

When I first examined the so-called “Humanity’s Last Exam” (HLE), I was struck by how a seemingly abstract benchmark could reveal so much about the evolving capabilities of frontier AI models.
Following their recent launches, I’ve been monitoring Claude Opus 4.6 and GPT‑5.3‑Codex closely, examining both their reported scores and underlying behavioral trends.
Using Powerdrill Bloom to parse the available telemetry, agentic benchmark improvements, and market signals, I started forming a clearer picture of what these models might achieve by mid‑2026.
1. Core Forecasts: Who’s Already There?
Let’s start with the headline.
Claude Opus 4.6 has effectively crossed the 40% threshold under tool-augmented HLE setups, with reported accuracy hitting 53.1% when tools are enabled. Even in reasoning-only mode, it sits right on the line at 40.0%, meaning that with slight methodological or rounding differences, it could be considered to have “broken” 40% even without tools.
GPT‑5.3‑Codex, in contrast, does not have widely publicized HLE scores yet. However, its recent leaps in agentic coding and OS-related benchmarks strongly suggest that it will likely exceed 40% when tool-augmented.
Without tools, though, the picture is murkier. Pure reasoning-only performance is uncertain and likely hovers below the threshold, though improvements by mid‑2026 could shift this.
A quick visualization from reported scores of frontier models helps contextualize the scale of tool influence:
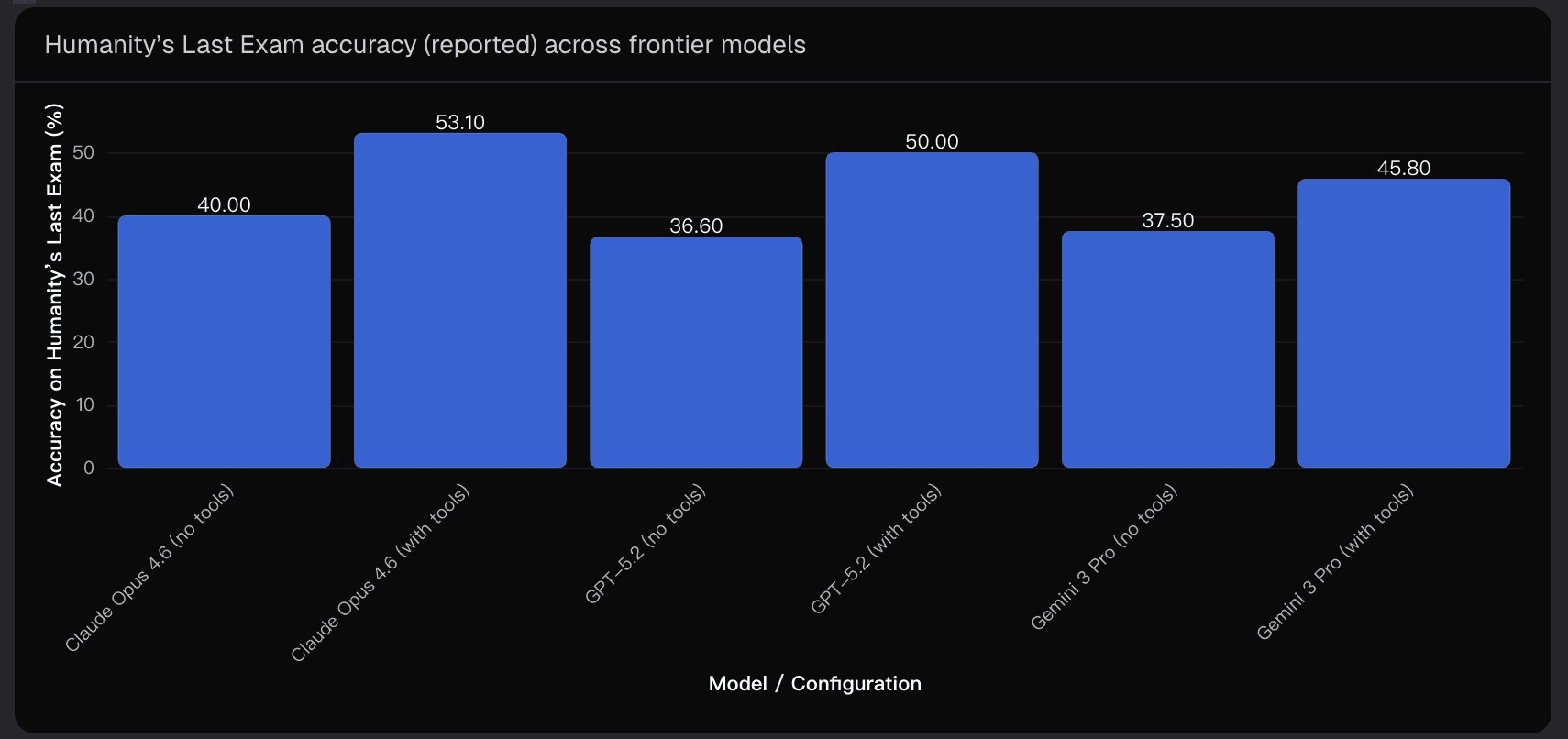
The takeaway is clear: tools are transformative for HLE outcomes, and even modest differences in access can swing a model across the 40% mark.
