乳がん診断の傾向と特徴量の重要度に関する包括的分析

このデータセットは、悪性腫瘍と良性腫瘍の分布に関する詳細情報、特徴量分析、データ可視化、予測モデリングなど、乳がん診断の傾向と動態を捉えています。
Powerdrillでこの乳がんデータを分析し、乳がん診断における重要な知見と傾向、および診断結果の予測における特徴量の重要性を掘り下げてみましょう。
提供されたデータセットに基づき、Powerdrillはメタデータを検出し分析し、以下の関連する問いを提示します。
1. 全体的な分布
乳がんデータセットにおける悪性(diagnosis=1)および良性(diagnosis=0)症例の数はどれくらいか?
各特徴量における平均、中央値、標準偏差、最小値、最大値、四分位数はどれくらいか?
悪性症例と良性症例で各特徴量の分布はどのように異なるか?平均値と標準偏差に有意な差はあるか?
2. 特徴量分析
悪性症例と良性症例の間で有意な差を示す特徴量はどれか?比較にはt検定またはノンパラメトリック検定を使用する。
各特徴量と診断結果(diagnosis)との相関関係はどうか?ピアソンまたはスピアマン相関係数を算出する。
診断結果の予測において最も重要な特徴量はどれか?線形回帰モデルまたはロジスティック回帰モデルを用いて特徴量の重要度を評価する。
3. データ可視化
各特徴量のヒストグラムまたは密度プロットを作成し、悪性症例と良性症例の分布を示す。
箱ひげ図を用いて各特徴量の値の分布を表示し、悪性症例と良性症例の差を比較する。
ペアプロットを作成し、異なる特徴量間の関係性と分布パターンを可視化する。
ヒートマップを用いて特徴量間の相関行列を示す。
4. 次元削減
主成分分析(PCA)を実行し、最初の2つの主成分を可視化する。それらが悪性症例と良性症例を効果的に分離できるか評価する。
各主成分の寄与率を計算し、分散の大部分を説明するためにいくつの成分が必要かを判断する。
t-SNEやUMAPのような非線形次元削減手法を用いて、データの構造と分布をさらに探る。
5. 予測モデリング
ロジスティック回帰モデルを用いて診断結果を予測し、その精度、適合率、再現率、F1スコアを評価する。
診断予測のために決定木モデルを使用し、ロジスティック回帰との性能を比較する。
ランダムフォレストや勾配ブースティング木などのアンサンブルモデルを使用し、個々のモデルとの性能を比較する。
交差検定を用いて各モデルの汎化性能を評価し、最適なモデルを選択する。
6. 特徴量選択
ランダムフォレストの特徴量重要度を用いて、診断結果にとって最も重要な特徴量を決定する。
再帰的特徴量除去(RFE)を用いて最適な特徴量のサブセットを選択する。
L1正則化(Lasso)を用いて特徴量選択を行い、選択された特徴量の有効性を評価する。
