Powerdrill AI、QuALITYベンチマークで第1位を獲得

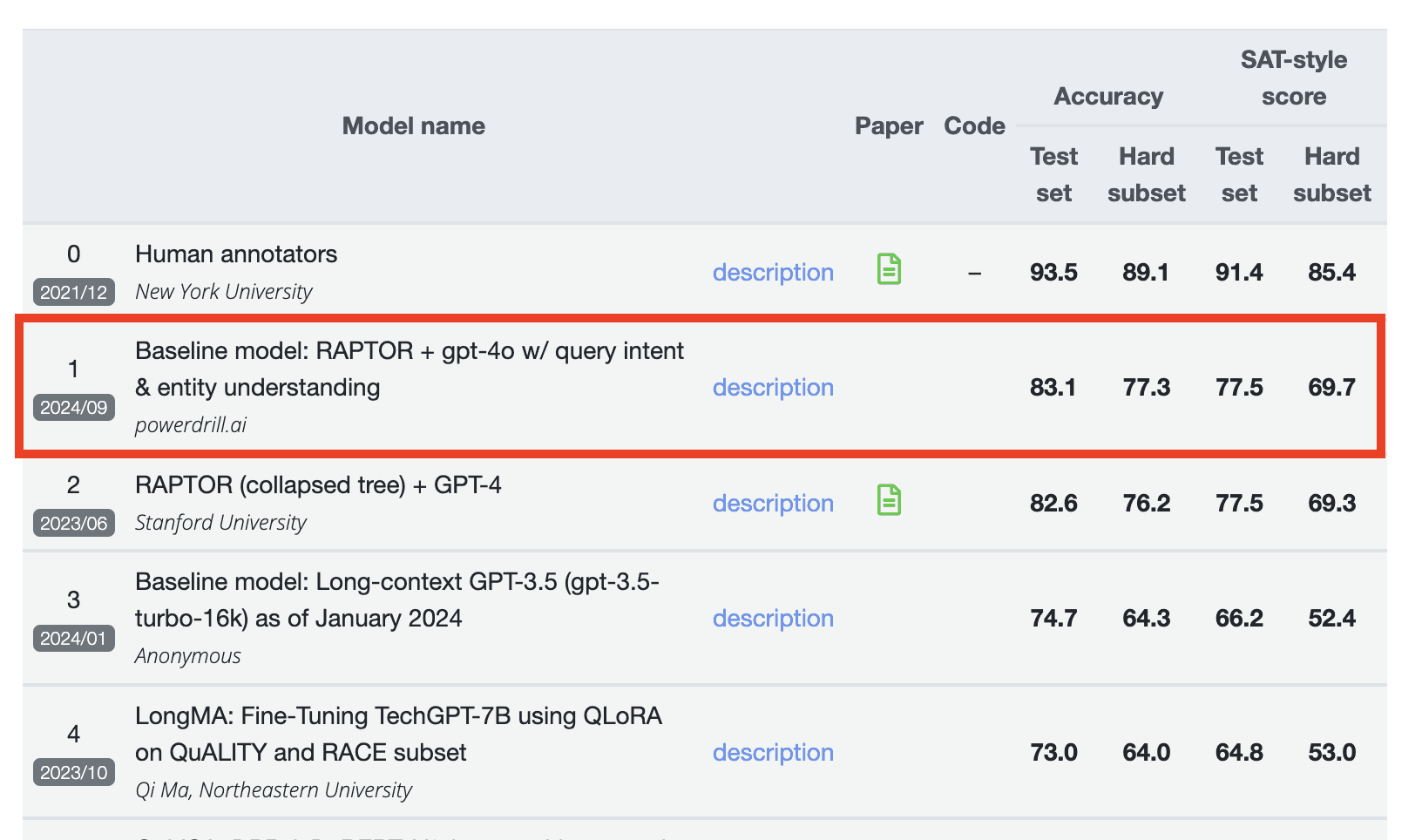
この度、Powerdrill AIがQuALITYベンチマークのリーダーボード(2024年9月更新)において、第1位を獲得したことをご報告いたします。正解率(Accuracy)において、テストセットで83.1、高難易度サブセットで77.3を記録。また、SAT形式スコアでは、テストセットで77.5、高難易度サブセットで69.7を達成しました。詳細はリーダーボードをご覧ください:https://nyu-mll.github.io/quality
QuALITYとは?
