Datos: Análisis Integral de las Tendencias de Diagnóstico de Cáncer de Mama y la Importancia de las Características

Este conjunto de datos captura las tendencias y dinámicas del diagnóstico de cáncer de mama, incluyendo información detallada sobre la distribución de casos malignos y benignos, análisis de características, visualización de datos y modelado predictivo.
Con el análisis de estos datos de cáncer de mama en Powerdrill, echemos un vistazo a las ideas clave y tendencias en el diagnóstico y la importancia de las características para predecir los resultados del cáncer de mama.
Dado el conjunto de datos, Powerdrill detecta y analiza los metadatos, y luego plantea estas indagaciones relevantes:
1. Distribución General
¿Cuáles son los recuentos de casos malignos (diagnóstico=1) y benignos (diagnóstico=0) en el conjunto de datos de cáncer de mama?
¿Cuáles son la media, mediana, desviación estándar, mínimo, máximo y cuartiles para cada característica?
¿Cómo difieren las distribuciones de cada característica entre casos malignos y benignos? ¿Existen diferencias significativas en sus medias y desviaciones estándar?
2. Análisis de Características
¿Qué características muestran diferencias significativas entre casos malignos y benignos? Utilice pruebas t o pruebas no paramétricas para la comparación.
¿Cuál es la correlación entre cada característica y el resultado del diagnóstico (diagnóstico)? Calcule los coeficientes de correlación de Pearson o Spearman.
¿Qué características son más importantes para predecir el resultado del diagnóstico? Evalúe la importancia de las características utilizando modelos de regresión lineal o regresión logística.
3. Visualización de Datos
Trace histogramas o gráficos de densidad para cada característica que muestren la distribución de casos malignos y benignos.
Utilice diagramas de caja para mostrar la distribución de valores de cada característica y comparar las diferencias entre casos malignos y benignos.
Cree gráficos de pares para visualizar relaciones y patrones de distribución entre diferentes características.
Utilice mapas de calor para mostrar la matriz de correlación entre características.
4. Reducción de Dimensionalidad
Realice un Análisis de Componentes Principales (PCA) y visualice los dos primeros componentes principales. Evalúe si separan efectivamente los casos malignos y benignos.
Calcule la proporción de varianza explicada para cada componente principal para determinar cuántos componentes son necesarios para explicar la mayor parte de la varianza.
Utilice técnicas de reducción de dimensionalidad no lineales como t-SNE o UMAP para explorar más a fondo la estructura y distribución de los datos.
5. Modelado Predictivo
Utilice modelos de regresión logística para predecir el resultado del diagnóstico y evalúe su precisión, precisión, recuperación y F1-score.
Intente utilizar modelos de árbol de decisión para la predicción del diagnóstico y compare su rendimiento con la regresión logística.
Utilice modelos de conjunto como bosques aleatorios o árboles de impulso de gradiente y compare su rendimiento con modelos individuales.
Evalúe la capacidad de generalización de cada modelo utilizando validación cruzada para seleccionar el mejor modelo.
6. Selección de Características
Utilice la importancia de características del bosque aleatorio para determinar qué características son más importantes para el resultado del diagnóstico.
Utilice la Eliminación Recursiva de Características (RFE) para seleccionar el subconjunto óptimo de características.
Utilice la regularización L1 (Lasso) para la selección de características y evalúe la efectividad de las características seleccionadas.
7. Análisis de Outliers
Identifique outliers en cada característica utilizando diagramas de caja o el método IQR.
Analice el impacto de los outliers en la distribución general y el rendimiento del modelo. Considere si debe eliminar o ajustar estos outliers.
Utilice métodos de clustering (como K-means o DBSCAN) para identificar posibles outliers en los datos.
8. Análisis de Grupos
Agrupe por diferentes características (por ejemplo, mean_radius, mean_texture) y analice la media y la desviación estándar de estas características en diferentes grupos.
Utilice diagramas de caja agrupados o gráficos de violín para comparar las distribuciones de características entre diferentes grupos.
Analice la interacción entre características, como el efecto combinado de características en el resultado del diagnóstico.
Utilice pruebas de chi-cuadrado o ANOVA para evaluar la asociación entre las características agrupadas y el resultado del diagnóstico.
Distribución General
Recuentos de Casos Malignos y Benignos
Maligno (diagnóstico=1): 212 casos
Benigno (diagnóstico=0): 357 casos
Estadísticas Resumen para Cada Característica
mean_radius:
Media: 14.13
Std: 3.52
Mín: 6.98
Máx: 28.11
mean_texture:
Media: 19.29
Std: 4.30
Mín: 9.71
Máx: 39.28
mean_perimeter:
Media: 91.97
Std: 24.30
Mín: 43.79
Máx: 188.50
mean_area:
Media: 654.89
Std: 351.91
Mín: 143.50
Máx: 2501.00
mean_smoothness:
Media: 0.10
Std: 0.01
Mín: 0.05
Máx: 0.16
Estadísticas Descriptivas para Cada Característica:
Media: El valor promedio en todas las características es 130.17 con una alta desviación estándar de 259.33, lo que indica una variabilidad significativa entre las medias de diferentes características.
Mediana: El valor mediano en las características es 111.77, también con una alta desviación estándar (217.59), lo que sugiere un amplio rango en la tendencia central de las características.
Desviación Estándar: La media de la desviación estándar en las características es 64.09, lo que indica una variación diversa en los datos.
Mínimo: El promedio de los valores mínimos para las características es 34.01, con algunas características teniendo un mínimo tan bajo como 0.00.
Cuartiles (Q1 y Q3): El primer cuartil (Q1) tiene un promedio de 87.24, y el tercer cuartil (Q3) tiene un promedio de 154.25, indicando la dispersión del 50% medio de los datos.
Máximo: El promedio de los valores máximos es 459.68, pero la desviación estándar es bastante alta (1002.50), mostrando que algunas características tienen valores máximos mucho más altos que otras.
Diferencias en las Distribuciones entre Casos Malignos y Benignos:
Casos Malignos:
Media: El promedio para casos malignos es 95.34 con una desviación estándar de 182.32.
Desviación Estándar: El promedio de la desviación estándar para casos malignos es 25.31.
