team (~95 $/mois) et une offre Essentials (~1 250 $/mois pour 20 utilisateurs), avec un engagement annuel. Les plans Enterprise dépendent du volume, du nombre d’utilisateurs et des fonctionnalités (embedded analytics, etc.).
Modèle à la consommation : ThoughtSpot propose également une tarification à l’usage (spécialement en cloud), ce qui peut être intéressant pour une intégration dans des applications clients ou des déploiements larges sans coût fixe élevé. Une différence notable par rapport au modèle par utilisateur de Tableau.
Essai gratuit : Une période d’essai et un niveau gratuit (limité) existent, mais pas d’outil gratuit permanent comme Power BI Desktop, ThoughtSpot étant principalement cloud.
Classement / Popularité
Leader en progression : Le passage de ThoughtSpot dans le quadrant Leader du Gartner 2024 souligne sa réputation croissante. Gartner met en avant son approche disruptive et son impact sur le marché de la BI.
Satisfaction utilisateur : Les retours utilisateurs sont très positifs — par exemple une note d’environ 4,6/5 sur Gartner Peer Insights (400+ avis), supérieure à certaines plateformes établies. Les utilisateurs apprécient particulièrement la recherche et la rapidité.
Part de marché : La part de marché reste faible face aux géants (estimée autour de 0,1 %), mais la croissance est notable, en particulier dans les grandes entreprises (retail, finance, tech) qui cherchent à démocratiser l’accès à la donnée. Les partenariats avec les data warehouses cloud renforcent également son adoption dans les architectures modernes.
TIBCO Spotfire
TIBCO Spotfire est une plateforme analytique historique, connue pour combiner visualisation interactive des données et analyses avancées intégrées (outils statistiques, data mining, analyses en temps réel). Spotfire est particulièrement apprécié dans des secteurs comme la pharmacie, l’énergie et l’industrie manufacturière, en raison de ses fortes capacités analytiques et de gestion des données. Concernant les fonctionnalités d’« agents de données » basés sur l’IA, Spotfire a adopté l’analytique augmentée en proposant des recommandations et insights générés par l’IA. Par exemple, son moteur d’IA peut suggérer automatiquement des visualisations et identifier des schémas ou anomalies dans les données, aidant les utilisateurs à détecter des tendances qui auraient pu passer inaperçues. Spotfire prend également en charge la recherche en langage naturel sur les données (même si cette fonctionnalité est peut-être moins mise en avant que l’interface de ThoughtSpot). En 2025, Spotfire est perçu comme une plateforme mature et fiable, ayant intégré l’IA pour assister, plutôt que complètement automatiser, le processus analytique.
Points forts
Recommandations IA intégrées : Spotfire se distingue par l’augmentation de l’analyse humaine grâce à des recommandations issues de l’IA. Au fur et à mesure de l’exploration des données, la plateforme peut mettre en avant des corrélations ou variations importantes. Cela guide les utilisateurs vers les bonnes questions et accélère l’analyse exploratoire.
Fonctionnalités analytiques riches : Au-delà de l’IA, Spotfire propose un ensemble très complet de fonctionnalités : analyse géospatiale, streaming temps réel, langage d’expression puissant pour les calculs, etc. La solution constitue un véritable « guichet unique » pour les utilisateurs avancés (les data scientists peuvent même intégrer des scripts R ou Python). Les fonctions agent IA viennent compléter cela en aidant les utilisateurs moins techniques à tirer parti de la puissance sous-jacente.
Adapté à l’entreprise : Spotfire dispose de solides capacités de gouvernance, de sécurité et de gestion de très grands volumes de données. Beaucoup de grandes entreprises l’utilisent depuis longtemps. Ainsi, l’agent IA (via « Insights » ou suggestions) peut être immédiatement appliqué à des données critiques et à grande échelle, de manière sécurisée.
