Powerdrill AIを使ってt検定を行う方法 | Powerdrill

t検定のような統計的検定は、データセットを比較し、有意な差を特定するのに役立つ、学術および研究分野において不可欠なツールです。その重要性にもかかわらず、統計学やプログラミングの知識がない人にとって、t検定を手動で行ったり、複雑なソフトウェアを使用したりすることは、困難な場合があります。
先進的なデータ分析ツールであるPowerdrill AIは、t検定の実施方法を革新します。ユーザーが自然言語でソフトウェアと対話できるようにすることで、Powerdrillは専門知識の必要性を排除します。データセットをアップロードし、平易な言葉または専門的な言葉で質問するだけで、残りはPowerdrillが処理します。
本ガイドでは、t検定を分かりやすく解説し、その実用的な応用を探り、Powerdrill AIを使ってt検定を簡単に行う方法をステップバイステップで説明します。
t検定とは?
t検定の定義と本質
t検定は、1つ以上のグループの平均を比較し、観測された差が統計的に有意であるかどうかを評価するために使用されるパラメトリックな統計的検定です。これは、標本サイズと変動性を考慮した場合に、グループ間の平均の差がランダムな偶然によって期待される以上のものかどうかを判断します。
t分布の紹介
ウィリアム・シーリー・ゴセットによって導入されたt分布は、t検定で使用される確率分布です。これは正規分布に似ていますが、裾が厚く、小さい標本サイズからの追加の不確実性に対応します。標本サイズが増加するにつれて、t分布は正規分布に収束します。
t検定と他の検定方法との比較