Casos Benignos:
Media: El promedio para casos benignos es 188.82 con una desviación estándar de 389.20.
Desviación Estándar: El promedio de la desviación estándar para casos benignos es 66.13.
Diferencias Significativas:
Existen diferencias significativas en las medias y desviaciones estándar entre casos malignos y benignos.
Los casos benignos tienen una media más alta para las características en comparación con los casos malignos, lo que podría indicar valores más grandes de estas características en los casos benignos.
La desviación estándar también es más alta en los casos benignos, sugiriendo más variabilidad dentro del grupo benigno comparado con el grupo maligno.
Análisis de Características
Diferencias Significativas en las Características entre Casos Malignos y Benignos:
Todas las características enumeradas (mean_radius, mean_texture, mean_perimeter, mean_area, mean_smoothness) exhiben diferencias significativas entre casos malignos y benignos.
Los T-Statistics son altamente negativos, indicando que las medias de estas características son significativamente más bajas en los casos benignos en comparación con los malignos.
Los P-Values son prácticamente cero (rango de 1.68446e-64 a 5.57333e-19), lo que rechaza fuertemente la hipótesis nula, confirmando que las diferencias en las medias son estadísticamente significativas.
Coeficientes de Correlación:
El contexto proporcionado no contiene los datos necesarios para determinar los coeficientes de correlación. Se requiere información adicional para completar esta parte del análisis.
Importancia de las Características en la Predicción del Resultado del Diagnóstico:
Los valores de importancia del modelo de regresión logística son todos negativos, lo que indica que, a medida que aumenta el valor de estas características, la probabilidad de un diagnóstico benigno aumenta.
mean_perimeter tiene el valor de importancia absoluta más alto (-1.86081), lo que sugiere que es la característica más influyente en la predicción del resultado del diagnóstico.
La característica con menos importancia es mean_radius con un valor de importancia de -1.18001.
Visualización de Datos
Con base en el contexto y las visualizaciones proporcionadas, se pueden extraer las siguientes conclusiones:
Distribución de Casos Malignos y Benignos:
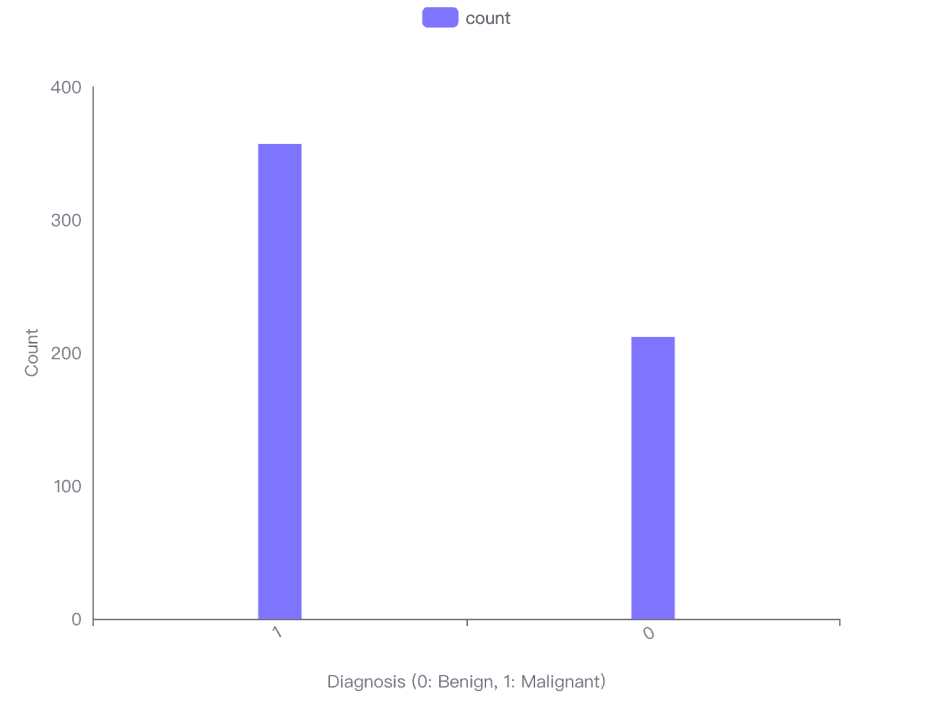
La visualización del gráfico de barras indica que hay más casos benignos (Diagnóstico 0) que casos malignos (Diagnóstico 1) en el conjunto de datos.
Específicamente, hay 357 casos benignos y 212 casos malignos.
Comparación de Valores de Características:
La visualización del diagrama de caja compara la distribución de valores de características entre casos malignos (1) y benignos (0) para 'mean_radius', 'mean_texture', 'mean_perimeter', 'mean_area', y 'mean_smoothness'.
El conjunto de datos para la comparación muestra que los casos malignos tienen tendencia a tener valores medios más altos para 'mean_radius', 'mean_texture', 'mean_perimeter', y 'mean_area' en comparación con los casos benignos.
'mean_smoothness' no muestra una diferencia significativa en los valores medios entre los dos diagnósticos.
Relaciones Entre Características:
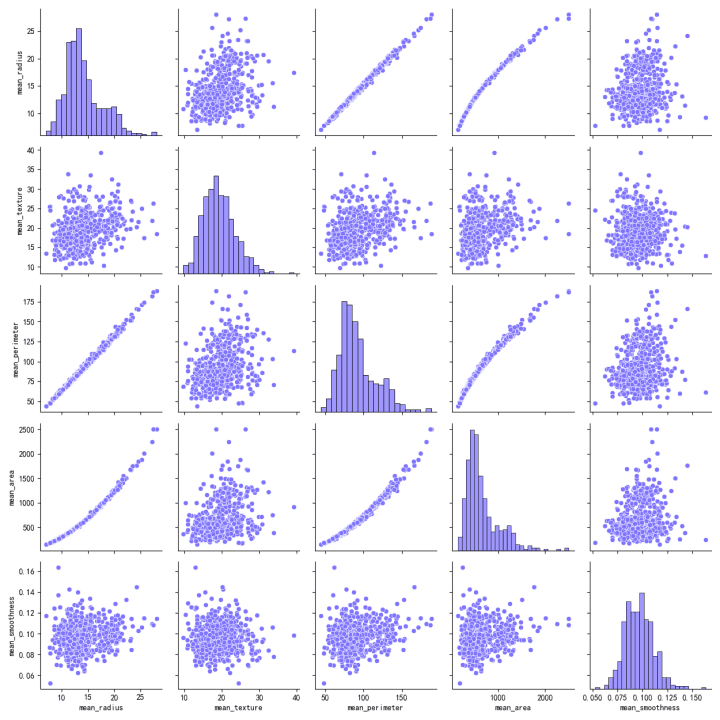
La matriz de gráficos de dispersión visualiza las relaciones entre pares de características.
