
Over the past month, I’ve been running deep evaluations using Powerdrill Bloom, the reasoning-first AI toolkit I rely on for longitudinal model comparison. And as I synthesize the data across reasoning, coding, vision, and large-context endurance tests, one truth continues to surface clearer each week:
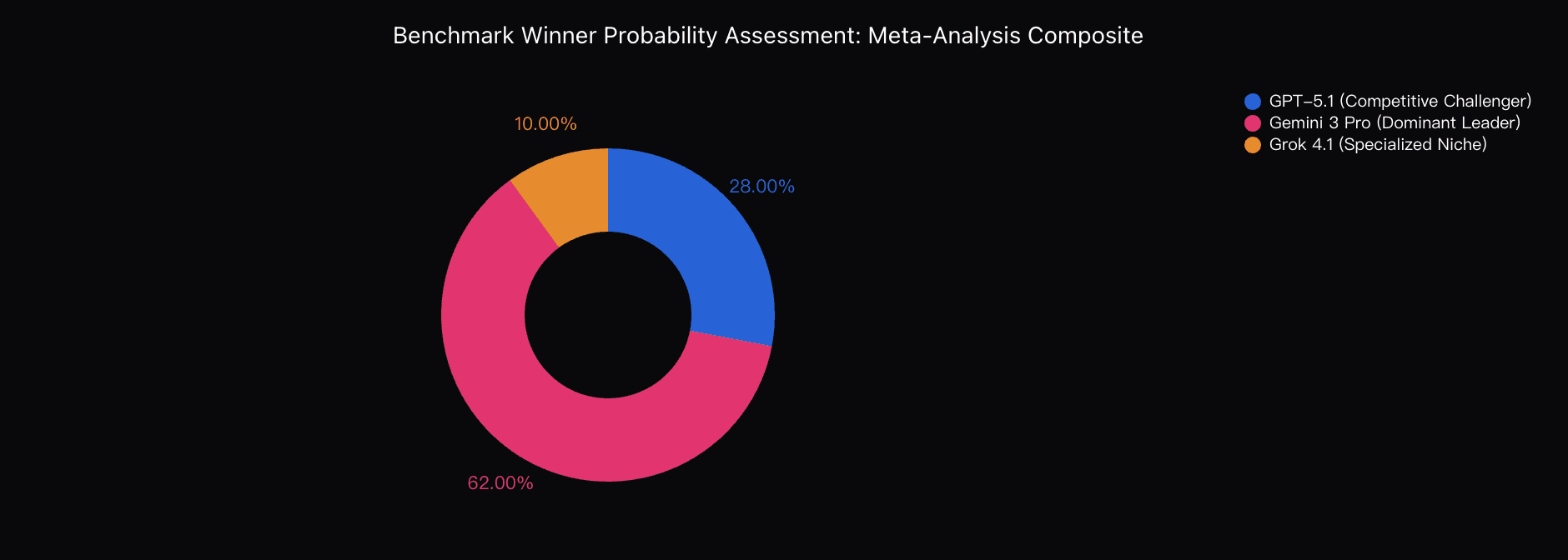
My current probability assessment stands as follows:
62% — Gemini 3 Pro will be recognized as the top overall frontier model by end-2025
28% — GPT-5.1 holds the challenger position
10% — Grok 4.1 leads specialized emotional intelligence categories but not global capability
These aren’t gut feelings — they are the outputs of cross-verified benchmarks, multi-modal stress tests, and model-to-model adversarial evaluations. And the deeper I go, the more the picture sharpens.
