
简介
如果你将 AI 用于 文档审阅、财务分析或学术研究,那么你大概率对这样一个令人沮丧的循环很熟悉:一次又一次地把同样的 PDF 和 Excel 表格上传到你的 AI 助手。每当你开始一个新会话时,AI 就会患上“失忆”。它会忘记你昨天上传的 50 页研究论文,丢失你的财务模型上下文,并且要求你从头解释项目目标。
为什么会这样?大多数 AI 工具把文件上传视为临时上下文,而不是持久知识。虽然这些系统很擅长在当下处理信息,但它们缺乏专门的长期保留基础设施。
要构建真正智能的工作流,你需要从一次性文件上传过渡到持久记忆层。本指南将解释为什么标准 AI 聊天机器人总是在处理你的文件时从头开始,以及如何使用 MemoryLake——一个持久的 AI 记忆基础设施——为你的文档、表格和研究材料构建一个可复用、可搜索、持久耐用的记忆工作流。
快速回答
为 AI 存储 PDF、Excel 和研究记忆是什么意思?
这意味着摆脱临时文件上传,建立一个持久记忆基础设施,让你的文档被持续存储、向量化,并被结构化,以便在多个会话和工具中持续供 AI 检索。
为什么 AI 通常会从头开始?
AI 模型在严格的上下文窗口限制内运行。当会话结束或上下文窗口填满时,你上传文件的临时记忆就会被清除。标准聊天历史会保留文本,但不会以持久方式索引复杂文件以支持稳健的未来检索。
MemoryLake 如何解决这个问题?
MemoryLake 作为持久 AI 记忆基础设施层运行。你无需反复上传文件,只需将它们一次性上传到一个 MemoryLake 项目中。该平台会自动将 PDF、Excel 文件和研究数据处理为一个持久的记忆层,并可通过 API 或 MCP 直接连接到你的工作流、智能体和聊天机器人,确保你的 AI 永远不必从头开始。
为什么 AI 在处理 PDF、Excel 文件和研究时总是从头开始
要修复 AI 失忆问题,我们首先需要理解大多数 AI 平台当前处理文件和记忆方式的局限性。
聊天历史 ≠ 持久记忆
许多用户以为,只要 AI 记得三次提示之前说过的话,它就在“学习”。然而,聊天历史只是文本的线性日志。一旦对话线程太长,最早的上下文就会被挤出 AI 的活动记忆范围。它并不是一个针对复杂文件而设计的结构化、可搜索数据库。
一次性文件上传 ≠ 可复用记忆系统
