最适合需要借助人工智能来管理文档、电子表格以及各种重复性工作流程的团队的10款最佳AI记忆工具
Joy·

如果你的团队正在积极将 AI 集成到日常运营中,你很可能已经遇到过一个令人沮丧的瓶颈:AI 失忆症。标准 AI 聊天机器人和轻量级代理在单次对话中表现出色,但一旦你开启新的会话,它们就会忘记一切。对于团队而言,反复粘贴同样的大型电子表格、重新上传入职文档,以及一再输入标准操作流程(SOP),并不是可扩展的工作方式。
现代团队不仅需要能聊天的 AI;他们需要 AI 记忆基础设施。他们需要的是能够在多个会话和工具之间,持续记住复杂业务上下文、详细电子表格、长篇文档以及重复性工作流规则的系统。
在这份全面的买家指南中,我们将分析当今可用的 10 款最佳 AI 记忆工具和平台。我们将探讨它们的差异、最适合的使用场景,以及你的团队如何选择合适的记忆架构,把 AI 从无状态聊天机器人转变为高度具备上下文意识的团队成员。
如果你正在为复杂的团队工作流寻找最佳 AI 记忆工具,这里是简明摘要:
最适合企业文档与电子表格记忆:MemoryLake 脱颖而出,它是一个持久、由用户治理的 AI 记忆层,可跨模型和代理工作,专门用于处理复杂文件和工作流规则。
最适合开发者优先的代理记忆:Letta(前身为 MemGPT)和 Mem0 为构建需要分层或用户特定记忆的自主代理的开发者提供了出色的框架和 API。
最适合低延迟应用集成:Zep 为对话式 AI 应用提供极快、基于意图的记忆提取能力。
最适合基础数据基础设施:像 Pinecone 和 Weaviate 这样的向量数据库,仍然是从零构建自定义检索增强生成(RAG)管道的团队所采用的行业标准。
在评估这些工具时,团队应超越简单的聊天记录。应优先选择能够提供跨会话连续性、多模态支持(文档和电子表格)、治理(可追溯性与版本控制)以及跨不同 LLM 可移植性的平台。
工具 | 最适合 | 记忆能力 | 文档/表格适配性 | 价格 |
持久型 AI 记忆基础设施 | 高(跨模型/代理,支持版本感知) | 优秀 | ||
个性化用户/代理记忆 API | 中高(实体与会话跟踪) | 中等 | ||
低延迟对话记忆 | 高(快速提取、对话上下文) | 中等 | ||
操作系统级持久代理记忆 | 高(分层、无限上下文) | 良好 | ||
框架绑定的图形记忆 | 中等(有状态的 LangGraph 记忆) | 良好 | ||
上下文增强与数据摄取 | 高(高级 RAG 和索引) | 优秀 | ||
无服务器向量记忆基础设施 | 高(海量规模语义搜索) | 良好(需要自定义管道) | ||