マン・ホイットニーのU検定やウィルコクソンの符号順位検定のようなノンパラメトリック手法とは異なり、t検定はデータの正規性を仮定しており、これらの仮定が満たされる場合に一般的に高い検出力を持つとされています。ANOVAのようなより複雑な手法よりも単純であるため、2グループ間の比較にはよく用いられるツールです。
t検定の種類
1. 1標本t検定
1標本t検定は、ある標本の平均が既知の、または仮定された母集団の平均と有意に異なるかどうかを評価します。
例とシナリオ: あるクラスの平均テストスコアが全国平均と異なるかどうかを評価する場合。
仮定: 標本が抽出される母集団は正規分布に従い、データは独立している必要があります。
2. 独立2標本t検定
独立2標本t検定は、2つの異なるグループの平均を比較し、それらが有意に異なるかどうかを判断します。
適用シナリオ: 男女の身長の比較、または治療群とプラセボ群の間で薬剤の有効性をテストする場合。
独立性の概念: 独立性とは、一方のグループの測定値が他方のグループに影響を与えないことを意味します。
等分散性: レベンス検定などの方法を用いて検証されるこの仮定は、グループ内のばらつきがほぼ等しいことを保証します。
3. 対応のあるt検定
対応のあるt検定は、同じグループからの平均を、2つの異なる時点または2つの異なる条件下で比較します。
独立2標本t検定との違い: 対応のあるt検定は、同じグループ内の測定値間の相関関係を考慮します。
適用シナリオ: ダイエット前後の体重など、実験前後の測定。
対応の根拠と方法: 対応付けは、測定値が関連していることを保証し、変動性を減らし、検定の検出力を高めます。
t検定の適用条件
1. データの正規性
正規分布の重要性: t検定は、有効な結果を保証するために正規性の仮定に依拠します。
