医疗领域大模型评估:文献综述与框架

随着生成式大语言模型在医疗领域的应用不断扩展,如何科学、统一地评估它们的表现,成为亟待解决的问题。尤其是在处理医疗问答、临床决策支持等场景时,AI生成内容的安全性、可靠性与准确性至关重要。
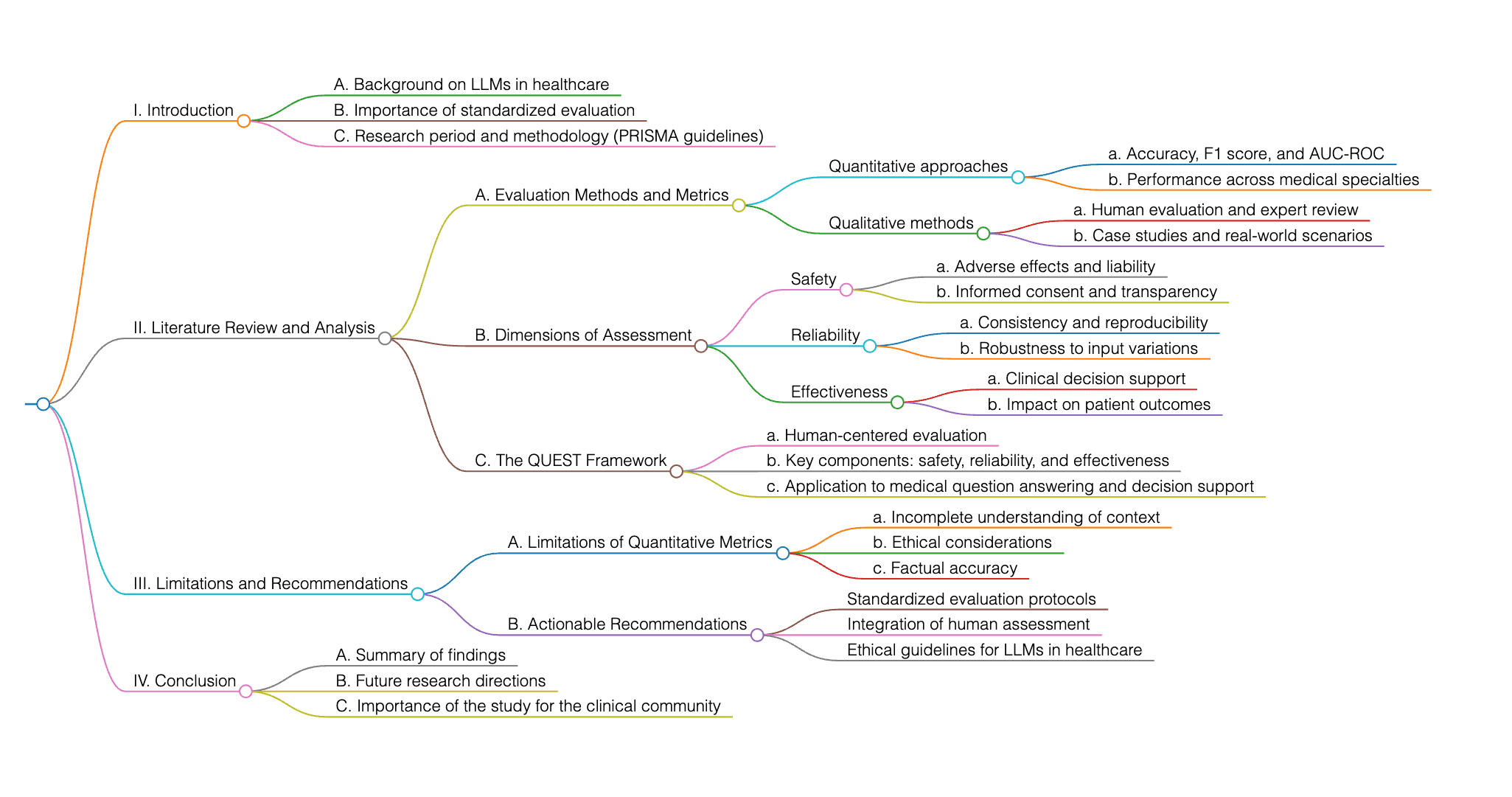
研究团队基于 PRISMA 指南,对 2018 至 2024 年间的相关文献进行了系统回顾,涵盖多个医学专业的评估方法、指标与维度。结果发现,目前的评估方式较为分散,缺乏统一标准。
为此,作者提出了 QUEST 框架,强调在人机协作评估中,人类专家的参与不可或缺。相比单纯依赖量化指标,人类评估更能把握医学内容的事实准确性与伦理合规性,也更有助于发现模型在临床应用中的潜在风险。
这项研究不仅为医疗领域的大模型评估提供了标准化参考,还指出了当前研究中的不足,并为临床与科研社区提出了可操作的改进建议,旨在提升 LLM 在医疗应用中的可信度与安全性。
思维导图
TL;DR
研究要解决的问题
当前评估医疗领域大语言模型(LLM)时,普遍依赖定量指标(如准确率、F1 值),但这些指标往往无法全面验证生成内容的真实性,也无法捕捉临床实践所需的细致理解。本文关注如何引入人类质性评估,确保 LLM 输出在可靠性、事实准确性、安全性和伦理合规性方面达到医疗标准。这并非全新问题,但作者通过系统综述与框架设计,推动了评估方法的标准化。
科学假设
作者验证的假设是:LLM 的表现与基准相比,其差异在统计学上具有显著性(通常用 P 值检验)。
创新点与优势
提出 QUEST 人类评估框架,结合跨专业文献回顾与评估准则,填补了评估规模、样本量和方法上的不足。与传统自动化指标相比,该框架:
更能捕捉临床场景中的细微差别
关注安全性与伦理风险
提供可在不同医疗专科落地的标准化流程
相关研究与代表人物
已有研究探索 ChatGPT 等模型在诊断建议、临床判断等任务中的表现,并用 T 检验、卡方检验、McNemar 检验等方法与医生结果对比。
代表性研究者包括:
Sinha R.K., Roy A.D., Kumar N., Mondal H., Sinha R.:探讨 ChatGPT 在病理学高阶问题求解中的应用
Ayers 等人:比较 ChatGPT 与医生在 Reddit “Ask Doctors” 论坛上的回答质量与相关性
关键解决思路
构建符合医疗价值观的人类评估框架,让 AI 评估不仅是数字游戏,而是与临床实践、伦理要求和患者安全高度对齐。