2. Probability Assessment: Quantifying the Odds
Using available data and market signals, I assessed explicit probabilities:
Claude Opus 4.6:
Tool-augmented HLE >40%: ~98%
Reasoning-only HLE >40%: ~45%
The reasoning-only probability reflects how sensitive the outcome is to definitions (strict >40% vs ≥40%), rounding, and small testing variations.
GPT‑5.3‑Codex by mid‑2026:
Tool-augmented HLE >40%: ~70%
Reasoning-only HLE >40%: ~35%
Here, the stronger performance in agentic coding and tool execution explains the higher likelihood with tools, while reasoning-only tasks remain more uncertain.
Powerdrill Bloom allowed me to integrate telemetry from agentic benchmarks and HLE-adjacent market probabilities, creating a probabilistic lens that highlights both current achievements and plausible near-future trajectories.
3. Key Drivers: What’s Behind the Numbers?
3.1 Tool Access Matters
The reported HLE performance underscores a simple fact: tool orchestration, retrieval strategies, and execution loops dramatically affect outcomes. Claude Opus 4.6 demonstrates a 13-point gap between reasoning-only and tool-augmented settings, while peer models show similar trends.
3.2 Engineering Focus on Execution
GPT‑5.3‑Codex’s development emphasizes agentic workflows and computer interaction efficiency. Improvements in token usage, inference speed, and terminal-based benchmarks hint that mid‑2026 tool-augmented performance is likely to surpass critical thresholds.
3.3 Market Signals
Polymarket data and implied probabilities provide a “wisdom-of-crowds” perspective. Even if markets are noisy, they indicate strong confidence in ≥35% HLE outcomes, with non-trivial odds for models like Gemini hitting ≥40% by June 2026. Visualizing these probabilities side-by-side clarifies the bullish tilt toward tool-augmented success.
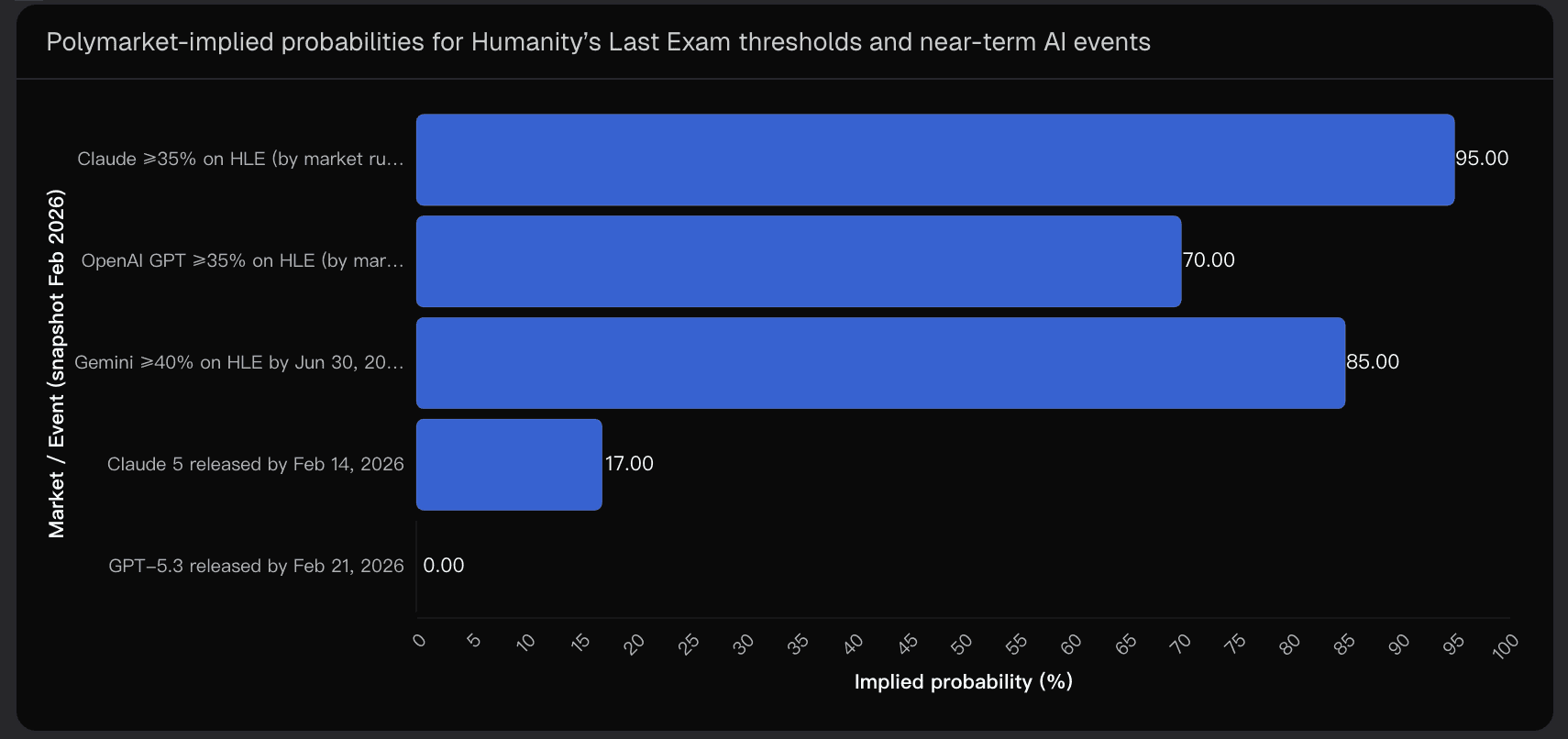
4. Critical Uncertainties