Hay una fuerte correlación positiva entre 'mean_radius', 'mean_perimeter' y 'mean_area', como lo indican los patrones lineales ajustados en los gráficos de dispersión.
Matriz de Correlación:
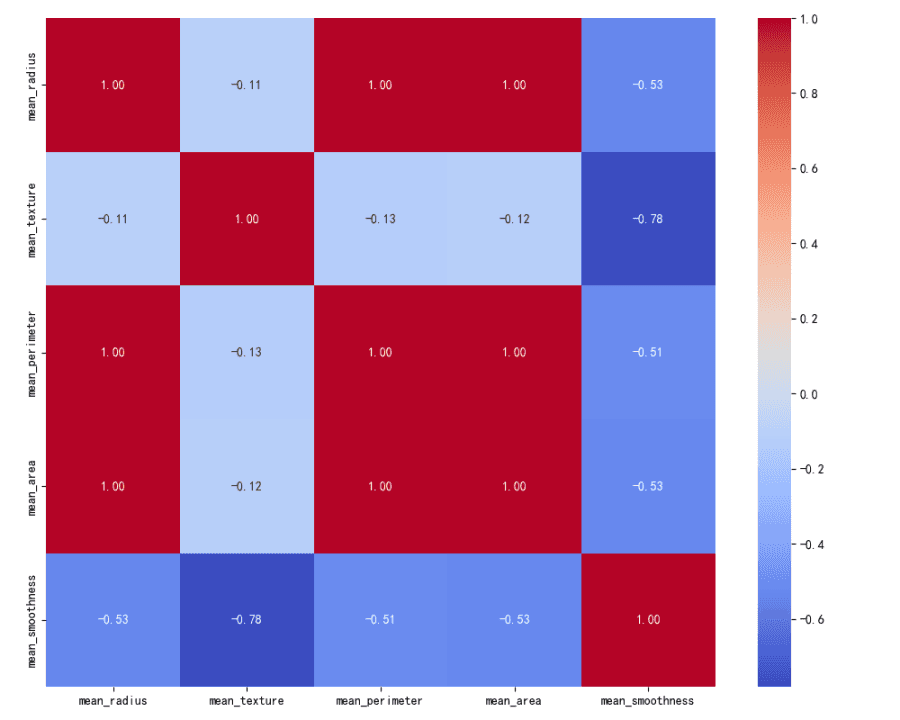
El mapa de calor visualiza la matriz de correlación para las características.
Las características 'mean_radius', 'mean_perimeter' y 'mean_area' tienen altas correlaciones positivas entre sí, cercanas a 1.
'mean_texture' tiene una correlación positiva moderada con 'mean_radius', 'mean_perimeter' y 'mean_area'.
'mean_smoothness' tiene una baja a moderada correlación positiva con las otras características.
Observaciones Clave Enfatizadas:
Más casos benignos que malignos en el conjunto de datos.
Valores medios más altos para ciertas características en casos malignos.
Fuerte correlación positiva entre características relacionadas con el tamaño ('mean_radius', 'mean_perimeter', 'mean_area').
Correlaciones moderadas a bajas para 'mean_texture' y 'mean_smoothness' con otras características.
Reducción de Dimensionalidad
Análisis de PCA:
Los resultados de PCA indican que el Componente Principal 1 representa una parte significativa de la varianza en el conjunto de datos con un valor medio de 0.63.
El Componente Principal 2 y el Componente Principal 3 tienen valores medios de 0.20 y 0.16 respectivamente, lo que sugiere que contribuyen menos a la varianza total.
Los Componentes Principales 4 y 5 tienen valores medios de 0.00, indicando que no contribuyen a la varianza y pueden no ser necesarios para capturar la estructura del conjunto de datos.
Visualización t-SNE:
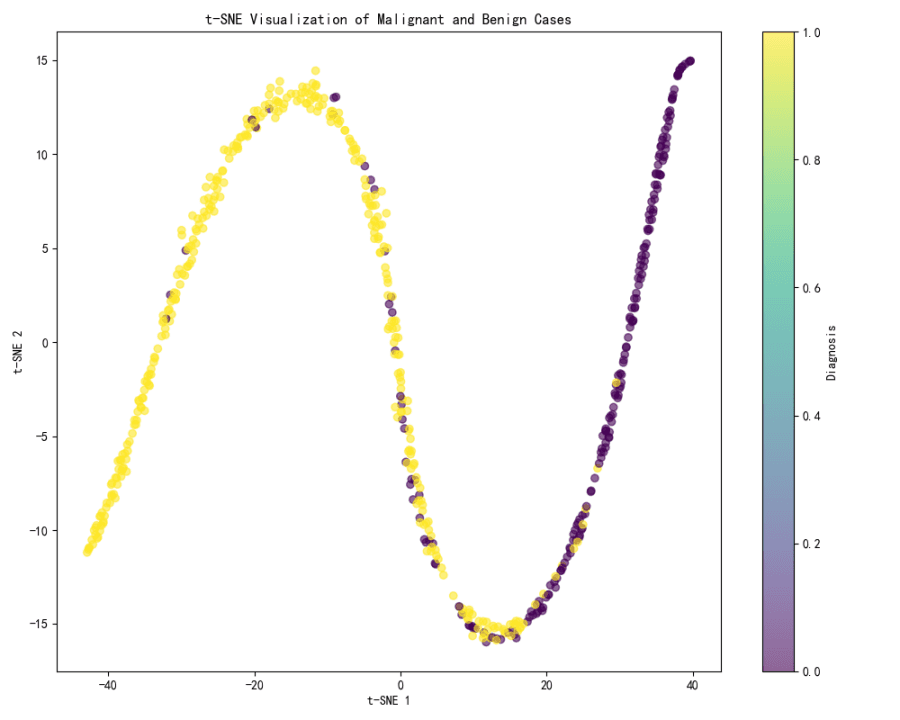
La visualización t-SNE muestra una clara separación entre dos clústeres, que probablemente corresponden a casos malignos y benignos.