Satisfaction utilisateur : Spotfire bénéficie d’avis positifs (4,4/5 sur Gartner Peer avec plus de 500 avis) et est souvent salué pour son équilibre entre simplicité d’utilisation et profondeur analytique. Beaucoup remarquent que Spotfire « rend les experts encore plus experts » grâce à la combinaison de visuels interactifs et d’analyses avancées.
Points faibles
Interface utilisateur & popularité : L’interface de Spotfire, bien que fonctionnelle, est parfois jugée moins moderne ou intuitive que celle de Tableau. Malgré les améliorations, la plateforme n’a pas gagné la même popularité auprès du grand public métier, en raison notamment de la domination de Tableau et Power BI. Cela peut freiner l’acquisition de nouveaux utilisateurs, malgré des capacités solides.
Des fonctions IA non centrales : Bien que Spotfire propose des fonctions d’analytique augmentée, la solution n’a pas été autant positionnée autour du concept « discuter avec ses données ». Les fonctions IA sont davantage de l’assistance (recommandations, auto-charting) qu’un véritable agent conversationnel. Ceux cherchant spécifiquement cette dimension peuvent ne pas penser à Spotfire en premier, même si l’outil est puissant par ailleurs.
Complexité des licences : Spotfire propose plusieurs éditions (cloud, plateforme, etc.) avec une tarification variable, souvent négociée en contexte entreprise. Ce n’est pas aussi simple pour une petite équipe de commencer avec Spotfire + IA qu’avec Power BI ou Tableau. Il existe une version d’essai gratuite, mais au-delà, on passe généralement par un processus commercial.
Tarification
Fourchette : Les prix rapportés vont d’environ 0,99 $ à 1 250 $, probablement par mois selon l’édition. Cette amplitude reflète différents niveaux : une version très limitée (potentiellement un accès cloud individuel autour de 1 $) jusqu’à des licences entreprise pouvant dépasser 1 250 $/mois. Une autre source mentionne 200 $ par utilisateur et par mois pour une souscription de base, ce qui correspond à un positionnement premium historique.
Éditions : Spotfire Cloud vs Spotfire Platform. Spotfire Cloud fonctionne davantage par abonnement utilisateur, tandis que l’on-premise ou la plateforme peuvent être facturés par serveur/cœur ou par rôle (analyste/contributeur vs simple lecteur). Par exemple, une licence analyste/designer coûte plus cher, alors qu’un rôle lecteur peut être très peu onéreux (jusqu’à ~0,99 $ dans certains cas).
Valeur : Beaucoup d’entreprises jugent le retour sur investissement satisfaisant, une seule licence Spotfire pouvant éviter l’achat de solutions statistiques supplémentaires ou de développements spécifiques. Mais pour de simples tableaux de bord, la solution peut être plus chère que Power BI.
Classement / Popularité
Présence stable : Spotfire n’est pas toujours la solution la plus visible médiatiquement, mais elle reste régulièrement bien positionnée. Dans les classements Gartner 2024, elle se situe juste en dessous du groupe des leaders (avec IBM et SAS), considérée comme solide mais avec une « vision » légèrement moins avancée que ceux ayant misé plus tôt sur le cloud et l’analytique augmentée. Elle bénéficie néanmoins d’une base d’utilisateurs fidèle.
Adoption sectorielle : Spotfire est particulièrement répandu dans certains secteurs — par exemple, une très grande majorité des grands laboratoires pharmaceutiques l’utilisent pour l’analyse de données de recherche, et de nombreuses entreprises pétrolières et gazières s’en servent pour l’analyse géospatiale ou de forage. Ces utilisateurs « experts » apprécient sa profondeur fonctionnelle. Le marché business plus général se tourne plus souvent vers Power BI ou Tableau.