AI 原生向量数据库记忆 | 高(混合搜索、多模态) | 良好(需要自定义管道) | ||
轻量级 AI 嵌入数据库 | 中等(快速本地/云端向量存储) | 中等 | ||
高性能向量记忆 | 高(高级过滤、可扩展) | 良好(需要自定义管道) |
MemoryLake 将自己定位为一个持久、可移植的 AI 记忆基础设施平台,专为需要 AI 系统记住复杂业务上下文的团队而设计。它不只是一个简单的聊天记录器,而是一个由用户拥有、受治理的记忆层,可在不同模型、代理、工具和会话之间无缝工作。
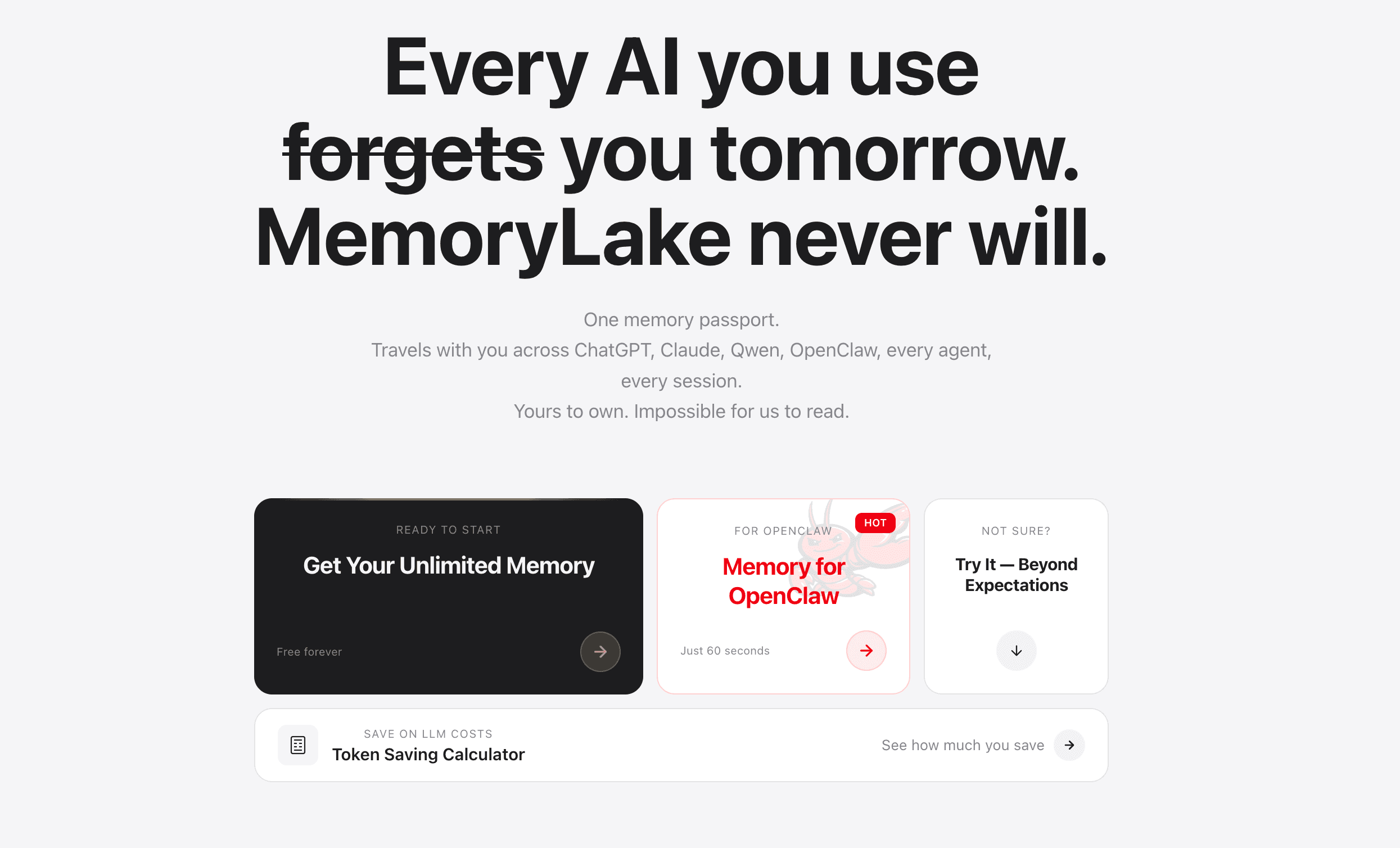
长期多模态记忆:专为摄取并持久记住复杂文档、详细电子表格和重复性工作流规则而构建,可跨无限会话使用。
跨代理与跨模型连续性:根据 MemoryLake 的公开资料,其记忆与任何单一 LLM 解耦,允许团队在切换 AI 模型的同时保留全部团队知识。
治理与来源追踪:提供深度可追溯性、支持版本感知的记忆思维以及清晰的数据来源,让团队准确知道 AI 的上下文知识来自哪里。
工作流规则强制执行:能够存储重复性的操作模式和业务逻辑,确保 AI 代理在每次交互中都自动遵循公司标准。
通用可移植性:作为独立基础设施层运行,并与你现有技术栈集成,而不是把你锁定在孤立生态中。
非常适合知识主要存在于文件、电子表格和 SOP 中,而不仅仅是聊天线程中的团队。
企业治理水平高;记忆可审计、可编辑并支持版本控制。
通过作为独立、可移植的记忆层,避免供应商锁定。
无需反复通过提示词塞入大型文档。
对于只需要基础对话式聊天机器人的个人用户或小团队来说,可能过于复杂。
作为基础设施平台,与轻量级即插即用的浏览器扩展相比,它需要更具战略性的实施过程。
这是一种相对较新的范式,需要团队改变对 AI 记忆“所有权”的思考方式。
免费开始。专业版每月 19 美元。高级版每月 199 美元。
Mem0 是一个面向开发者的记忆层,旨在构建个性化 AI 应用。它专注于提供统一 API,使 LLM 能够记住用户偏好、会话历史和实体关系,并跨不同应用保持一致。
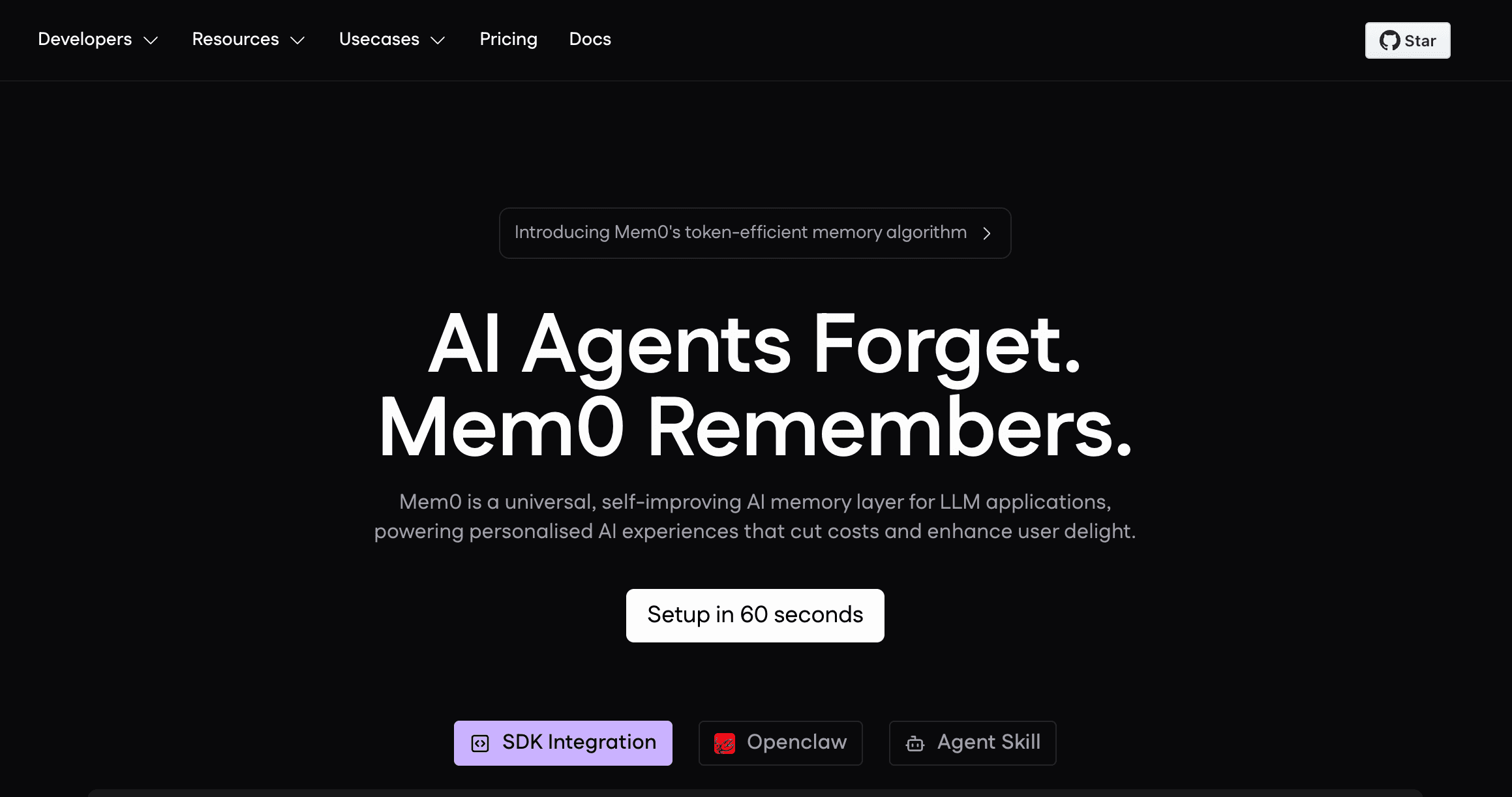
多层级记忆架构:支持用户、会话和 AI 代理记忆,让开发者可以控制 AI 记住什么。
自适应记忆管理:自动提取实体、更新变化中的事实,并遗忘过时信息。
简单 API 集成:专为开发者设计,可用最少代码轻松将记忆注入现有 LLM 应用。
向量与图搜索:将语义搜索与关系映射结合,以实现更准确的上下文回忆。