検定方法:
統計的検定: シャピロ-ウィルク検定またはコルモゴロフ-スミルノフ検定。
2. 標本の独立性
独立性の重要性: 独立性の違反は、偏った結果につながる可能性があります。
独立性の確保: 適切なランダム化と重複するグループの回避は、独立性を維持するのに役立ちます。
3. 等分散性(独立2標本t検定の場合)
結果への影響: 分散の不均一性は、検定の妥当性を歪める可能性があります。
検定方法: レベンス検定またはバートレット検定。
t検定の計算原理
1. 1標本t検定
1標本t検定の計算式は以下の通りです。
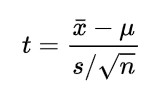
ここで:
xˉ: 標本平均
μ: 母集団平均
s: 標本標準偏差
n: 標本サイズ
2. 独立2標本t検定
等分散性の場合:
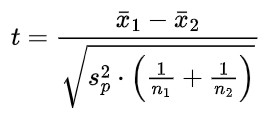
ここで
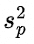
はプールされた分散です。
不等分散性の場合: 不均一な分散を調整するために補正式が適用されます。
3. 対応のあるt検定
対応のあるt検定では、以下の手順で行います。
対応する観測値間の差を計算します。
これらの差に1標本t検定の公式を適用します。
t検定の仮説検定プロセス
仮説の提唱
帰無仮説 (H0): 差がないと仮定します(例:μ1=μ2)。
対立仮説 (H1): 有意な差があると仮定します(例:μ1≠μ2)。
有意水準の選択
一般的な水準:0.05または0.01。
選択は、研究の厳密さと第一種過誤の結果によって異なります。
t値と自由度の計算
自由度 (df):
