Las 10 mejores herramientas de memoria de IA para equipos que necesitan que la IA recuerde documentos, hojas de cálculo y reglas repetitivas de flujo de trabajo

Introducción
Si su equipo está integrando activamente la IA en las operaciones diarias, probablemente se haya topado con un cuello de botella frustrante: la amnesia de la IA. Los chatbots de IA estándar y los agentes ligeros son brillantes dentro de una sola conversación, pero en el momento en que inicia una nueva sesión, lo olvidan todo. Para los equipos, pegar las mismas hojas de cálculo masivas, volver a cargar documentos de incorporación y volver a escribir repetidamente los procedimientos operativos estándar (SOP) no es una forma escalable de trabajar.
Los equipos modernos no solo necesitan IA que pueda conversar; necesitan infraestructura de memoria de IA. Necesitan sistemas que puedan recordar de forma persistente contexto empresarial complejo, hojas de cálculo detalladas, documentos extensos y reglas de flujo de trabajo repetitivas a través de múltiples sesiones y herramientas.
En esta guía de compra completa, analizaremos las 10 mejores herramientas y plataformas de memoria de IA disponibles hoy. Exploraremos en qué se diferencian, qué casos de uso atienden mejor y cómo su equipo puede elegir la arquitectura de memoria adecuada para convertir la IA de un chatbot sin estado en un miembro del equipo altamente contextualizado.
Respuesta rápida: ¿Cuáles son las mejores herramientas de memoria de IA para equipos?
Si busca una recomendación rápida sobre las mejores herramientas de memoria de IA para flujos de trabajo complejos de equipo, aquí tiene el resumen ejecutivo:
Mejor para memoria empresarial de documentos y hojas de cálculo: MemoryLake destaca como una capa de memoria de IA persistente y gobernada por el usuario que funciona con modelos y agentes, diseñada específicamente para manejar archivos complejos y reglas de flujo de trabajo.
Mejor para memoria de agentes pensada primero para desarrolladores: Letta (antes MemGPT) y Mem0 ofrecen excelentes frameworks y APIs para desarrolladores que construyen agentes autónomos que necesitan memoria jerárquica o específica del usuario.
Mejor para integración de aplicaciones con baja latencia: Zep proporciona una extracción de memoria extremadamente rápida y guiada por intención para aplicaciones de IA conversacional.
Mejor para infraestructura de datos fundamental: Las bases de datos vectoriales como Pinecone y Weaviate siguen siendo estándares de la industria para equipos que construyen canalizaciones de Generación Aumentada por Recuperación (RAG) personalizadas desde cero.
Al evaluar estas herramientas, los equipos deben mirar más allá del simple historial de chat. Dé prioridad a las plataformas que ofrezcan continuidad entre sesiones, soporte multimodal (documentos y hojas de cálculo), gobernanza (trazabilidad y control de versiones) y portabilidad entre diferentes LLM.
Tabla comparativa: resumen de las 10 mejores herramientas de memoria de IA
Herramienta | Ideal para | Fortaleza de la memoria | Ajuste para documentos/hojas de cálculo | Precio |
Infraestructura persistente de memoria de IA | Alta (multimodelo/agente, consciente de versiones) | Excelente | ||
APIs de memoria personalizada para usuarios/agentes | Media-alta (seguimiento de entidades y sesiones) | Moderado | ||
Memoria conversacional de baja latencia | Alta (extracción rápida, contexto de diálogo) | Moderado | ||
Memoria persistente de agentes a nivel de sistema operativo | Alta (jerárquica, contexto infinito) | Bueno | ||
Memoria de grafo ligada al framework | Media (memoria con estado de LangGraph) | Bueno | ||
Aumento de contexto e ingesta de datos | Alta (RAG e indexación avanzados) | Excelente | ||
Infraestructura serverless de memoria vectorial | Alta (búsqueda semántica a gran escala) | Bueno (requiere una canalización personalizada) | ||
Memoria de base de datos vectorial nativa de IA | Alta (búsqueda híbrida, multimodal) | Bueno (requiere una canalización personalizada) | ||
Base de datos de embeddings de IA ligera | Media (almacén vectorial local/nube rápido) | Moderado | ||
Memoria vectorial de alto rendimiento | Alta (filtrado avanzado, escalable) | Bueno (requiere una canalización personalizada) |
1. MemoryLake
MemoryLake se posiciona como una plataforma de infraestructura de memoria de IA persistente y portátil diseñada específicamente para equipos que necesitan que sus sistemas de IA recuerden contextos empresariales complejos. En lugar de actuar como un simple registro de chat, funciona como una capa de memoria propiedad del usuario y gobernada, que opera sin problemas a través de diferentes modelos, agentes, herramientas y sesiones.