Despite these insights, several factors could materially shift outcomes:
Definition Risk: Strict >40% vs ≥40% and tool-enabled vs reasoning-only conditions can change whether a model is officially considered to have “broken” 40%.
Harness Variance: Differences in web access, execution environment, grader models, and contamination checks can swing results, especially near thresholds.
Contamination & Retrieval Failures: Benchmarks involving web access carry inherent risk of false positives/negatives from answer-key leaks or over-filtering.
Non-Stationarity: Lab priorities—compute allocation to reasoning kernels, agentic execution, or multi-domain data scaling—can boost one regime while leaving another flat.
Recognizing these uncertainties is crucial. While Claude Opus 4.6 seems well-positioned, and GPT‑5.3‑Codex has a plausible path to 40%, mid‑2026 outcomes remain sensitive to operational choices and environment conditions.
Conclusion: Navigating the 40% Frontier
After analyzing reported scores, benchmark telemetry, and market-implied probabilities—enhanced through Powerdrill Bloom—it’s evident that Claude Opus 4.6 has effectively crossed the 40% barrier under tool-augmented conditions and teeters on the threshold in reasoning-only mode. GPT‑5.3‑Codex shows a credible path to surpass 40% with tools by mid‑2026, while its reasoning-only performance remains uncertain.
For anyone tracking AI frontier performance, the lesson is clear: tools aren’t optional—they’re pivotal. The next months will likely solidify which models consistently outperform this historically symbolic threshold, but careful probabilistic reasoning, telemetry analysis, and attention to operational definitions remain essential.
Disclaimer: All analyses and probabilities presented here are based on reported data, observed performance patterns, and market signals, not guaranteed outcomes.