Évolutions récentes : Depuis l’intégration de TIBCO dans Cloud Software Group (après sa fusion avec Citrix), des investissements ont été faits pour renforcer l’IA au sein de Spotfire. Les dernières versions mettent davantage en avant l’IA et l’intégration avec les pipelines data science. Même si la solution ne fait pas autant la une que celles revendiquant « ChatGPT dans la BI », elle progresse régulièrement. Sa présence dans les listes « Best AI Analytics Software 2025 » confirme qu’elle est considérée comme un acteur majeur dans l’usage de l’IA pour l’analytique.
Qlik Sense (avec Insight Advisor)
Vue d’ensemble : Qlik Sense est une plateforme BI et de « data discovery » de premier plan, historiquement reconnue pour son moteur analytique associatif. Qlik a pleinement adopté l’analytique augmentée grâce à son Insight Advisor, qui fournit aux utilisateurs des insights, des visualisations et des récits générés par l’IA. La plateforme Qlik est capable de répondre à des questions en langage naturel et de produire des analyses à travers l’ensemble du modèle de données. En 2023, Qlik a présenté Qlik Staige, une initiative dédiée à l’IA combinant automatisation et analytique pilotée par le machine learning afin d’accélérer la prise de décision. Grâce à ces fonctionnalités, Qlik Sense dispose en pratique d’un assistant IA capable de générer automatiquement des insights, voire des tableaux de bord analytiques complets, à partir de simples instructions utilisateur – ou même de façon automatique sur la base du profilage des données.
Points forts
Moteur associatif avec IA : Le moteur associatif unique de Qlik permet d’explorer les données de manière non linéaire (sélections, zones grisées). Associé aux suggestions d’Insight Advisor, il peut révéler des relations cachées que des requêtes linéaires ne détecteraient pas. L’IA exploite ce fonctionnement pour mettre en évidence des facteurs ou anomalies potentiellement importants.
Analyse en langage naturel et conversationnelle : Insight Advisor Chat permet aux utilisateurs métier de poser des questions en langage naturel et d’obtenir des réponses, sous forme visuelle ou narrative. Cette fonctionnalité est disponible dans l’édition cloud de Qlik et peut s’intégrer à des outils tels que Slack ou Teams, amenant l’analytique directement dans les environnements de travail.
Analytique complète : L’initiative Qlik Staige (lancée fin 2023) propose une offre vraiment de bout en bout : analytique descriptive, prédictive et prescriptive, au sein d’une même plateforme. L’IA ne sert pas uniquement aux « auto-insights », mais également à alimenter des modèles prédictifs (via AutoML acquis avec Big Squid) et à générer des « data stories » (explications narratives). Cette approche intégrée séduit les entreprises cherchant une plateforme analytique unifiée.
Niveau entreprise & déploiement hybride : Qlik est disponible on-premise, en cloud ou en mode hybride. Il est souvent privilégié par les organisations nécessitant de la flexibilité dans la gestion des données. Les fonctionnalités IA fonctionnent dans ces différents contextes, ce qui signifie que même sans 100 % de données dans le cloud, l’IA de Qlik reste opérationnelle.
Points faibles
Esthétique des visualisations : Les visuels de Qlik Sense sont parfois jugés moins attractifs que ceux de Tableau. Ils sont fonctionnels, mais pour des dashboards « pixel-perfect », il faut parfois recourir à des extensions ou à des ajustements manuels. L’IA produit des graphiques, mais une « mise en forme » supplémentaire peut être nécessaire.
Courbe d’apprentissage : Le paradigme associatif demande un temps d’adaptation. Même avec l’aide de l’IA, comprendre le modèle de données et interpréter les associations grisées peut nécessiter une formation. Insight Advisor cherche à simplifier cela, mais les nouveaux utilisateurs peuvent trouver l’approche moins intuitive qu’un simple moteur de recherche analytique.
Visibilité sur le marché : Qlik reste très capable mais moins présent dans la « hype » médiatique récente. Certains décideurs peuvent ainsi sous-estimer la maturité de ses fonctionnalités IA, comparé à l’exposition médiatique de Microsoft, Salesforce, etc. Qlik doit continuer à valoriser ses innovations IA.
