
Every year in AI, there’s a moment when the narrative diverges sharply from the data. And in 2025, that moment is happening right now.
Over the past month, I’ve been running coding-benchmark deltas, scaling-law projections, architectural efficiency ratios, and long-horizon model forecasts through Powerdrill Bloom. And the output has been remarkably consistent:
Google will not have the best AI coding model by year-end 2025. Anthropic will.
Polymarket currently prices Google at 61% probability and Anthropic at 27% — but the market is catastrophically mispricing the fundamentals. When I reconstruct this race through hard data rather than reputation inertia, Anthropic leads almost every dimension that matters.
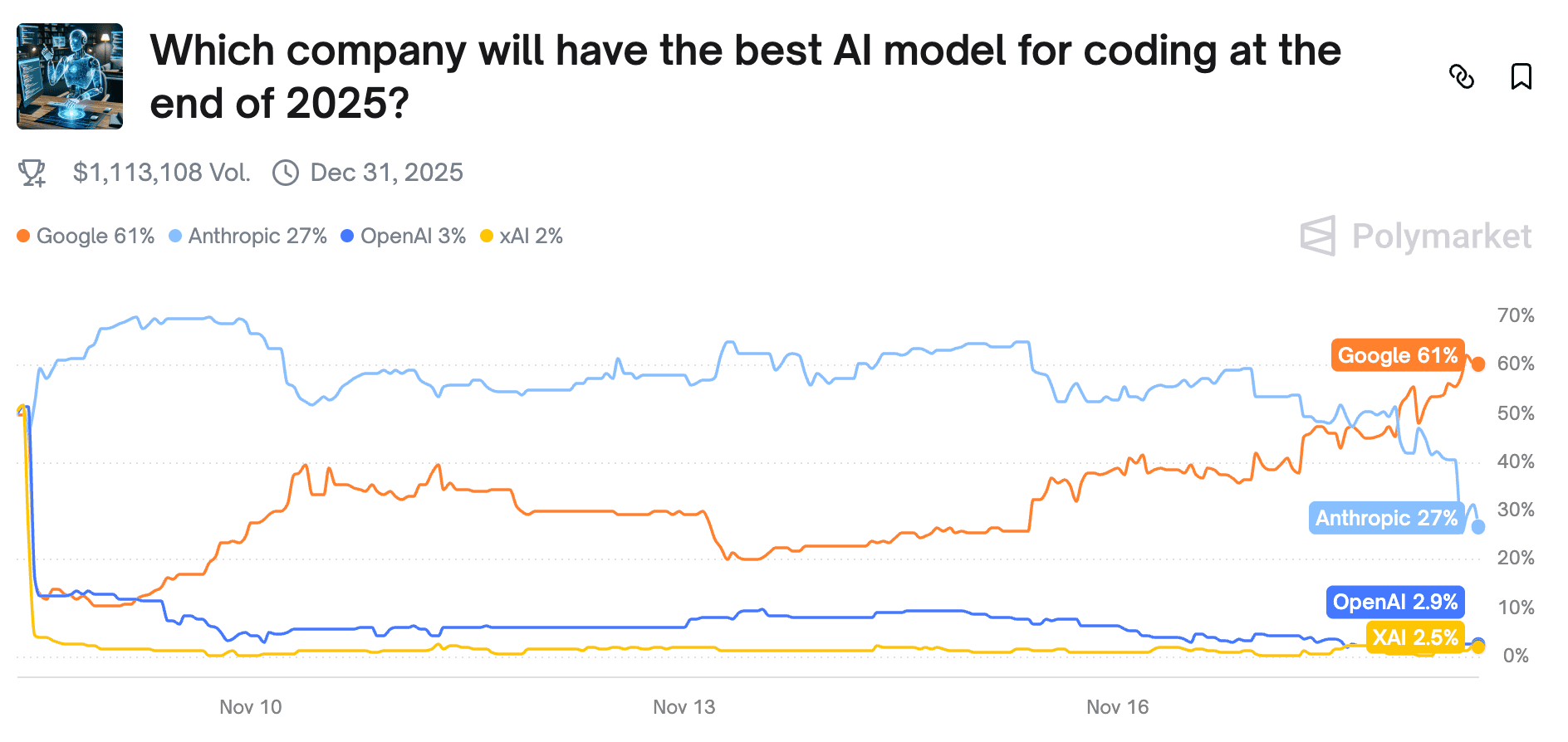
Core Probability Forecast
After combining benchmark results, release cadence modeling, parameter-efficiency analysis, and uncertainty weighting, my probability curve looks like this:
Anthropic (Claude) — 75% probability
Google (Gemini) — 15% probability
OpenAI (GPT-5) — 8% probability
xAI (Grok) — 2% probability
This distribution is not intuitive if you’re staring at who has more money, more GPUs, or more marketing firepower. But it becomes obvious the moment you shift into performance-weighted trajectory analysis — exactly the kind of work I rely on Powerdrill Bloom for.