仪表盘管理:为开发者提供 UI,用于查看、编辑和监控正在创建的记忆。
对开发者非常友好,文档出色,API 易于使用。
非常适合需要跟踪单个用户偏好和个性化设置的应用。
开源社区支持确保快速更新和功能增加。
主要面向开发者构建应用,因此对寻求开箱即用解决方案的非技术业务团队来说可访问性较低。
虽然它能处理文档,但其核心优势更偏向对话上下文和用户偏好,而不是复杂的电子表格推理。
与企业级基础设施平台相比,其治理功能仍在成熟中。
入门版每月 19 美元。专业版每月 249 美元。
Zep 是一款低延迟、可扩展的记忆解决方案,专为对话式 AI 助手和代理量身打造。它专注于快速事实提取、对话历史管理和语义搜索,确保 AI 代理能够流畅交流而不会丢失对话主线。
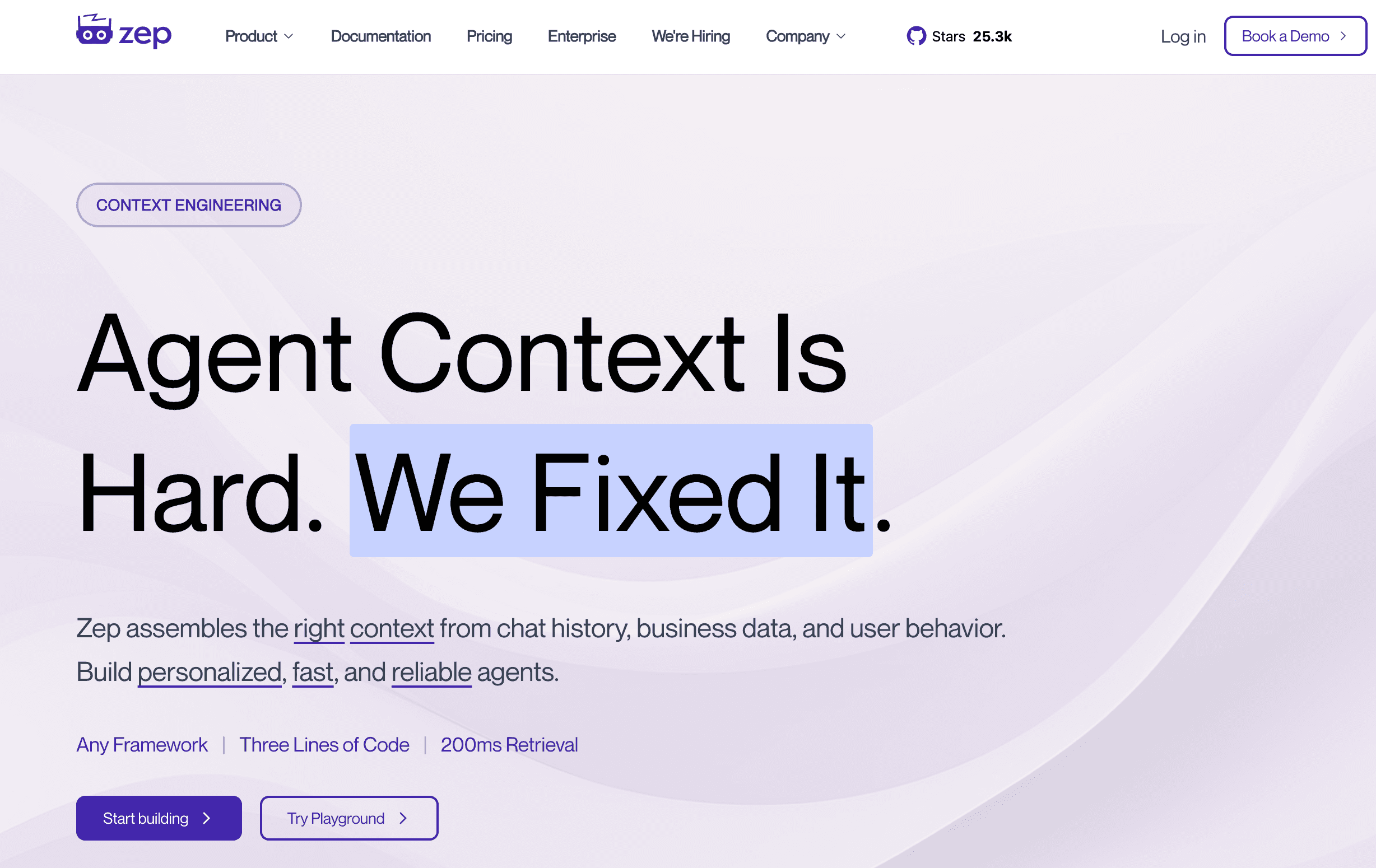
永久对话记忆:自动总结、嵌入并存储聊天历史,以高效管理长期上下文窗口。
事实与实体提取:主动从对话中提取核心事实、日期和实体,构建用户的结构化画像。
极低延迟:专为快速检索而设计,确保对话式 AI 应用在记忆回忆时不会出现卡顿。
对话分类:可自动对存储的记忆流中的意图和情绪进行标记与分类。
自托管与云选项:可在公司 VPC 内本地部署以保障隐私,也可作为托管云服务使用。
性能极快,非常适合实时客户支持机器人和对话代理。
开箱即用的事实提取让开发者无需编写复杂提示工程来总结聊天内容。
本地部署选项带来较强的隐私控制。
高度优化于聊天和对话;不太适合复杂文档或电子表格记忆治理。
并非为非技术团队提供的跨工具通用业务上下文平台。
与更广泛的记忆基础设施层相比,内置的工作流规则强制执行有限。
Flex 每月 125 美元。Flex Plus 每月 375 美元。
Letta 是一个受操作系统启发的框架,用于创建有状态的自主 AI 代理。它通过使用类似操作系统的记忆分层(主存 vs. 外部存储)来按需调入和调出信息,从而让 LLM 产生“无限上下文”的效果。
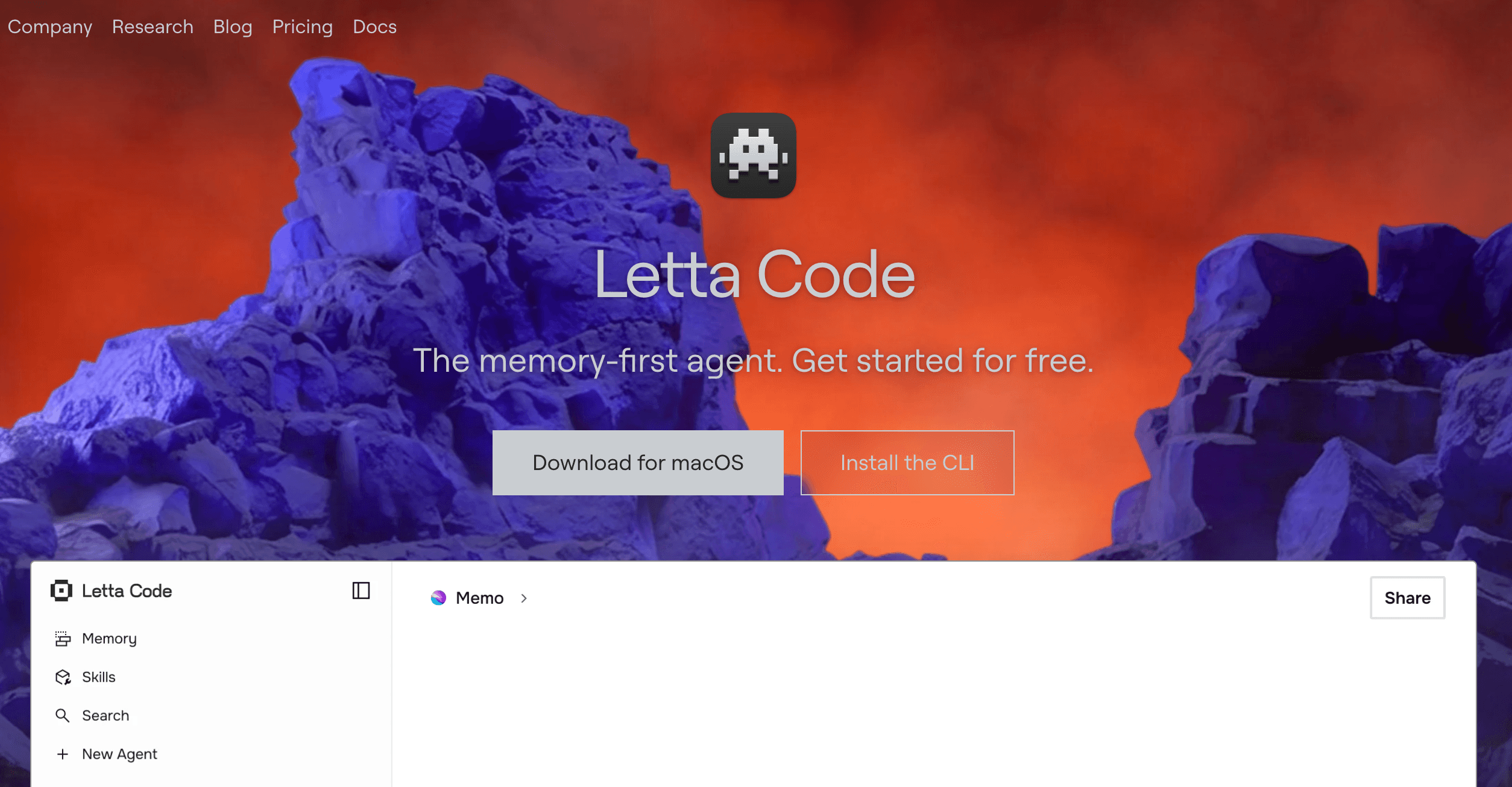
分层记忆架构:将记忆分为快速“工作记忆”(上下文内)和可扩展“档案记忆”(外部数据库)。
自编辑记忆:AI 代理可以自行决定何时将新信息写入记忆、更新现有事实或搜索档案。
持久代理状态:代理可在后台持续运行,根据外部事件或计划唤醒,同时保留完整历史上下文。
文档解析:可将外部数据源和文档摄取到档案记忆中,供代理之后查询。
支持本地 LLM:与本地托管模型配合良好,为敏感数据提供更强隐私保护。