1標本の場合: df=n−1。
独立2標本の場合: 等分散ならdf=n1+n2−2。
臨界値の探索またはp値の計算
臨界値にはt分布表を使用するか、p値にはソフトウェアを使用します。
意思決定
t値と臨界値を比較するか、p値と有意水準を比較して、帰無仮説を採択または棄却します。
Powerdrill AI: あなたのt検定計算機
Powerdrill AIは、複雑な統計分析をシームレスな体験へと変革します。t検定がどのように簡素化されるかをご覧ください。
使いやすさ: データセットをアップロードし、質問するだけです。コーディングは不要です。
多機能な分析: 1標本、独立2標本、および対応のあるt検定を実行できます。
透明性: すべての分析において、Pythonコードとデータソースを確認できます。
効率性: 解釈と視覚化を伴う結果を数秒以内に取得できます。
Powerdrillでt検定を行う方法
ステップ1: データアップロード

学生の成績と性別を含むデータセットをPowerdrillにアップロードし、その構造と内容を理解するために基本的な情報と最初の数行を表示します。
ステップ2: データクレンジング
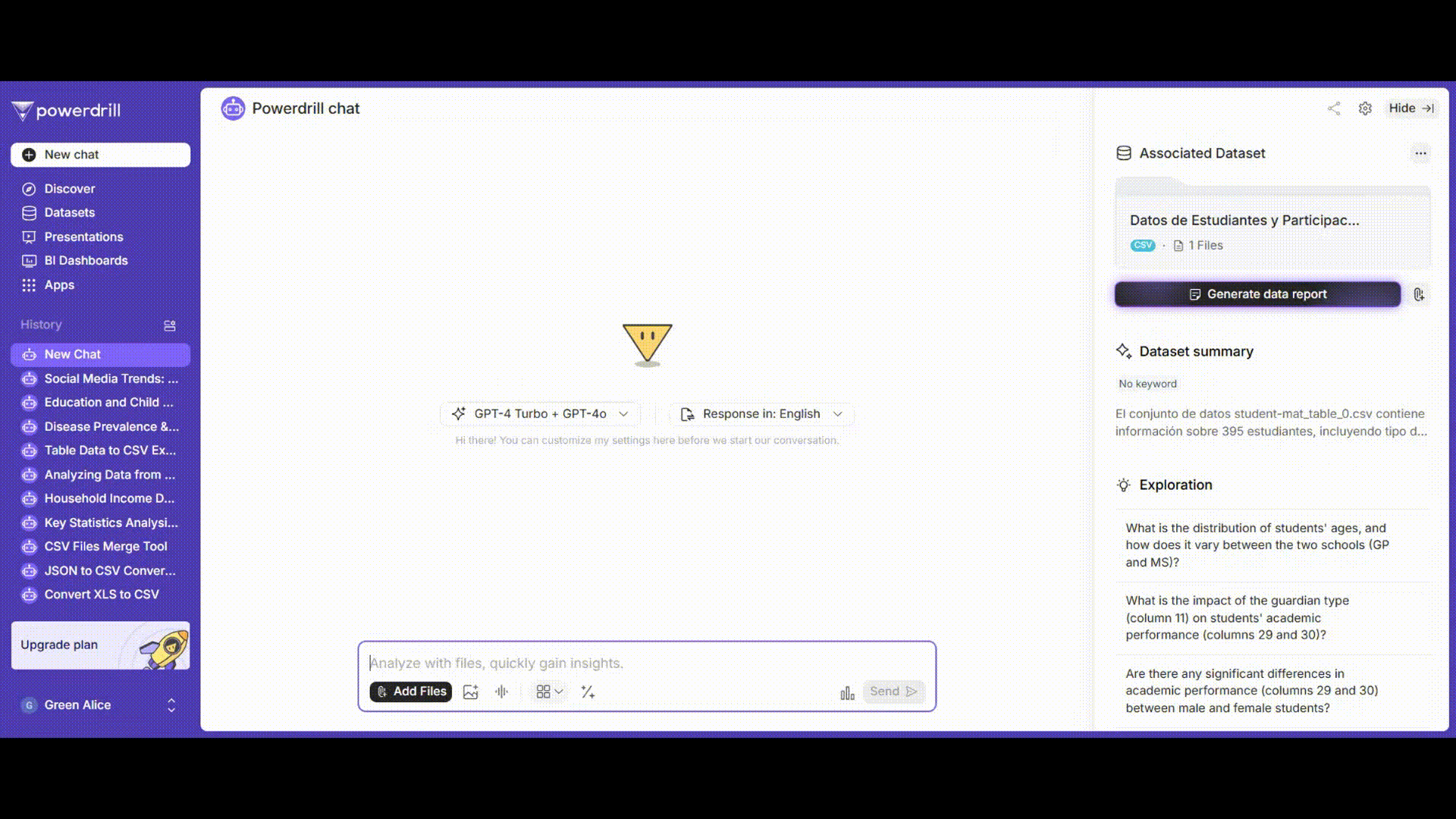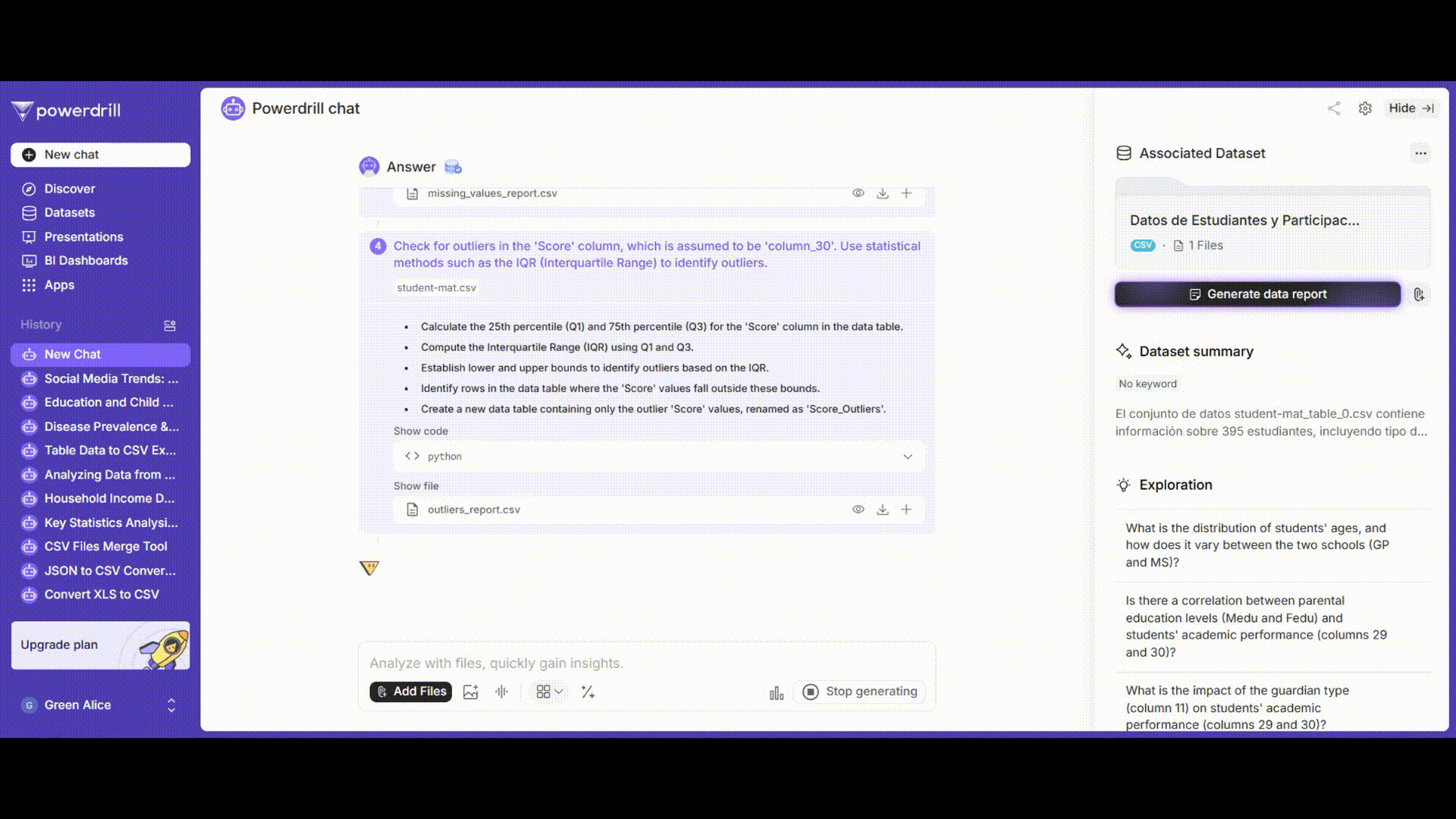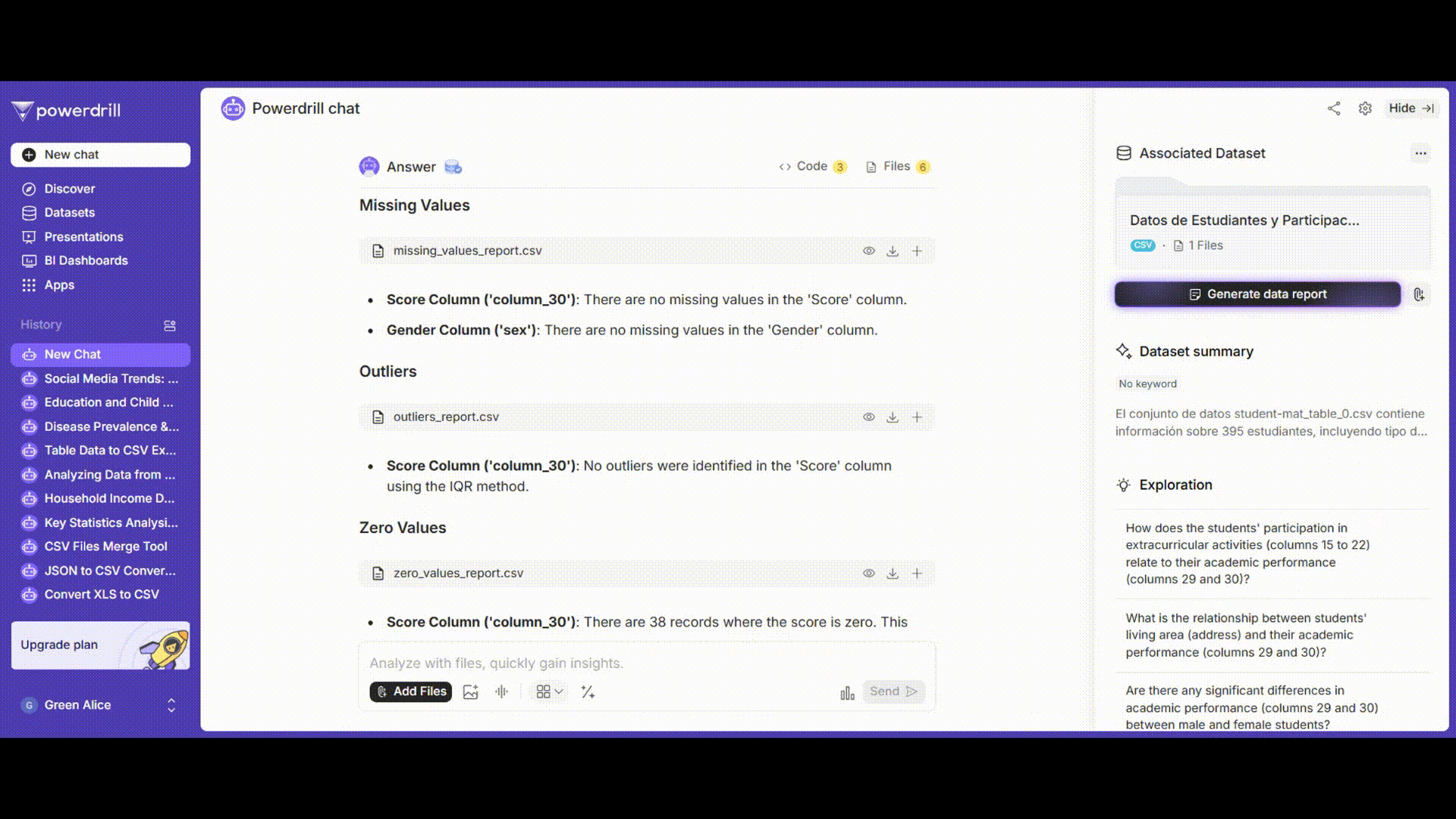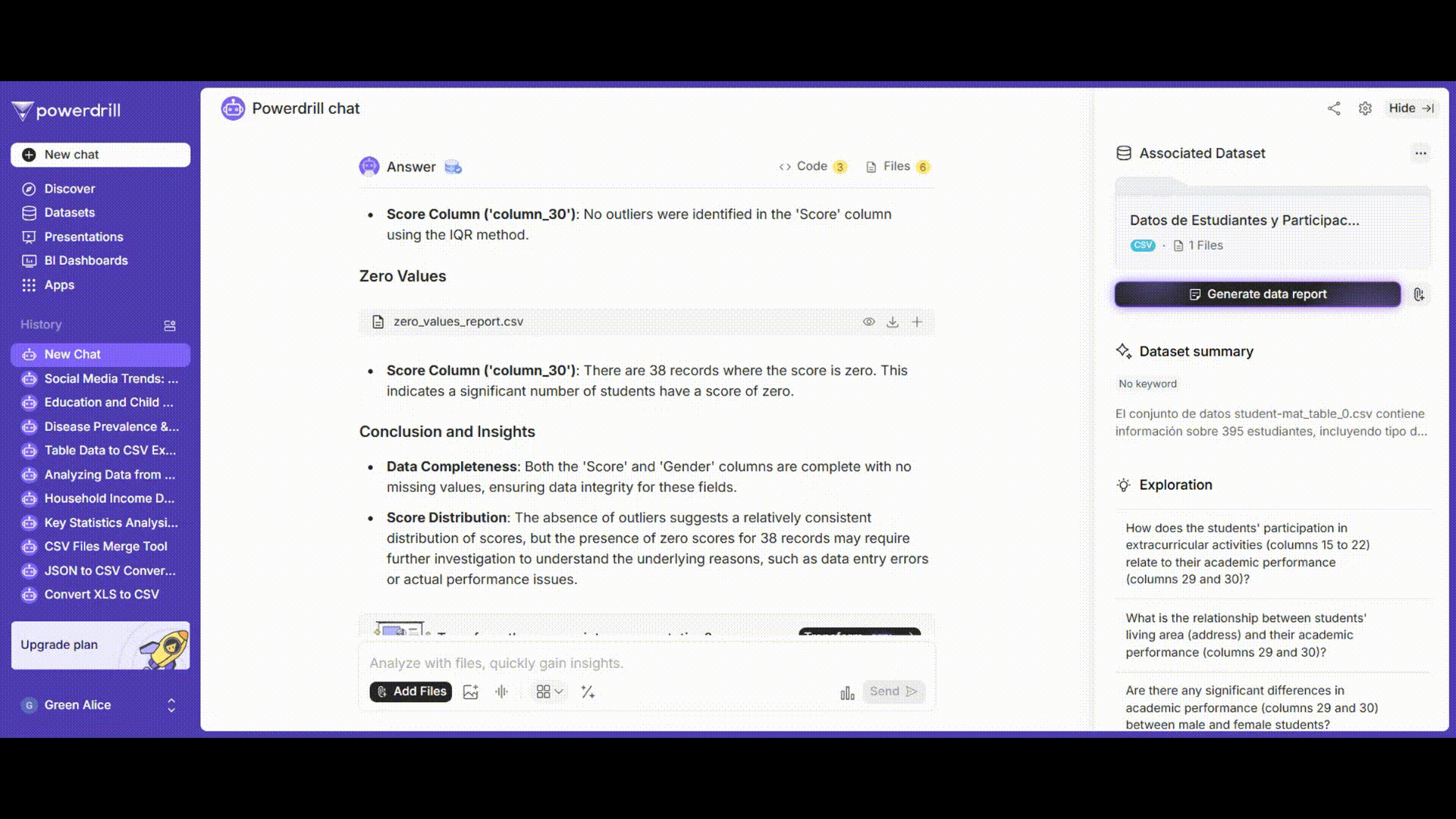
欠損値の処理
成績と性別の列に欠損値があるかどうかを確認し、削除や補完など、状況に応じて処理します。