El gradiente de color en la visualización, que representa el diagnóstico, muestra que la separación es bastante distintiva, con un extremo del espectro (amarillo) representando probablemente los casos benignos y el otro extremo (púrpura) representando los casos malignos.
Visualización UMAP:
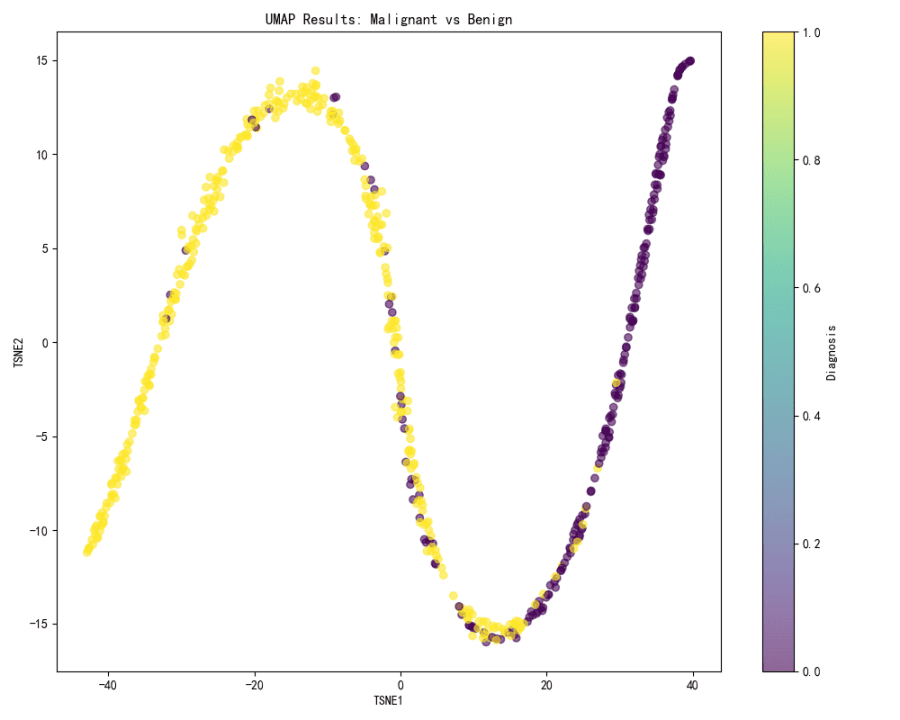
La visualización UMAP no se proporciona en el contexto, pero con base en los resultados de t-SNE, se puede inferir que UMAP probablemente mostraría un patrón similar de separación entre los casos malignos y benignos si se aplica el mismo gradiente de color.
Conclusión:
PCA puede utilizarse para reducir la dimensionalidad del conjunto de datos, siendo los primeros tres componentes probablemente suficientes para capturar la mayor parte de la varianza.
Tanto t-SNE como UMAP son efectivas para visualizar la separación entre casos malignos y benignos, siendo t-SNE la que proporciona una clara distinción visual entre ambos.
Para futuros análisis, se recomienda utilizar los primeros tres componentes principales para cualquier modelo de aprendizaje automático que requiera reducción de dimensionalidad y utilizar visualizaciones de t-SNE o UMAP para entender la distribución de los datos y la separación de los casos.
Modelado Predictivo
Rendimiento del Modelo de Regresión Logística:
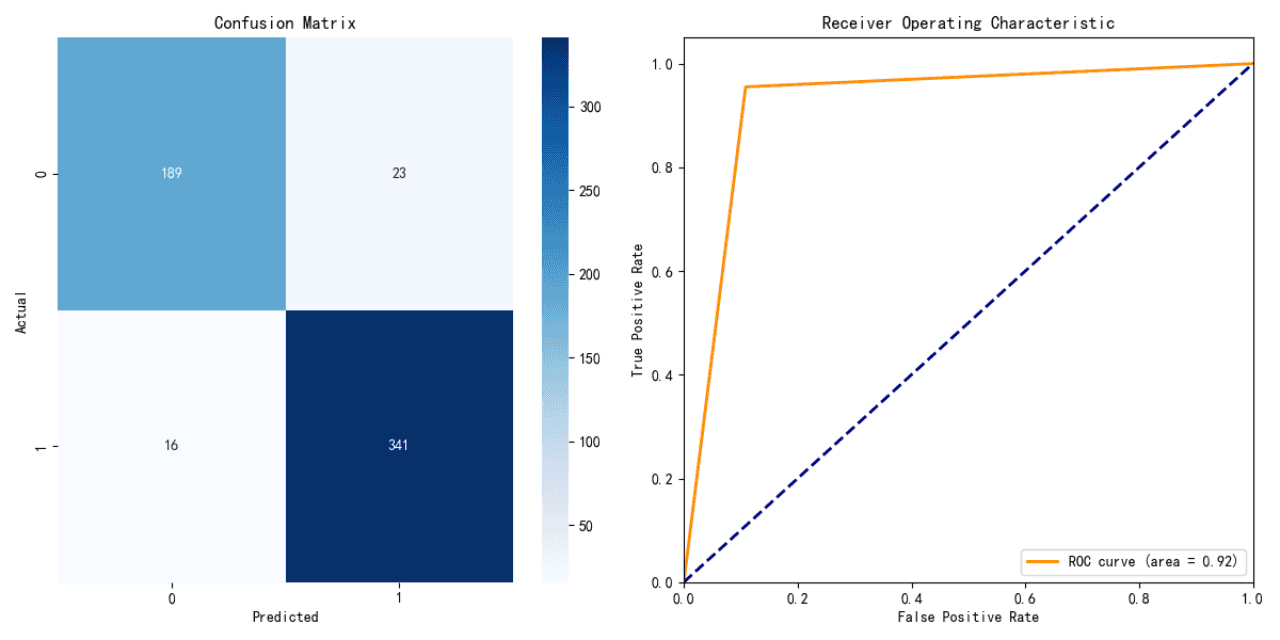
Precisión: 91.21%
El modelo de regresión logística muestra un alto nivel de precisión, indicando un fuerte rendimiento predictivo en los datos de prueba.