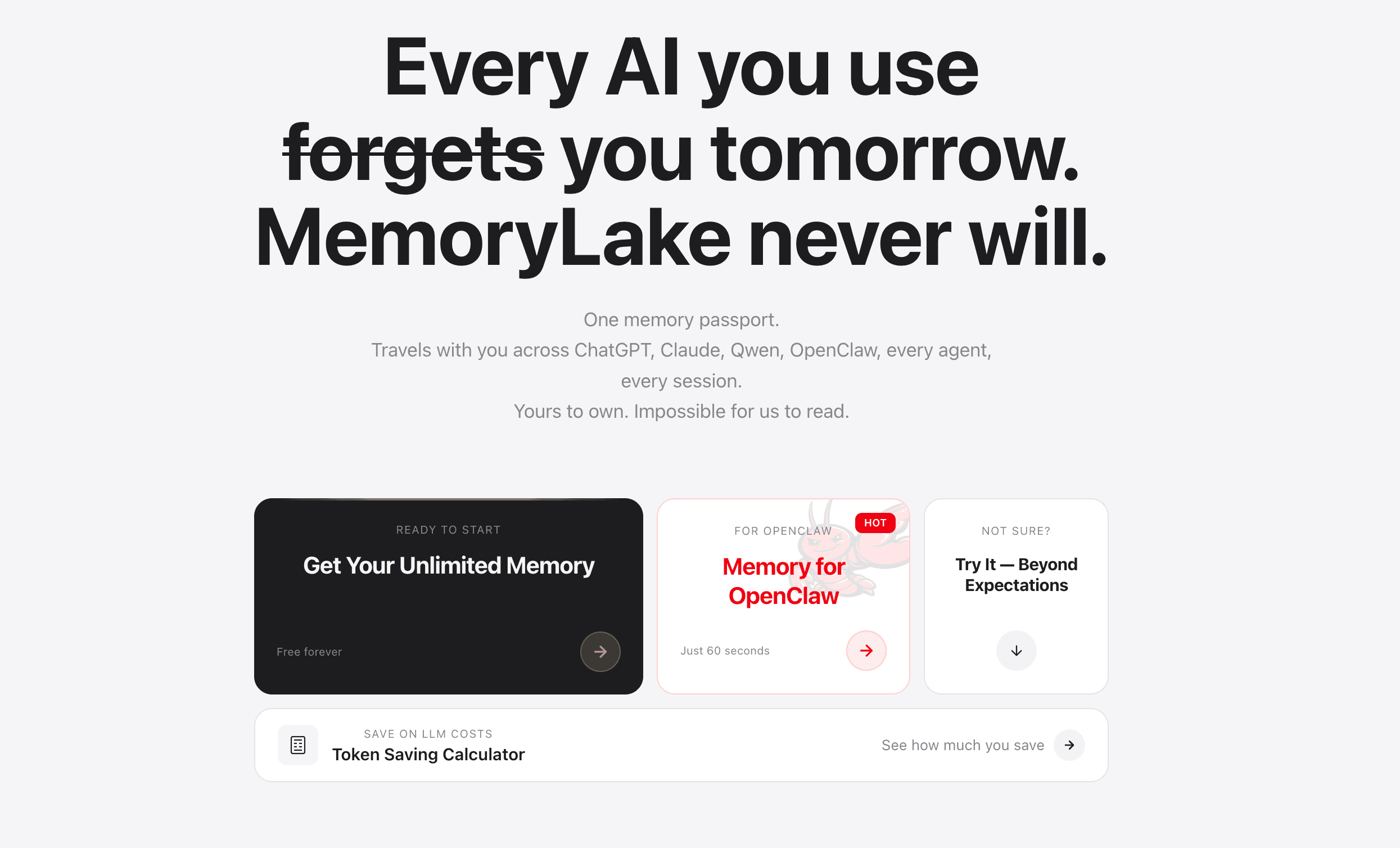
Características clave
Memoria multimodal a largo plazo: diseñada específicamente para ingerir y recordar de forma persistente documentos complejos, hojas de cálculo detalladas y reglas de flujo de trabajo repetitivas a lo largo de sesiones infinitas.