プロンプト例: 「'grades'列に欠損値がある場合、この列の平均値で埋めてください。'gender'列に欠損値がある場合、対応する行を削除してください。」
外れ値の処理
成績列の外れ値を検出し、ビジネスロジックに基づいて削除、修正、または保持するかを決定します。
プロンプト例: 「ボックスプロット法を使用して'grades'列の外れ値を検出してください。」
データ型の確認と変換
'grades'列が数値型、'gender'列がカテゴリ型であることを確認します。
プロンプト例: 「'grades'列を数値型に、'gender'列をカテゴリ型に変換してください。」
ステップ3: 探索的データ分析
記述統計
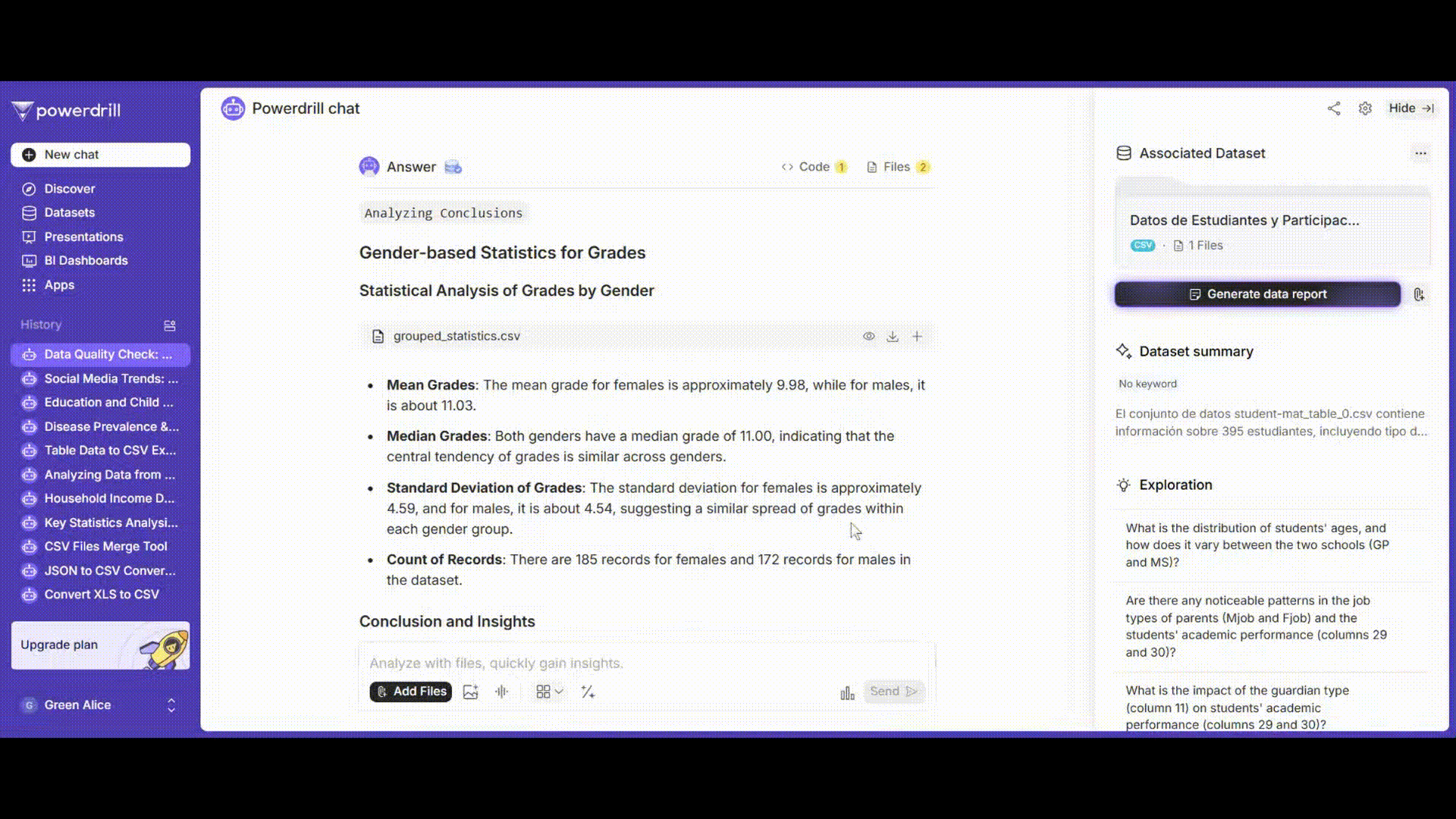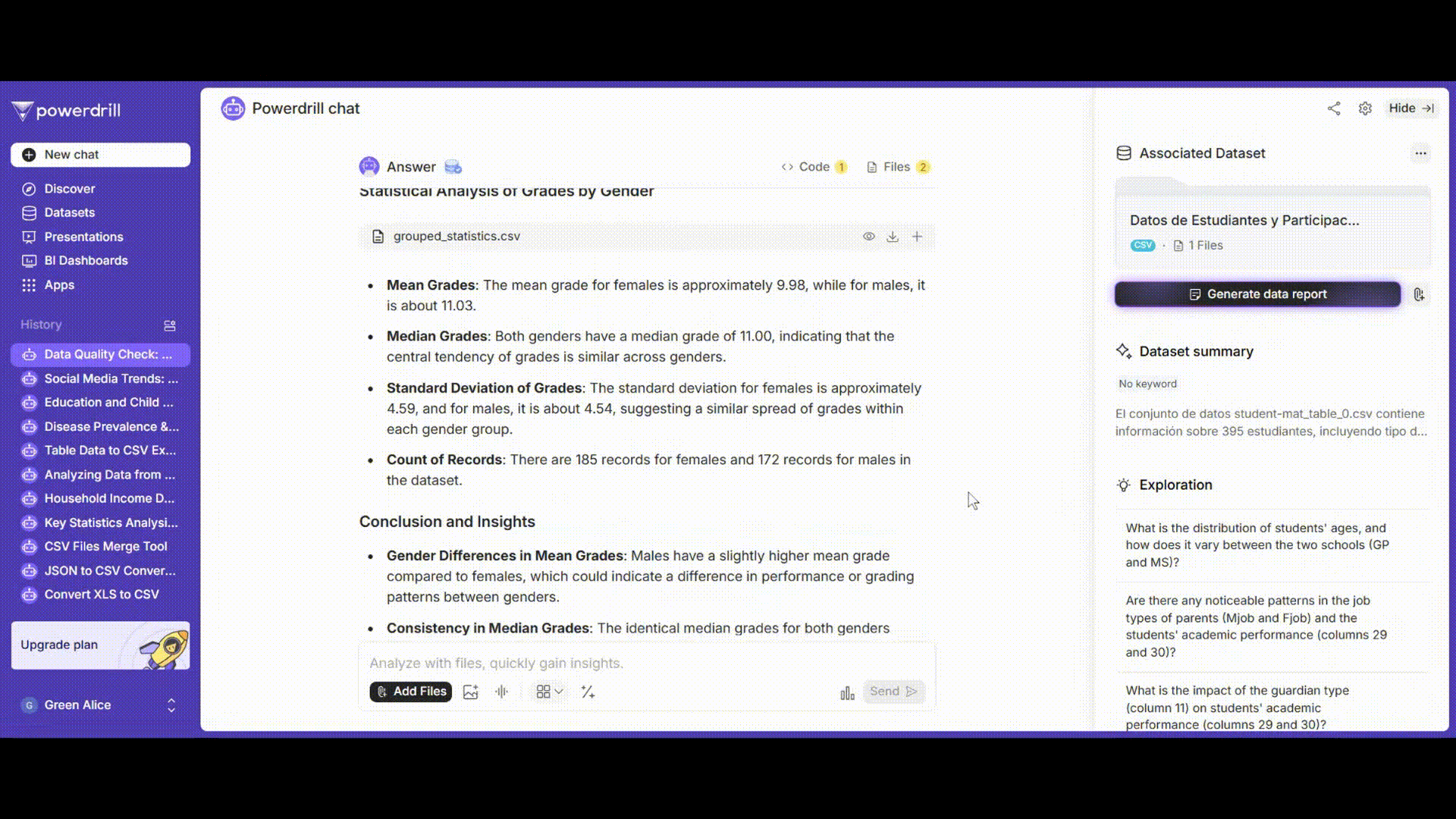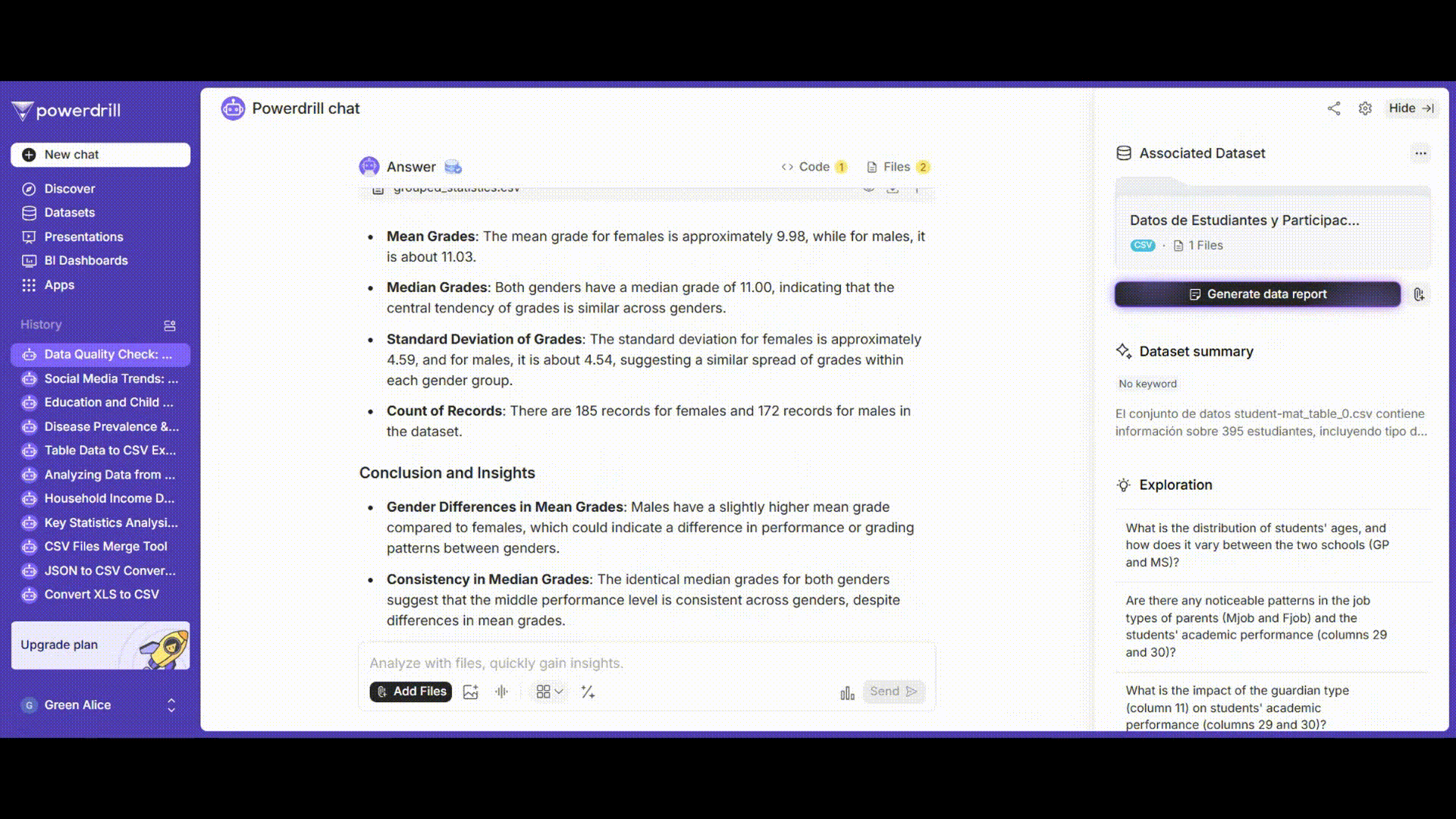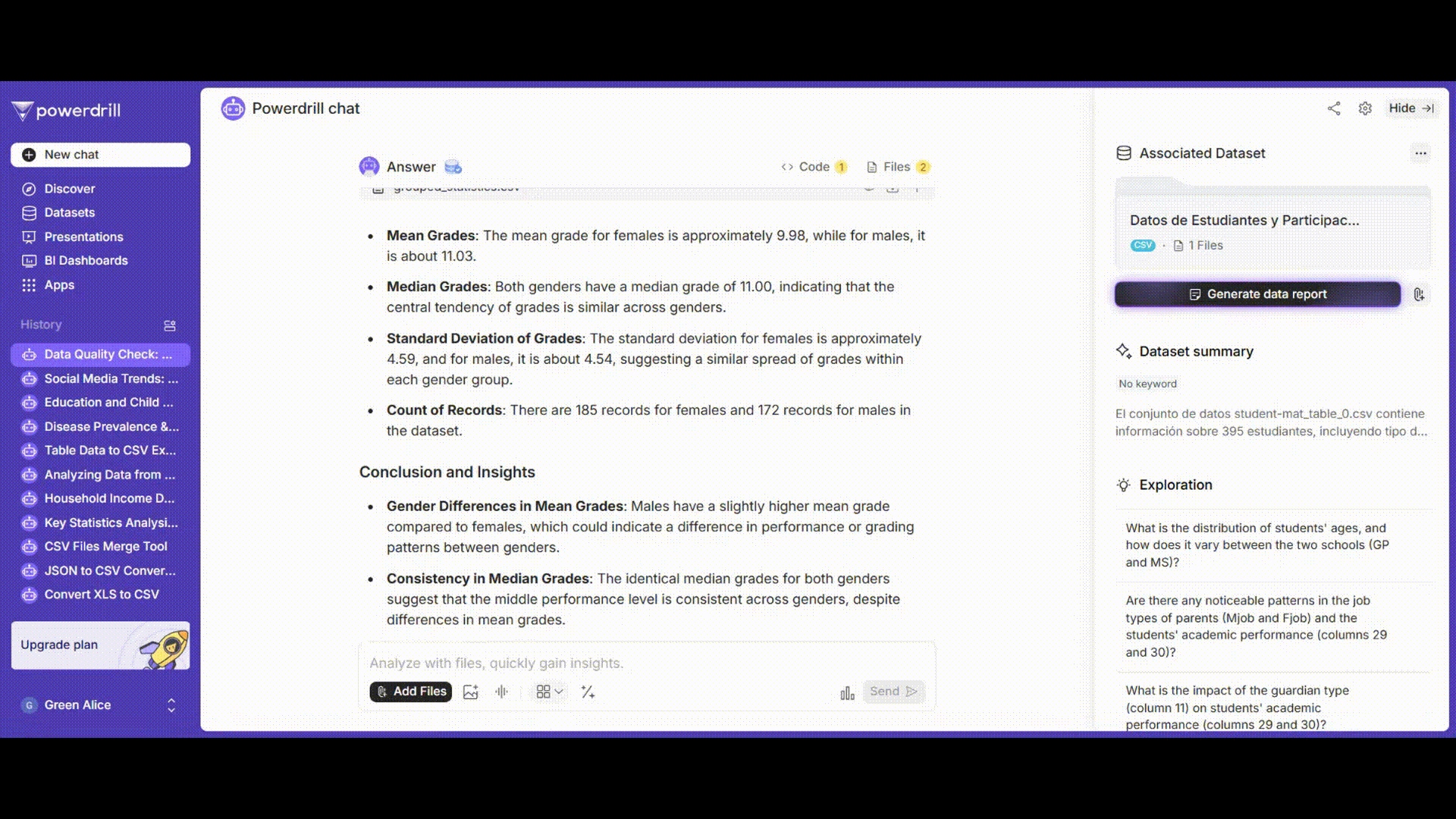
成績を性別でグループ化し、平均、中央値、標準偏差などの記述統計量を計算します。
プロンプト例: 「'grades'列を'gender'列でグループ化し、各グループの平均、中央値、標準偏差、および件数を計算してください。」
可視化
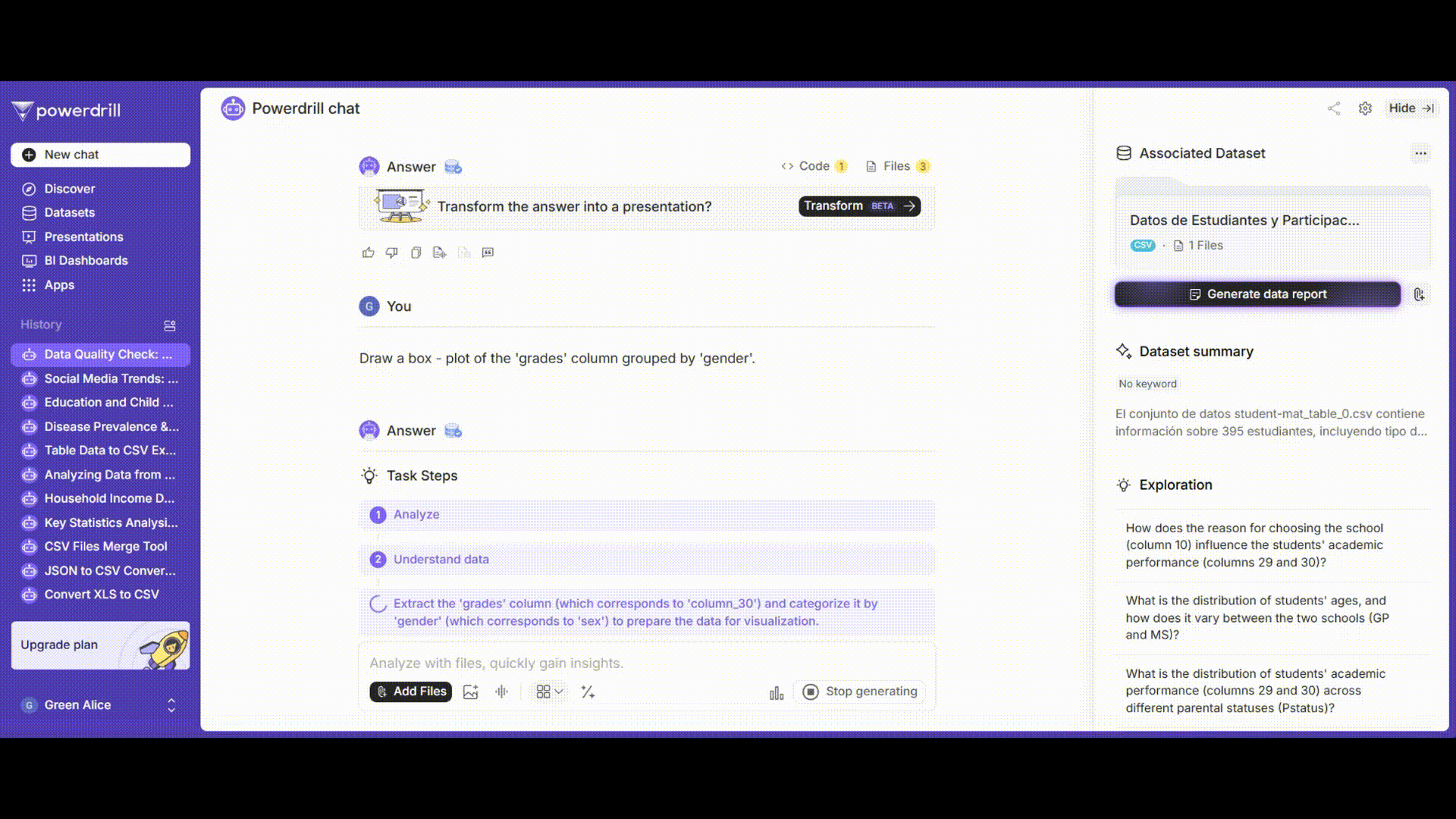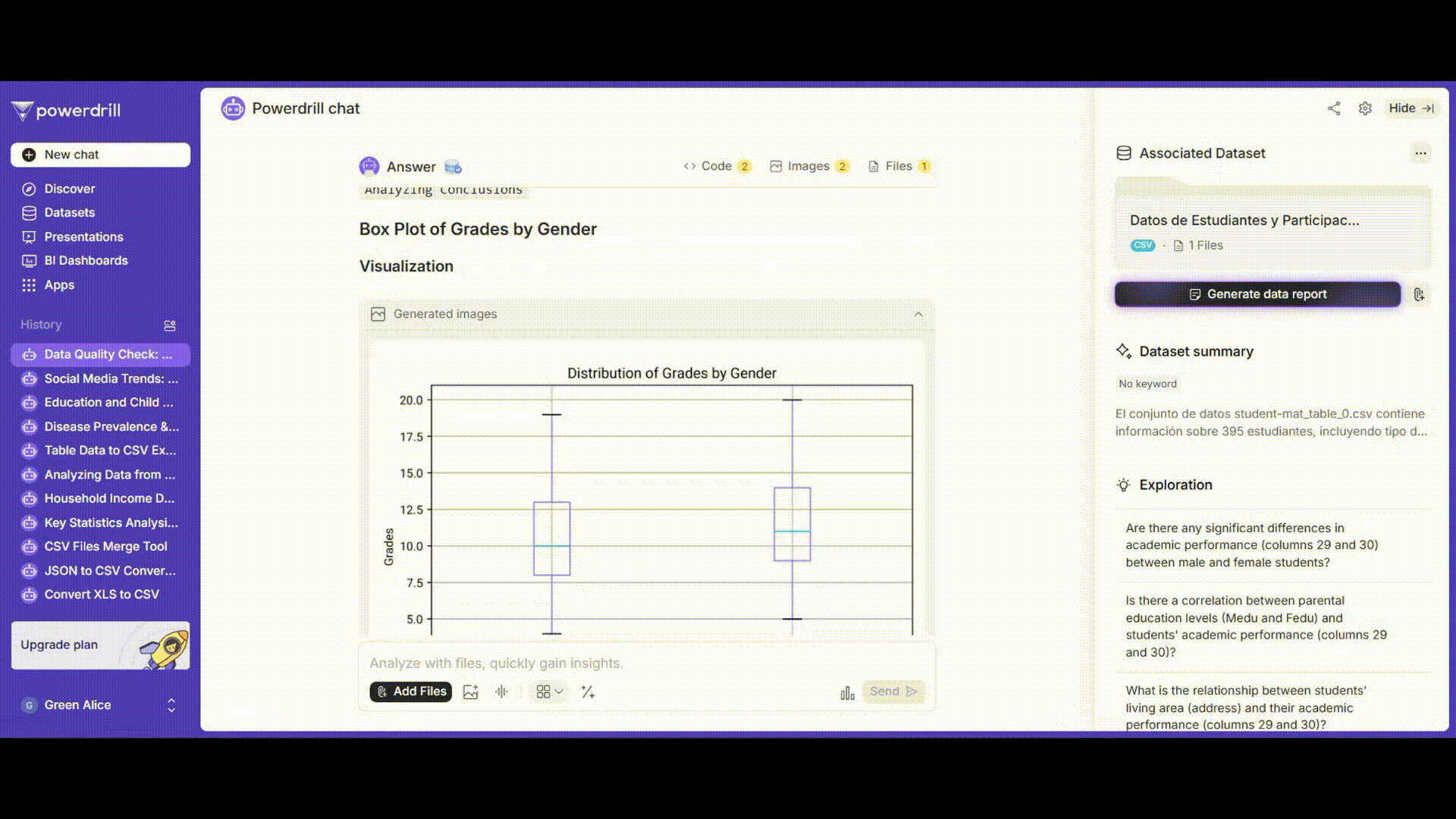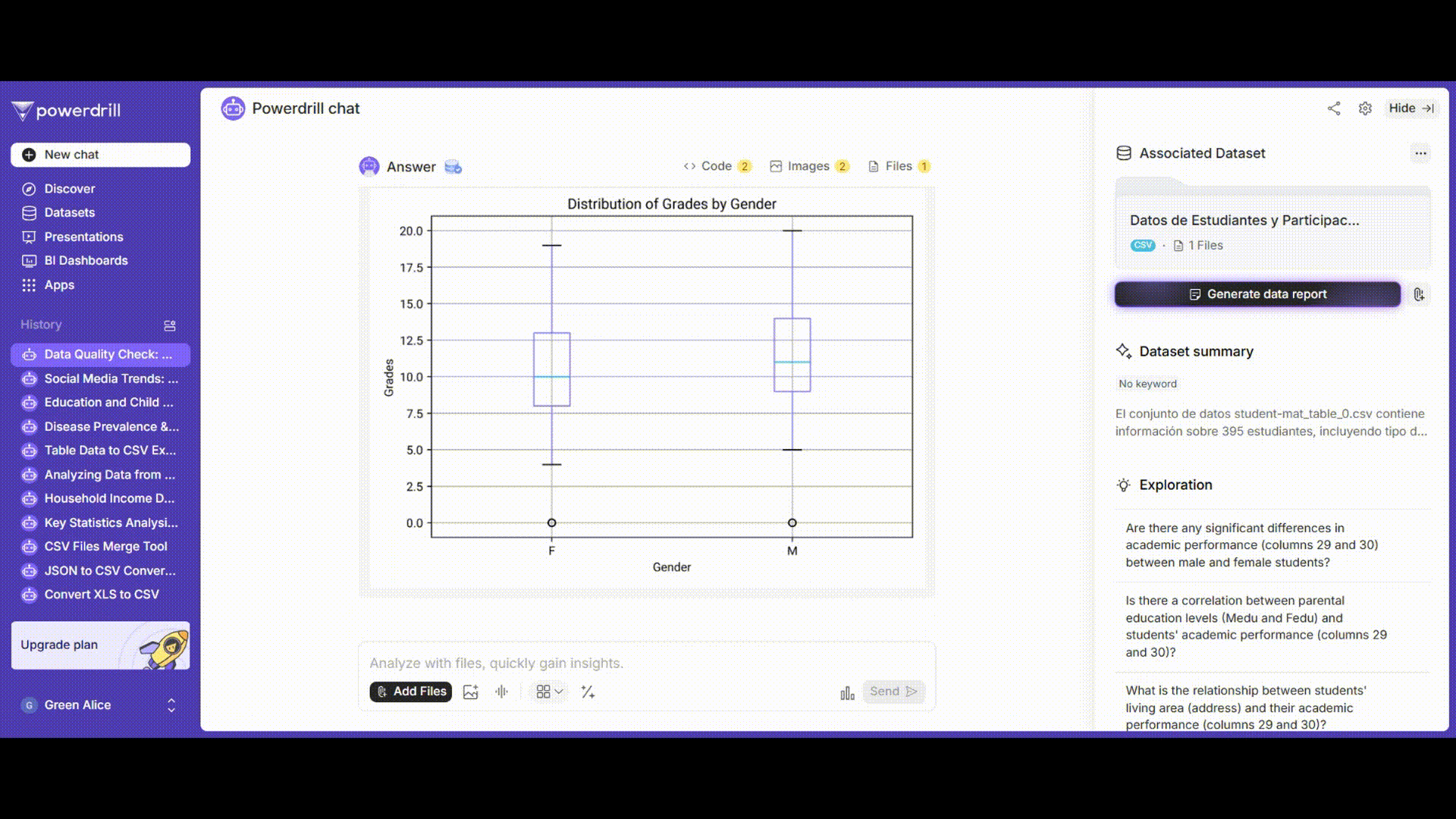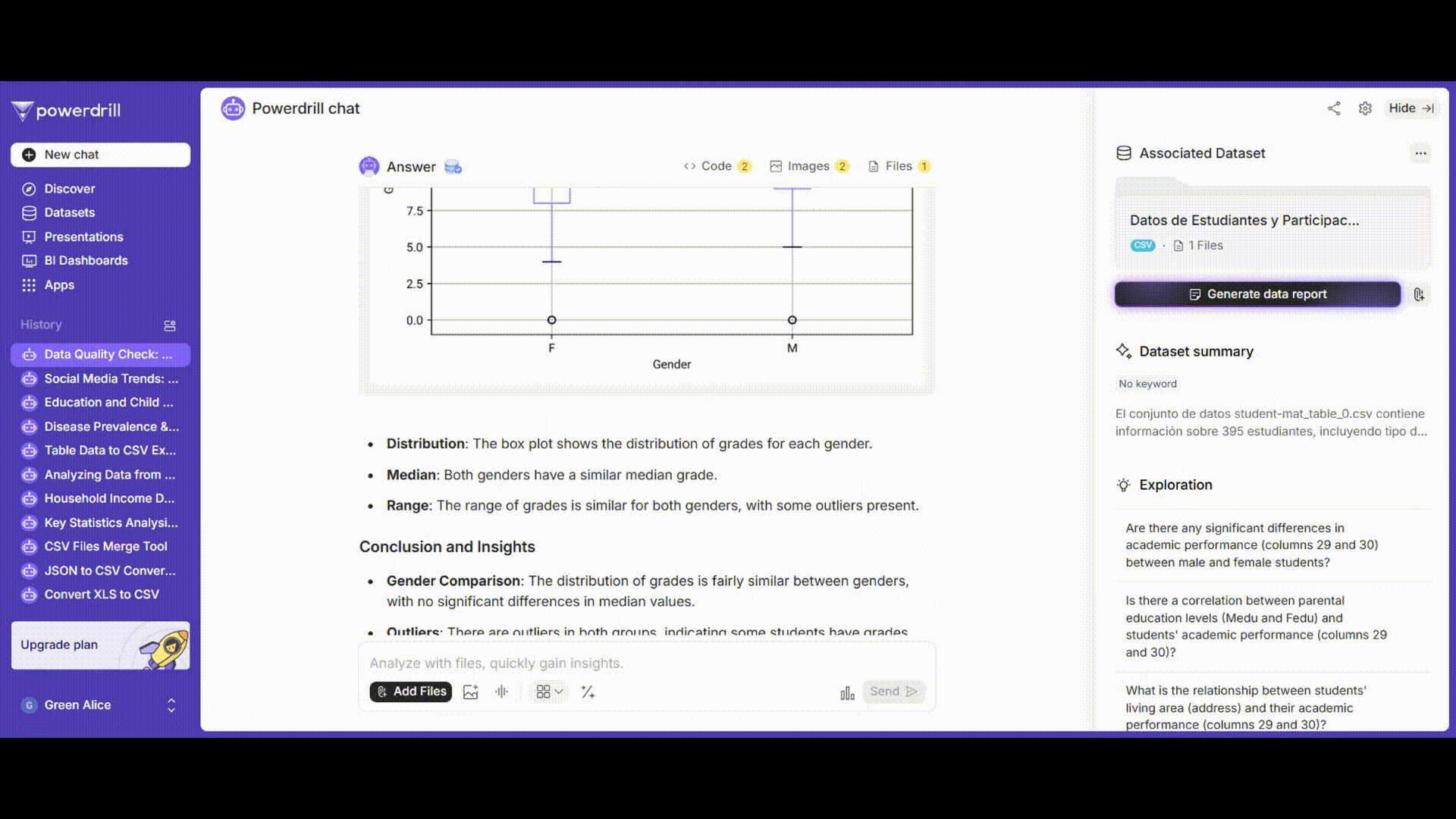
男子学生と女子学生の成績分布を視覚的に表示するために、箱ひげ図とヒストグラムを描画します。