当你将 PDF 或 Excel 文件拖放到标准聊天机器人界面时,系统只会在那次特定对话中临时读取它。你一打开新的聊天窗口,这个文件就消失了。这会迫使以研究为主的工作流陷入一个重复循环:上传、等待处理、再重新提示。
标准 RAG ≠ 项目记忆层
检索增强生成(RAG)非常适合在大型数据库中查找相关文本片段。然而,基础的 RAG 设置往往彼此孤立且高度技术化。它提供了可搜索性,但并不自动等同于一个整体性的项目记忆层;在这个层中,文件、对话上下文和结构化数据能够在多个用户会话和 AI 智能体之间协同共存。
更好的记忆工作流是什么样的
如果你想阻止 AI 总是从头开始,你需要一个将记忆视为基础设施的工作流。一个更好的、持久的记忆工作流应具备以下特点:
项目级记忆:信息按项目分组,这意味着所有相关的 PDF、表格和研究上下文都保存在一个专用空间中。
可复用上下文:你只需上传并处理一次文件。之后,任何连接到该项目的 AI 工具都能立即访问其中的洞见。
支持文件密集型知识:系统必须能够准确解析复杂格式,包括 Excel 中的表格数据以及学术 PDF 的复杂版式。
工具无关性:你的记忆不应被锁定在某一个特定聊天机器人里。它应当通过 API 或 MCP 连接到你使用的任何工具(ChatGPT、Claude、自定义智能体等)。
分步说明:如何使用 MemoryLake 存储 PDF、Excel 和研究记忆
MemoryLake 将自己定位为专为文件、对话和项目上下文设计的持久记忆基础设施。它弥合了原始知识输入与你持续进行的 AI 工作流之间的鸿沟。
下面是使用 MemoryLake 建立持久记忆工作流的分步指南。
步骤 1:创建项目并上传你的文件和数据
要停止反复解释,你首先需要建立一个专用的记忆容器。
登录 MemoryLake 并创建一个新项目(例如,“Q3 市场研究”)。
点击附件按钮上传你的本地文件。MemoryLake 会自动分析、分块并记录内容。
该平台支持多种文档类型,包括 PDF、Word、Excel 和 Markdown。
如果你的数据存放在其他地方,你也可以前往文件部分连接外部数据源,确保所有研究材料流入一个统一的项目记忆中。
步骤 2:在 Playground 中搜索并与项目聊天
在将这套记忆集成到外部工具之前,你应该先验证 AI 是否正确理解了你的文件上下文。
打开你 MemoryLake 项目内置的 Playground。
直接询问你刚上传的复杂数据(例如,“总结上传的 Excel 模型中提到的财务风险”)。