Continuidad entre agentes y entre modelos: según los materiales públicos de MemoryLake, su memoria está desacoplada de un único LLM, lo que permite a los equipos cambiar entre modelos de IA sin perder el conocimiento del equipo.
Gobernanza y procedencia: ofrece trazabilidad profunda, un enfoque de memoria consciente de versiones y una procedencia clara para que los equipos sepan exactamente de dónde obtuvo una IA su conocimiento contextual.
Aplicación de reglas de flujo de trabajo: capaz de almacenar patrones operativos recurrentes y lógica empresarial, garantizando que los agentes de IA sigan automáticamente los estándares de la empresa en cada interacción.
Portabilidad universal: funciona como una capa de infraestructura independiente que se integra con su pila tecnológica existente, en lugar de encerrarlo en un ecosistema aislado.
Ventajas
Ajuste excepcional para equipos cuyo conocimiento vive principalmente en archivos, hojas de cálculo y SOP, en lugar de solo en hilos de chat.
Alto nivel de gobernanza empresarial; la memoria puede auditarse, editarse y controlarse por versiones.
Evita la dependencia del proveedor al actuar como una capa de memoria independiente y portátil.
Elimina la necesidad de insertar manualmente documentos grandes en los prompts una y otra vez.
Desventajas
Puede ser excesivo para usuarios individuales o equipos pequeños que solo necesitan chatbots conversacionales básicos.
Como plataforma de infraestructura, requiere un proceso de implementación estratégico en comparación con extensiones ligeras del navegador listas para usar.
Es un paradigma relativamente nuevo que exige que los equipos cambien la forma en que piensan sobre el 'control' de la memoria de IA.
Precio
Empiece gratis. Pro a $19/mes. Premium a $199/mes.
2. Mem0
Mem0 es una capa de memoria pensada para desarrolladores y diseñada para crear aplicaciones de IA personalizadas. Se centra en ofrecer una API unificada que permite a los LLM recordar preferencias del usuario, historiales de sesión y relaciones entre entidades a través de diferentes aplicaciones.