プロンプト例: 「'gender'でグループ化された'grades'列の箱ひげ図を描画してください。」
ステップ4: 検定の前提条件
正規性検定
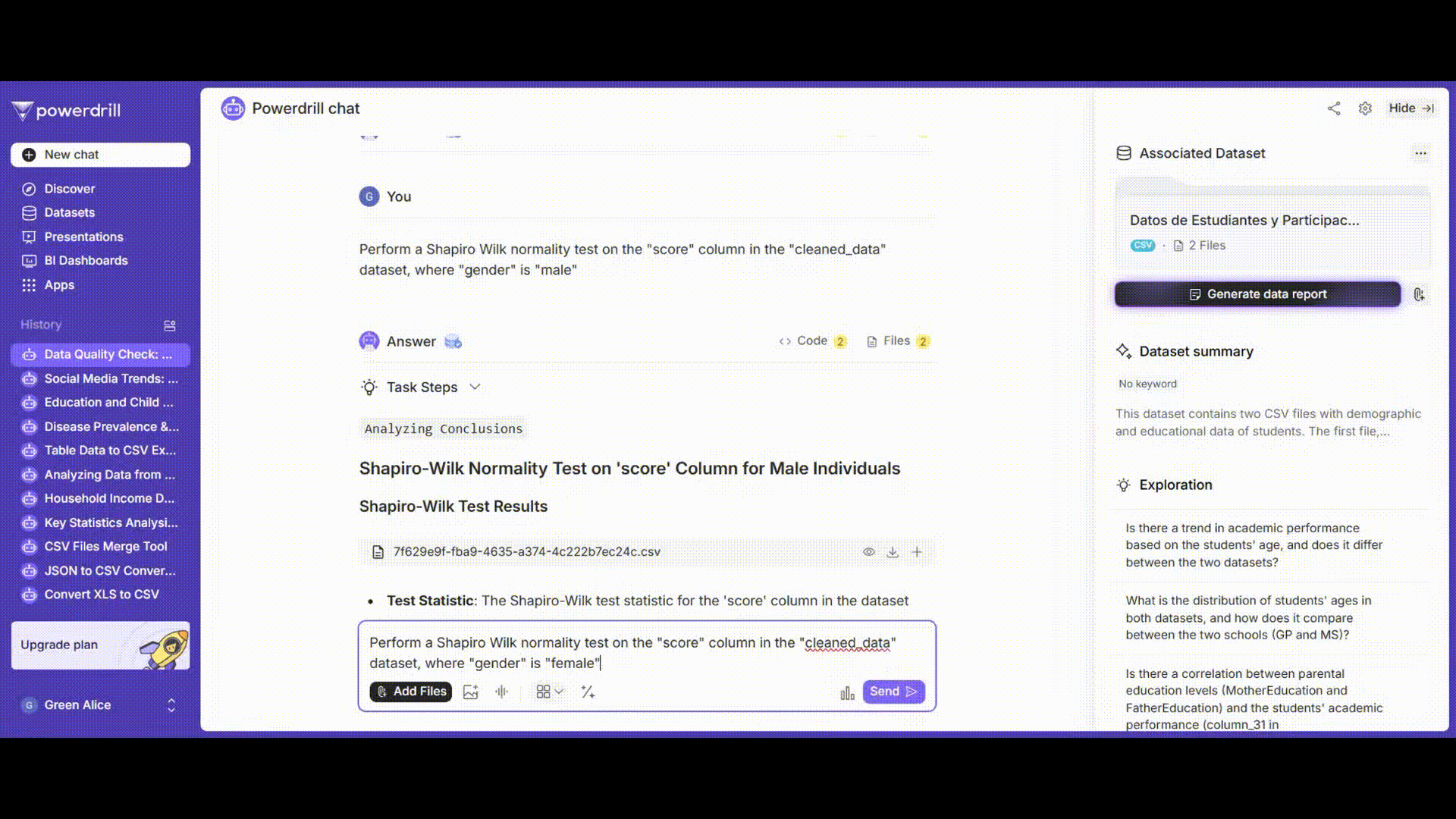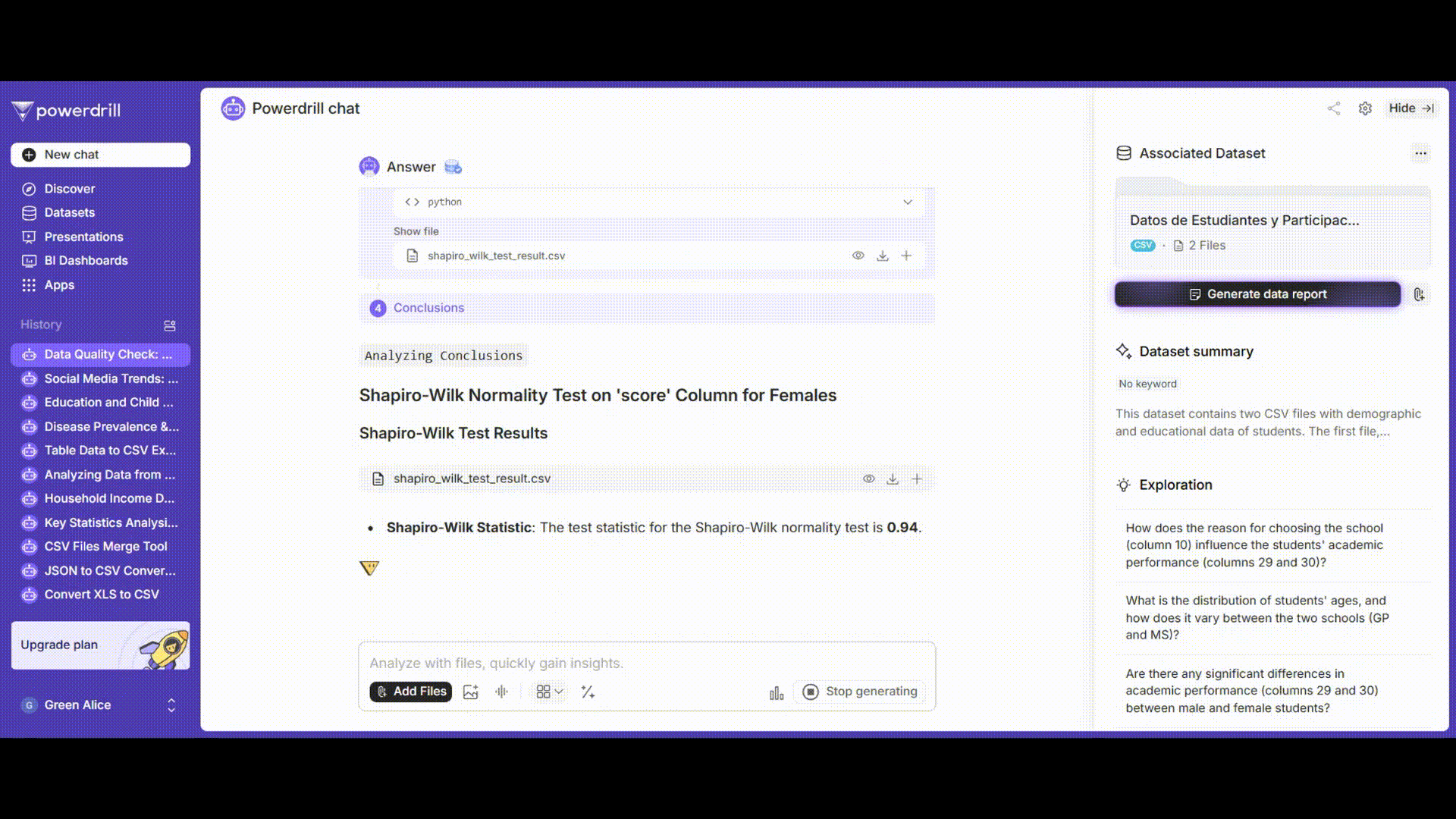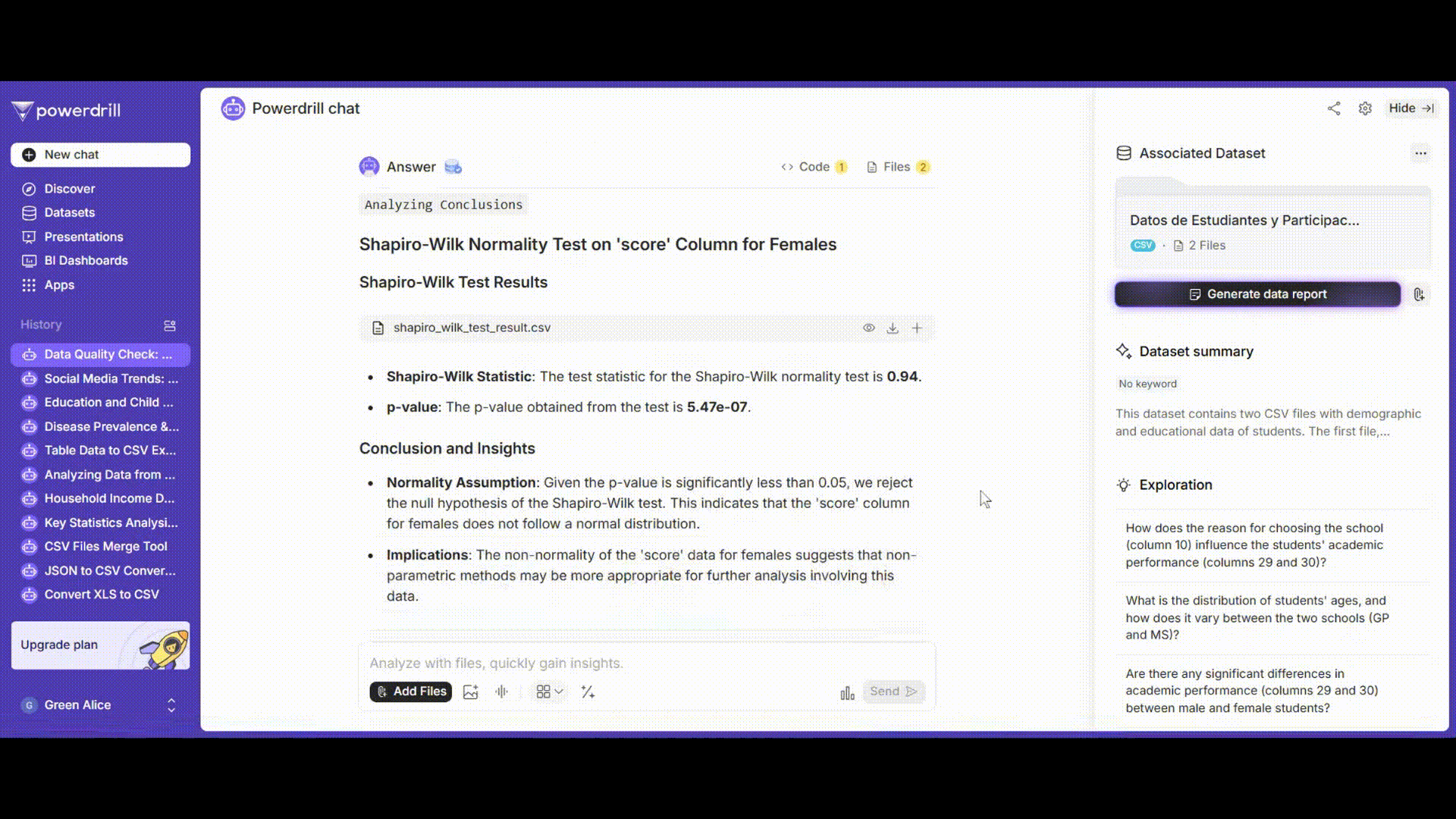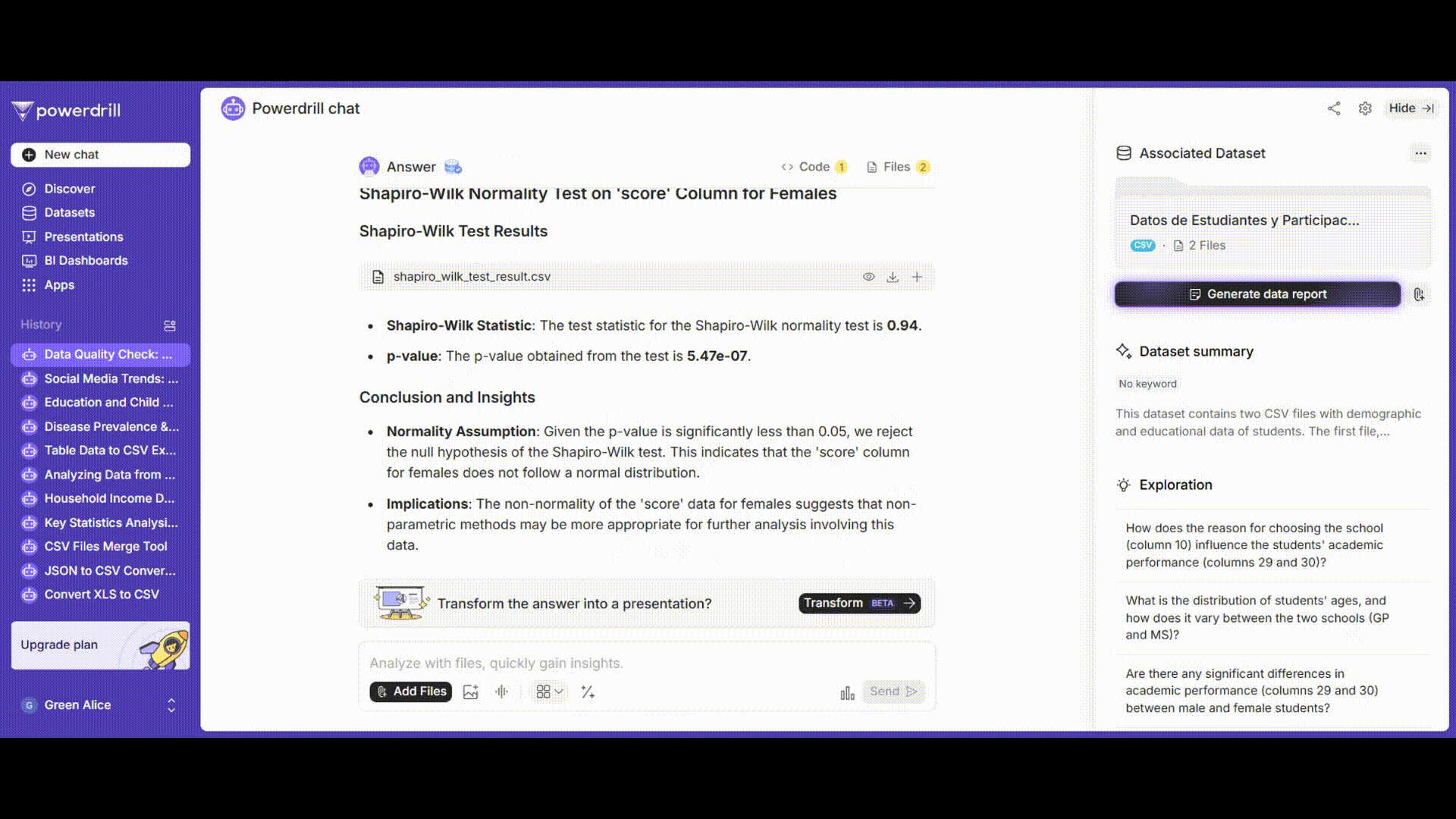
男子学生と女子学生の成績についてそれぞれ正規性検定を実施します。シャピロ-ウィルク検定またはコルモゴロフ-スミルノフ検定を使用できます。
プロンプト例:
「'gender'が'male'である'grades'列にシャピロ-ウィルク正規性検定を実施してください。」
「'gender'が'female'である'grades'列にシャピロ-ウィルク正規性検定を実施してください。」
等分散性検定
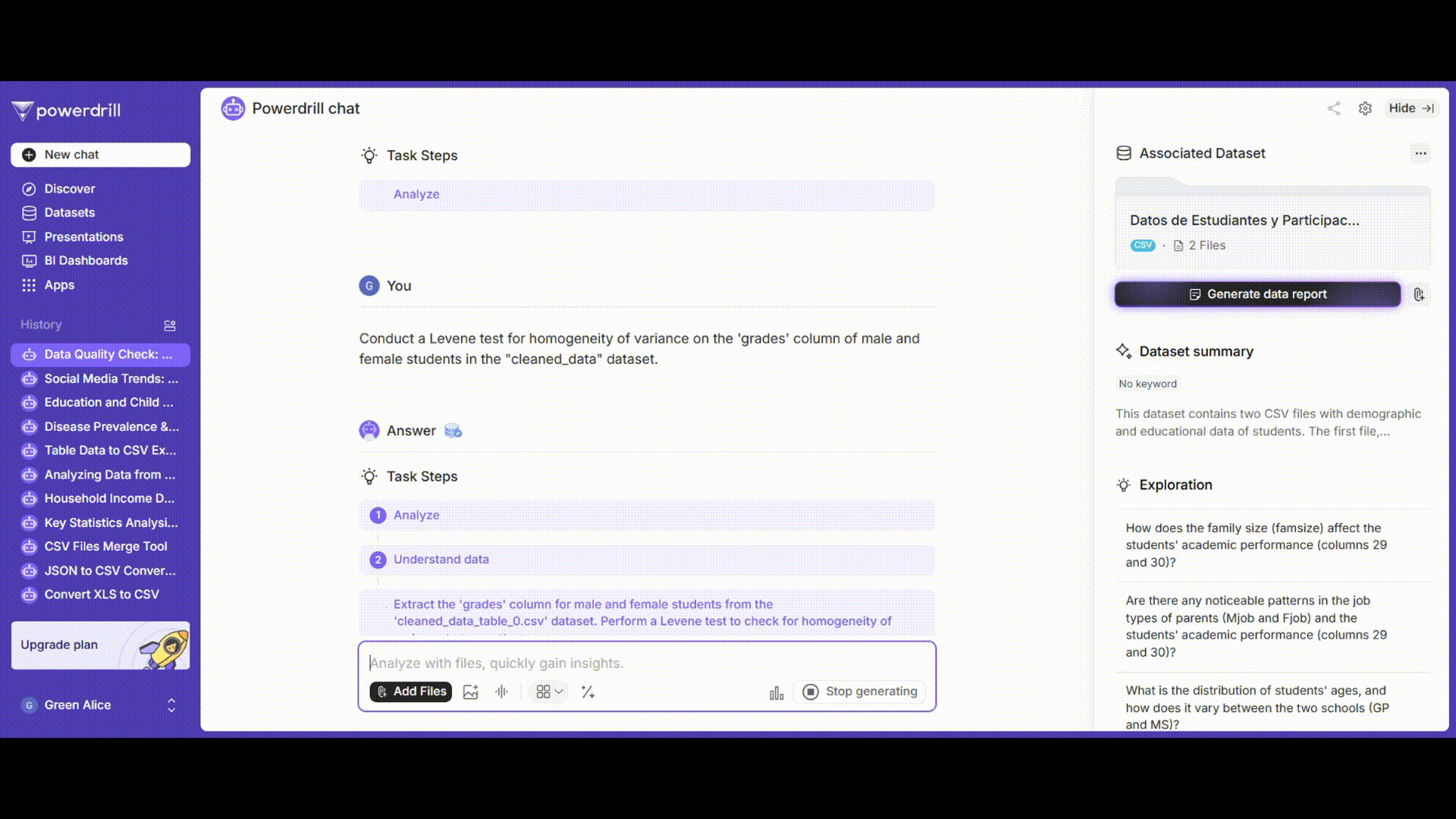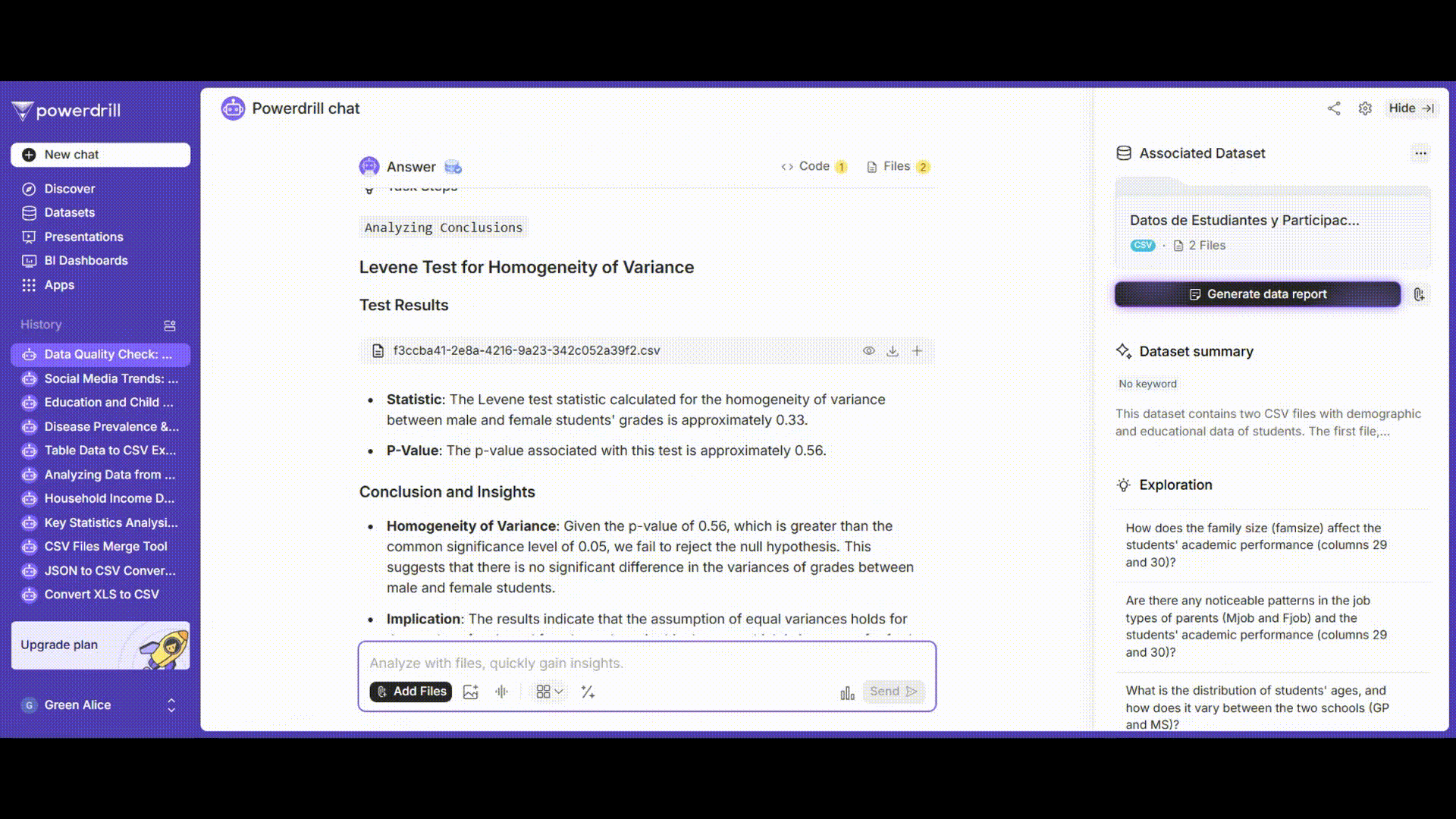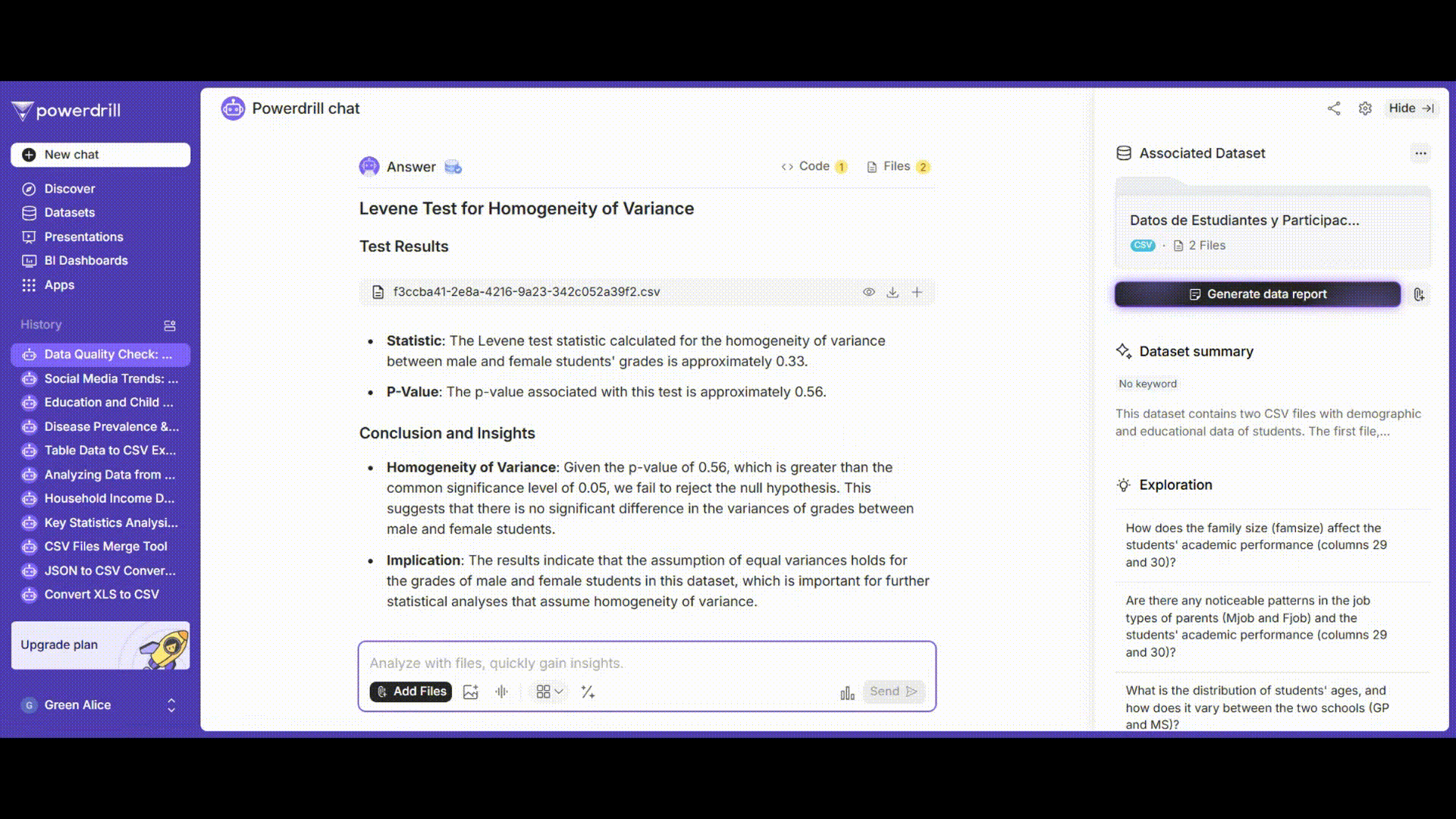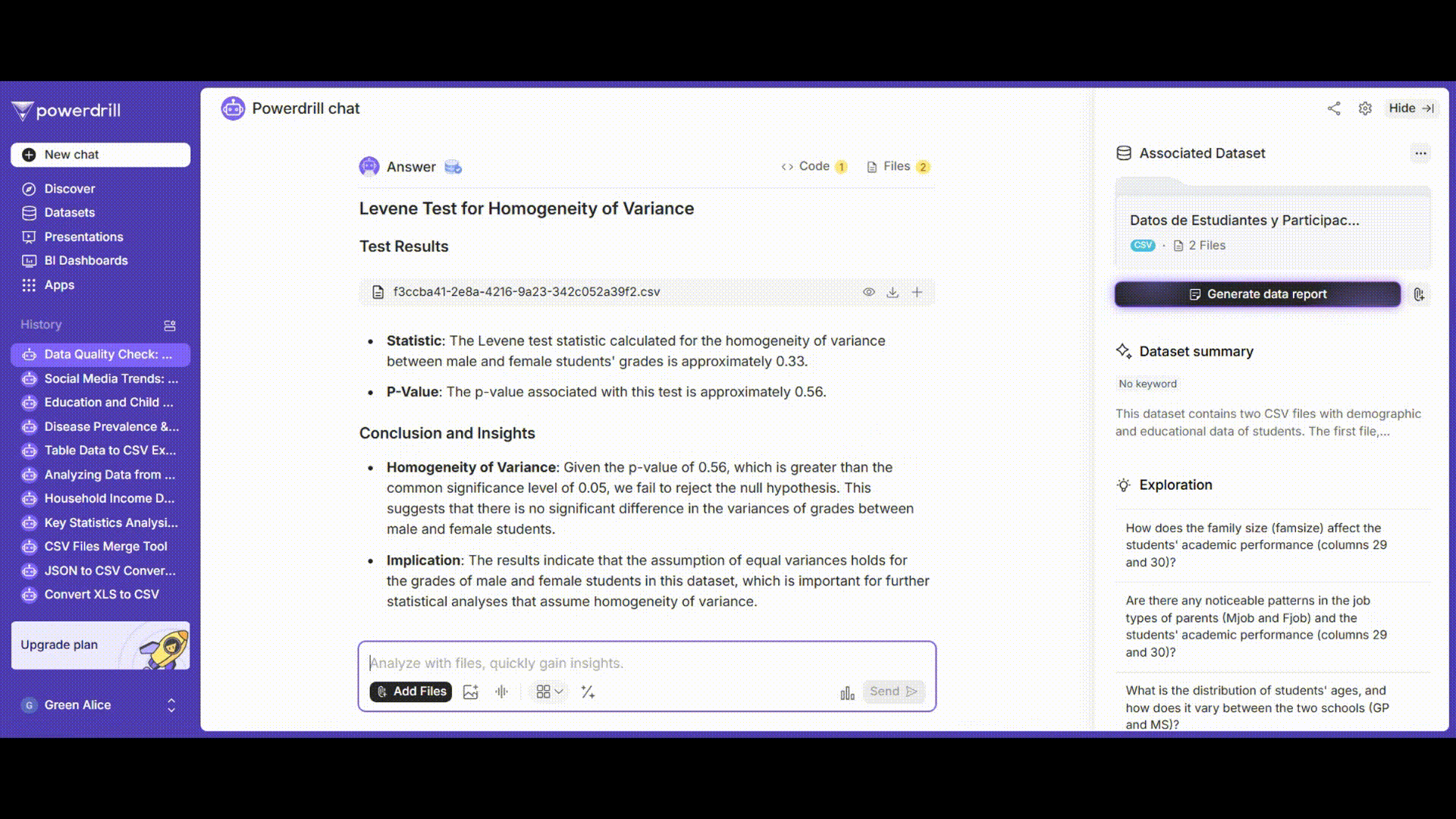
レベンス検定を使用して、男子学生と女子学生の成績の分散が均一であるかどうかを判断します。
プロンプト例: 「男子学生と女子学生の'grades'列に対して等分散性のレベンス検定を実施してください。」
ステップ5: 独立2標本t検定の実行
