Predicción de relaciones para la completación del grafo de conocimiento utilizando grandes modelos de lenguaje

Tema Central
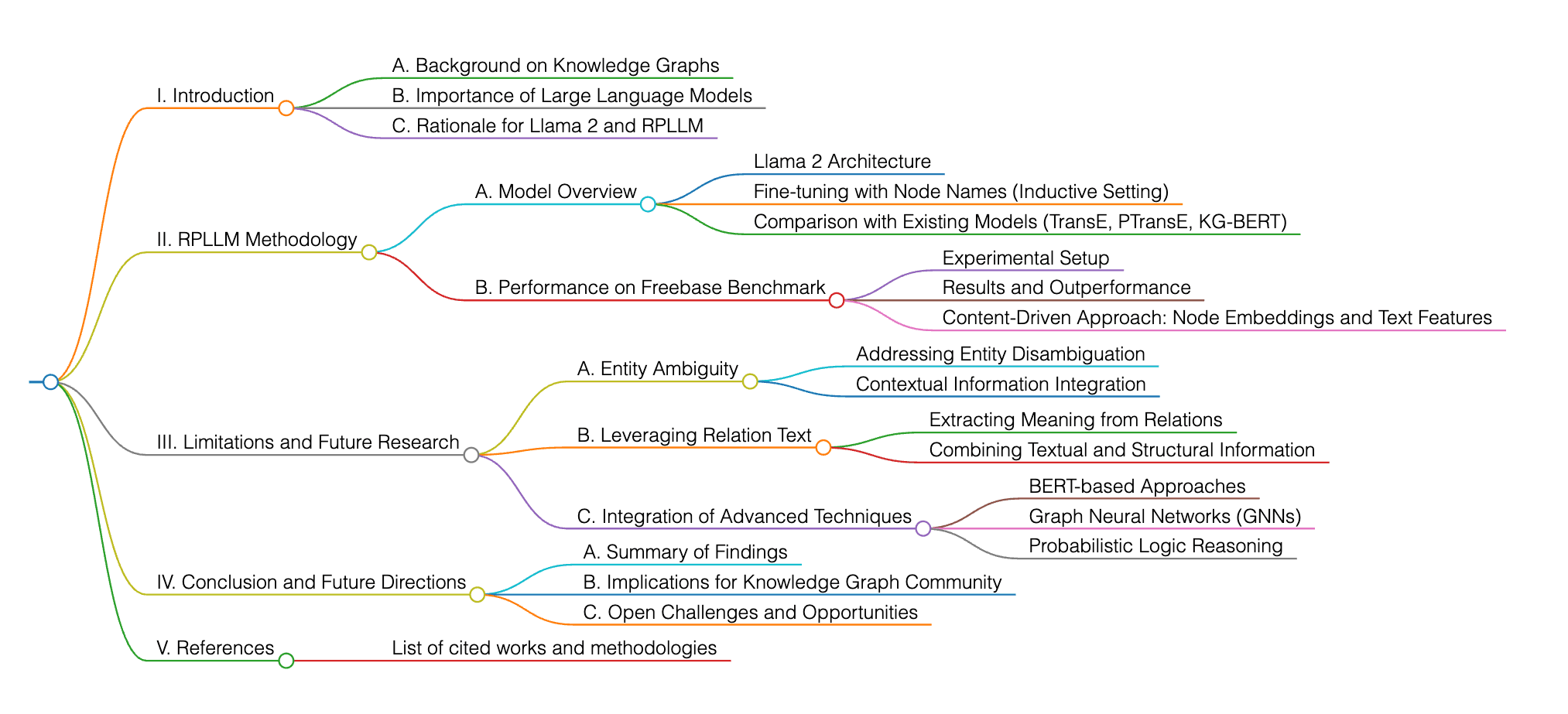
El documento explora el uso de modelos de lenguaje grandes, especialmente Llama 2, para completar grafos de conocimiento, centrándose en tareas de predicción de relaciones. Introduce RPLLM, que ajusta el modelo con nombres de nodos para manejar configuraciones inductivas y supera a modelos existentes como TransE, PTransE y KG-BERT en el estándar de Freebase. El estudio destaca el potencial de enfoques impulsados por contenido, utilizando incrustaciones de nodos y características de texto, para mejorar la precisión de los grafos de conocimiento. El trabajo futuro sugiere abordar las limitaciones, como la ambigüedad de entidades y el uso de texto de relaciones, para mejorar aún más el rendimiento. El campo está en constante evolución, con investigaciones que incorporan diversas técnicas como BERT, Redes Neuronales de Grafos y razonamiento lógico probabilístico.
Mapa Mental
Resumen
¿Qué problema intenta resolver el documento? ¿Es este un problema nuevo?
El documento tiene como objetivo abordar el problema de ambigüedad de entidades en la investigación de Compleción de Grafos de Conocimiento (KGC). Este problema ha llevado a bajas clasificaciones en las evaluaciones de modelos y afecta el rendimiento de los modelos actuales. Si bien no es un problema nuevo, el documento sugiere direcciones de investigación futuras para explorar cómo aprovechar el texto de relaciones en la capacitación de tríos y utilizar descripciones de entidades para mejorar los resultados con una carga computacional mínima.
¿Qué hipótesis científica busca validar este documento?
El documento tiene como objetivo validar la hipótesis de que los modelos actuales, incluido el que se presenta, demuestran un rendimiento de vanguardia en las tareas de predicción de relaciones, como lo evidencian los informes de clasificación de predicciones consistentemente altos y las mejoras incrementales de nuevos estudios.