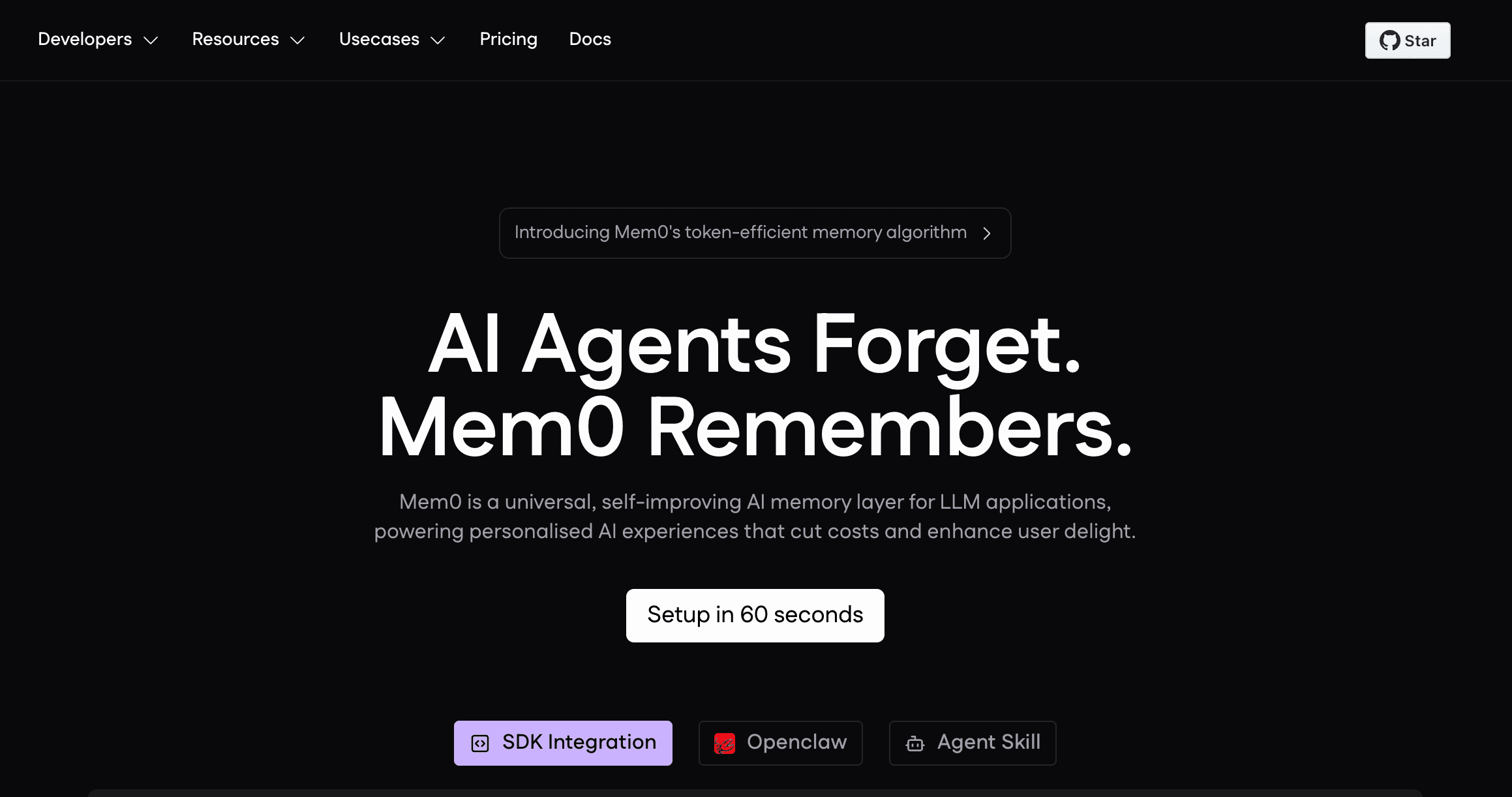
Características clave
Arquitectura de memoria multinivel: admite memoria de usuario, de sesión y de agente de IA, lo que permite a los desarrolladores delimitar qué recuerda la IA.
Gestión adaptativa de la memoria: extrae automáticamente entidades, actualiza hechos cambiantes y olvida información obsoleta.
Integración API sencilla: diseñada para que los desarrolladores inyecten memoria fácilmente en aplicaciones LLM existentes con un mínimo de código.
Búsqueda vectorial y por grafos: combina búsqueda semántica con mapeo de relaciones para un recuerdo contextual más preciso.
Gestión mediante panel: proporciona una interfaz para que los desarrolladores vean, editen y supervisen las memorias que se están creando.
Ventajas
Muy amigable para desarrolladores, con excelente documentación y APIs fáciles de usar.
Ideal para aplicaciones que necesitan rastrear preferencias individuales de usuario y configuraciones personalizadas.
El respaldo de la comunidad de código abierto garantiza actualizaciones rápidas y nuevas funciones.