面向自主代理记忆的突破性方法,让 AI 能动态管理自身状态。
非常适合长期运行任务和需要在数月后回忆过去交互的复杂代理。
强大的开源基础与高度活跃的开发者社区。
技术门槛很高,需要较强的开发经验来配置和编排。
由于 AI 自主管理其记忆,可追溯性和严格的人为治理有时更难落实。
它不是面向业务团队的即插即用 SaaS 应用,而是一个用于构建代理的框架。
专业版每月 20 美元。Max Lite 每月 100 美元。Max 每月 200 美元。
LangChain 是业内最广泛使用的 LLM 应用构建框架。随着 LangGraph 的推出,它已演进为支持复杂的有状态多代理工作流,为开发者提供强大的工具来管理 AI 执行图中的记忆和对话状态。
有状态图架构:LangGraph 允许开发者将代理工作流建模为图,并在每个节点自动持久化状态和记忆。
内置记忆模块:提供开箱即用的记忆类型,包括缓冲记忆、摘要记忆和实体记忆。
检查点功能:允许工作流暂停、检查并稍后恢复,本质上充当短期和中期记忆。
人在回路:状态管理使工作流能够暂停、请求人工批准,并在不丢失上下文的情况下继续。
庞大生态系统:可与几乎所有向量数据库、文档加载器和可用 LLM 无缝集成。
为希望构建高度定制化、有状态 AI 工作流的开发者提供无与伦比的灵活性。
状态管理(检查点)为复杂代理任务提供极佳的可追溯性。
庞大的集成范围使其能够轻松从现有公司数据库中提取记忆。
学习曲线陡峭;LangChain 和 LangGraph 的实现可能非常复杂且冗长。
记忆绑定于应用框架;它不是非技术团队可以直接交互的独立、可移植记忆层。
它本身不是专门的文档/电子表格记忆库(依赖第三方向量数据库集成)。
Plus 每席位每月 39 美元。
LlamaIndex 是一款顶级数据框架,专门用于将自定义数据源(文档、电子表格、API)连接到 LLM。虽然它通常被视为 RAG(检索增强生成)框架,但它也是企业应用中关键的记忆和上下文增强层。
高级数据摄取:擅长解析复杂文档、PDF,以及 SQL 数据库和 CSV 等结构化数据。
自定义索引:允许团队构建向量索引、树索引和关键词索引,以优化 AI 检索记忆的方式。
上下文增强:通过动态检索最相关的数据块并注入到 LLM 提示中,充当外部记忆库。
代理式工作流:支持能够对复杂数据集和多步骤查询进行推理的高级数据代理。
评估与追踪:提供用于衡量检索到的记忆准确性和相关性的工具。
对于需要高度依赖大量现有公司文档和电子表格的应用来说,属于顶级选择。
高度可定制的索引策略允许非常精确的记忆检索。
弥合了结构化企业数据与非结构化 LLM 推理之间的鸿沟。
