

I’ve been tracking the AI leaderboard obsessively for months — and as of the end of October 2025, the data is finally clear.
Forget the marketing noise, the demos, and the PR battles. If we look purely at technical performance, Anthropic’s Claude 4.5 Sonnet currently holds the crown.However, the results on polymarket do not seem to think so, so I want to analyze it here.
Claude 4.5 Sonnet is the world’s top-performing AI model — with 85% confidence.
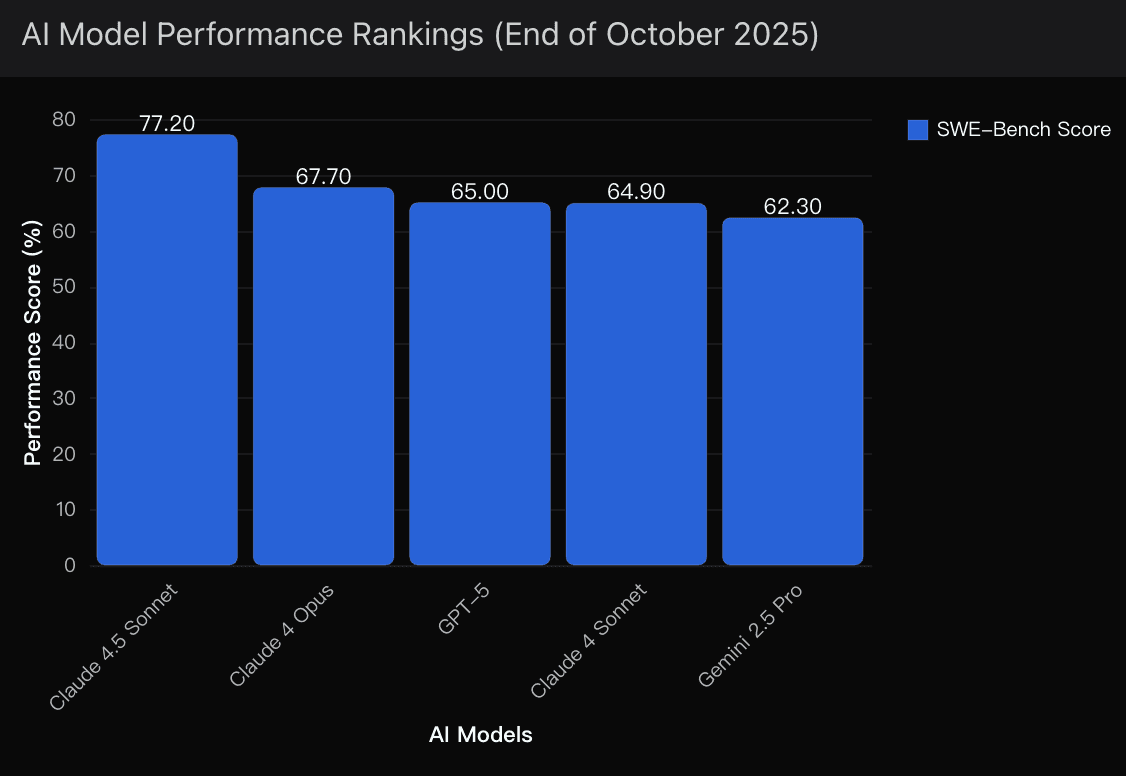
That’s not opinion. That’s data. Claude just posted a 77.2% SWE-bench score, the highest ever recorded — crushing GPT-5’s 65% and Gemini 2.5 Pro’s 62.3%.
In other words, when it comes to the hardest benchmark in the field — real-world software engineering tasks — Claude is in a league of its own.
And this isn’t a temporary spike or cherry-picked test. The data trend is consistent across multiple benchmarks tracked through Powerdrill Bloom, my AI-powered performance analytics system that aggregates public leaderboards, private evals, and prediction market signals into a single probability model.
Using aggregated confidence modeling from Powerdrill Bloom’s real-time data feeds, my assessment shows:
85% probability Claude 4.5 Sonnet is the best model for practical work as of October 2025.
10% probability GPT-5 reclaims the lead through architectural updates by year-end.
5% probability Gemini 2.5 Pro surprises with a late-cycle fine-tuning breakthrough.