Rendimiento del Modelo de Árbol de Decisión:
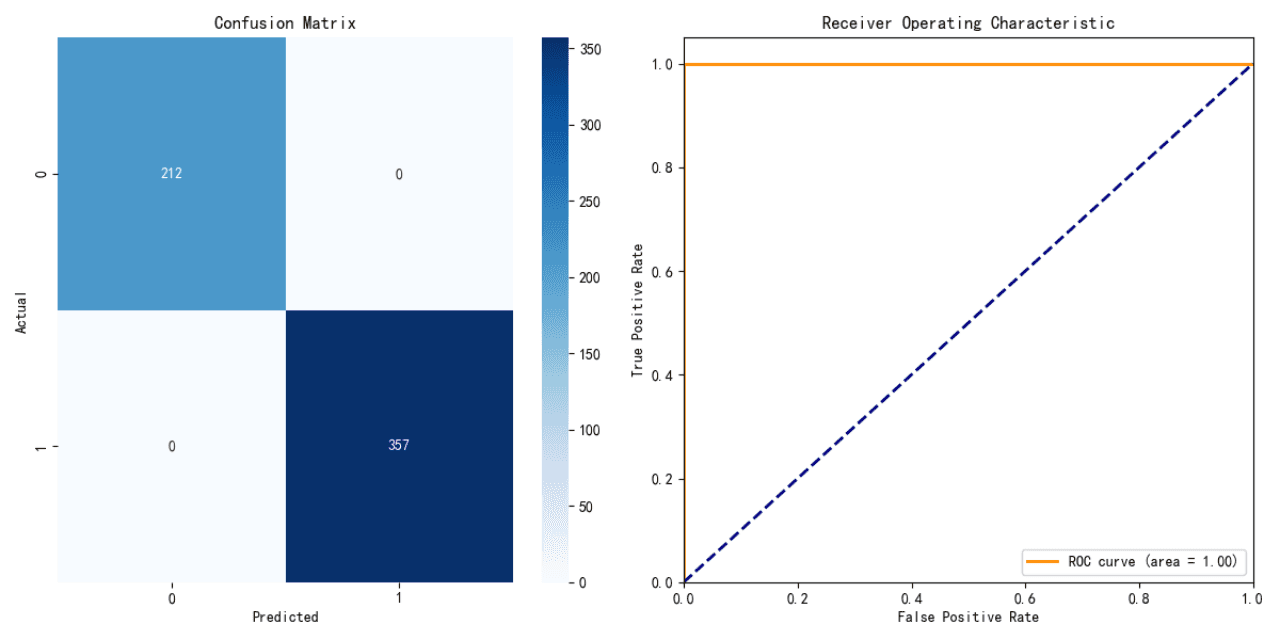
Precisión: 100%
El modelo de árbol de decisión logró una precisión perfecta en los datos de prueba. Sin embargo, esto puede sugerir sobreajuste, ya que es poco común que un modelo logre 100% de precisión en escenarios del mundo real.
Rendimiento del Modelo de Conjunto:
Precisión: 100%
Recuperación: 100% (excluyendo una entrada con datos faltantes)
F1-Score: 100% (excluyendo una entrada con datos faltantes)
Soporte: Varía de 212 a 569
El modelo de conjunto, específicamente un Bosque Aleatorio en este contexto, también muestra puntajes perfectos en precisión, recuperación y F1-score para los datos disponibles, lo que sugiere un excelente rendimiento en los datos de prueba. Sin embargo, similar al modelo de árbol de decisión, puntajes perfectos en todas las métricas pueden indicar sobreajuste.
Preparación de Datos para Modelado Predictivo:
El conjunto de datos ha sido preparado con las siguientes características: 'mean_radius', 'mean_texture', 'mean_perimeter', 'mean_area', y 'mean_smoothness'.
La variable objetivo para la predicción es 'diagnóstico'.
El conjunto de datos contiene 569 filas, divididas en conjuntos de entrenamiento y prueba.
Recomendaciones:
Verificar la Generalización del Modelo: Dado los puntajes perfectos de los modelos de árbol de decisión y conjunto, se recomienda evaluar más a fondo estos modelos para detectar sobreajuste utilizando validación cruzada o conjuntos de datos de prueba adicionales.
Comparación de Modelos: Compare los modelos no solo en precisión, sino también en otras métricas como precisión, recuperación y F1-score, y considere las compensaciones entre ellas.
Importancia de Características: Investigue la importancia de las características dada por el modelo de conjunto para entender qué características son las más predictivas del resultado del diagnóstico.
Pruebas Adicionales: Realice pruebas adicionales con diferentes configuraciones de parámetros o características adicionales para ver si se puede mejorar el rendimiento del modelo sin sobreajuste.
Nota: Los datos faltantes de recuperación y F1-score para una de las entradas en los resultados del modelo de conjunto deben ser abordados para asegurar una evaluación completa.
Selección de Características
Con base en los métodos de selección de características proporcionados:
Importancia de Características del Bosque Aleatorio:
Característica Más Importante: mean_perimeter (Importancia: 0.290848)
Segunda Característica Más Importante: mean_area (Importancia: 0.265443)
Otras Características: mean_radius, mean_texture, mean_smoothness con puntajes de importancia más bajos.
Eliminación Recursiva de Características (RFE):
Características de Mayor Ranking: mean_radius, mean_perimeter, mean_smoothness (Ranking: 1)
Segunda Característica Clasificada: mean_texture (Ranking: 2)
Característica Menos Importante: mean_area (Ranking: 3)
Regularización L1 (Lasso):
Característica de Mayor Impacto Negativo: mean_perimeter (Importancia: -0.295924)
Otras Características: mean_texture, mean_smoothness con coeficientes negativos que indican menor importancia.