它是一个数据框架,而不是一个独立、可移植的用户记忆应用。开发者必须构建实际应用。
与专门的用户记忆工具相比,它默认并不能像后者那样轻松原生管理“用户状态”或“跨会话用户偏好”。
需要管理外部向量数据库来实现持久化。
入门版每月 50 美元。专业版每月 500 美元。
Pinecone 是一个完全托管的无服务器向量数据库,作为成千上万 AI 应用的基础记忆基础设施。虽然它在对话意义上并不是一个独立的“记忆工具”,但它是让 AI 能够存储和检索海量语义记忆的后端引擎。

无服务器向量搜索:自动扩展,可在无需基础设施管理的情况下处理数十亿级向量嵌入。
实时索引更新:允许即时更新数据库,确保 AI 的记忆反映实时数据变化。
混合搜索:将稠密向量搜索(语义含义)与稀疏关键词搜索结合,以实现高度准确的文档检索。
元数据过滤:支持复杂查询(例如,“查找这个记忆,但只限于 HR 团队在 2024 年上传的文档中”)。
企业安全:SOC2 合规与企业级访问控制。
对于需要海量记忆存储的企业部署来说,极其可靠且可扩展。
无服务器架构消除了管理数据库基础设施的 DevOps 负担。
元数据过滤非常适合权限管理和团队知识分层。
它纯粹是数据库层;团队必须自行构建检索逻辑、解析和应用界面。
它不会原生理解“工作流”或“用户会话”——它只理解向量嵌入。
按基础设施使用量计费,需要仔细优化以避免成本膨胀。
入门版每月 50 美元。企业版每月 500 美元。
Weaviate 是一个开源、AI 原生的向量数据库,旨在充当智能应用的长期记忆。它通过与机器学习模型的无缝集成以及强大的混合搜索能力脱颖而出,因此深受企业 RAG 架构青睐。

内置向量化:可借助集成模块在摄取时自动将数据向量化,简化记忆创建管道。
高级混合搜索:将向量搜索与 BM25 关键词搜索融合,确保对特定文档和数据点的高准确检索。
多租户支持:架构上能够安全地处理成千上万不同用户或租户的独立记忆空间。
类图关系:支持数据对象之间的交叉引用,使 AI 记忆能够理解不同文档和概念之间的关系。
灵活部署:可本地运行、通过 Docker、在 Kubernetes 上运行,或使用完全托管云服务。
多租户能力使其非常适合为自身终端用户构建记忆功能的 B2B SaaS 公司。
内置向量化降低了构建记忆管道团队的入门门槛。
开源特性提供部署灵活性并避免供应商锁定。
与 Pinecone 一样,它是数据库,这意味着它缺乏让非技术团队直接与 AI 记忆交互的原生 UI/UX。
需要专门的开发资源来实现和维护记忆编排逻辑。