Tarification
Licence Qlik : Qlik Sense est généralement facturé par utilisateur (Professional ou Analyzer). À titre indicatif : Professional ~ 40 $/utilisateur/mois ; Analyzer ~ 20 $/utilisateur/mois (selon les accords). Insight Advisor et les fonctionnalités IA de base sont incluses dans Qlik Cloud. Les capacités avancées (ex : AutoML) peuvent être proposées en option. Il existe également des modèles de tarification basés sur la capacité pour les grands déploiements.
Proposition de valeur : Pour les organisations exploitant l’ensemble des capacités de Qlik (intégration, analytique et IA), le coût peut être justifié par la consolidation des outils. Pour un usage principalement orienté dashboarding, le prix peut paraître supérieur à celui de Power BI.
Essai gratuit : Qlik propose une période d'essai et une version Desktop gratuite pour un usage personnel (conception locale). Cela permet d’expérimenter Insight Advisor à petite échelle.
Classement / Popularité
Statut de Leader : Qlik est depuis de nombreuses années un Leader dans le Magic Quadrant de Gartner, y compris en 2024. Gartner a particulièrement salué l’exécution de Qlik et ses investissements IA (dont Staige), confirmant sa pertinence dans l’ère de l’IA.
Retour utilisateurs : Les avis utilisateurs se situent autour de 4,5/5 sur de nombreuses plateformes. Qlik est apprécié pour ses performances et son moteur associatif. Les fonctionnalités IA se sont nettement améliorées — les premières versions d’Insight Advisor étaient jugées limitées, mais les versions récentes fournissent des suggestions nettement plus utiles.
Adoption du marché : Qlik n’a pas le volume d’utilisateurs de Power BI, mais bénéficie d’une base très solide dans les secteurs intensifs en données. De nombreux clients migrent vers Qlik Cloud afin de tirer parti des fonctionnalités IA et de l’intégration avec Qlik Data Integration.
AnswerRocket
AnswerRocket est une plateforme d’analytique alimentée par l’IA, conçue pour permettre aux utilisateurs métier d’obtenir rapidement des insights grâce à des requêtes en langage naturel et à la génération automatisée de rapports. Elle agit en quelque sorte comme un analyste intelligent : on lui pose une question, et la plateforme récupère les données, crée les graphiques, réalise les analyses et fournit même des interprétations écrites. AnswerRocket est particulièrement populaire dans les domaines du marketing et des biens de grande consommation (CPG), où les responsables de marque peuvent analyser facilement la performance de campagnes ou les tendances de ventes, sans devoir attendre l’intervention d’équipes data. La plateforme combine une interface de recherche avec des capacités IA (incluant des techniques de machine learning) afin d’automatiser de nombreuses tâches analytiques manuelles.
Points Forts
Questions en langage naturel et facilité d’usage : Les utilisateurs métier peuvent formuler leurs questions en langage courant et AnswerRocket les traduit automatiquement en requêtes. Par exemple : « Affiche la croissance des ventes par région au cours des 6 derniers mois et explique les facteurs ». La plateforme génèrera un graphique avec les taux de croissance par région et une narration du type : « Les ventes ont augmenté de 10 % dans le Nord-Est grâce au produit X, tandis que le Sud a connu une baisse en raison de Y », en s’appuyant sur son analyse IA.
Insights automatisés et reporting : La plateforme peut automatiser le reporting récurrent. Elle produit des graphiques prêts à être intégrés dans des présentations et même des rapports multi-pages, programmables. Certaines agences l’utilisent pour générer des rapports clients, économisant ainsi des heures de travail manuel. Elle peut également envoyer des insights proactifs (alertes lors de variations anormales de KPI), agissant comme un analyste virtuel disponible en permanence.