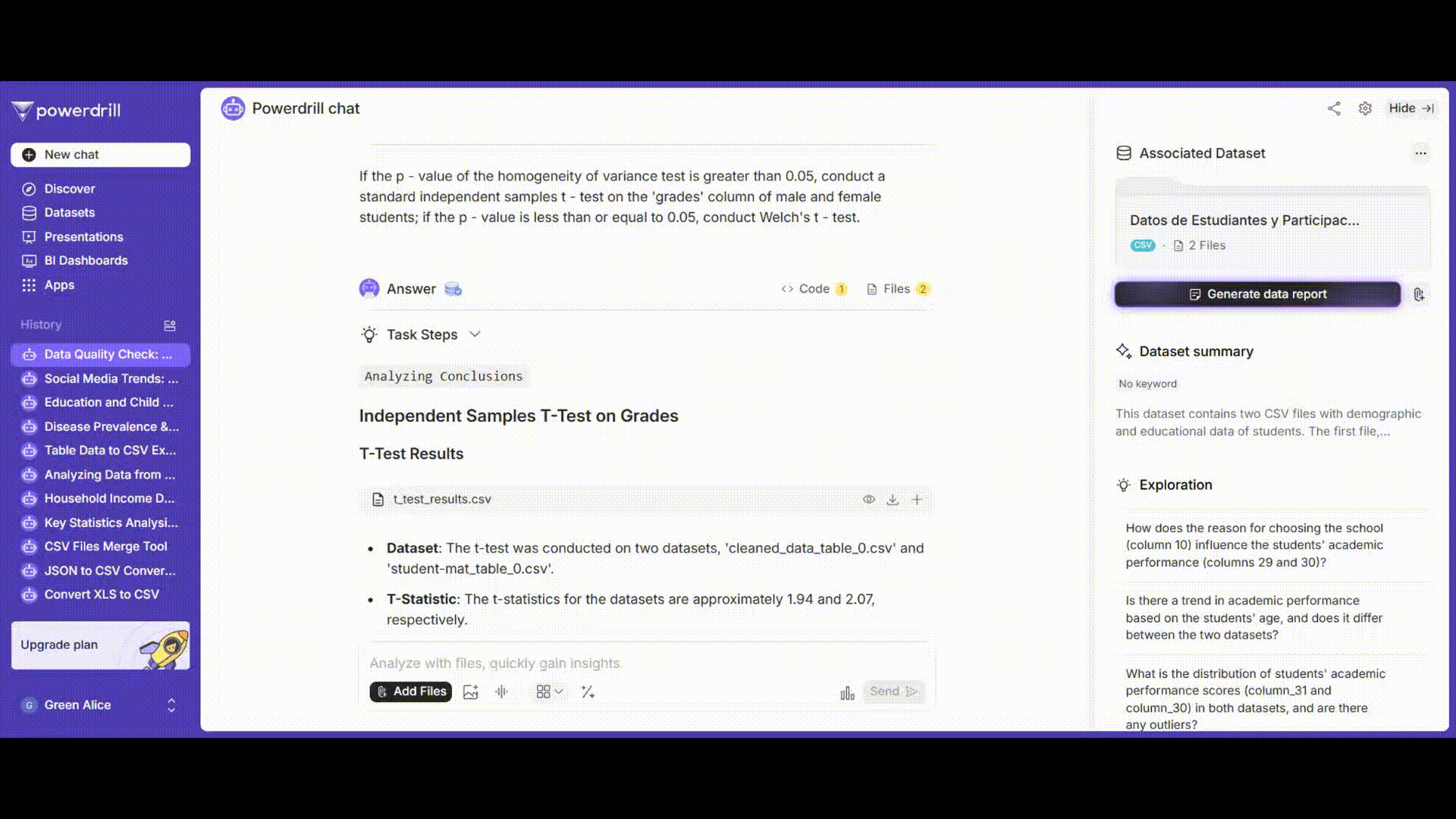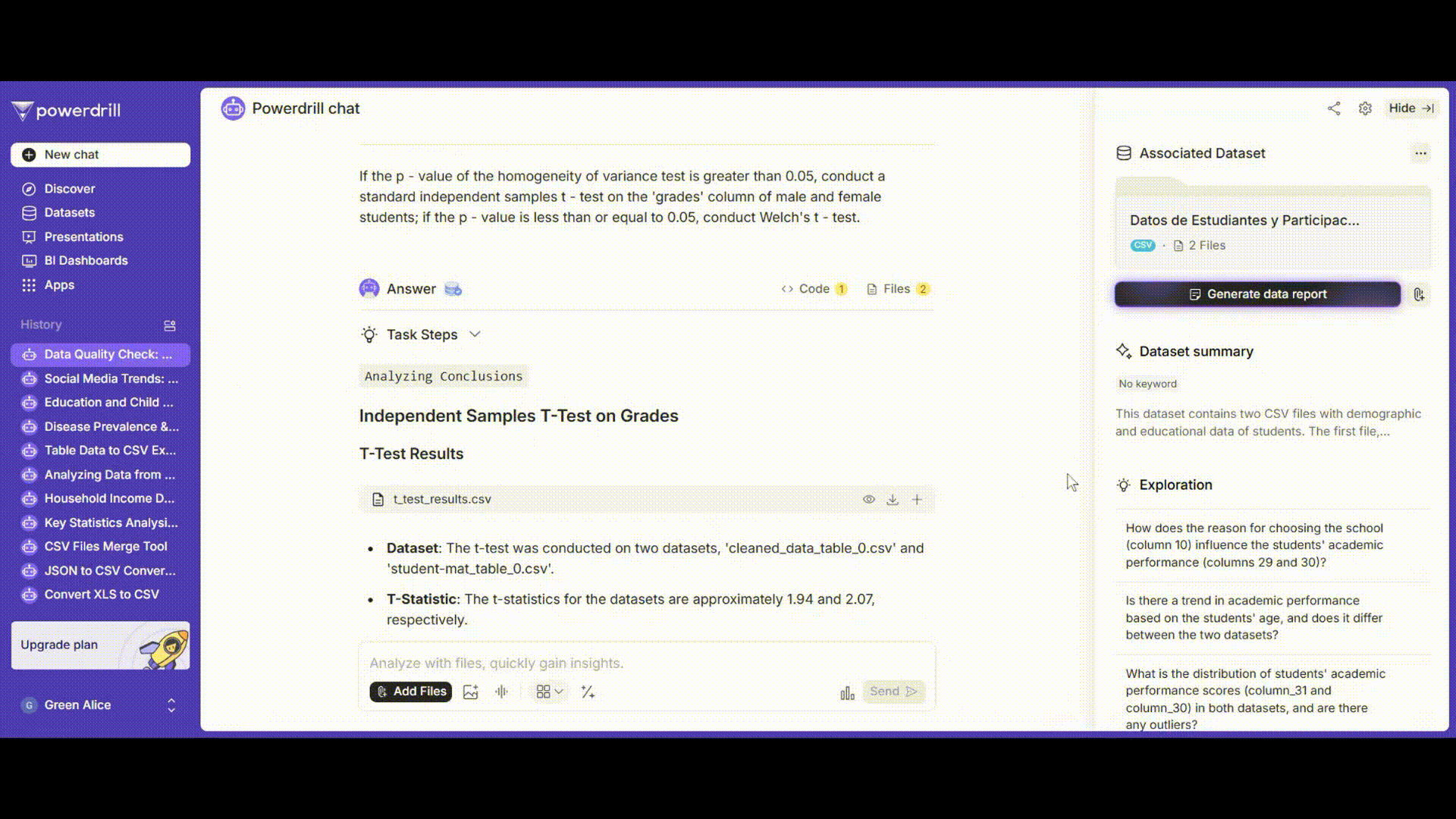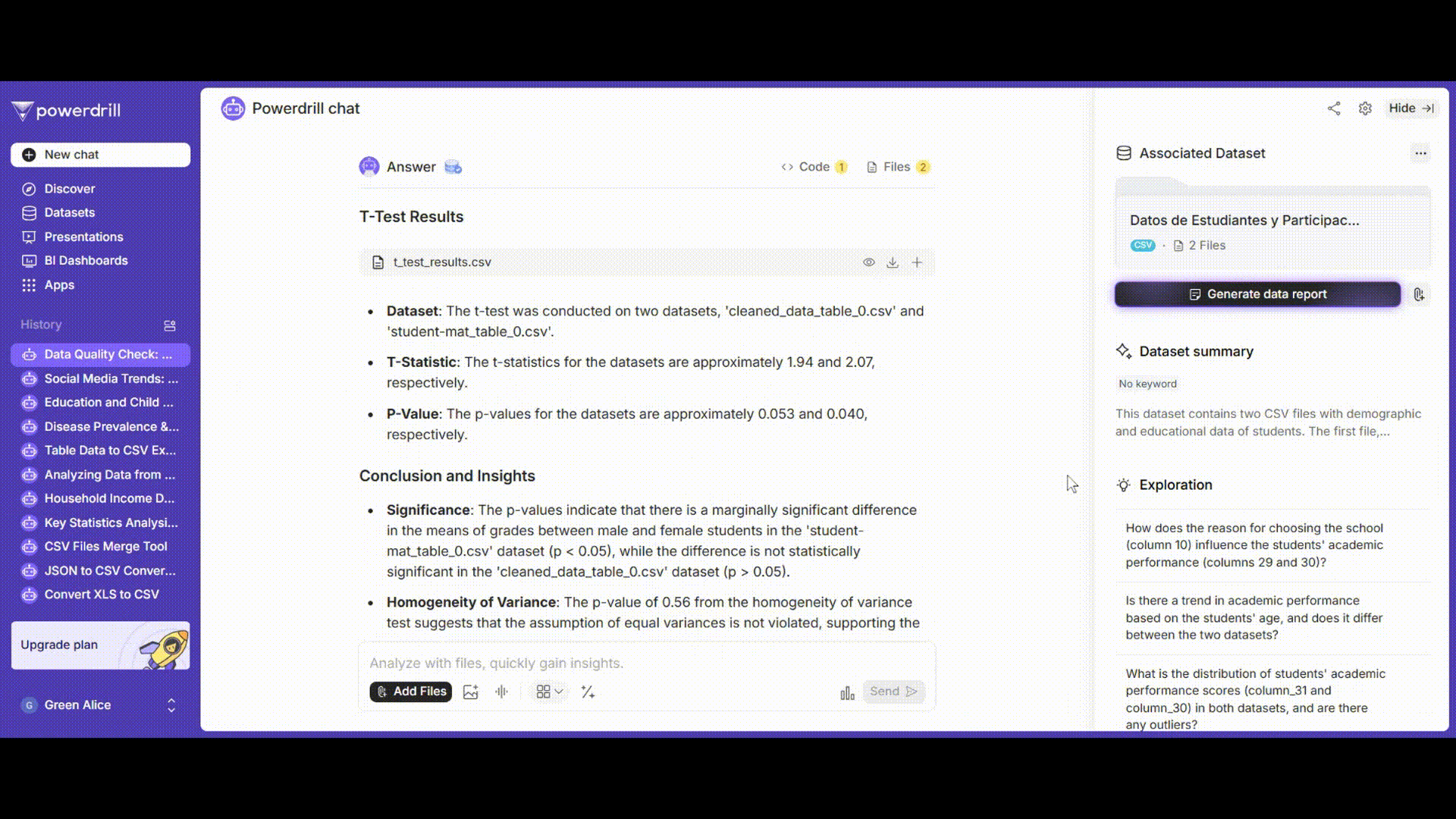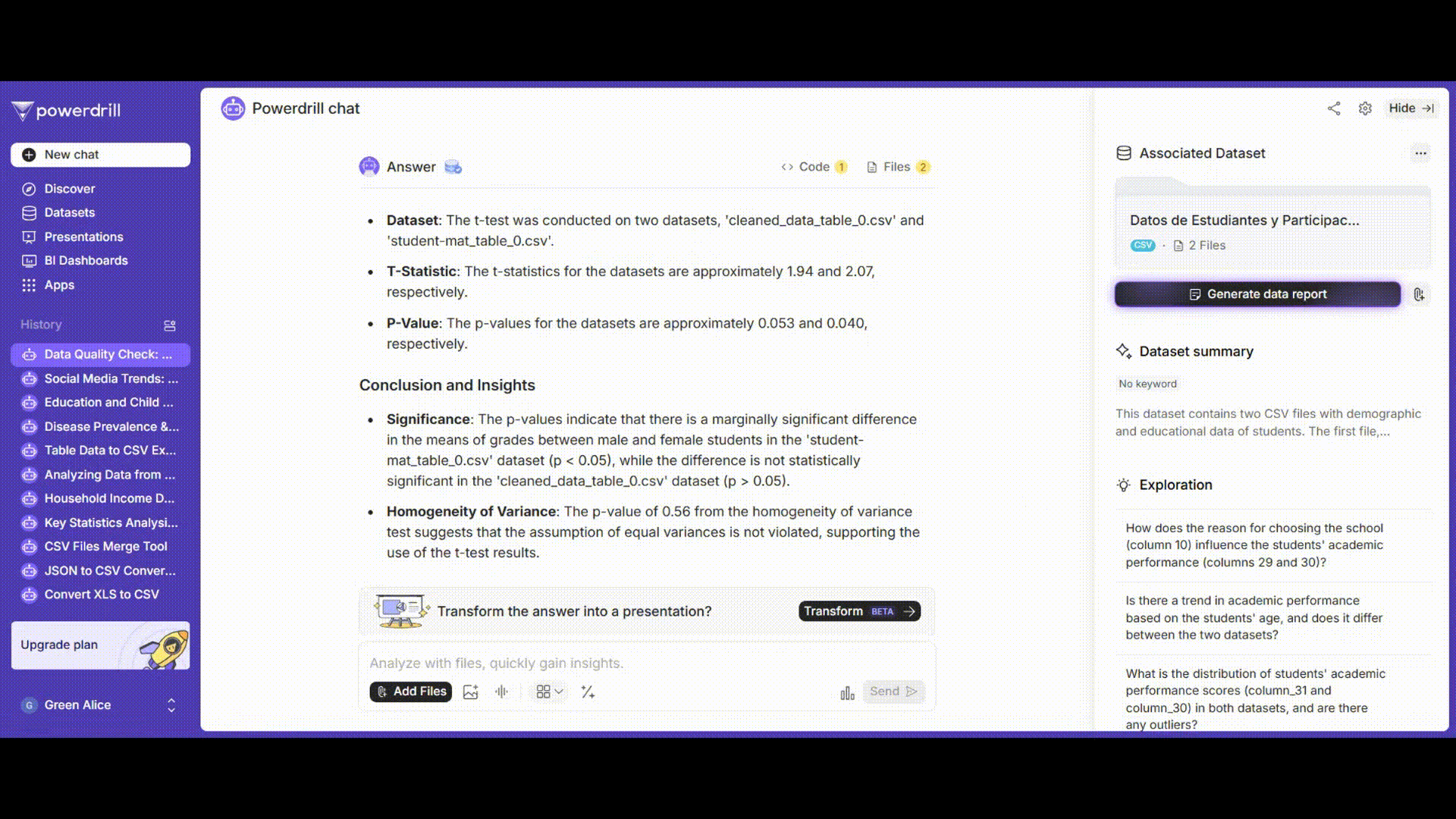
等分散性検定の結果に基づいて適切なt検定方法を選択します(分散が均一であれば標準的なt検定を使用し、分散が不均一であればウェルチのt検定を使用します)。
プロンプト例: 「等分散性検定のp値が0.05より大きい場合、男子学生と女子学生の'grades'列に対して標準的な独立2標本t検定を実施してください。p値が0.05以下の場合、ウェルチのt検定を実施してください。」
ステップ6: 結果の解釈
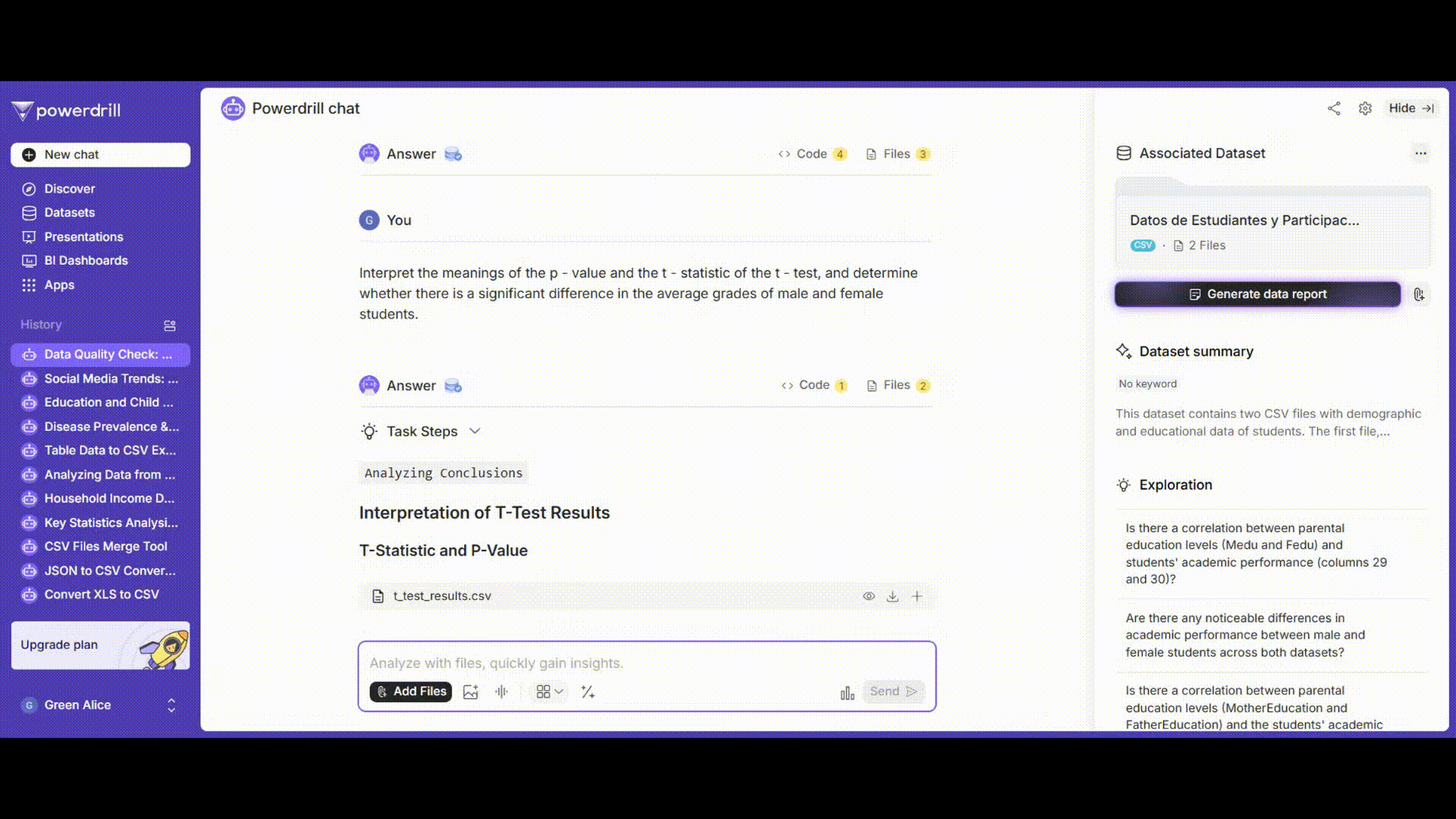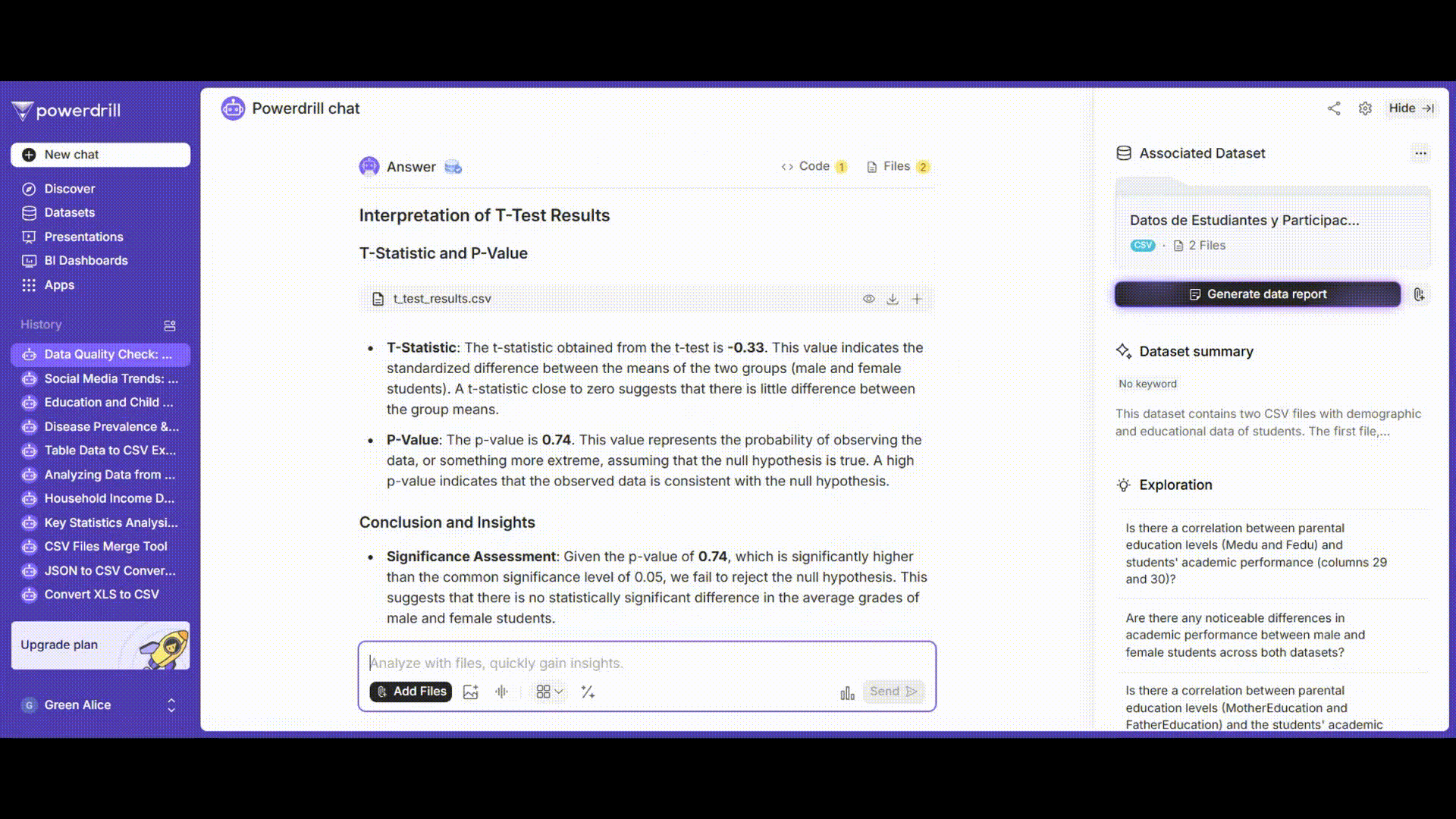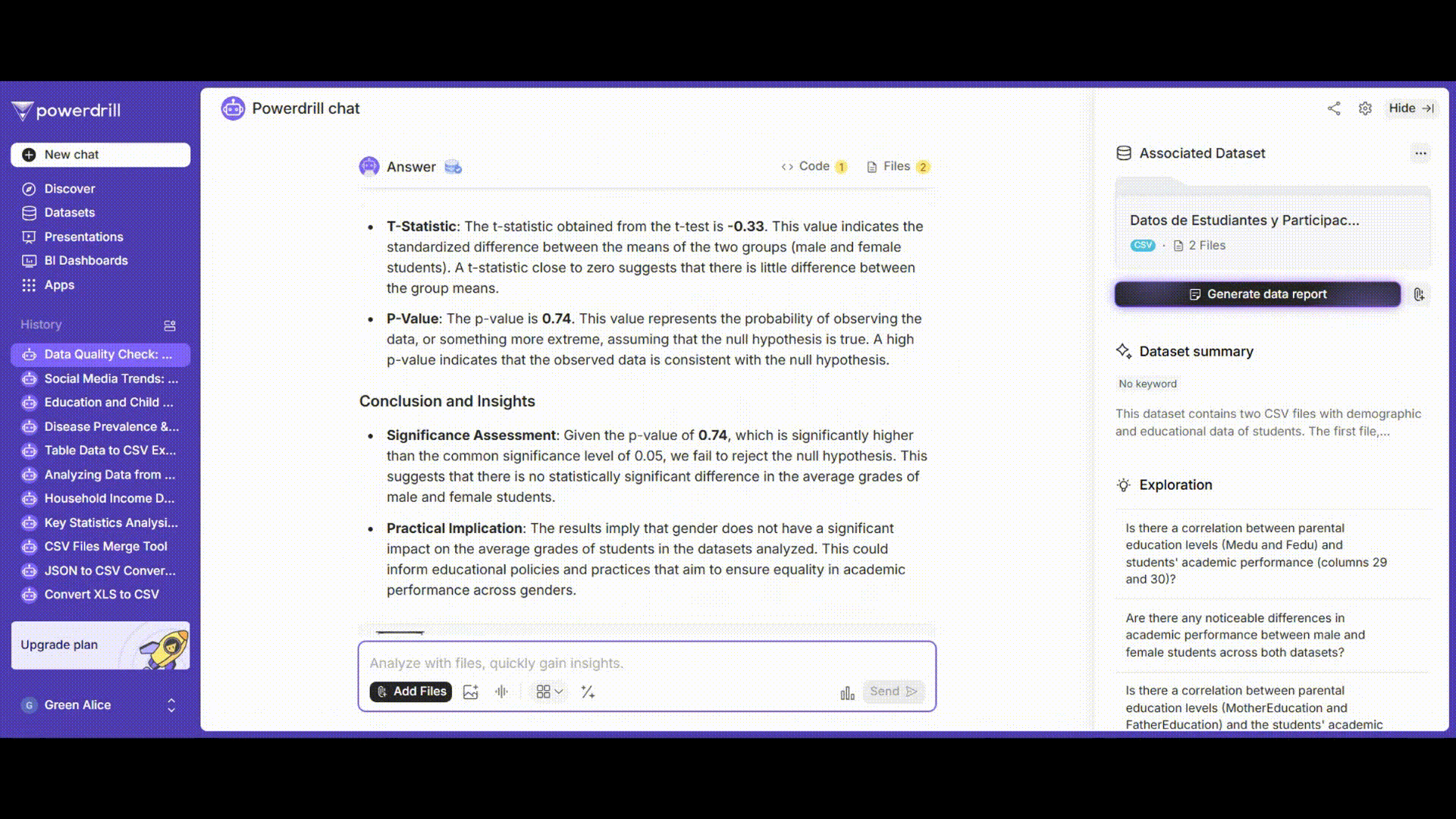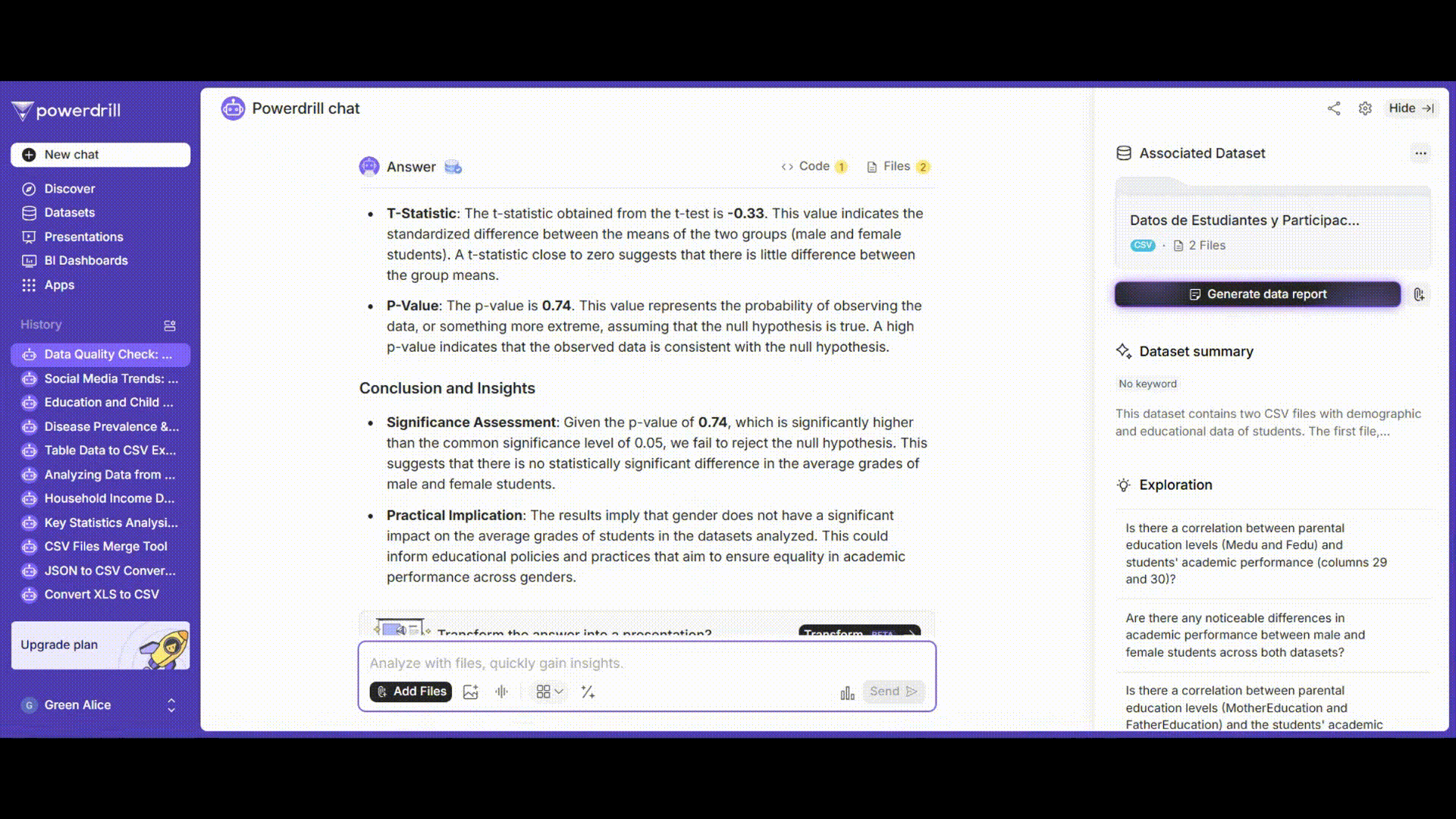
t検定の結果を解釈し、男子学生と女子学生の平均成績に有意な差があるかどうかを判断し、データクレンジング、分析、検定結果を含むレポートを生成します。
プロンプト例: 「t検定のp値とt統計量の意味を解釈し、男子学生と女子学生の平均成績に有意な差があるかどうかを判断してください。」
t検定結果の解釈
t値の意味と解釈
t値の絶対値が大きいほど、帰無仮説に反する強力な証拠となります。
p値の理解
定義: 帰無仮説が真であると仮定した場合に、標本データと同等またはそれ以上に極端な結果が観測される確率。