Desventajas
Está construido principalmente para desarrolladores que crean aplicaciones, lo que lo hace menos accesible para equipos de negocio no técnicos que buscan una solución lista para usar.
Si bien maneja documentos, su fortaleza principal se inclina fuertemente hacia el contexto conversacional y las preferencias del usuario, más que hacia el razonamiento complejo con hojas de cálculo.
Las funciones de gobernanza aún están madurando en comparación con las plataformas de infraestructura de nivel empresarial.
Precio
Starter a $19/mes. Pro a $249/mes.
3. Zep
Zep es una solución de memoria escalable y de baja latencia, diseñada específicamente para asistentes y agentes de IA conversacional. Se centra en la extracción rápida de hechos, la gestión del historial de diálogo y la búsqueda semántica para garantizar que los agentes de IA puedan conversar con fluidez sin perder el hilo de la conversación.
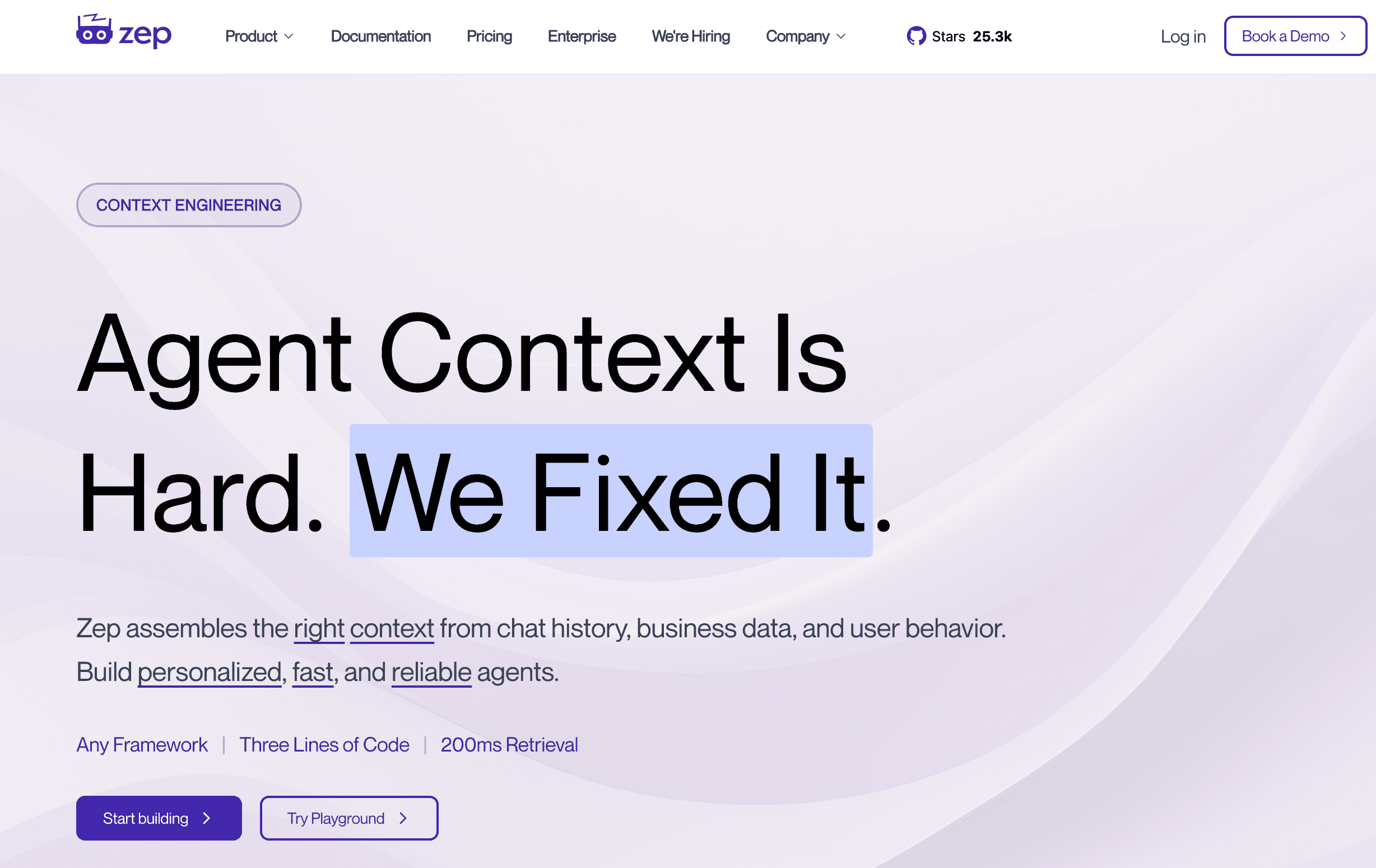
Características clave
Memoria conversacional perpetua: resume, vectoriza y almacena automáticamente los historiales de chat para gestionar de forma eficiente ventanas de contexto de largo plazo.