Modèles spécialisés par domaine : AnswerRocket s’est concentré sur certains domaines (marketing, analytique des ventes) et dispose de connaissances ou de modèles prêts à l’emploi qui le rendent immédiatement pertinent dans ces secteurs. Cette spécialisation peut générer des insights plus adaptés que des outils généralistes.
Intégration : La solution se connecte aux sources de données courantes (Excel, bases SQL, data warehouses cloud). Elle est conçue pour se superposer à l’existant, sans nécessiter de migration des données, facilitant le déploiement et exploitant des données à jour.
Points Faibles
Profondeur d’analyse personnalisée : Si elle est excellente pour les questions rapides, la plateforme ne remplace pas toujours un outil BI complet pour des analyses complexes multi-dimensionnelles. Pour des croisements de données très spécifiques ou des visualisations inédites, il peut être nécessaire d’exporter les données vers un autre outil. L’abstraction simplifie l’usage, mais limite parfois la flexibilité.
Scalabilité et performance : En fonction du volume de données et de la complexité des requêtes, les performances peuvent varier. Une question nécessitant un calcul lourd (par exemple une régression à la volée ou le scan de millions de lignes sans pré-agrégation) peut entraîner des latences. L’éditeur gère probablement cela par du traitement in-memory ou de la mise en cache, mais les très grands volumes restent un point d’attention.
Taille du fournisseur : AnswerRocket est un acteur plus petit que Microsoft ou Salesforce. Certaines grandes entreprises peuvent hésiter à dépendre d’un fournisseur plus réduit pour des usages stratégiques, même si beaucoup l’adoptent pour sa spécialisation. La pérennité et l’innovation continue sont des sujets à surveiller dans un marché très concurrentiel.
Tarification
Coût de départ : Selon SelectHub, les tarifs d’AnswerRocket « commencent dans une fourchette de 10 à 100 $ » (probablement par utilisateur et par mois, selon les fonctionnalités et l’échelle). Cela suggère une entrée relativement accessible, avec une montée en prix pour les déploiements entreprise. L’absence de tarif public clair indique vraisemblablement un modèle de devis personnalisé pour les grands comptes.
Modèle entreprise : Souvent, ces solutions sont facturées en fonction du nombre d’utilisateurs ou de la consommation. Si de nombreux collaborateurs doivent y accéder, l’abonnement peut représenter plusieurs dizaines de milliers de dollars par an. L’argument est qu’elle se rentabilise en remplaçant des tâches analytiques manuelles.
Essai / POC : AnswerRocket propose généralement une preuve de concept ou un pilote (souvent basé sur les données du prospect). Il n’existe pas de version gratuite permanente ; il s’agit d’un produit commercial.
Classement / Popularité
Reconnaissance : Solutions Review a classé AnswerRocket parmi les meilleurs logiciels d’analytique IA pour 2025, ce qui indique une bonne réputation dans la catégorie de l’analytique augmentée. Il est régulièrement comparé aux grands fournisseurs et se distingue par son ergonomie.
Satisfaction utilisateur : D’après SelectHub, la satisfaction utilisateur est « excellente » (basée sur 46 avis) et AnswerRocket occupe la 22ᵉ place dans leur annuaire Data Analytics Software. Les utilisateurs apprécient de ne pas avoir à coder ni à effectuer d’analyses manuelles.
Adoption : Sa part de marché reste modeste ; AnswerRocket fait partie des nouvelles solutions d’analytique IA (concurrents : Tellius, Sisu Data, etc.). Il compte néanmoins des références notables (dont des entreprises du Fortune 500) et gagne du terrain dans les agences et équipes marketing. Il ne remplace pas nécessairement les grandes plateformes BI, mais est souvent utilisé en complément pour accélérer l’analyse ad-hoc et le reporting.