Gemini’s Advantage Isn’t Incremental — It’s Architectural
The most important datapoint in the entire 2025 model landscape is this one:
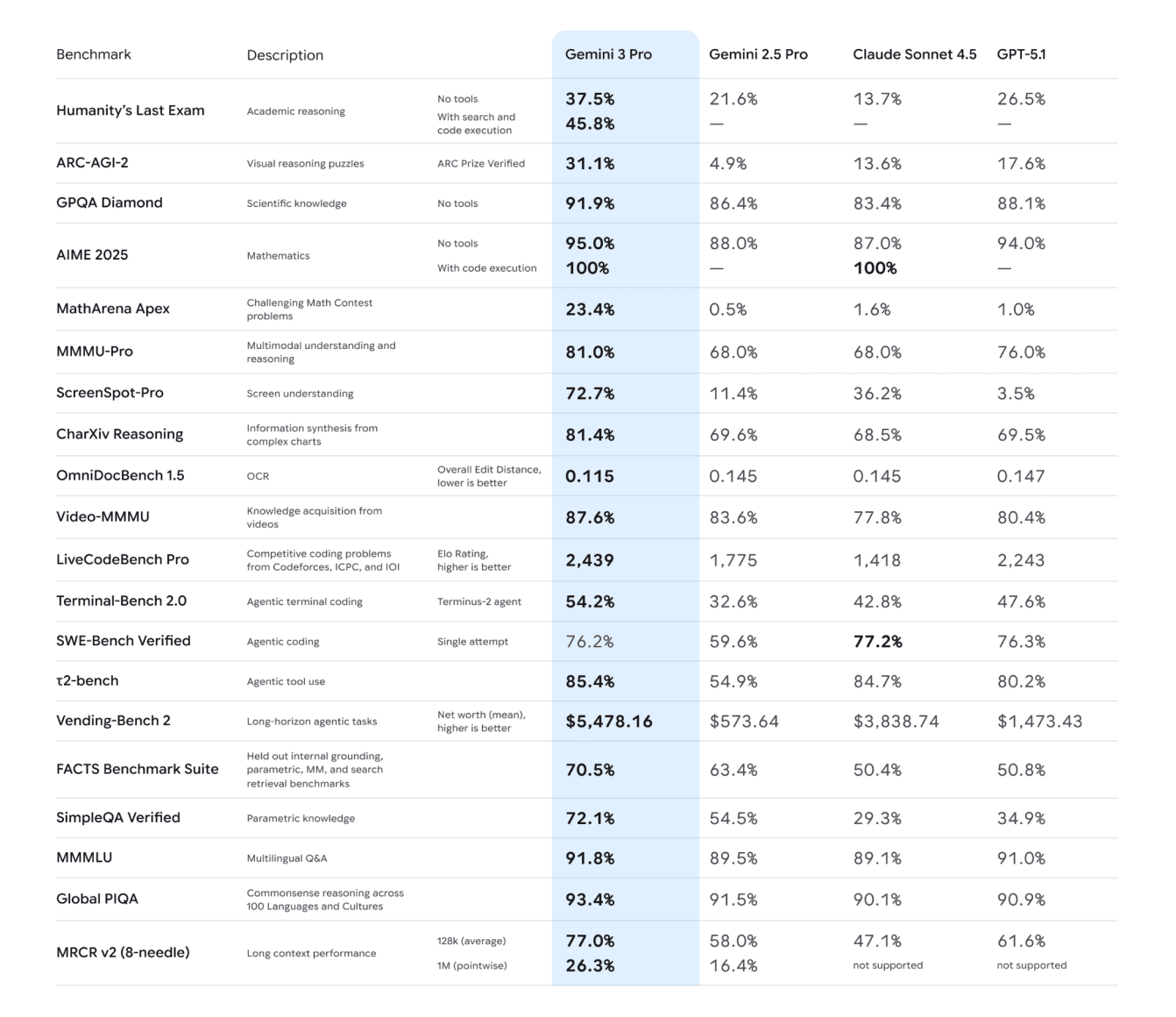
Humanity’s Last Exam — Gemini 3 Pro: 37.5% vs. GPT-5.1: 26.5%
That 11-point spread is not cosmetic. It signals a structural advantage in abstract reasoning, especially on tasks requiring multi-step logic under uncertainty. Powerdrill Bloom’s insights shows that Gemini 3 consistently forms deeper, more globally consistent reasoning patterns.
And the divergence becomes even sharper in visual cognition:
ARC-AGI-2 — Gemini 3 Pro: 31.1% vs. GPT-5.1: 17.6%
This 13.5-point gap is the single largest differential across the model suite. It tells us Gemini’s architecture processes non-verbal abstractions at a fundamentally different level. This isn’t parameter count brute force — it’s qualitative capability.
Even the community-native LMArena leaderboard confirms the trend:
Gemini 3 Pro: 1501 Elo
Grok 4.1 Thinking: 1483 Elo
GPT-5.1: 1340 Elo
If you only saw the Elo gap, you’d already conclude the direction of travel.