Extracción de hechos y entidades: extrae proactivamente hechos centrales, fechas y entidades de las conversaciones para construir un perfil estructurado del usuario.
Latencia extremadamente baja: diseñado para una recuperación rápida, asegurando que las aplicaciones de IA conversacional no sufran retrasos durante el recuerdo de memoria.
Clasificación de diálogos: puede etiquetar y clasificar automáticamente intenciones y emociones a partir de los flujos de memoria almacenados.
Opciones de autoalojamiento y nube: puede implementarse localmente dentro de la VPC de una empresa por motivos de privacidad o usarse como servicio gestionado en la nube.
Ventajas
Rendimiento rapidísimo, lo que lo hace ideal para bots de atención al cliente en tiempo real y agentes conversacionales.
La extracción de hechos lista para usar ahorra a los desarrolladores tener que escribir una ingeniería de prompts compleja para resumir chats.
Fuertes controles de privacidad con opciones de implementación local.
Desventajas
Muy optimizado para chat y conversación; menos adecuado para una gobernanza compleja de memoria de documentos o hojas de cálculo.
No está diseñado como una plataforma generalizada de contexto empresarial entre herramientas para equipos no técnicos.
Aplicación limitada de reglas de flujo de trabajo integradas en comparación con capas de infraestructura de memoria más amplias.
Precio
Flex a $125/mes. Flex Plus a $375/mes.
4. Letta (antes MemGPT)