QuALITY(Question Answering with Long Input Texts)は、特に現在のモデルが通常扱える長さをはるかに超える文脈での、長文読解能力を評価するために設計されたデータセットです。このデータセットには、平均約5,000トークンからなる英語の長文テキストが含まれています。要約や抜粋に基づいて問題が作成される他のデータセットとは異なり、QuALITYの問題は、文章全体を読んだコントリビューターによって作成・検証されています。
QuALITYの重要な特徴の一つは、時間制限のあるアノテーターが回答できる問題は全体の半数に過ぎない点です。これは、流し読みや単純なキーワード検索では安定して高得点を獲得することが困難であることを示唆しています。この特性により、データセットは特に挑戦的なものとなっており、表面的な情報抽出ではなく、深い内容理解が可能なモデルの開発を促進することを目的としています。
ベースラインモデルの正解率は約55.4%と低く、人間の93.5%には遠く及びません。また、データセットには特に難易度の高い問題で構成される「高難易度サブセット(QuALITY-HARD)」も含まれています。
QuALITYの評価基準

ランキングは、テストセット全体における正解率(Accuracy)に基づいて決定されます。これは、一部の問題に限定せず、すべての問題にどれだけ正確に答えられたかに基づいて順位が決定されることを意味します。
ここでの正解率は、正解数をテストセットの総問題数で割ることで算出され、全体的なパフォーマンスを直接的に測る指標となります。
一方、SAT形式スコアはより複雑な評価方法です。このスコアは、まず正解数を基準としますが、ランダムな推測による正答を防ぐため、誤答1問につき1/3点が減点されます。このペナルティにより、参加者はより慎重に回答することが求められます。なお、無回答の選択肢はスコアに影響を与えません(0点として扱われます)。最終的に、この調整後のスコアを総問題数で割り、参加者の総合的なパフォーマンスを反映した最終スコアが算出されます。
最終的なQuALITYのランキングは、正解率とSAT形式スコアという2つの主要な要素で決定されます。これらはそれぞれ、テストセットと高難易度サブセットの両方で評価されます。特筆すべきは、Powerdrill AIがスタンフォード大学やノースイースタン大学などのモデルを上回り、すべての評価項目で最高スコアを記録したことです。参考として、スコア0がベンチマークの基準値となります。このPowerdrill AIの卓越したパフォーマンスは、QuALITYが要求するタスク処理におけるその優れた能力を明確に示しています。