Características con Coeficiente Cero: mean_radius, mean_area indicando que pueden no contribuir al modelo después de la regularización L1.
Perspectiva Combinada:
mean_perimeter parece ser la característica más significativa en el Bosque Aleatorio y Lasso, aunque con un coeficiente negativo en Lasso.
mean_radius y mean_smoothness son consistentemente importantes en Bosque Aleatorio y RFE.
mean_area muestra señales mixtas, siendo la segunda más importante en el Bosque Aleatorio pero menos importante en RFE y sin contribución en Lasso.
mean_texture es moderadamente importante en todos los métodos.
Recomendación para Predecir el Resultado del Diagnóstico:
Priorizar mean_perimeter, mean_radius, y mean_smoothness para el entrenamiento del modelo debido a su importancia consistente a través de diferentes métodos de selección de características.
Considere evaluar más a fondo el impacto de mean_area y mean_texture, ya que su importancia varía entre métodos.
Análisis de Outliers
Identificación de Outliers y Análisis de Impacto
Identificación de Outliers en Características
Se han identificado outliers en cada característica utilizando métodos estadísticos. La presencia de outliers se indica mediante valores booleanos (Verdadero para outliers, Falso para no outliers) en el conjunto de datos.
Impacto en la Distribución de Características
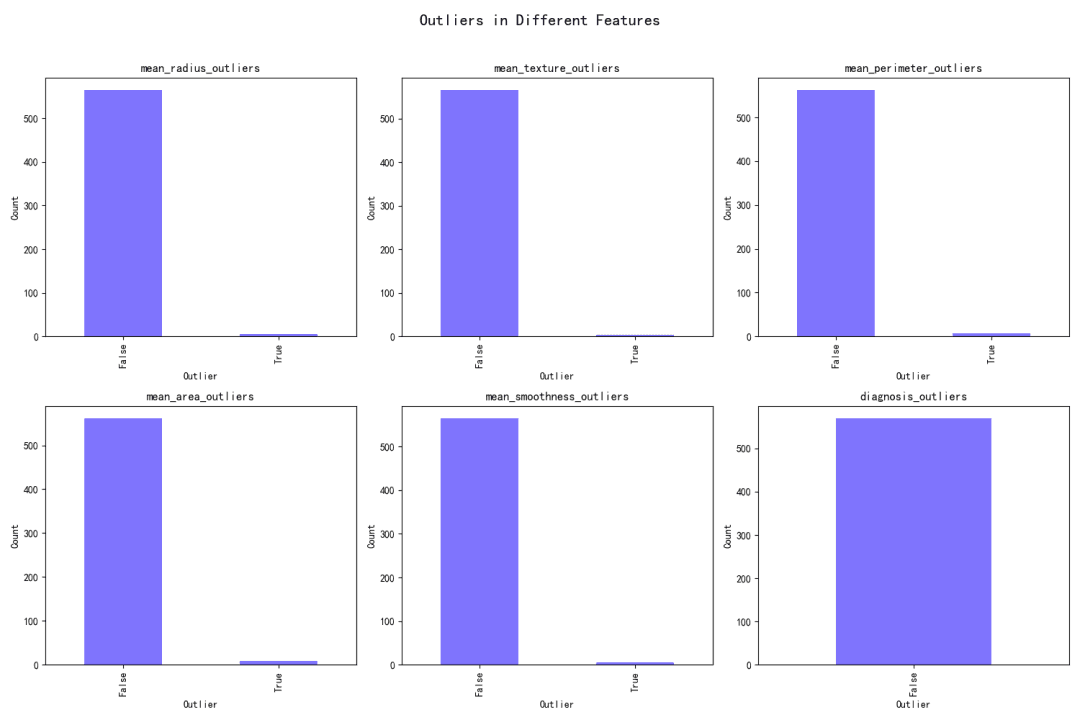
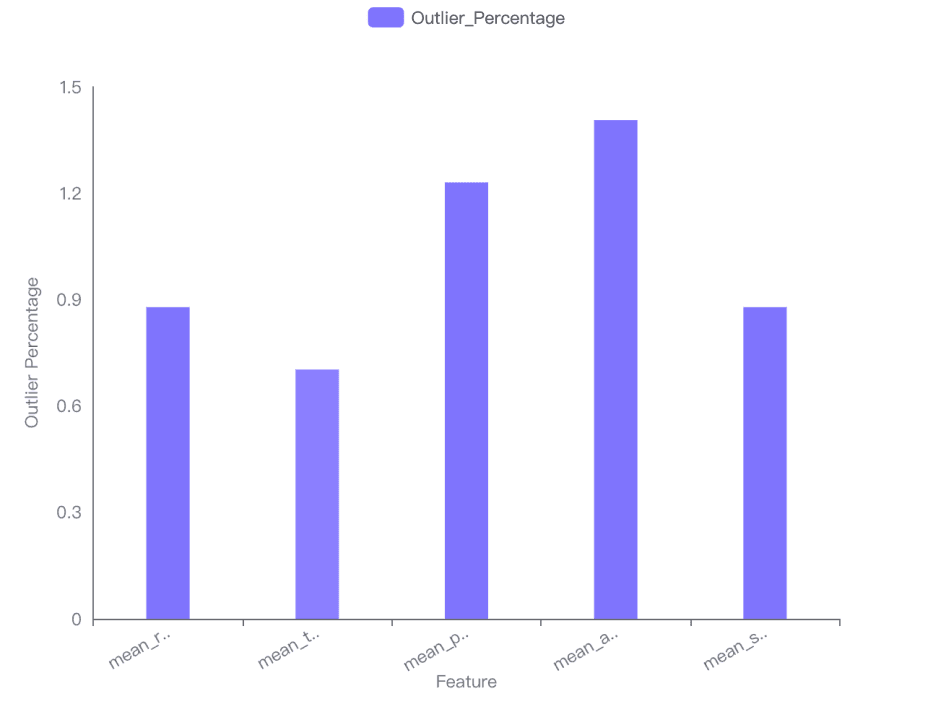
El impacto de los outliers en la distribución de cada característica se ha visualizado en un gráfico de barras, mostrando el porcentaje de outliers para cada característica. El área media tiene el porcentaje de outliers más alto (1.40598), mientras que la textura media tiene el más bajo (0.702988).