图形功能很有用,但正确建模需要较长的学习曲线。
Flex 每月 45 美元。Premium 每月 400 美元。
Chroma 是一个轻量级、开源的 AI 嵌入数据库,因其简单性和速度而深受开发者青睐。它作为 LLM 应用中易于部署的记忆存储,允许 AI 快速从文档和过去的交互中检索上下文。

开发者优先的简洁性:只需几行代码即可安装并运行,原生支持 Python 或 JavaScript。
内存与持久化存储:既可轻松在内存中运行用于测试,也可保存到磁盘以实现持久本地记忆。
自动嵌入:内置嵌入函数,开发者可直接传入原始文本,由 Chroma 处理向量化。
丰富的生态集成:可无缝接入 LlamaIndex、LangChain 及其他主要 AI 框架。
本地优先:针对本地运行高度优化,确保敏感团队文档的数据隐私。
可以说是用于快速原型开发 AI 记忆时最容易上手的向量数据库。
非常适合本地、隐私优先的部署场景,在这些场景中敏感团队数据不能离开内部网络。
完全免费且开源。
缺乏更大型向量数据库所具备的高级企业多租户和分布式扩展能力。
不是托管基础设施平台;用于生产环境时,团队必须自行管理部署。
它严格来说只是一个嵌入存储;不会原生处理代理状态、工作流规则或跨工具可移植性。
入门版免费,团队版每月 250 美元,企业定价为定制。
Qdrant 是一个用 Rust 构建的高性能向量搜索引擎,旨在作为 AI 应用快速且可扩展的记忆后端。它尤其适合需要在语义搜索之外还进行大量元数据过滤的应用。

高速向量搜索:采用 Rust 编写,在记忆检索方面提供卓越性能和资源效率。
高级负载过滤:允许团队为记忆附加复杂的 JSON 负载,并基于严格业务逻辑过滤搜索。
量化支持:使用先进压缩技术,以低成本存储海量向量记忆而不损失准确性。
分布式架构:为企业环境中的高可用性和横向扩展而构建。
多语言 SDK:提供 Python、Rust、Go、TypeScript 等官方客户端。
由于基于 Rust 的架构,性能极高且资源消耗低。
对于需要将严格关键词规则与语义记忆结合的团队来说,负载过滤非常有价值。
由于内置量化,在大规模场景下非常具备成本效益。
需要强大的工程团队才能将其作为自定义 RAG/记忆管道的一部分来实现。
与 Mem0 这类目标明确的记忆工具相比,原生“开箱即用”的用户管理较少。
没有面向业务用户去治理或追踪 AI 记忆逻辑的原生 UI。
Qdrant Cloud 提供托管服务,原型开发有永久免费层,之后按使用量计费,并根据所需集群资源和存储进行扩展。也提供定制企业定价。