实验是如何设计的?
本研究的实验设计,主要是将 ChatGPT 在 Reddit “Ask Doctors” 论坛中对提问的回答,与医生提供的答案进行比较。研究团队采用卡方检验(Chi-square test)来分析两者在建议质量与相关性上的差异。此外,研究还考虑了在受控环境与真实场景中分别测试大语言模型(LLM),以全面评估其性能。
用于量化评估的数据集与代码开源情况
医疗领域的量化评估中,常用的数据集会配合多种性能指标,包括:准确率(Accuracy)、F-1 值以及ROC 曲线下面积(AUCROC)。这些指标在衡量 LLM 在不同医学任务中的表现时应用广泛,但它们往往难以捕捉临床实践中所需的细腻理解。
至于代码开源情况,文中指出目前主流研究中使用的模型并非全部开源,例如 Meta 的 Llama 等开源模型,并未位列本研究回顾中使用频率最高的模型之列,因此相关实验代码并未开放。
实验与结果是否有力支撑科学假设?
医疗领域关于 LLM 的研究包含多种实验设计与结果呈现。例如,Tang 等人采用 T 检验(T-test)对比 ChatGPT 与医疗从业者整理的医学证据的正确性;Ayers 等人则在 Reddit “Ask Doctors” 数据上,利用卡方检验分析 ChatGPT 与医生回答在质量和相关性上的差异。
这些实验旨在评估 LLM 在医疗任务中的性能,并验证不同研究提出的科学假设——有的关注统计显著性差异,有的比较模型与人类专家的质量与相关性,还有的考察模型在科研或临床应用中的可靠性与实用性。整体来看,这些实验为假设验证提供了实证支持,但针对特定假设的评估力度与广度仍依赖于具体研究设计与数据规模。
论文的主要贡献
本论文的贡献包括:
研究构思与设计:由 T.Y.C.T. 与 S.S. 主导研究构思、设计、组织研究工作,并负责结果分析与论文撰写、审阅和修订。
结果分析与论文修订:S.K., A.V.S., K.P., K.R.M., H.O., X.W. 参与结果分析、撰写、审阅与修订工作。
论文撰写与完善:S.V., S.F., P.M., G.C., C.S., Y.P. 参与论文撰写、审阅与修订。
可深入拓展的研究方向
未来的深入研究可以聚焦于:
在不同医学专科中,系统探索人类评估的多维度指标
总结与分享人类评估设计与监测的最佳实践
针对评估中的局限性提出改进方法
开展涵盖多种医学任务与专业的案例研究
阅读更多
以上摘要由 Powerdrill 自动生成。 点击链接可查看摘要页面及其他推荐论文。