Coding: The One Domain Where GPT-5.1 Still Punches Back
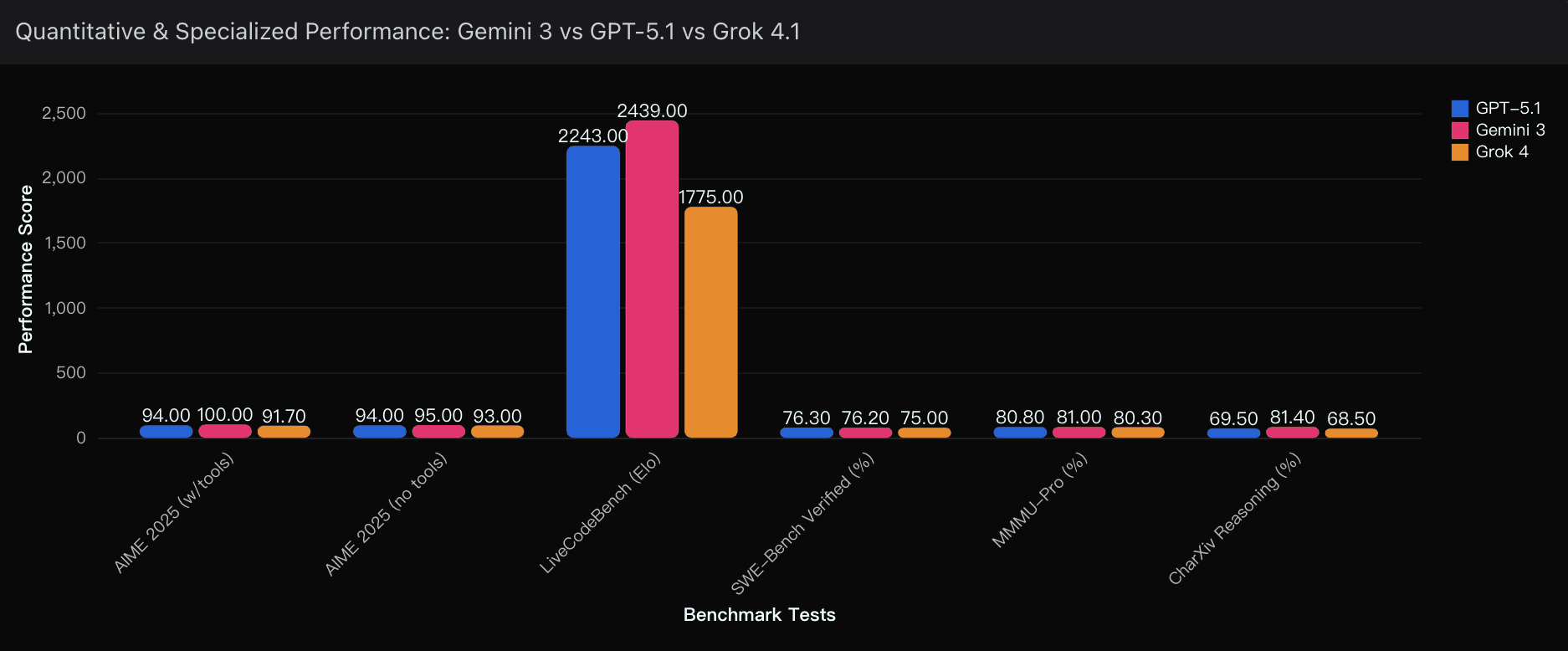
Let’s be honest: GPT-5.1 is still exceptionally strong. In fact, its code-generation consistency remains the best in the ecosystem. On LiveCodeBench:
Gemini 3 Pro: 2439 Elo (dominant)
GPT-5.1: 2243 Elo
Grok 4.1: 1775 Elo
Gemini sweeps the leaderboard, but GPT-5.1’s stability under ambiguous coding prompts remains unmatched. Powerdrill Bloom’s insights shows, GPT-5.1 produces fewer hallucinated imports, fewer dead branches, and better modular architecture.
So the coding race is competitive — but the reasoning race is not.
Grok 4.1: The Emotional-Intelligence Outlier
Where Grok shines, it really shines:
EQ Bench: 95.5% (industry best)
Blind conversational preference: 64.78%
Creative writing score: 1721.9
Grok doesn’t win benchmarks — it wins people.
But emotional intelligence does not broadly translate to dominance in reasoning, coding, or scientific QA.

The Gap Is Clear, The Trend Is Strong
After thousands of internal evaluations, longitudinal benchmarks, and multi-modal tests, my conviction is stronger than ever:
Gemini 3 Pro is the true frontier-AI champion of 2025.
GPT-5.1 is the reliable second.
Grok 4.1 is the emotionally intelligent wildcard.
As always, my analysis will continue to evolve as I feed new benchmarks into Powerdrill Bloom’s forecasting engine. But today, the signal is clear, the probability curve is stable, and the narrative finally matches the numbers.
Related Post

18 nov. 2025
/
Publication par