Letta es un framework inspirado en sistemas operativos para crear agentes de IA autónomos y con estado. Ofrece a los LLM la ilusión de un contexto infinito utilizando una jerarquía de memoria similar a la de un sistema operativo (memoria principal frente a almacenamiento externo) para intercambiar información según sea necesario.
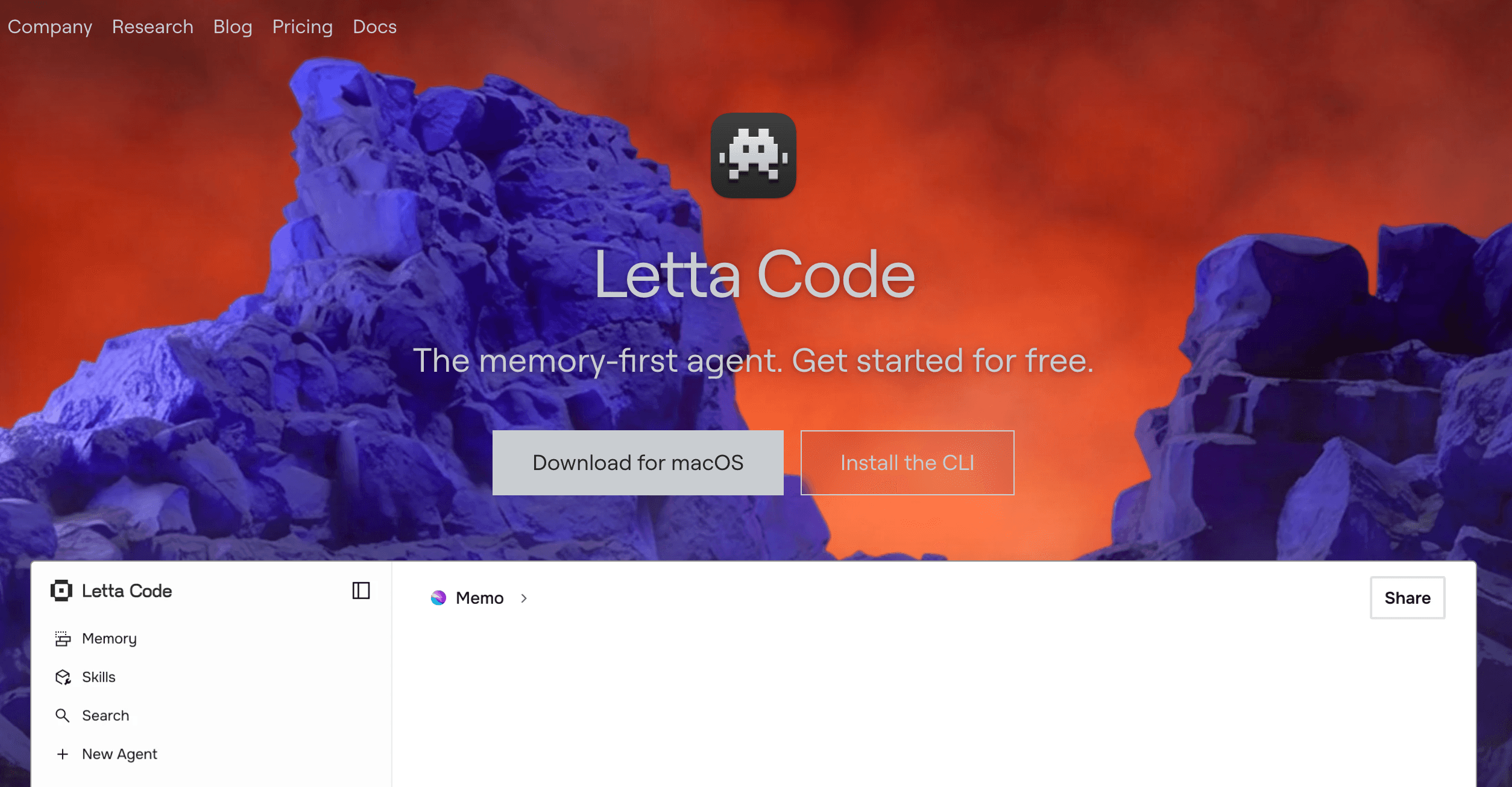
Características clave
Arquitectura de memoria por niveles: divide la memoria en una 'memoria de trabajo' rápida (en contexto) y una 'memoria de archivo' escalable (base de datos externa).
Memoria autoeditada: el propio agente de IA puede decidir cuándo escribir nueva información en la memoria, actualizar hechos existentes o buscar en sus archivos.
Estado persistente del agente: los agentes pueden ejecutarse continuamente en segundo plano, activándose según eventos externos o programaciones mientras conservan el contexto histórico completo.
Análisis de documentos: puede ingerir fuentes de datos externas y documentos en su memoria de archivo para que el agente los consulte más adelante.
Compatibilidad con LLM locales: funciona bien con modelos alojados localmente, proporcionando una fuerte privacidad para datos sensibles.
Ventajas
Enfoque innovador para la memoria de agentes autónomos, permitiendo que la IA gestione su propio estado de forma dinámica.
Excelente para tareas de larga duración y agentes complejos que necesitan recordar interacciones pasadas durante meses.
Base de código abierto sólida con una comunidad de desarrolladores muy activa.
Desventajas
Muy técnico y requiere una experiencia significativa de desarrollo para configurarlo y orquestarlo.
Como la IA gestiona su propia memoria, a veces puede ser más difícil imponer la trazabilidad y una gobernanza humana estricta.