每个团队的 AI 成熟度和使用场景都不同。为了避免拿苹果和橙子比较,以下是根据你的具体购买场景对这些工具的分类方式:
如果你的目标是构建一个集中式、受治理且可移植的记忆层,服务整个组织——尤其是复杂文档和重复性工作流——那么非常推荐 MemoryLake。它通过提供一个非技术运营团队也能真正治理的基础设施平台,超越了原始数据库的范畴。
如果你是构建 AI 应用的开发者,只需要一个能记住用户偏好的 API,那么 Mem0 提供了非常出色的开箱即用解决方案。如果你需要本地原型开发,Chroma 是最快搭建起来的向量存储。
如果你的数据科学团队正在使用海量企业数据湖从零构建自定义上下文引擎,那么 LlamaIndex(用于数据摄取/编排)与 Pinecone 或 Weaviate(用于向量存储)的组合就是行业标准。
如果你正在构建需要在后台运行、自行编辑记忆并维持复杂多步骤状态的自主 AI 代理,那么 Letta(MemGPT)和 LangChain(LangGraph)之类的框架是目前最稳健的工具。
为了做出明智的采购决策,团队必须理解 AI 市场中的技术区别。很多时候,供应商会混淆这三个概念,导致实施失败。
这就是 ChatGPT 或 Claude 的默认行为。它只是把你之前的消息追加到上下文窗口中,直到达到 token 限制。一旦你开启新的聊天,AI 就会忘记一切。它是无状态、不可移植的,并且不足以支撑团队级文档记忆。
像 Pinecone、Weaviate 和 Qdrant 这样的工具都是向量数据库。它们把数据存储为数学嵌入,以便 AI 进行语义搜索。然而,数据库只是存储。它并不会原生知道如何管理“用户会话”“跨代理可移植性”或“工作流执行”。你必须雇佣开发者在其之上构建记忆逻辑。
像 MemoryLake 这样的工具充当数据库之上的综合层。它们提供真正的基础设施平台,处理电子表格摄取、文档版本管理、会话连续性维护,并提供治理 UI。它们弥合了原始数据存储与终端用户 AI 体验之间的差距。
把同样的说明、SOP 和电子表格反复复制粘贴到一个空白 AI 提示窗口中的时代正在走向终结。随着 AI 从一个简单的头脑风暴助手演变为自主团队成员,持久记忆不再是奢侈品;它是基础设施层面的基本要求。
在评估市场时,团队必须认识到开发者导向数据库、框架绑定的状态管理器以及真正的企业记忆平台之间的差异。如果你的团队有开发者在构建自定义 RAG 管道,那么投资 Pinecone、LlamaIndex 或 Letta 都会带来巨大价值。
然而,如果你的团队更关注业务成果,或者你的运营知识主要存在于文件、电子表格和复杂工作流规则中,那么你需要一种能够弥合原始数据与 AI 连续性之间差距的解决方案。