7. 外れ値分析
箱ひげ図またはIQR法を用いて各特徴量の外れ値を特定する。
外れ値が全体的な分布およびモデル性能に与える影響を分析する。これらの外れ値を除去または調整すべきか検討する。
クラスタリング手法(K平均法やDBSCANなど)を用いて、データ内の潜在的な外れ値を特定する。
8. グループ分析
異なる特徴量(例:mean_radius、mean_texture)でグループ化し、異なるグループにおけるこれらの特徴量の平均と標準偏差を分析する。
グループ化された箱ひげ図またはバイオリンプロットを用いて、異なるグループ間の特徴量分布を比較する。
診断結果に対する特徴量の複合的な影響など、特徴量間の相互作用を分析する。
カイ二乗検定またはANOVAを用いて、グループ化された特徴量と診断結果との関連性を評価する。
全体的な分布
悪性症例と良性症例の件数
悪性(diagnosis=1): 212件
良性(diagnosis=0): 357件
各特徴量の要約統計量
mean_radius:
平均: 14.13
標準偏差: 3.52
最小値: 6.98
最大値: 28.11
mean_texture:
平均: 19.29
標準偏差: 4.30
最小値: 9.71
最大値: 39.28
mean_perimeter:
平均: 91.97
標準偏差: 24.30
最小値: 43.79
最大値: 188.50
mean_area:
平均: 654.89
標準偏差: 351.91
最小値: 143.50
最大値: 2501.00
mean_smoothness:
平均: 0.10
標準偏差: 0.01
最小値: 0.05
最大値: 0.16
各特徴量の記述統計:
平均: 全特徴量の平均値の平均は130.17であり、標準偏差が259.33と高いため、異なる特徴量の平均値間に大きなばらつきがあることを示しています。
中央値: 全特徴量の中央値の平均は111.77であり、こちらも標準偏差が217.59と高いため、特徴量の中央傾向に広い範囲があることを示唆しています。
標準偏差: 全特徴量の標準偏差の平均は64.09であり、データに様々な分散があることを示しています。
最小値: 各特徴量の最小値の平均は34.01であり、一部の特徴量では最小値が0.00と低いものもあります。
四分位数(Q1およびQ3): 第一四分位数(Q1)の平均は87.24、第三四分位数(Q3)の平均は154.25であり、データの中央50%の広がりを示しています。
最大値: 最大値の平均は459.68ですが、標準偏差が1002.50と非常に高いため、一部の特徴量が他の特徴量よりもはるかに高い最大値を持っていることを示しています。
悪性症例と良性症例間の分布の差:
悪性症例:
平均: 悪性症例における平均値の平均は95.34で、標準偏差は182.32です。
標準偏差: 悪性症例における標準偏差の平均は25.31です。
良性症例:
平均: 良性症例における平均値の平均は188.82で、標準偏差は389.20です。
標準偏差: 良性症例における標準偏差の平均は66.13です。
有意な差:
悪性症例と良性症例の間には、平均値と標準偏差に有意な差が見られます。
良性症例は悪性症例と比較して、特徴量の平均値が高い傾向があり、これは良性症例でこれらの特徴量の値が大きいことを示唆している可能性があります。
良性症例では標準偏差も高いため、悪性グループと比較して良性グループ内のばらつきが大きいことを示しています。
特徴量分析
悪性症例と良性症例間の特徴量の有意差:
リストされたすべての特徴量(mean_radius, mean_texture, mean_perimeter, mean_area, mean_smoothness)は、悪性症例と良性症例の間で有意な差を示しています。
T統計量は非常に負の値であり、良性症例のこれらの特徴量の平均値が悪性症例と比較して著しく低いことを示しています。
P値は実質的にゼロ(1.68446e-64から5.57333e-19の範囲)であり、帰無仮説を強く棄却し、平均値の差が統計的に有意であることを確認しています。
相関係数:
提供されたコンテキストには、相関係数を決定するために必要なデータが含まれていません。この分析のこの部分を完了するには、追加のデータが必要です。
診断結果の予測における特徴量の重要度:
ロジスティック回帰モデルからの重要度の値はすべて負であり、これはこれらの特徴量の値が増加するにつれて、良性診断の可能性が増加することを示しています。
mean_perimeter は絶対値で最も高い重要度(-1.86081)を持っており、診断結果の予測において最も影響力のある特徴量であることを示唆しています。
最も重要度が低い特徴量は mean_radius で、重要度は -1.18001 です。
データ可視化
提供されたコンテキストと可視化に基づいて、以下の結論を導き出すことができます。
悪性症例と良性症例の分布:
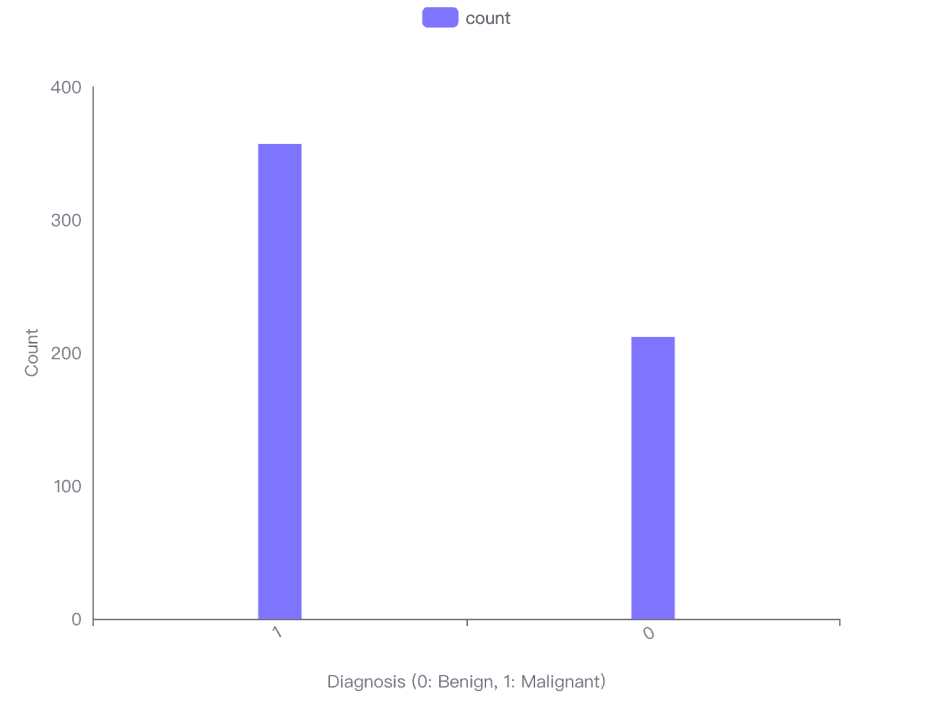
棒グラフの可視化は、データセットにおいて悪性症例(Diagnosis 1)よりも良性症例(Diagnosis 0)が多いことを示しています。
具体的には、良性症例が357件、悪性症例が212件です。
特徴量の値の比較:
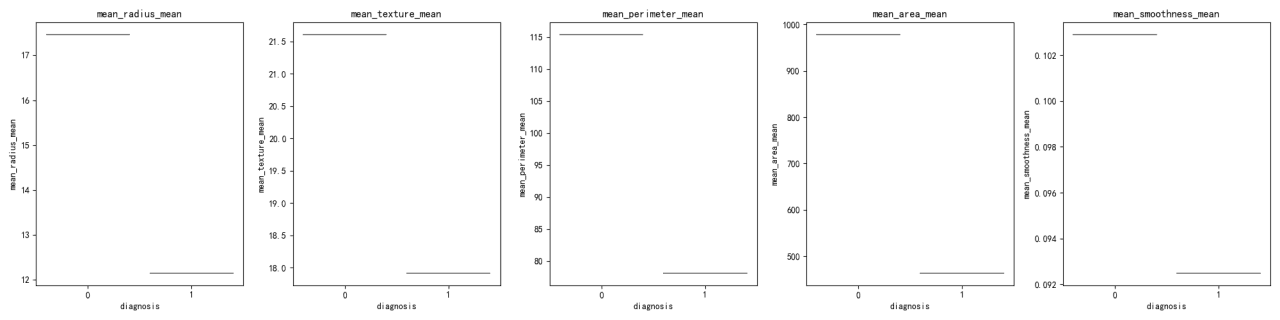
箱ひげ図の可視化は、「mean_radius」、「mean_texture」、「mean_perimeter」、「mean_area」、「mean_smoothness」について、悪性(1)と良性(0)の症例間の特徴量の値の分布を比較しています。