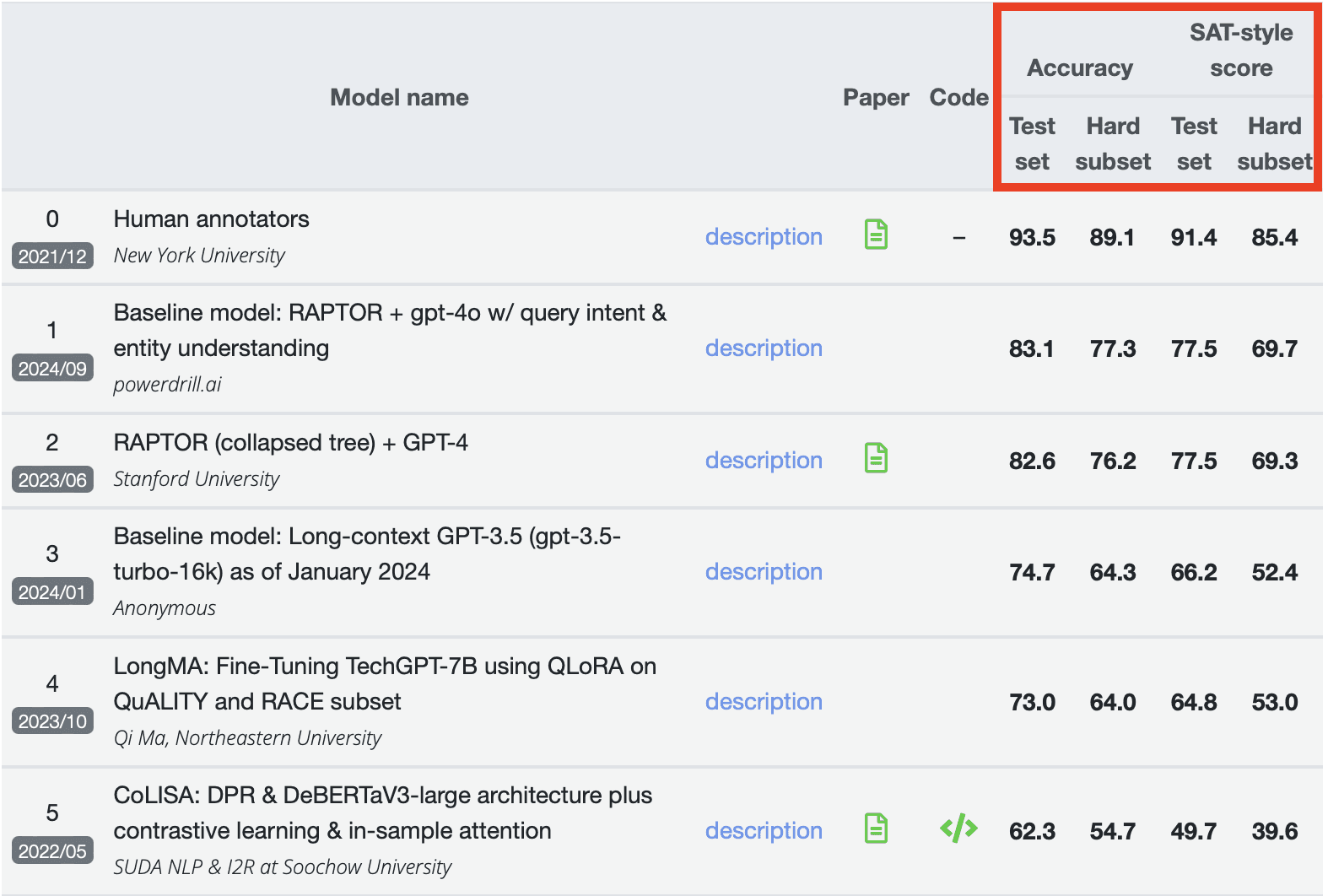
テストセット(Test set)とは、モデルのトレーニング後にその性能を評価するために確保されるデータセットの一部です。通常、モデルがトレーニングや検証の段階で見たことのないデータが含まれており、モデルが未知のデータに対してどれだけ汎化できるかを測定することを目的としています。正解率、適合率、再現率などの性能指標は、このテストセットでのモデルの性能に基づいて計算されます。
高難易度サブセット(Hard subset)とは、テストセットの中でも特にモデルにとって処理が難しい問題を集めた部分です。これには、クラス間の区別が微妙であったり、データにノイズが多かったり、モデルが従来から苦手とするようなケースが含まれます。高難易度サブセットでの性能は、より厳しい条件下でのモデルの挙動を理解し、具体的な改善点を特定するために別途分析されることがよくあります。
Powerdrill AIが第1位を獲得した理由
Powerdrill AIは、複雑なクエリを効率的に処理するために設計された高度なシステムです。高度なアルゴリズムを用いてユーザーの入力を分解し、検索プロセスを最適化することで、正確で関連性の高い情報を迅速に提供します。このシステムは様々な文脈に適応し、シームレスで効果的なユーザー体験を実現します。
RAPTORは、複数の抽象化レベルで文脈情報を取り込むことにより、大規模言語モデルのパラメトリック知識を強化する革新的なツリーベースの検索システムです。再帰的なクラスタリングと要約技術を用いて階層的なツリー構造を構築し、検索対象コーパスの様々なセクションにまたがる情報を統合します。ボトムアップ方式で、RAPTORはテキストのチャンク(塊)をクラスタリングして要約を生成し、リーフノードに元のテキスト、上位ノードに要約された情報を持つ多層ツリーを構築します。
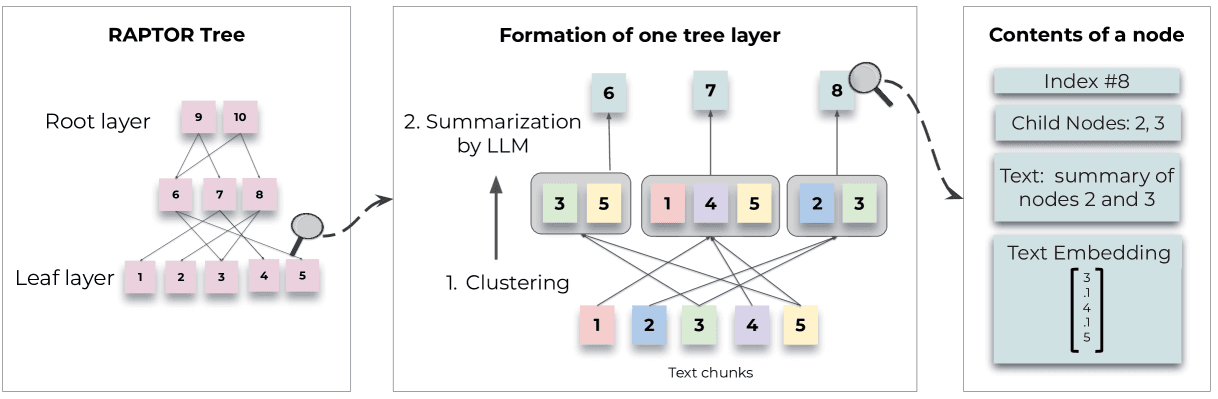
Powerdrill AIは、このRAPTORインデックスを活用して、より洗練されたチャンクを検索し、RAG(Retrieval-Augmented Generation、検索拡張生成)タスクにおける推論と応答の質を向上させています。Powerdrill AIはまず、ユーザーのクエリをマルチホッププランに分解します。この分解により、システムは複雑なクエリを段階的に処理し、各ステップを正確に実行することが可能になります。
