Redefiniendo la Recuperación de Información de Bases de Datos Estructuradas a través de Modelos de Lenguaje Grandes

Tema Central
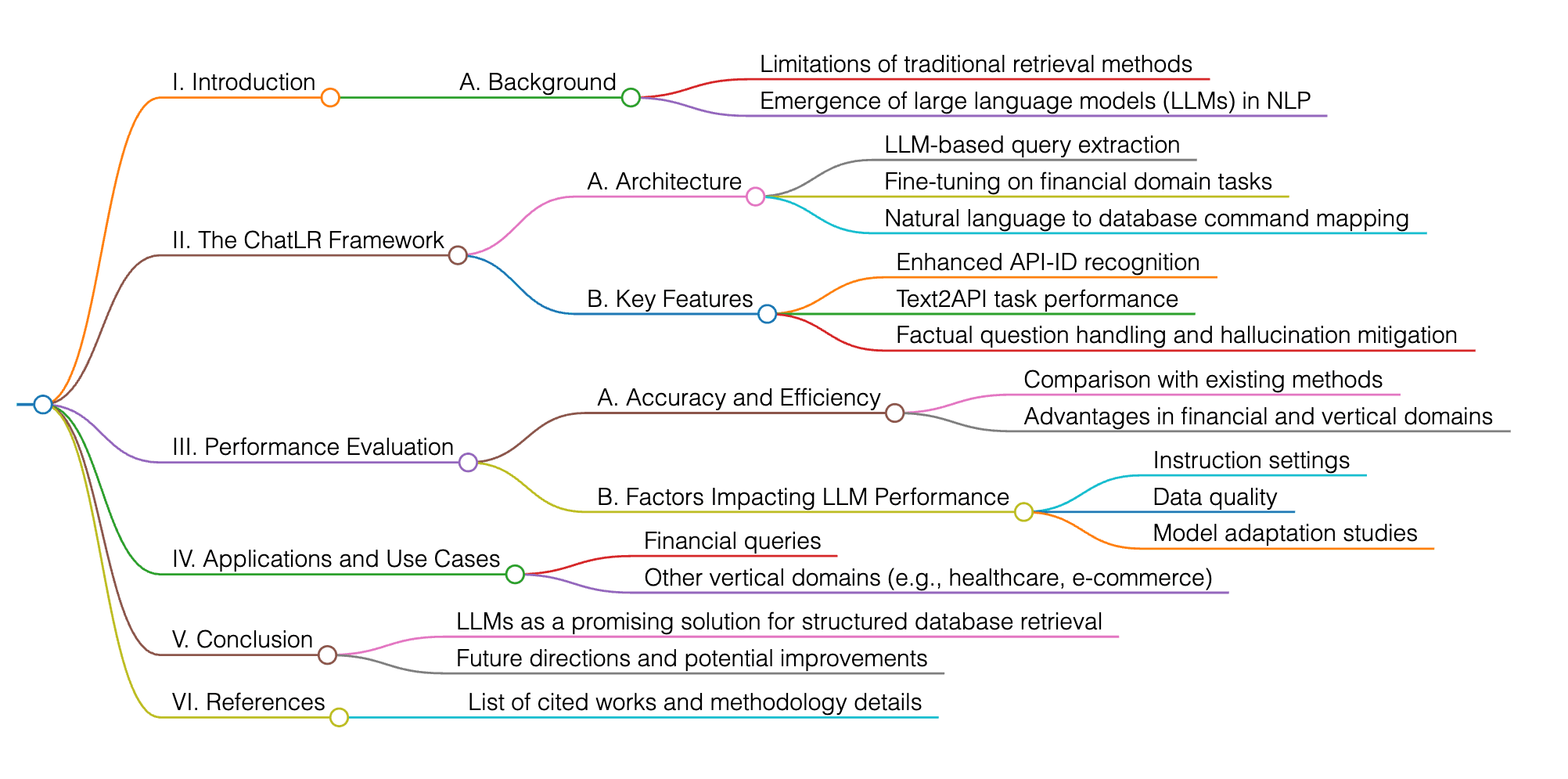
El documento presenta ChatLR, un marco de augmentación de recuperación que mejora la recuperación de información en bases de datos estructuradas utilizando modelos de lenguaje grandes (LLMs). Aborda las limitaciones de los métodos tradicionales aprovechando los LLMs para la extracción precisa de consultas y el ajuste fino en tareas del dominio financiero. ChatLR supera los métodos existentes con alta precisión, particularmente en el reconocimiento de API-ID y las tareas de Text2API, mejorando los LLMs para preguntas fácticas y mitigando problemas de alucinación. El marco se centra en mapear consultas en lenguaje natural a comandos de base de datos precisos, mejorando la precisión y eficiencia en dominios financieros y otros verticales. Los estudios también exploran el impacto de las configuraciones de instrucción, la calidad de los datos y la adaptación del modelo en el rendimiento de los LLM en varias NLP tareas.