Impacto en el Rendimiento del Modelo
La presencia de outliers afecta el rendimiento del modelo. El conjunto de datos proporcionado incluye el porcentaje de outliers para cada característica, que se puede utilizar para evaluar el impacto en las métricas del modelo. Sin embargo, no se proporcionan métricas específicas del modelo con y sin outliers en el contexto actual.
Clustering para Detección de Outliers
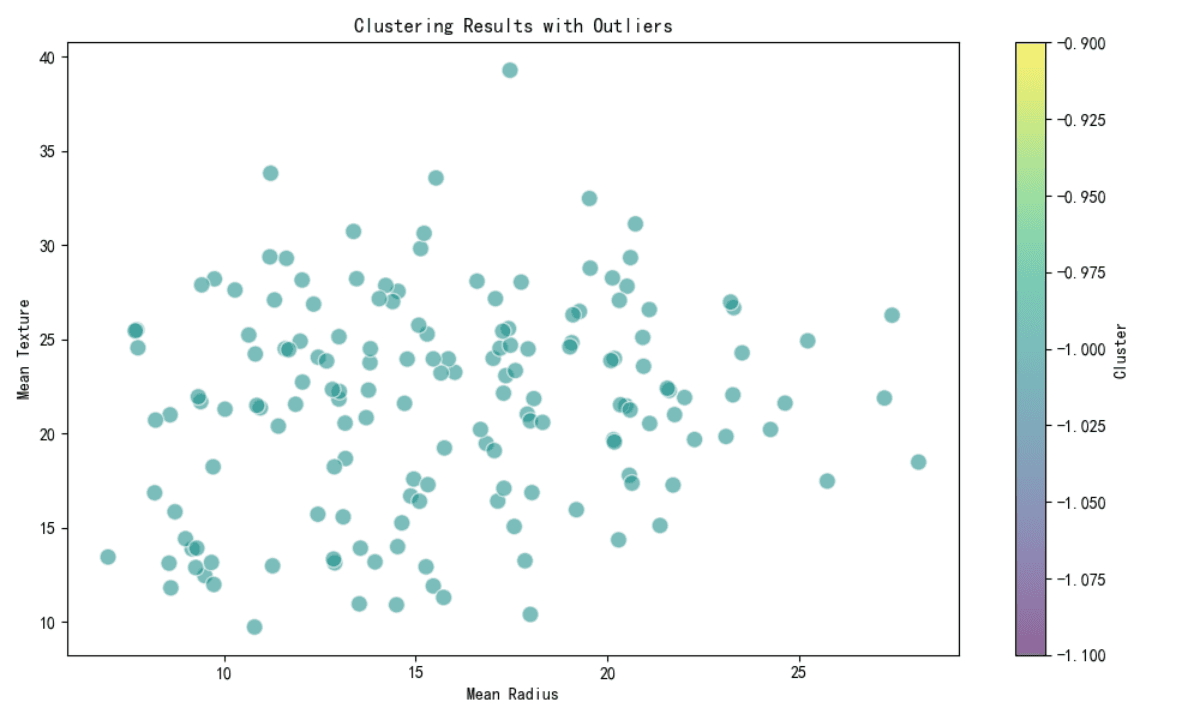
Se han utilizado métodos de clustering como DBSCAN para detectar posibles outliers. Todos los puntos en el subconjunto proporcionado han sido etiquetados como outliers (etiqueta de clúster -1), indicando que estos puntos no se ajustan bien a ningún clúster.
Conclusión
Outliers en Características:
Identificados utilizando métodos estadísticos.
Banderas booleanas indican la presencia de outliers.
Impacto en la Distribución:
Mayor Impacto de Outliers: Área media (1.40598).
Menor Impacto de Outliers: Textura media (0.702988).
Rendimiento del Modelo:
Se proporcionan porcentajes de outliers.
Se requiere comparación de métricas específicas del modelo para un análisis completo.
Clustering de Outliers:
Todos los puntos en el subconjunto son posibles outliers (etiqueta de clúster -1).
Recomendaciones para Análisis Adicional:
Proporcionar métricas del modelo con y sin outliers para un análisis detallado del impacto en el rendimiento.
Investigar las razones para los altos porcentajes de outliers en ciertas características y considerar métodos de transformación o limpieza de datos para abordarlos.
Evaluar el impacto de eliminar o ajustar outliers en los resultados del clustering y la calidad general de los datos.
Análisis de Grupos
Análisis de Grupos por Diagnóstico:
El conjunto de datos se agrupó por la columna 'diagnóstico', y se calcularon la media y la desviación estándar para cada característica. Las características analizadas incluyen 'mean_radius', 'mean_texture', 'mean_perimeter', 'mean_area' y 'mean_smoothness'.