マルチホッププランの各ステップで、クエリからキーエンティティ(主要な固有表現)が抽出されます。これらのエンティティは、クエリとデータベースやドキュメント内の最も関連性の高い情報を照合する上で極めて重要であり、必要なデータの検索精度を向上させます。
プロセスをさらに最適化するため、Powerdrill AIはリランキングモデルを実装しています。このモデルは、クエリへの回答に不可欠ではない不要な情報のチャンクをフィルタリングします。これにより、関連性の低い部分を取り除くことで、システムが過度に長いコンテキストを処理することを避け、コストを削減するだけでなく、レイテンシを低減してシステム全体のパフォーマンスを向上させます。
総じて、Powerdrill AIは、クエリの分解、エンティティ抽出、データ検索プロセスを慎重に管理することで、正確かつ効率的なクエリ処理の実現に注力しています。
Powerdrill AIの今後の展望
Powerdrill AIが長文読解質問応答のQuALITYベンチマークで第1位を獲得したことは、本プラットフォームにとって極めて重要な成果です。この評価は、特に長く複雑な入力テキストを扱う際の、Powerdrill AIの比類なき精度と複雑なユーザーのクエリへの応答能力を裏付けるものです。難易度の高いテストケースで知られるQuALITYベンチマークは、長文を理解し、正確に質問に答えるモデルの能力を評価します。これは高度な読解力と洗練された処理能力を必要とする偉業です。この分野で競合を凌駕したことで、Powerdrill AIは実世界のデータシナリオに対応する優れた能力を証明し、AIによるクエリ解釈のリーダーとしての地位をさらに固めました。
このマイルストーンは、Powerdrill AIを支える戦略と技術の有効性を証明するだけでなく、将来の発展への道を切り拓くものでもあります。この成果により、Powerdrill AIはさらなる能力拡大に向けて有利な立場に立ち、より複雑なタスクをより高い効率で処理できるようモデルを洗練させていくことができます。今後は、レイテンシの最適化、コスト削減、そしてさらに長文で詳細な入力テキストを処理する能力の強化に重点が置かれるでしょう。この成功は継続的なイノベーションを促進し、Powerdrill AIがAI駆動のクエリ処理業界をリードし続け、様々な分野での応用を拡大していくことを可能にします。
ぜひお試しください:/