对于已经超越简单聊天历史和轻量级 API 的团队,MemoryLake 非常值得评估。它作为一个持久、可移植的记忆层运行,使你的 AI 能够在不同会话、模型和代理之间保留关键团队上下文。它确保当你的业务逻辑发生变化时,AI 的记忆也随之更新,并辅以企业工作流所要求的治理与可追溯性。
不要再在每次打开新标签页时重新训练你的 AI。投资可扩展的 AI 记忆基础设施,让你的 AI 终于学会你的团队究竟是如何工作的。
AI 记忆工具是软件或基础设施,它让人工智能模型能够跨多个会话和交互,持续存储、回忆和更新信息——例如用户偏好、业务上下文或操作规则——从而克服标准 LLM 与生俱来的失忆问题。
聊天历史只是把过去的消息重新提供给当前提示,直到模型达到 token 限制。AI 记忆工具会动态提取事实、将其外部存储,并有选择地检索最相关的信息,从而实现跨数月甚至数年的无限上下文保留。
可以,但这取决于工具。轻量级聊天记忆工具难以处理结构化数据。像 MemoryLake 这样的高级基础设施平台,或像 LlamaIndex 这样的框架,专门为摄取、解析并持久回忆复杂电子表格和多页文档中的数据而设计。
向量数据库(如 Pinecone)是嵌入数据的后端存储。AI 记忆工具或平台(如 MemoryLake 或 Mem0)则包含编排逻辑、用户管理、跨会话连续性以及治理功能,这些都是让存储数据真正作为 AI 代理“记忆”发挥作用所必需的。
对于构建应用的开发团队,Mem0 或 Letta 都很出色。对于需要 AI 持久记住公司 SOP、文档和工作流、且不想进行自定义编码的业务和运营团队来说,像 MemoryLake 这样的企业平台是更优选择。
企业必须优先考虑治理(知道 AI 为什么记住了某件事)、可追溯性、安全性、多模态支持(文档/电子表格)以及可移植性(在不丢失已积累团队记忆的前提下切换 AI 模型的能力)。
通常不够。轻量级 API 非常适合记住简单的用户偏好(例如“我更喜欢 Python 而不是 JavaScript”)。然而,处理严格合规规则、重复性操作模式和详细电子表格的工作流繁重团队,需要一个更强大的基础设施层,以支持复杂的规则执行和数据版本管理。
MemoryLake 的定位不仅仅是一个工具,而是一个持久、由用户治理的基础设施层。它强调跨模型可移植性,这意味着你团队的记忆不会被锁定在某一家 AI 供应商上。该公司强调其能够原生处理复杂的多模态输入——例如业务文档和重复性工作流——同时为团队提供审计和安全管理该记忆所需的治理能力。