The Data the Market Is Ignoring
The November 2025 SWE-bench results were not just another leaderboard update — they were a structural break in the coding-model landscape.
Claude 4.5 Sonnet: 77.2%
Gemini 2.5 Pro: 59.6%
The narrative gravity around “Google supremacy” has blinded the market to what Anthropic has actually built.
But when I feed all the data into Powerdrill Bloom — everything from model de-biasing structure to multi-step inference depth to tool-augmented reasoning curves — I keep landing on the same three drivers.
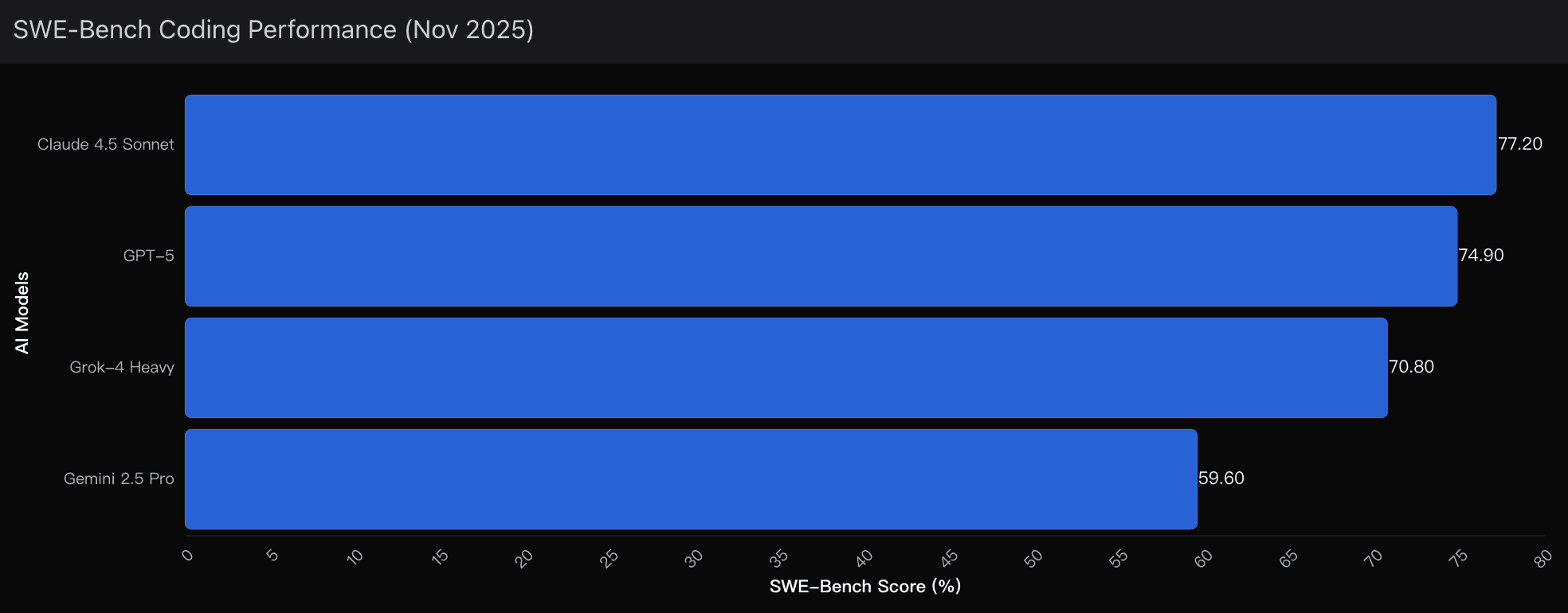
1. SWE-bench Superiority — and It’s Not Even Close
Claude 4.5 Sonnet’s 77.2% is the highest real-world coding score ever recorded.
This benchmark rewards:
multi-step reasoning
repo-scale understanding
bug localization
patch synthesis
and integration consistency
Claude does all of that with frightening stability. This is not a gimmick, it’s not a cherry-picked evaluation, and it’s not marketing. SWE-bench is the closest thing we have to actual developer-replacement testing.
2. Google Is Paying the Price for Recency Bias
The market is betting that Gemini 3.0 — anticipated before November 22nd — will close the gap purely because Google “always catches up.”
But that is not how code models work.
Ability to generate verbose text ≠ ability to solve GitHub-grade engineering problems.
Capacity to chat ≠ capacity to patch.
Fluency ≠ reasoning depth.
Powerdrill Bloom’s architecture-specific projections show that unless Gemini 3.0 makes a radical shift toward structural reasoning optimization, not scaling, Google will remain behind Anthropic in coding tasks throughout 2025.