誤解の回避: 小さいp値は対立仮説を裏付けるものではなく、むしろ帰無仮説に反する強い証拠を示します。
信頼区間の役割と解釈
概念: 真の母集団パラメータが含まれる可能性が高い値の範囲。
有用性: 信頼区間は、効果量と精度を測る指標を提供することでp値を補完します。
本記事で概説されたガイドラインと原則に従うことで、読者はデータ分析において自信を持ってt検定を使用し、堅牢で意味のある結論を導き出すことができます。
今すぐt検定を簡素化しましょう!
複雑な統計に足止めされないでください。Powerdrill AIを使えば、t検定の実施はかつてないほど簡単になります。データセットをアップロードし、質問するだけで、洞察を引き出しましょう。今すぐサインアップして、簡単なデータ分析への旅を始めましょう。
よくある質問
1. Powerdrillを使用するために統計知識が必要ですか?
いいえ、Powerdrillはすべての人向けに設計されています。データをアップロードし、自然言語で質問するだけです。
2. Powerdrillは大規模なデータセットを処理できますか?
はい、Powerdrillは何百万行ものデータセットを処理し、効率的に結果を提供できます。
3. どのような種類のファイルをアップロードできますか?
PowerdrillはCSV、XLSX、TSVなどに対応しています。
4. Powerdrillの計算は信頼できますか?
もちろんです。Powerdrillは使用されたPythonコードとデータソースを表示することで、完全な透明性を提供します。
5. t検定の種類を指定する必要がありますか?
いいえ、Powerdrillがあなたのクエリに基づいて適切なt検定を判断します。