测试检索、聊天能力和上下文理解。
这样做是在证明核心概念:你的项目知识现在正被主动复用,而不是每次新查询都要求你重新上传电子表格。
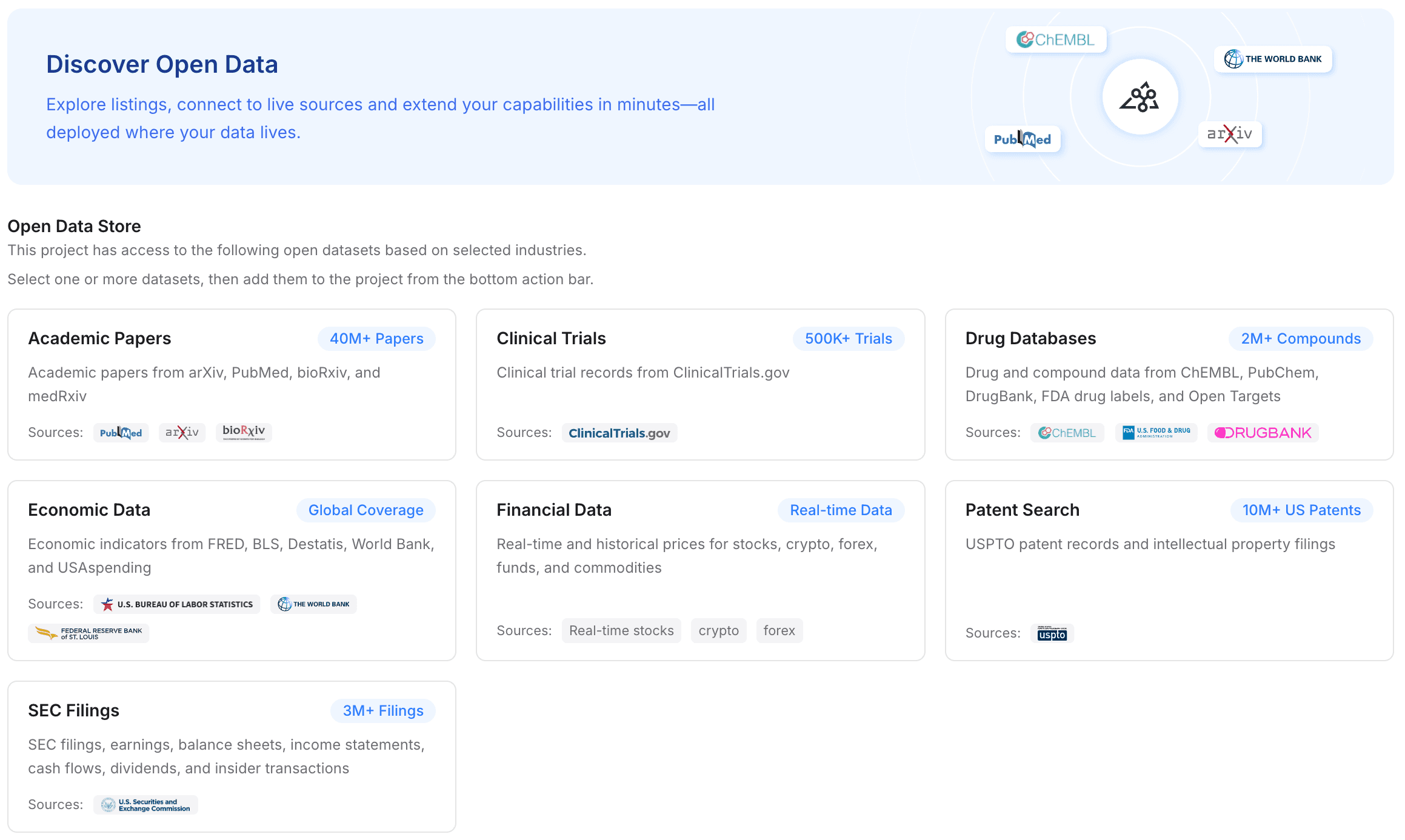
步骤 3:添加开放数据以丰富领域知识
一个强大的记忆层不只是存储你的私有文件;它还会借助更广泛的行业知识为其提供上下文。MemoryLake 允许你使用开放数据来增强你的项目记忆,而不必手动四处查找并上传公共数据集。
前往你项目中的数据集部分。
只需点击一次,即可将免费的高质量行业数据集直接加入你项目的记忆中。
可用的数据类型包括学术论文、临床试验、药物数据库、经济数据、金融数据、专利检索和 SEC 文件。
通过将你的私有 PDF/Excel 文件与这些开放数据集合并,你的 AI 助手会立即获得深度、专门的领域知识,而你无需亲自下载并上传任何公共 SEC 文件。
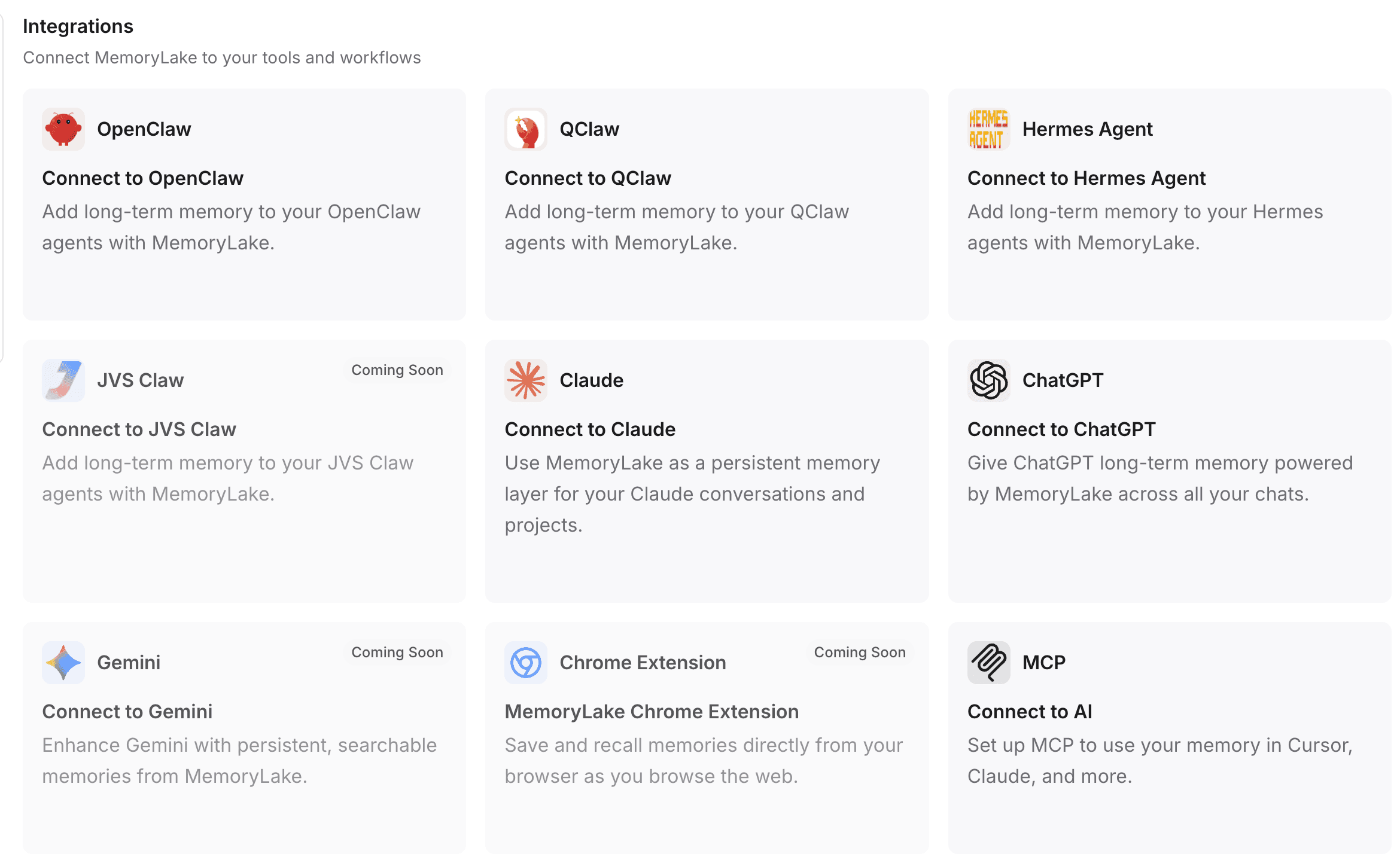
步骤 4:将 MemoryLake 连接到你的工具和工作流
记忆只有在能连接到你实际使用的工具时才有价值。MemoryLake 的设计目标就是直接接入你的日常 AI 工作流。
进入项目设置,选择或创建你自己的 API 密钥。
一条命令安装:对于许多集成,MemoryLake 支持一条命令安装流程,让你的插件立即运行起来。
自动配置(例如 OpenClaw):如果你正在使用像 OpenClaw 这样的平台,只需复制提供的设置说明,并直接粘贴到 OpenClaw 界面中。OpenClaw 会自动安装所需插件、配置你的项目设置,并无缝为你重启网关。
广泛兼容:你可以将这套持久记忆直接路由到诸如 ChatGPT、Claude、OpenClaw 和 Hermes Agent 等常用界面中。
程序化访问:对于开发者和 AI 智能体构建者,MemoryLake 可通过 MCP(模型上下文协议)和 API 深度集成到后端系统中,确保你的自定义机器人拥有持久、长期的记忆层。
从文件构建可复用 AI 记忆的最佳实践
按项目组织,而不仅仅按文件组织:不要把所有文档都扔进一个庞大的全局记忆池。保持上下文清晰区分(例如,“竞争对手分析”与“人力资源政策”),以确保高质量检索。
把记忆当作可复用上下文,而不只是云存储:你的目标不仅仅是备份 PDF;而是让它们可以被对话式使用。确保你上传的文件与你计划提出的问题相关。