¿Qué nuevas ideas, métodos o modelos propone el documento? ¿Cuáles son las características y ventajas en comparación con métodos anteriores?
El documento introduce la utilización de Modelos de Lenguaje Grandes (LLMs) para completar grafos de conocimiento, empleando específicamente Llama 2 para la clasificación multi-etiqueta de secuencias en tareas de predicción de relaciones, logrando nuevos puntajes de referencia en Freebase y puntajes equivalentes en WordNet. Además, sugiere aprovechar descripciones de entidades y texto de relaciones en la capacitación de tríos, explorar técnicas de muestreo negativo e introducir nuevos grafos de conocimiento de evaluación para escenarios de predicción de relaciones más sofisticados. Estoy feliz de ayudar con su pregunta. Sin embargo, necesito información o contexto más específico sobre el documento al que se refiere para proporcionar un análisis detallado. Proporcione el título del documento, el autor o un breve resumen del contenido para poder ayudarlo mejor.
El enfoque del documento se destaca debido a su uso de LLMs, especialmente Llama 2, para tareas de predicción de relaciones basadas en texto, demostrando un rendimiento competitivo tanto en grafos de conocimiento de FreeBase como de WordNet. En comparación con métodos anteriores, el modelo demuestra un rendimiento de vanguardia con clasificaciones de predicciones consistentemente altas y mejoras menores de nuevos estudios. Además, el documento sugiere aprovechar descripciones de entidades y texto de relaciones en la capacitación de tríos, explorar técnicas de muestreo negativo e introducir nuevos grafos de conocimiento de evaluación para escenarios de predicción de relaciones más sofisticados.
¿Existen investigaciones relacionadas? ¿Quiénes son los investigadores destacados en este campo? ¿Cuál es la clave para la solución mencionada en el documento?
La investigación actual en el campo de la Compleción de Grafos de Conocimiento (KGC) ha mostrado avances significativos, con un rendimiento de vanguardia demostrado por varios modelos. Investigadores destacados en esta área incluyen a Alqaaidi y Kochut, entre otros. La clave para la solución mencionada en el documento radica en utilizar nombres de entidades como entrada para el LLM, lo que implica la tokenización del texto y la codificación de los tokens en IDs numéricos. Este enfoque garantiza una implementación simple y altamente efectiva del modelo, mejorando su rendimiento en las tareas de predicción de relaciones.
¿Cómo se diseñaron los experimentos en el documento?
Los experimentos en el documento se diseñaron para evaluar el rendimiento del modelo en dos estándares ampliamente reconocidos, FreeBase y WordNet. El modelo fue ajustado utilizando el modelo Llama 2 preentrenado con 7 mil millones de parámetros para la tarea de predicción de relaciones. La configuración experimental involucró la utilización de muestreo negativo en la tarea LP para mejorar la diversidad de los datos de entrenamiento, pero el muestreo negativo no se incorporó en la tarea RP debido a diferencias fundamentales en la metodología de asignación de etiquetas. Además, se utilizó el tokenizador Llama 2 con una longitud de relleno de 50 para las secuencias de texto de las entidades, y el modelo fue ajustado utilizando el algoritmo de optimización Adam con una tasa de aprendizaje de 5e-5.
¿Cuál es el conjunto de datos utilizado para la evaluación cuantitativa? ¿Es el código de código abierto?
El conjunto de datos utilizado para la evaluación cuantitativa incluye FreeBase y WordNet. El código para el modelo no se menciona explícitamente como de código abierto en los contextos proporcionados.
¿Los experimentos y resultados en el documento proporcionan un buen apoyo para las hipótesis científicas que necesitan ser verificadas? Analice.
Los experimentos y resultados presentados en el documento ofrecen un apoyo sustancial para las hipótesis científicas que requieren verificación. El estudio demuestra la efectividad del modelo a través de evaluaciones en estándares bien establecidos, FreeBase y WordNet, mostrando el rendimiento y las capacidades del modelo. Los resultados indican un rendimiento de vanguardia y mejoras en las tareas de predicción de relaciones, validando las hipótesis planteadas en la investigación. Para proporcionar un análisis preciso, necesitaría información más específica sobre el documento, como el título, autores, pregunta de investigación, metodología y hallazgos clave. Esta información me ayudará a evaluar la calidad de los experimentos y resultados en relación con las hipótesis científicas que se están probando. No dude en proporcionar más detalles para que pueda ayudarlo más.
¿Cuáles son las contribuciones de este documento?
El documento realiza contribuciones significativas al exhibir un rendimiento de vanguardia en las clasificaciones de predicción y sugerir direcciones de investigación potenciales para tareas de predicción de entidades. Además, introduce la aplicación de técnicas de muestreo negativo para la tarea de RP, lo que podría mejorar el rendimiento del modelo.
¿Qué trabajo puede continuar en profundidad?
La investigación futura en el campo de la Compleción de Grafos de Conocimiento (KGC) podría centrarse en abordar el problema de ambigüedad de entidades, como se destaca en el estudio. Este problema llevó a clasificaciones más bajas en la evaluación del modelo, lo que indica un área potencial de mejora. Los investigadores podrían explorar cómo aprovechar el texto de relaciones en la capacitación de tríos y utilizar descripciones de entidades para mejorar los resultados con una carga computacional mínima adicional. Además, la introducción de nuevos escenarios de evaluación en grafos de conocimiento podría enriquecer la literatura y avanzar en técnicas de predicción de relaciones.
Conocer Más
El resumen anterior fue generado automáticamente por Powerdrill.
Haga clic en el enlace para ver la página de resumen y otros documentos recomendados.