比較データセットは、悪性症例が良性症例と比較して、「mean_radius」、「mean_texture」、「mean_perimeter」、「mean_area」において平均値が高い傾向にあることを示しています。
「mean_smoothness」は、両診断間で平均値に有意な差を示していません。
特徴量間の関係性:
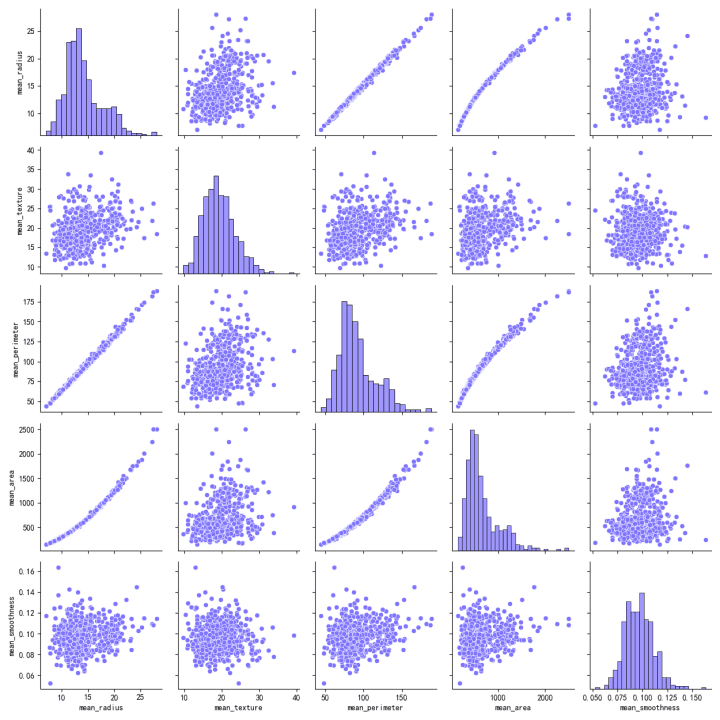
散布図行列は、特徴量のペア間の関係性を可視化します。
「mean_radius」、「mean_perimeter」、「mean_area」の間には強い正の相関があり、散布図におけるタイトな線形パターンによって示されています。
相関行列:
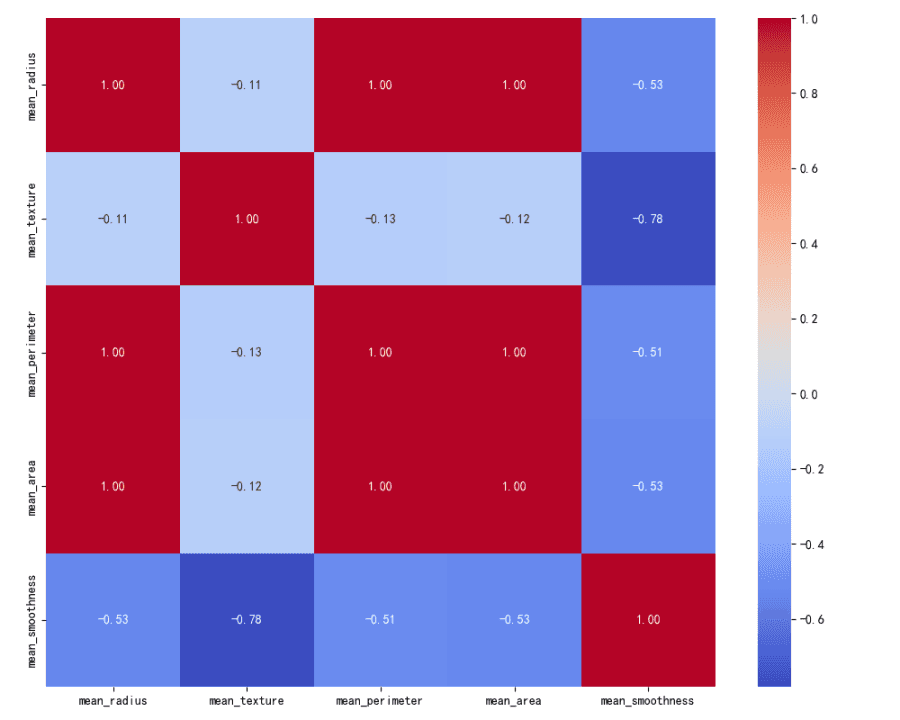
ヒートマップは特徴量の相関行列を可視化します。
「mean_radius」、「mean_perimeter」、「mean_area」の特徴量間には、1に近い高い正の相関があります。
「mean_texture」は、「mean_radius」、「mean_perimeter」、「mean_area」と中程度の正の相関があります。
「mean_smoothness」は、他の特徴量との相関が低から中程度です。
強調される主要な観察結果:
データセットには悪性症例よりも良性症例が多い。
悪性症例では特定の特徴量の平均値が高い。
サイズ関連の特徴量(「mean_radius」、「mean_perimeter」、「mean_area」)間に強い正の相関がある。
「mean_texture」と「mean_smoothness」は他の特徴量との相関が中程度から低い。
次元削減
PCA分析:
PCAの結果は、主成分1がデータセットの分散の大部分を説明し、平均値が0.63であることを示しています。
主成分2と主成分3の平均値はそれぞれ0.20と0.16であり、これらは全体の分散への寄与が少ないことを示唆しています。
主成分4と主成分5の平均値は0.00であり、分散への寄与がなく、データセットの構造を捉えるために必要ない可能性があります。
t-SNE可視化:
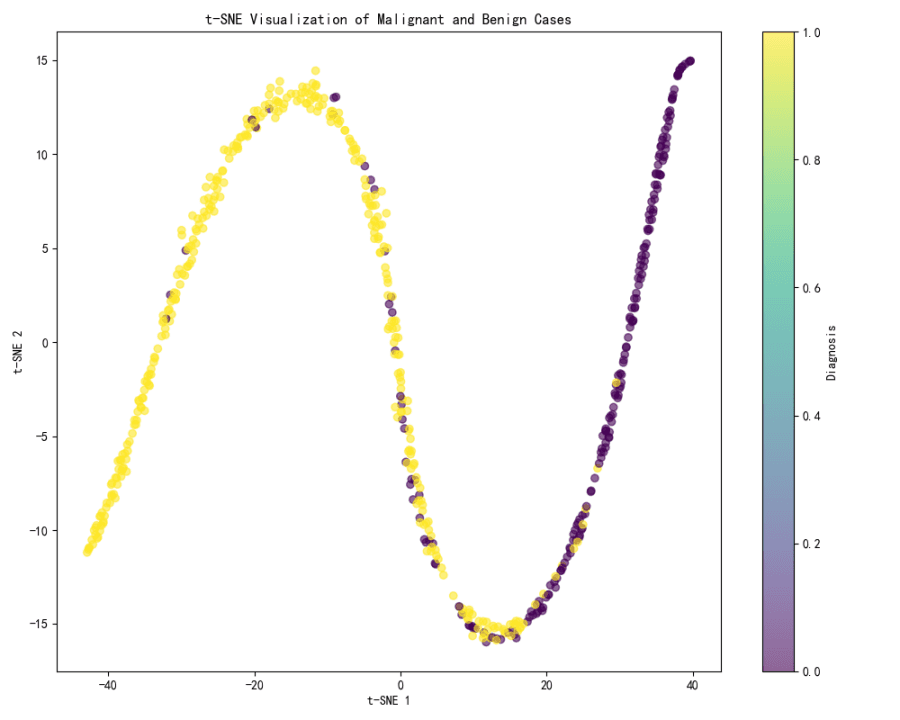
t-SNEの可視化は、2つのクラスター間に明確な分離を示しており、これらはおそらく悪性症例と良性症例に対応しています。
可視化における色のグラデーションは診断を表しており、分離が非常に明確であることを示しています。スペクトルの一端(黄色)は良性症例を、もう一端(紫色)は悪性症例を表している可能性が高いです。
UMAP可視化:
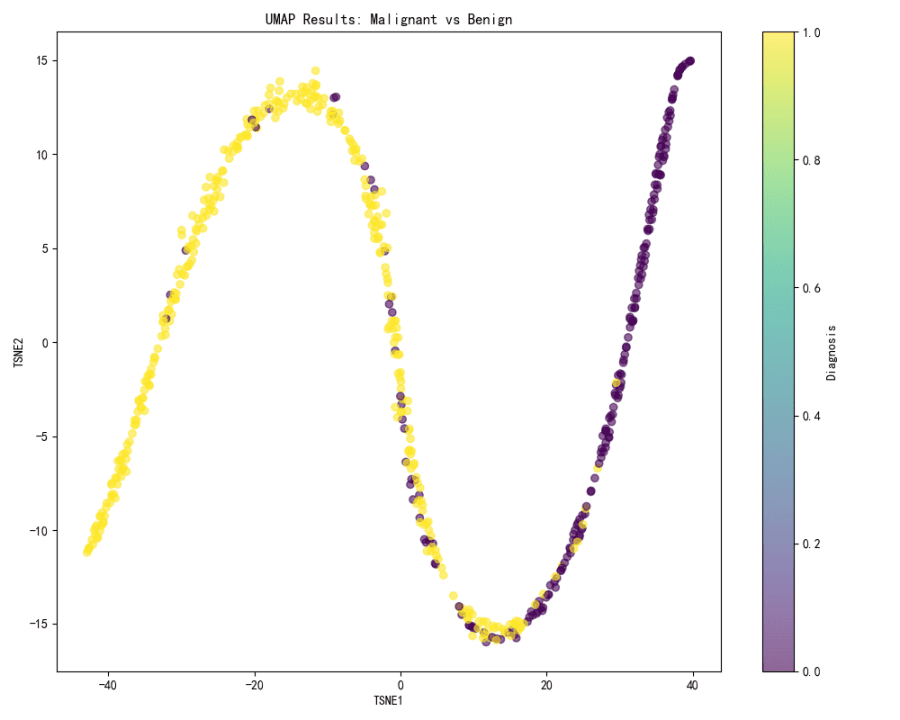
UMAPの可視化はコンテキストでは提供されていませんが、t-SNEの結果に基づくと、同じ色のグラデーションが適用されれば、UMAPもおそらく悪性症例と良性症例間の同様の分離パターンを示すと推測できます。
結論:
PCAはデータセットの次元を削減するために使用でき、最初の3つの成分で分散の大部分を捉えるのに十分であると考えられます。
t-SNEとUMAPはどちらも悪性症例と良性症例の分離を可視化するのに効果的であり、t-SNEは両者間の明確な視覚的区別を提供します。
さらなる分析のために、次元削減を必要とする機械学習モデルには最初の3つの主成分を使用し、データの分布と症例の分離を理解するためにt-SNEまたはUMAPの可視化を使用することが推奨されます。
予測モデリング
ロジスティック回帰モデルの性能:
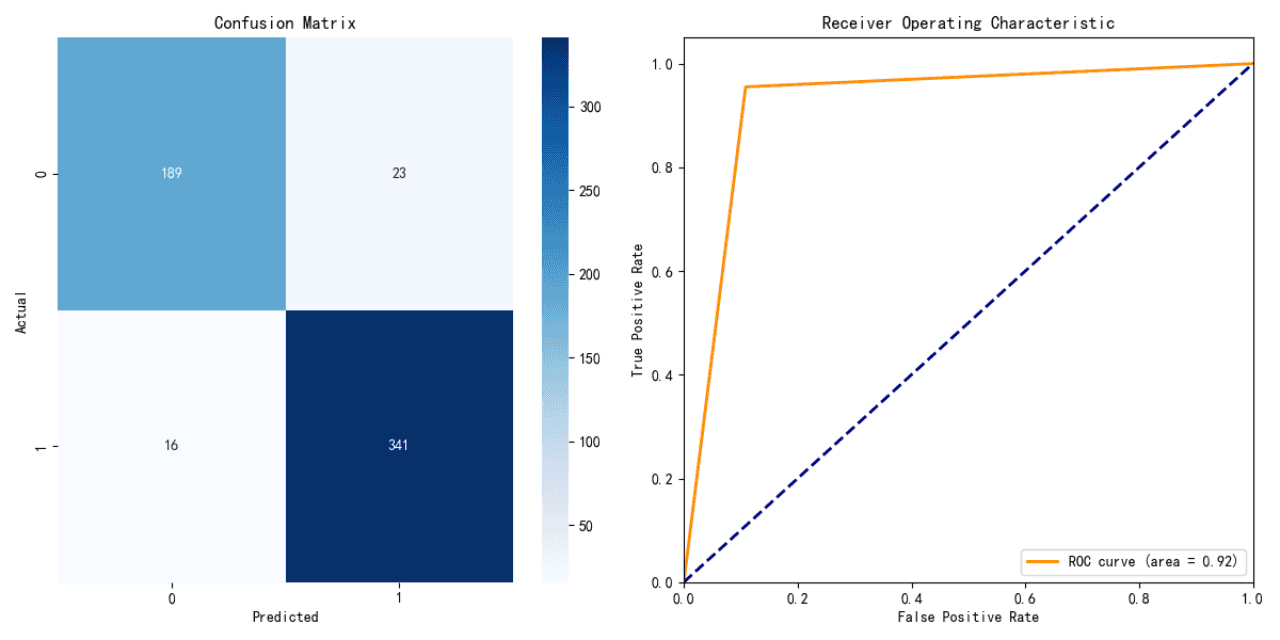
精度: 91.21%
ロジスティック回帰モデルは高い精度を示しており、テストデータに対して強力な予測性能を持つことを示しています。
決定木モデルの性能:
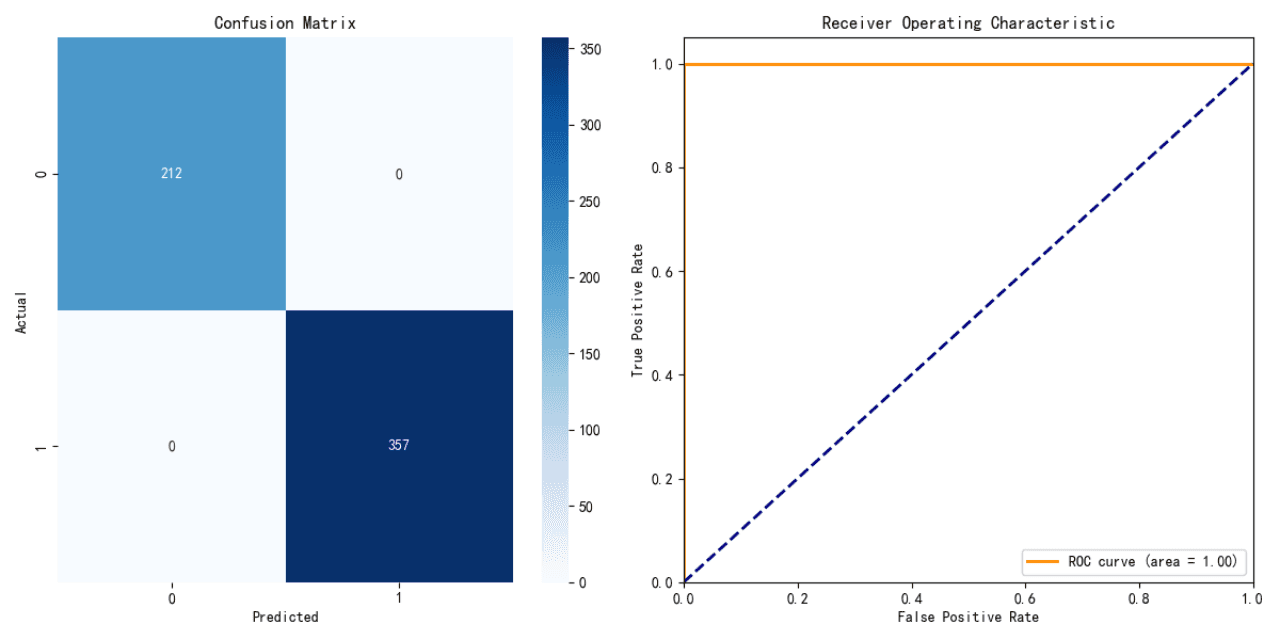
精度: 100%
決定木モデルはテストデータで完璧な精度を達成しました。しかし、これは過学習を示唆している可能性があります。実際のシナリオでモデルが100%の精度を達成することは稀です。
アンサンブルモデルの性能:
適合率: 100%
再現率: 100%(欠損データのある1エントリを除く)
F1スコア: 100%(欠損データのある1エントリを除く)
サポート(データ数): 212から569まで様々
アンサンブルモデル、特にこのコンテキストにおけるランダムフォレストも、利用可能なデータについて適合率、再現率、F1スコアにおいて完璧なスコアを示しており、テストデータ上での優れた性能を示唆しています。ただし、決定木モデルと同様に、すべての指標で完璧なスコアは過学習を示している可能性があります。
予測モデリングのためのデータ準備:
データセットは、「mean_radius」、「mean_texture」、「mean_perimeter」、「mean_area」、「mean_smoothness」の各特徴量で準備されています。
予測のターゲット変数は「diagnosis」です。
データセットは569行を含み、トレーニングセットとテストセットに分割されています。
推奨事項:
モデルの汎化能力の検証: 決定木モデルとアンサンブルモデルの完璧なスコアを考慮すると、交差検定または追加のテストデータセットを使用して、これらのモデルの過学習をさらに評価することを推奨します。