Mapa Mental
Resumen
¿Qué problema intenta resolver el documento? ¿Es este un problema nuevo?
El documento aborda los desafíos asociados con los Modelos de Lenguaje Grandes (LLMs), particularmente sus limitaciones para incorporar conocimientos actualizados y la tendencia a generar respuestas fácticamente inexactas, conocido como el "problema de alucinación". Este problema no es nuevo y ha persistido en varios escenarios que involucran LLMs.
¿Qué hipótesis científica busca validar este documento?
Este documento busca validar la hipótesis de que utilizar un nuevo marco de augmentación de recuperación llamado ChatLR, que emplea principalmente la poderosa capacidad de comprensión semántica de los Modelos de Lenguaje Grandes (LLMs) como recuperadores, puede lograr una recuperación de información precisa y concisa, especialmente en el dominio financiero.
¿Qué nuevas ideas, métodos o modelos propone el documento? ¿Cuáles son las características y ventajas en comparación con métodos anteriores?
El documento introduce un nuevo marco de augmentación de recuperación llamado ChatLR, que aprovecha los Modelos de Lenguaje Grandes (LLMs) como recuperadores para mejorar la precisión de recuperación de información. Este marco utiliza principalmente la capacidad de comprensión semántica de los LLMs para lograr una recuperación de información precisa y concisa. Además, el documento presenta un sistema de búsqueda y respuesta a preguntas basado en LLM adaptado para el dominio financiero mediante el ajuste fino en tareas como el reconocimiento de API-ID y Text2API, mostrando la efectividad de ChatLR al abordar consultas de usuarios con una precisión general que supera el 98.8%.
El marco ChatLR ofrece varias ventajas clave sobre los métodos anteriores. En primer lugar, aborda el "problema de alucinación" comúnmente encontrado en los Modelos de Lenguaje Grandes (LLMs) al incorporar técnicas de Generación Aumentada por Recuperación (RAG), que reducen significativamente la generación de respuestas fácticamente inexactas. Además, ChatLR demuestra un rendimiento superior en precisión, con una mejora notable del 62.6% en el reconocimiento de API-ID y casi el 83.6% en tareas de Text2API en comparación con los LLMs independientes después del ajuste fino. Esta mayor precisión se atribuye al meticuloso proceso de generación de datos y la integración de bases de datos estructuradas específicas del dominio financiero, asegurando la relevancia y precisión de la información recuperada. Además, la capacidad de ChatLR para adaptarse a diferentes dominios verticales y escenarios mediante el ajuste fino de instrucciones e incorporación de varios ejemplos completos de salida de datos mejora su utilidad práctica en aplicaciones del mundo real.
¿Existen investigaciones relacionadas? ¿Quiénes son los investigadores destacados en este tema en este campo? ¿Cuál es la clave para la solución mencionada en el documento?
En el campo de la augmentación de recuperación y la recuperación de información utilizando Modelos de Lenguaje Grandes (LLMs), hay investigadores notables como Mingzhu Wang, Yuzhe Zhang, Qihang Zhao, Juanyi Yang y Hong Zhang. Estos investigadores han contribuido al desarrollo de marcos como ChatLR, que aprovechan los LLMs para una recuperación de información precisa y concisa en bases de datos estructuradas.