谨慎将私有文件与领域数据集结合:使用开放数据(如 SEC 文件或学术论文)来补充你的内部 Excel 文件,让 AI 对主题有一个整体视角。
从一开始就考虑工作流集成:不要在孤岛中构建记忆。从第一天起,就要规划这套记忆将如何被呈现出来——无论是在 Claude、ChatGPT 还是自定义内部智能体中。
决定哪些应作为长期记忆,哪些只作为临时上下文:如果某个文档只是为了快速修正格式而需要,那么标准聊天上传就足够了。如果它是一篇你会在数月内反复引用的基础研究论文,那它就应该放在 MemoryLake 中。
应避免的常见错误
只依赖聊天历史:认为让 ChatGPT 线程保持开启六个月是一种可行的研究存储方式。(它最终会损坏、变慢或遗忘。)
反复上传同样的文件:每周一早上都拖放同一个 PDF,只会浪费 token、计算配额和你自己的时间。
把 RAG 与持久记忆混为一谈:以为写一个基础的 Python RAG 脚本就解决了持久、多智能体项目记忆的用户体验问题。
把电子表格和 PDF 当成纯文本块:Excel 文件有行、列和关系。标准聊天机器人在上传时往往会打乱这些数据。专用记忆层能够准确解析表格和结构化数据。
从不把记忆真正落地到工具中:搭建了一个很棒的数据库,却没有通过 API 或 MCP 将其连接到团队实际工作的工具上。
哪些人适合使用这套持久记忆工作流
这套持久记忆工作流非常适合以下人群:
研究人员和学者:他们需要在为期数月的项目中查询数十篇密集的学术论文。
金融分析师:他们需要 AI 记住复杂的 Excel 模型和历史 SEC 文件,而不会丢失上下文。
AI 智能体构建者:他们正在开发需要可靠、持久上下文的长期运行自主助手。
知识密集型团队:法律、医疗和咨询团队的日常工作围绕着大量相互关联的文件展开。
开发者:他们希望获得开箱即用的记忆基础设施,通过 API/MCP 连接,而不是从头构建复杂的 RAG 管道。
结论
如果你一直在对抗上下文窗口限制、token 限制和 AI 失忆,解决方案不是写更好的提示词,而是改变 AI 处理文件的方式。
指望 AI 仅通过基础聊天历史或一次性上传来记住复杂的 PDF、Excel 表格和深度研究材料,最终都会导致 AI 重新从头开始。要构建真正智能、长期运行的工作流,你需要实现一个持久记忆层。