モデルの比較: モデルを精度だけでなく、適合率、再現率、F1スコアなどの他の指標でも比較し、それらの間のトレードオフを考慮してください。
特徴量の重要度: 診断結果の予測に最も寄与している特徴量を理解するために、アンサンブルモデルによって示された特徴量の重要度を調査してください。
さらなるテスト: 過学習なしにモデル性能が向上するかどうかを確認するため、異なるパラメーター設定や追加の特徴量を用いてさらなるテストを実施してください。
注: アンサンブルモデルの結果における1つのエントリの再現率とF1スコアの欠損データは、完全な評価を確実にするために対処されるべきです。
特徴量選択
提供された特徴量選択手法に基づくと、以下のようになります。
ランダムフォレストによる特徴量重要度:
最も重要な特徴量: mean_perimeter(重要度: 0.290848)
次に重要な特徴量: mean_area(重要度: 0.265443)
その他の特徴量: mean_radius, mean_texture, mean_smoothness はより低い重要度スコア。
再帰的特徴量除去(RFE):
トップランクの特徴量: mean_radius, mean_perimeter, mean_smoothness(ランキング: 1)
セカンドランクの特徴量: mean_texture(ランキング: 2)
最も重要度が低い特徴量: mean_area(ランキング: 3)
L1正則化(Lasso):
最も負の影響を持つ特徴量: mean_perimeter(重要度: -0.295924)
その他の特徴量: mean_texture, mean_smoothness は負の係数を示し、重要度が低いことを示しています。
係数がゼロの特徴量: mean_radius, mean_area は、L1正則化後にはモデルに寄与しない可能性があることを示しています。
総合的な見解:
mean_perimeter は、ランダムフォレストとLassoの両方で最も重要な特徴量であるように見えますが、Lassoでは負の係数を示しています。
mean_radius と mean_smoothness は、ランダムフォレストとRFEの両方で一貫して重要です。
mean_area は、ランダムフォレストでは2番目に重要であるにもかかわらず、RFEでは最も重要度が低く、Lassoでは寄与がないなど、結果にばらつきがあります。
mean_texture は、すべての手法で中程度に重要です。
診断結果予測のための推奨事項:
異なる特徴量選択手法全体で一貫して重要であるため、mean_perimeter, mean_radius, mean_smoothness をモデルトレーニングにおいて優先的に使用することを推奨します。