Autres solutions notables (Other Notable Mentions)
IBM Watson et Cognos Analytics : IBM a intégré les capacités d’IA de Watson dans Cognos Analytics (sa plateforme BI). Cognos peut désormais générer automatiquement des insights et proposer des analyses conversationnelles. Watson Assistant est également utilisé dans certaines organisations comme agent de question-réponse sur les données (bien qu’il soit plus souvent utilisé sur les documents). Les offres IBM sont robustes et de niveau entreprise, mais bénéficient d’une visibilité moindre dans l’écosystème actuel d’analytique IA. Elles restent un choix privilégié dans les environnements fortement orientés IBM, avec des forces en gouvernance et en scalabilité.
SAP Analytics Cloud (SAC) : La plateforme analytique de SAP inclut les fonctionnalités Smart Insights et Search to Insight, pilotées par l’IA. Elles permettent aux utilisateurs de SAC (souvent dans des environnements SAP) d’interroger les données en langage naturel et d’obtenir des explications automatiques sur les visualisations. Il s’agit de la réponse de SAP à l’analytique augmentée au sein de son écosystème.
Sisense Fusion : Sisense, connu pour l’analytics embarqué (embedded analytics), propose les capacités Fusion qui intègrent des insights IA directement dans les applications. La solution peut automatiquement mettre en évidence des tendances ou anomalies pour les utilisateurs, sans même qu’ils posent de questions. Sisense offre également des requêtes en langage naturel via des bots comme BloX et s’intègre avec des outils de messagerie. C’est un acteur particulièrement pertinent pour les cas d’usage d’analytics embarqué dans un produit destiné à des clients.
Yellowfin – Signals & Stories : Yellowfin BI (éditeur australien) propose Signals, un moteur IA qui analyse en continu les données afin d’identifier des changements significatifs et d’alerter automatiquement les utilisateurs, et Stories, un espace collaboratif narratif. La plateforme vise à automatiser la découverte d’insights puis à permettre aux utilisateurs de construire un récit autour des données. Yellowfin n’a pas la part de marché des grands acteurs, mais son approche automatisée des signaux est avancée et a été reconnue dans les rapports Gartner.
Oracle Analytics Cloud : Oracle est devenu leader en 2024 (selon Gartner), en partie grâce à l’intégration de l’IA dans sa plateforme analytique. Oracle Analytics exploite le machine learning pour réaliser, par exemple, des analyses de facteurs clés (key driver analysis) et, avec les données issues des applications Oracle Fusion, peut générer des récits automatiquement. Parmi les nouveautés, on note une application mobile entièrement pilotée par la voix, permettant d’interroger verbalement les données. Pour les organisations déjà engagées dans l’écosystème Oracle, l’évolution est particulièrement intéressante.
Classements des produits et tendances du marché
Avec le nombre croissant d’agents data IA et d’outils d’analyse disponibles, comment se positionnent-ils ? En termes de popularité utilisateur et d’évaluations d’experts :
Leaders Gartner & Forrester : À l’horizon 2024/2025, Microsoft, Salesforce (Tableau), Qlik, ThoughtSpot, Oracle figurent parmi les Leaders du Magic Quadrant Gartner pour les plateformes Analytics & BI. Power BI domine largement en part de marché grâce à son ubiquité, tandis que Tableau reste une référence en visualisation. La montée de ThoughtSpot illustre la demande croissante pour l’analyse basée sur la recherche et l’IA. L’arrivée d’Oracle et Google (via Looker) dans le carré des Leaders montre de nouvelles forces dans l’analytics cloud. De leur côté, TIBCO Spotfire, IBM Cognos, SAS restent juste en dessous des Leaders, avec des cas d’usage solides et une base utilisateur fidèle.