通过使用 MemoryLake,你可以把临时文件上传转化为持久、可复用的项目记忆。无论你是用学术论文和 SEC 文件等开放数据集丰富内部文档,还是将这套记忆无缝连接到 Claude、ChatGPT 和 OpenClaw 等工具,MemoryLake 都能确保你的 AI 保留知识。停止每个会话都从头开始,开始构建一个能够长久保存记忆的 AI 工作流。
常见问题
如何让 AI 在不同会话之间记住 PDF 文件?
要让 AI 在不同会话之间记住 PDF,你必须摆脱标准聊天界面,改用像 MemoryLake 这样的持久记忆层。通过将 PDF 上传到专用项目中,文件会被处理并永久存储,使任何连接的 AI 工具都能在未来会话中检索其上下文,而无需重新上传。
AI 能在不重新上传的情况下记住 Excel 表格吗?
可以,但不能通过标准聊天历史实现。通过使用 AI 记忆基础设施,你的 Excel 文件会被解析并作为结构化项目记忆存储。这使 AI 能够在未来的任何时间点引用具体单元格、趋势和表格数据。
RAG 足够用于研究记忆工作流吗?
虽然 RAG(检索增强生成)提供了搜索文档的技术能力,但基础 RAG 往往不足以支撑无缝的研究工作流。用户需要一个完整的项目记忆层,将文档解析、对话上下文、开放数据集集成以及与实际聊天界面的便捷 API/MCP 连接结合起来。
存储 AI 研究记忆的最佳方式是什么?
最佳方式是使用一种持久记忆基础设施,按项目组织数据,支持多模态文件类型(PDF、Markdown、Excel),并允许你用开放数据集(如临床试验或学术论文)丰富私有研究。
MemoryLake 如何与 OpenClaw 或 Claude 等工具协同工作?
MemoryLake 作为这些工具的外部“脑”。通过配置 API 密钥,或直接将设置说明粘贴到 OpenClaw 等工具中(其可自动安装插件、配置插件并重启网关),你就为你的 LLM 提供了对持久项目记忆的直接访问。
可以通过 API 或 MCP 连接 MemoryLake 吗?
可以。MemoryLake 支持通过传统 API 和模型上下文协议(MCP)进行程序化集成,这使它对构建自定义 AI 智能体或企业应用的开发者来说非常灵活。
为什么 AI 总是对文档从头开始?
标准 AI 模型并不具备本地化长期记忆;它们依赖临时上下文窗口。一旦聊天结束或达到 token 上限,上传的文档就会从活动记忆中被清除,为新输入腾出空间。