La clave para la solución mencionada en el documento implica el concepto de Generación Aumentada por Recuperación (RAG). Este enfoque mejora los LLMs incorporando conocimiento externo recuperado de un corpus para guiar el proceso de razonamiento durante la generación. Al combinar el conocimiento recuperado con la consulta, los LLMs están mejor equipados para proporcionar respuestas precisas a preguntas fácticas, superando las limitaciones asociadas con la dependencia exclusiva del conocimiento parametrizado almacenado dentro del modelo.
¿Cómo se diseñaron los experimentos en el documento?
Los experimentos en el documento se diseñaron realizando un ajuste fino en varios Modelos de Lenguaje de última generación (LLMs) preentrenados en chino utilizando un conjunto de datos etiquetado de 10,000 artículos de noticias en chino. Los resultados experimentales mostraron que todos los modelos exhibieron una alta capacidad de alineación de etiquetas después del ajuste fino, con Chinese-Alpaca demostrando las puntuaciones Rouge más altas en el conjunto de prueba. El proceso de ajuste fino implicó optimizar el tiempo de entrenamiento y el uso de memoria al emplear una técnica de ajuste fino altamente eficiente llamada LoRA y ajustar simultáneamente el modelo para las tareas de reconocimiento de API-ID y Text2API en un conjunto de datos que comprende un total de 70,000 instancias.
¿Cuál es el conjunto de datos utilizado para la evaluación cuantitativa? ¿El código es de código abierto?
El conjunto de datos utilizado para la evaluación cuantitativa no se menciona explícitamente en los contextos proporcionados. Sin embargo, el código utilizado para la evaluación es de código abierto, como se indica en la mención del ajuste fino del marco ChatLR y la obtención de una mayor precisión en los conjuntos de prueba.
¿Los experimentos y resultados en el documento proporcionan un buen apoyo a las hipótesis científicas que necesitan ser verificadas? Por favor, analice.
Los experimentos y resultados presentados en el documento proporcionan un fuerte apoyo a las hipótesis científicas que necesitan ser verificadas. El estudio llevó a cabo experimentos de ajuste fino en varios Modelos de Lenguaje Grandes (LLMs) de última generación para tareas de resumen de texto en chino. Los resultados demostraron una alta capacidad de alineación de etiquetas después del ajuste fino, con el modelo Chinese-Alpaca mostrando las puntuaciones Rouge más altas en el conjunto de prueba. Además, el modelo ChatLR, basado en el modelo fundamental Chinese-Alpaca, mostró una precisión general de recuperación de información que supera el 98.8%. Estos hallazgos indican una alineación exitosa con las hipótesis científicas y validan la efectividad del marco propuesto para abordar consultas de usuarios.
¿Cuáles son las contribuciones de este documento?
El documento introduce un nuevo marco de augmentación de recuperación llamado Recuperación de LLM con Chat (ChatLR) que aprovecha los LLM para operaciones de recuperación, diseñado específicamente para consultas fácticas en bases de datos estructuradas, mejorando significativamente la precisión en la recuperación de conocimiento relacionado con las consultas. El marco logra una búsqueda precisa y eficiente de información relevante dentro de bases de datos estructuradas al mapear consultas en lenguaje natural a comandos de búsqueda de base de datos precisos, permitiendo una fácil generalización a varios dominios verticales mediante la modificación del contenido relevante.
¿Qué trabajo puede continuarse en profundidad?
Se puede realizar un trabajo adicional para ampliar las categorías de tipos de bases de datos compatibles e investigar un enfoque integrativo para unificar tareas de consulta de bases de datos estructuradas y no estructuradas para optimizar la utilización del conocimiento externo de bases de datos en preguntas basadas en conocimiento fáctico.
Leer Más
El resumen anterior fue generado automáticamente por Powerdrill.
Haga clic en el enlace para ver la página de resumen y otros documentos recomendados.