Avis utilisateurs : Sur Gartner Peer Insights, ThoughtSpot affiche l’une des meilleures notes clients avec 4,6/5, dépassant beaucoup de concurrents. Power BI et Tableau tournent autour de 4,4–4,5 avec des centaines d’avis – un signe de satisfaction large. Qlik et Spotfire se situent aussi dans une moyenne élevée (autour de 4,3–4,5). Les outils plus spécialisés ou émergents (AnswerRocket, etc.) comptent moins d’avis mais obtiennent généralement des retours positifs, notamment sur la facilité d’usage. Les utilisateurs soulignent par exemple que “ThoughtSpot offre une approche de recherche pour des insights rapides, tandis que Tableau excelle dans les visualisations personnalisées” – illustrant que chaque solution a sa force perçue.
Popularité Open-Source (agents IA) : Sur GitHub, AutoGPT a été l’un des projets les plus étoilés en 2023 (100k+), déclenchant une vague d’innovation. LangChain est devenu indispensable pour les développeurs (~78k stars fin 2024). Même s’il ne s’agit pas de “produits” au sens traditionnel, leur popularité montre l’intérêt très fort pour la création d’agents IA personnalisés.
Parts de marché estimées : Dans le marché analytique global (au-delà de l’IA), Microsoft domine avec une part estimée à 30 %+ dans l’usage des outils BI. Tableau/Salesforce et Qlik suivent. ThoughtSpot, plus récent, reste plus petit mais en croissance rapide. Le segment “AI Analytics” lui-même était évalué autour de ~13 Md$ en 2024, avec une forte croissance prévue. Cela indique qu’aujourd’hui, l’IA est devenue une fonctionnalité incontournable dans l’analytics — on ne parle plus d’un marché séparé, mais d’une bataille de capacités IA au sein des plateformes BI.
Études de cas & retours d’expérience : Des entreprises de multiples secteurs ont rapporté des résultats concrets grâce à ces agents data IA. Par exemple, des agences marketing utilisent les fonctionnalités IA d’AgencyAnalytics pour réduire de plusieurs heures le temps consacré à la rédaction de rapports. Des institutions financières exploitent DeepSeek Agent pour faire tourner des robots de recherche en trading 24h/24 et 7j/7. Dans le retail, certaines enseignes utilisent Power BI Copilot pour générer automatiquement des synthèses narratives lors des réunions hebdomadaires, au lieu de mobiliser des analystes. Ces exemples démontrent que, lorsqu’ils sont bien déployés, les agents IA peuvent offrir un retour sur investissement immédiat en économisant du temps et en révélant des insights difficiles à obtenir manuellement.
Tendance – Des copilotes partout : Une tendance forte est l’émergence de “copilotes” dans presque tous les outils – GitHub Copilot pour le code, 365 Copilot pour Office, et désormais des BI Copilots dans les plateformes analytiques. Les Big Tech (Microsoft, Google, Salesforce) dominent le développement d’assistants IA généralistes. Cette domination apporte des solutions puissantes mais élève fortement la barre pour les acteurs plus petits, qui doivent souvent se spécialiser (comme AnswerRocket, ThoughtSpot, etc.).
En résumé, le marché des agents data basés sur l’IA en 2025 est vivant et en évolution rapide. Les éditeurs d’analytics traditionnels injectent de l’IA pour rester leaders, tandis que de nouveaux acteurs (ainsi que des projets open-source) repoussent les limites de l’autonomie et de la facilité d’utilisation. Pour une organisation en phase de sélection, le choix dépendra souvent de l’alignement avec l’écosystème existant (Microsoft, Salesforce, ou autres), du niveau d’autonomie recherché, du budget, ainsi que du niveau de compétences des utilisateurs. La bonne nouvelle, c’est qu’il existe désormais une solution pour presque chaque besoin – allant d’un outil « point-and-click » capable de générer les graphiques d’une présentation, jusqu’à un framework Python capable de mener seul un projet de recherche complet. La course est lancée pour déterminer quels agents et plateformes apporteront le plus de valeur et capteront l’adoption majoritaire dans les années à venir, mais ceux présentés dans ce rapport font clairement partie des principaux prétendants aujourd’hui.