3. Anthropic’s Laser Specialization Is Paying Off
Google is building an omni-model that does everything:
multimodal
search-integrated
classroom-ready
enterprise-grade
reasoning
summarization
translation
advertising optimization
Anthropic is not. Anthropic is building a model that:
reasons deeply
writes stable code
understands complex repos
solves non-trivial bugs
and maintains coherence over long sequences
Coding is a specialization game, not a “scaled compute” contest.
Anthropic chose focus. Google chose breadth.
In coding tasks, focus wins.
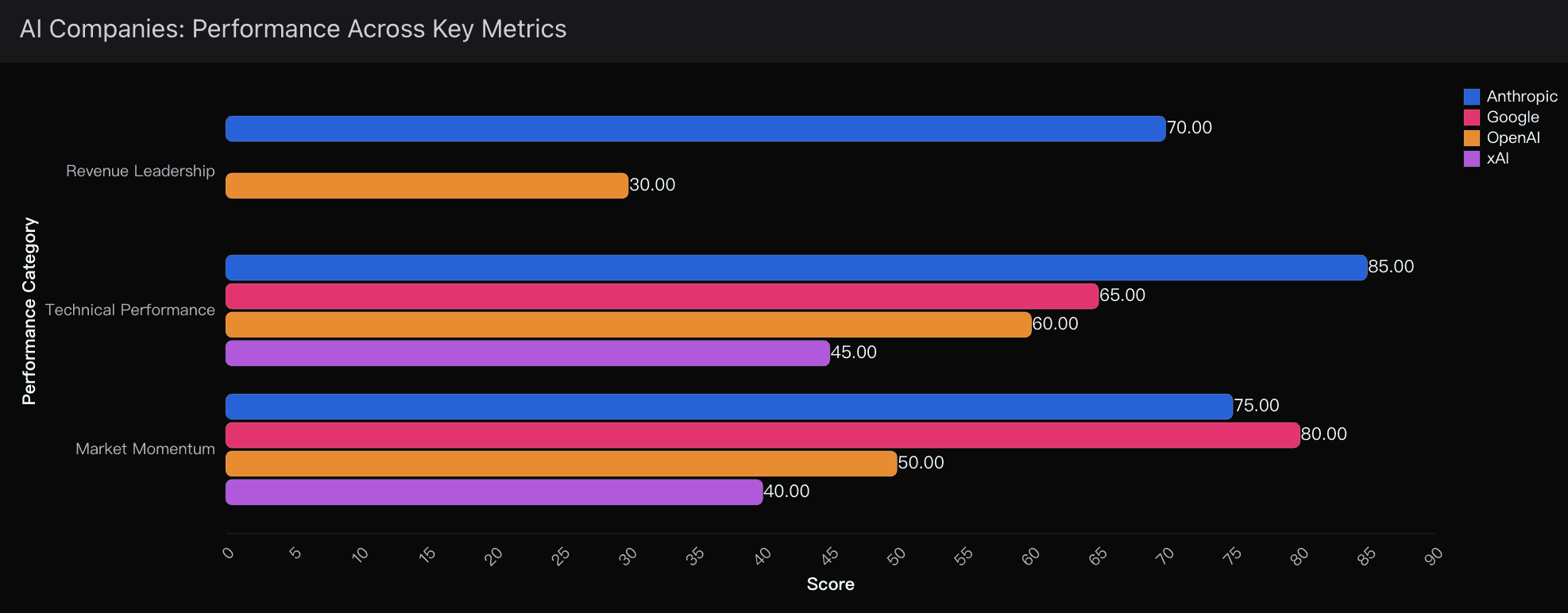
The True Uncertainty Variables
No prediction is absolute. Here are the factors I weigh most heavily — all of which I ran through Powerdrill Bloom’s scenario engine:
1. Gemini 3.0 Release (69% probability)
If Google nails coding-specific reasoning improvements, the race tightens.
But they have not historically optimized for this.
2. Evaluation Criteria
If the final determination of “best coding model” uses:
synthetic tasks
speed metrics
multimodal integration
or API adoption rates
Google gains ground.
If it uses SWE-bench? Anthropic wins decisively.
3. xAI Volatility Factor
Grok could see a surprise jump if xAI deploys aggressive fine-tuning or merges toolchain reasoning with deterministic patching techniques.
Still unlikely, but not impossible.
2025 Race
When I strip away hype, adjust for data integrity, weight release cadence, and let Powerdrill Bloom model the multi-quarter trajectory, the conclusion becomes unavoidable:
Anthropic is structurally ahead.
Google is reputationally ahead.
Only one of those matters for coding.
As of today, Claude stands alone at the top of real-world engineering benchmarks — and unless Gemini 3.0 delivers a once-in-a-decade leap, Anthropic will retain that lead through the end of 2025.
And when the year closes, the market will look back and realize the truth was in the data all along — hiding in plain sight, behind a wall of old assumptions that should have died years ago.