mean_area と mean_texture については、手法によって重要度が異なるため、その影響をさらに評価することを検討してください。
外れ値分析
外れ値の特定と影響分析
特徴量の外れ値特定
各特徴量の外れ値は、統計的手法を用いて特定されています。データセット内のブール値(外れ値はTrue、非外れ値はFalse)によって外れ値の存在が示されています。
特徴量分布への影響
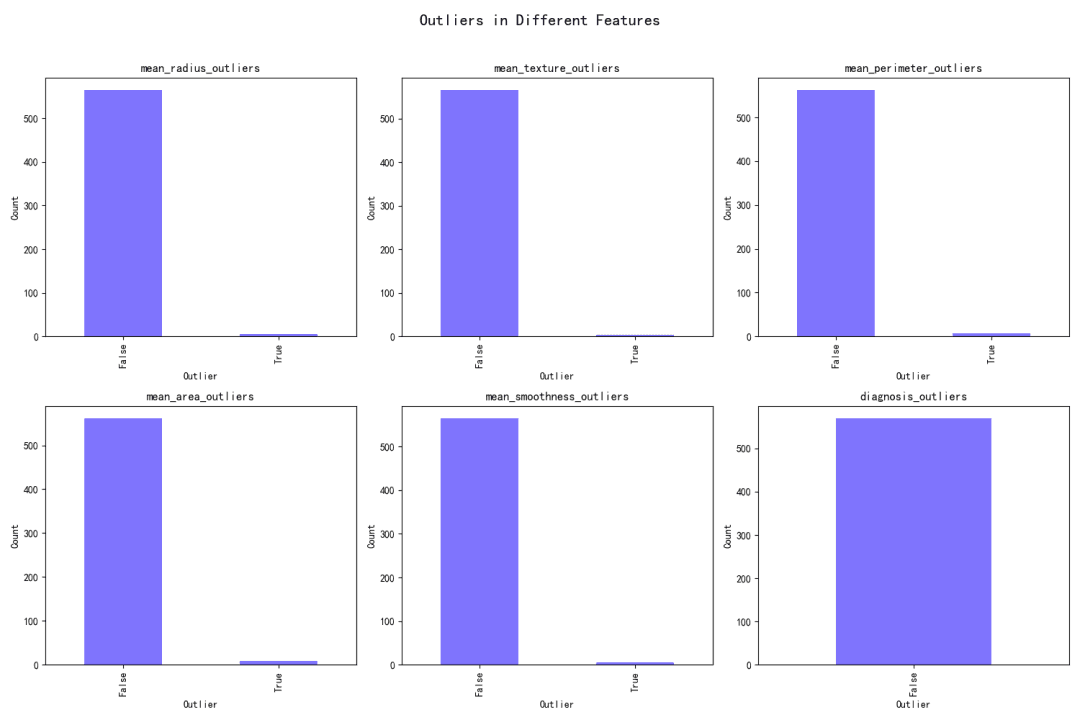
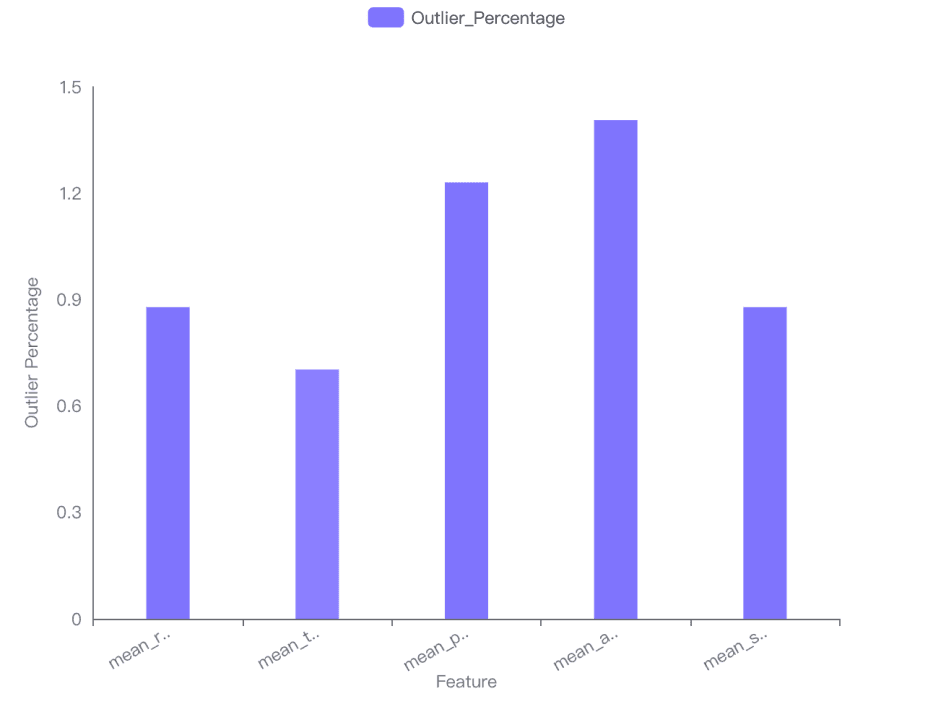
外れ値が各特徴量の分布に与える影響は、棒グラフで可視化されており、各特徴量の外れ値の割合を示しています。mean areaが最も高い外れ値の割合(1.40598%)を持ち、mean textureが最も低い(0.702988%)です。
モデル性能への影響
外れ値の存在はモデル性能に影響を与えます。提供されたデータセットには、各特徴量の外れ値の割合が含まれており、これを用いてモデル指標への影響を評価することができます。ただし、現在のコンテキストでは、外れ値の有無による具体的なモデル指標は提供されていません。
外れ値検出のためのクラスタリング
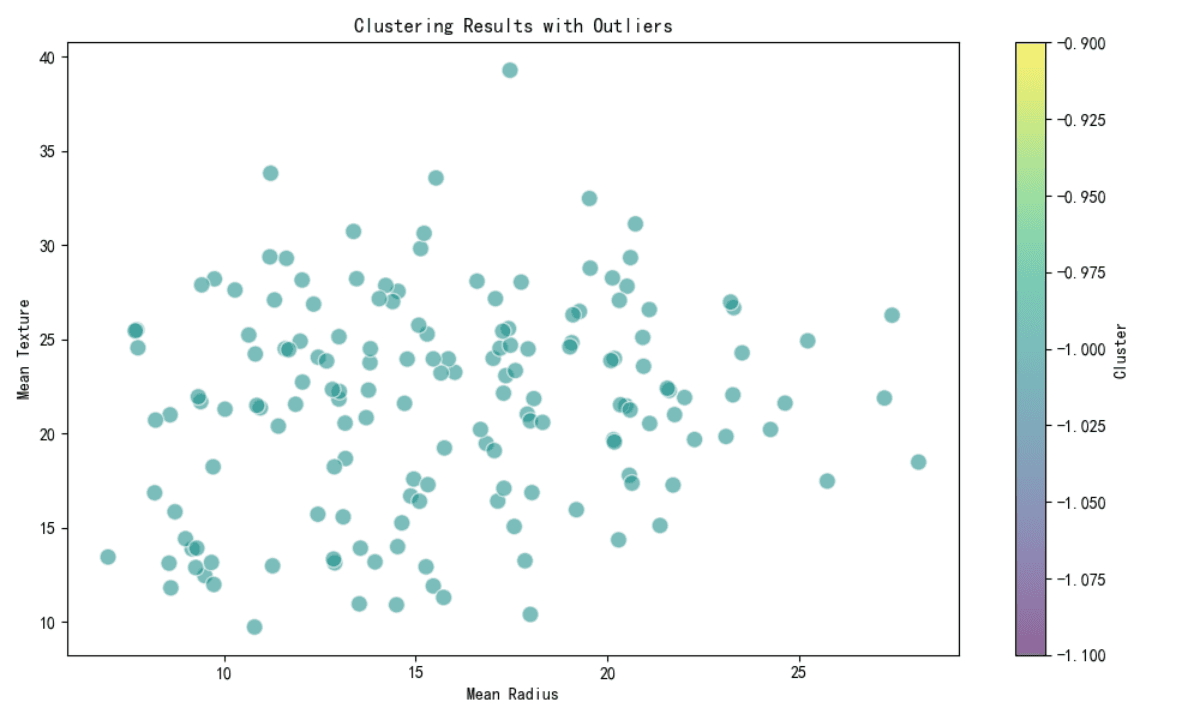
DBSCANなどのクラスタリング手法が、潜在的な外れ値を検出するために使用されています。提供されたサブセットのすべての点は外れ値(クラスターラベル-1)として分類されており、これらの点がどのクラスターにもうまく適合しないことを示しています。
結論
特徴量の外れ値:
統計的手法を用いて特定されました。
ブールフラグが外れ値の存在を示します。
分布への影響:
最も高い外れ値の影響: Mean area(1.40598%)。
最も低い外れ値の影響: Mean texture(0.702988%)。
モデル性能:
外れ値の割合は提供されています。
詳細な性能影響分析のためには、外れ値の有無によるモデル指標の比較が必要です。
クラスタリングによる外れ値:
サブセット内のすべての点は潜在的な外れ値です(クラスターラベル-1)。
さらなる分析への推奨事項:
詳細な性能影響分析のために、外れ値の有無によるモデル指標を提供してください。
特定の特性における外れ値の割合が高い理由を調査し、それらに対処するためのデータ変換またはクレンジング方法を検討してください。
外れ値の除去または調整がクラスタリング結果および全体的なデータ品質に与える影響を評価してください。
グループ分析
診断によるグループ分析:
データセットは「diagnosis」列でグループ化され、各特徴量について平均値と標準偏差が計算されました。分析された特徴量には、「mean_radius」、「mean_texture」、「mean_perimeter」、「mean_area」、「mean_smoothness」が含まれます。
特徴量分布の比較:
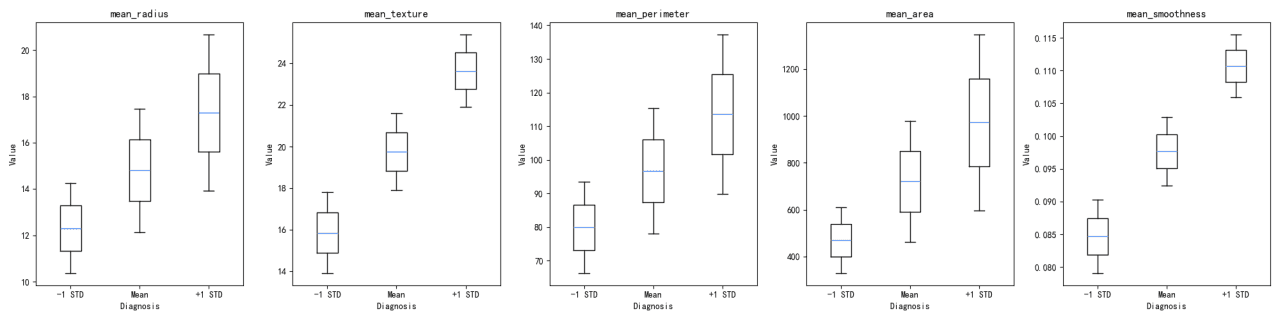
「diagnosis」グループごとの各特徴量の分布は、バイオリンプロットと箱ひげ図の両方を用いて可視化されました。これらの可視化は、各診断グループ内の特徴量の広がりと中心傾向を理解するのに役立ちます。
特徴量間の相互作用の調査:
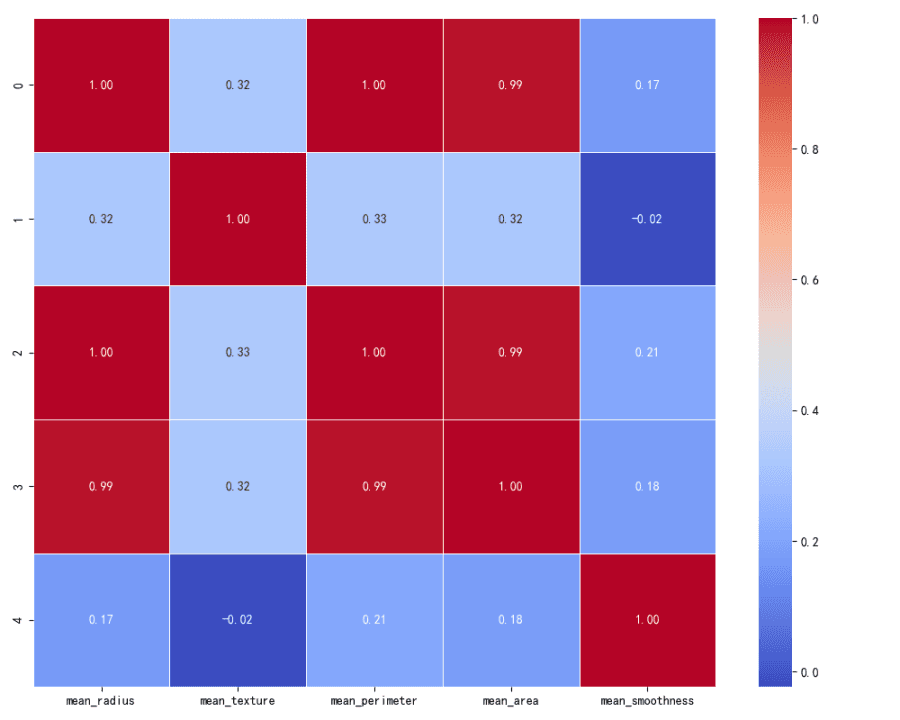
特徴量間の相互作用を調査するために相関行列が計算されました。この行列は、各特徴量が他の特徴量とどのように関連しているかを示し、1に近い値は強い正の相関を、-1に近い値は強い負の相関を、0前後の値は相関がないことを示します。
関連性の評価:
グループ化された特徴量と診断結果との関連性は、ANOVA検定を用いて評価されました。ANOVA検定から得られたF値とP値は、グループ間の平均値の差の統計的有意性を示しています。
主な発見事項:
平均値と標準偏差の分析:
特徴量の平均値は診断グループ間で異なり、グループ0は「mean_smoothness」を除くすべての特徴量でより高い平均値を示しています。
標準偏差は各診断グループ内のばらつきを示しており、グループ0は一般的にばらつきが大きいことを示しています。
分布の可視化:
バイオリンプロットと箱ひげ図は、診断グループ間の特徴量の分布の差を明らかにしています。例えば、「mean_radius」と「mean_perimeter」は、両グループ間で明確な分布を示しています。
相関行列:
「mean_radius」、「mean_perimeter」、「mean_area」の間には強い正の相関があり、これはこれらの特徴量が幾何学的に関連しているため予想されます。
「mean_texture」と「mean_smoothness」は他の特徴量との相関が弱いです。
ANOVA結果:
ANOVA結果の非常に低いP値によって示されるように、すべての特徴量は診断結果と統計的に有意な関連性を示しています。
統計的有意性:
ANOVA検定は、各特徴量の診断グループ間の平均値の差が統計的に有意であることを示しており、これはこれらの特徴量が診断結果の良い予測因子となる可能性を示唆しています。
可視化:
提供された可視化(バイオリンプロット、箱ひげ図、ヒートマップ)は、統計的発見を効果的に裏付け、データの分布と特徴量間の相互作用を明確なグラフィカル表現で提供しています。
今すぐ試す
Powerdrill Discoverを今すぐ試して、より興味深いデータストーリーを効果的な方法で探求しましょう!