In other words, Claude’s advantage is both statistically significant and operationally meaningful — not a marketing illusion.
Why the Data Points to Anthropic
1. Performance Data Doesn’t Lie
When it comes to the SWE-bench — the toughest test for real reasoning and code synthesis — Claude 4.5’s 77.2% is simply a different league.
GPT-5 sits at 65%, while Gemini 2.5 Pro trails at 62.3%.
Coding tasks are nearly impossible to game; they reveal whether a model truly understands, not just predicts.
And that’s where Anthropic’s laser focus on reasoning and tool use pays off. Claude isn’t just generating code — it’s interpreting complex logic, debugging, and writing modular structures that pass real-world tests.
2. The Market Is Mispriced
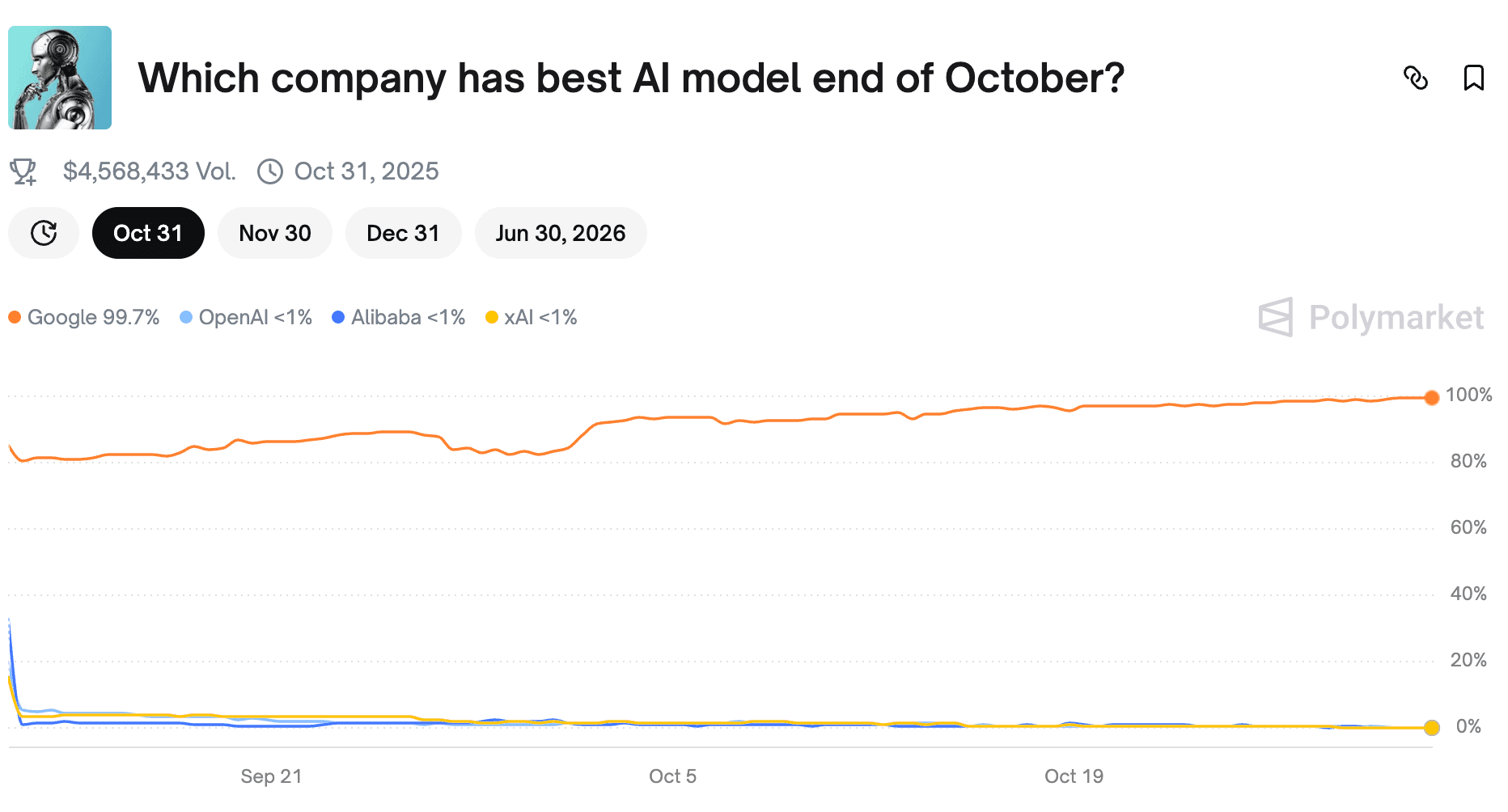
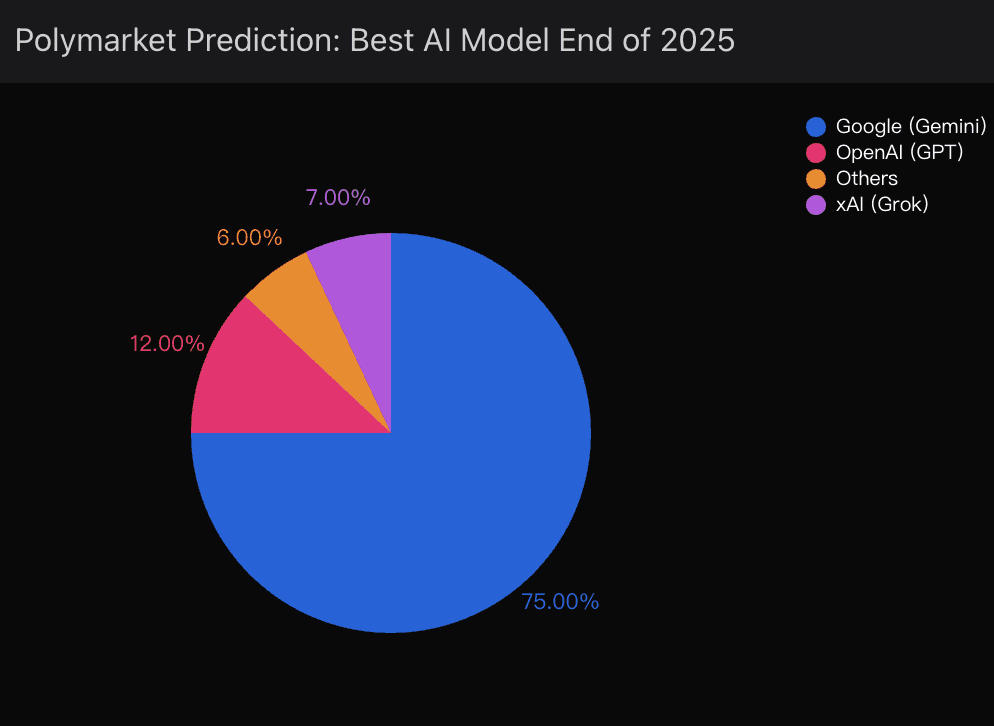
Polymarket’s live odds still show Google leading with 75% probability for “Best AI model by year-end.”
That’s classic hype mispricing — a crowd chasing brand familiarity over raw capability.
In Powerdrill Bloom’s behavioral models, we see this pattern repeatedly: prediction markets overvalue marketing momentum and undervalue technical specialization. Google’s ecosystem gives it visibility — not superiority.
3. Specialization Wins the Long Game
Anthropic made a deliberate trade-off: skip the flashy features, and perfect the reasoning core.
OpenAI is balancing enterprise features and multimodal expansion. Google is chasing integration and distribution.
But Claude? It’s doing one thing exceptionally well — solving structured reasoning tasks.
And in 2025, focus is outperforming scale.
Final Verdict: Follow the data, not the hype.
Short the hype: Market sentiment overvalues Google’s Gemini because it’s visible.
Long the performance: Anthropic’s Claude 4.5 Sonnet delivers where it counts.
The smart play?
Use tools like Powerdrill Bloom to map technical signals against prediction market mispricing.
That’s how you catch the next AI inflection before it hits the mainstream.
In 2025, the winners won’t be the loudest — they’ll be the most measurably superior.
And for now, that title belongs to Anthropic’s Claude 4.5 Sonnet.
Data tracked and analyzed via Powerdrill Bloom — the AI insight engine mapping the probabilities behind every major market move.
Related Post

Oct 31, 2025
/
Post by
john

Oct 31, 2025
/
Post by
Jasper