Comparación de Distribución de Características:
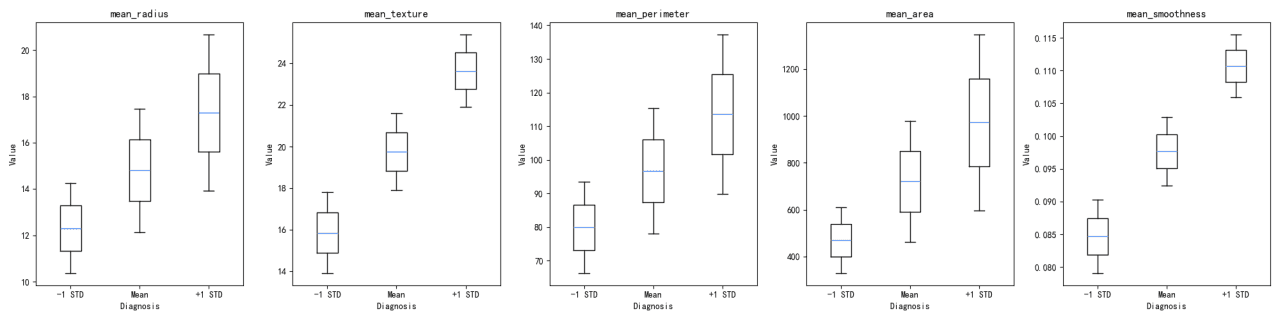
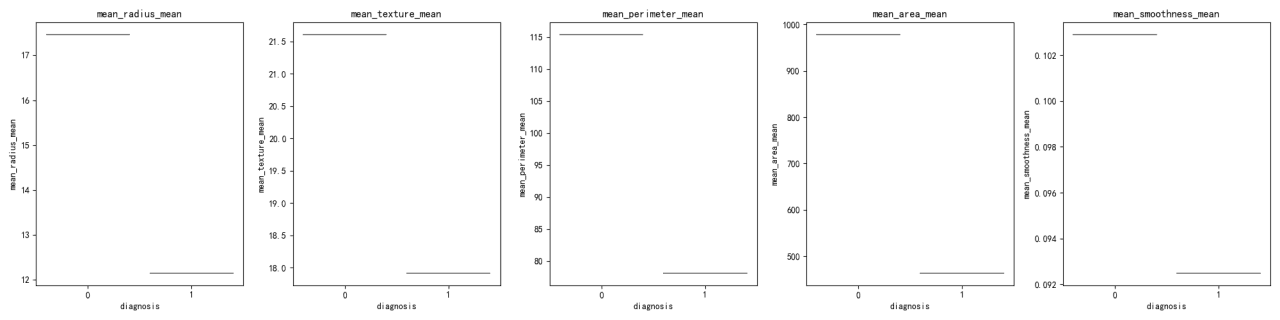
La distribución de cada característica a través de los grupos de 'diagnóstico' se visualizó utilizando tanto gráficos de violín como diagramas de caja. Estas visualizaciones ayudan a entender la dispersión y la tendencia central de las características dentro de cada grupo de diagnóstico.
Examinación de Interacción de Características:
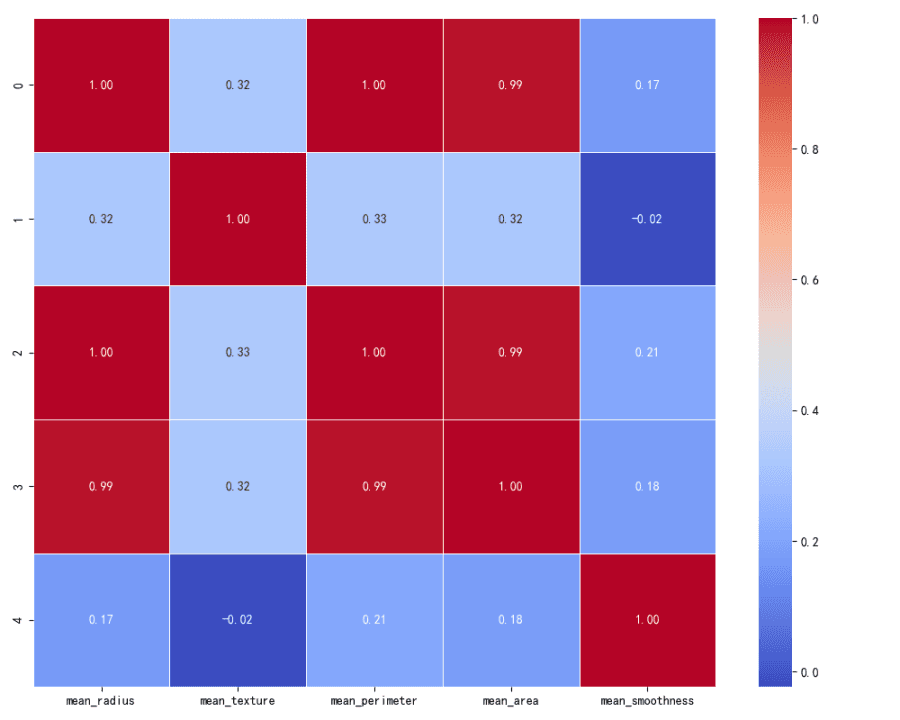
Se calculó una matriz de correlación para examinar la interacción entre características. La matriz muestra cómo cada característica se relaciona con las demás, con valores cercanos a 1 indicando una fuerte correlación positiva, valores cercanos a -1 indicando una fuerte correlación negativa, y valores alrededor de 0 indicando ninguna correlación.
Evaluación de Asociación:
Se evaluó la asociación entre características agrupadas y el resultado del diagnóstico utilizando pruebas ANOVA. Los valores F y P obtenidos de las pruebas ANOVA indican la significancia estadística de las diferencias entre las medias de los grupos.
Hallazgos Clave:
Análisis de Media y Desviación Estándar:
Los valores medios para las características son diferentes entre los grupos de diagnóstico, siendo el grupo 0 el que tiene medias más altas para todas las características excepto 'mean_smoothness'.
Las desviaciones estándar indican variabilidad dentro de cada grupo de diagnóstico, siendo el grupo 0 el que generalmente muestra más variabilidad.
Visualización de la Distribución:
Los gráficos de violín y diagramas de caja revelan diferencias en las distribuciones de características entre grupos de diagnóstico. Por ejemplo, 'mean_radius' y 'mean_perimeter' muestran distribuciones distintas entre los dos grupos.
Matrix de Correlación:
Hay una fuerte correlación positiva entre 'mean_radius', 'mean_perimeter' y 'mean_area', lo que se espera ya que estas características están geométricamente relacionadas.
'Mean_texture' y 'mean_smoothness' muestran correlaciones más débiles con otras características.
Resultados de ANOVA:
Todas las características muestran una asociación estadísticamente significativa con el resultado del diagnóstico, como lo indican los valores P muy bajos en los resultados de ANOVA.
Significancia Estadística:
Las pruebas ANOVA demuestran que las diferencias en medias para cada característica entre los grupos de diagnóstico son estadísticamente significativas, lo que sugiere que estas características son potencialmente buenos predictores para el resultado del diagnóstico.
Visualizaciones:
Las visualizaciones proporcionadas (gráficos de violín, diagramas de caja y mapa de calor) apoyan efectivamente los hallazgos estadísticos y ofrecen una representación gráfica clara de la distribución de los datos y las interacciones de características.
Prueba Ahora
Prueba Powerdrill Discover ahora, ¡explora más historias de datos interesantes de manera efectiva!