No es una aplicación SaaS lista para usar para equipos de negocio; es un framework para construir agentes.
Precio
Pro a $20/mes. Max Lite a $100/mes. Max a $200/mes.
5. LangChain (LangGraph)
LangChain es el framework más utilizado de la industria para construir aplicaciones LLM. Con la introducción de LangGraph, ha evolucionado para admitir flujos de trabajo multiagente complejos y con estado, proporcionando a los desarrolladores herramientas robustas para gestionar la memoria y el estado conversacional a través de grafos de ejecución de IA.
Características clave
Arquitectura de grafo con estado: LangGraph permite a los desarrolladores modelar los flujos de trabajo de los agentes como grafos, persistiendo automáticamente el estado y la memoria en cada nodo.
Módulos de memoria integrados: ofrece tipos de memoria listos para usar, incluida memoria de búfer, memoria de resumen y memoria de entidad.
Funcionalidad de punto de control: permite pausar, inspeccionar y reanudar los flujos de trabajo más tarde, actuando esencialmente como memoria de corto y medio plazo.
Humano en el circuito: la gestión del estado permite pausar los flujos de trabajo, pedir aprobación a una persona y continuar sin perder contexto.
Ecosistema enorme: se integra sin problemas con casi todas las bases de datos vectoriales, cargadores de documentos y LLM disponibles.
Ventajas
Flexibilidad incomparable para desarrolladores que desean construir flujos de trabajo de IA altamente personalizados y con estado.
La gestión del estado (puntos de control) proporciona una excelente trazabilidad para tareas complejas de agentes.
La enorme variedad de integraciones facilita extraer memoria de bases de datos empresariales existentes.
Desventajas
Curva de aprendizaje pronunciada; LangChain y LangGraph pueden ser muy complejos y extensos de implementar.
La memoria está ligada al framework de la aplicación; no es una capa de memoria portátil e independiente con la que puedan interactuar equipos no técnicos.
No es, por sí solo, un repositorio dedicado de memoria para documentos/hojas de cálculo (depende de integraciones de bases de datos vectoriales de terceros).
Precio
Plus a $39 / asiento al mes.
6. LlamaIndex
LlamaIndex es un framework de datos de primer nivel diseñado específicamente para conectar fuentes de datos personalizadas (documentos, hojas de cálculo, API) con LLM. Aunque a menudo se lo considera un framework de RAG (Generación Aumentada por Recuperación), sirve como una capa crítica de memoria y aumento de contexto para aplicaciones empresariales.
Características clave
Ingesta avanzada de datos: destaca en el análisis de documentos complejos, PDF y datos estructurados como bases de datos SQL y CSV.
Indexación personalizada: permite a los equipos crear índices vectoriales, índices de árbol e índices de palabras clave para optimizar cómo la IA recupera la memoria.
Aumento de contexto: funciona como un banco de memoria externo al recuperar dinámicamente los fragmentos de datos más relevantes para inyectarlos en el prompt del LLM.
Flujos de trabajo agénticos: admite agentes de datos avanzados capaces de razonar sobre conjuntos de datos complejos y consultas de varios pasos.
Evaluación y trazado: proporciona herramientas para medir la precisión y la relevancia de la memoria recuperada.
Ventajas
Lo mejor de su clase para aplicaciones que necesitan depender fuertemente de grandes volúmenes de documentos y hojas de cálculo empresariales existentes.
Las estrategias de indexación altamente personalizables permiten una recuperación de memoria muy precisa.
Salva la brecha entre los datos estructurados de la empresa y el razonamiento no estructurado de los LLM.
Desventajas
Es un framework de datos, no una aplicación de memoria de usuario independiente y portátil. Requiere que los desarrolladores construyan la aplicación real.
No gestiona de forma nativa el 'estado del usuario' ni las 'preferencias del usuario entre sesiones' con la misma facilidad que las herramientas dedicadas a memoria de usuario listas para usar.
Requiere administrar bases de datos vectoriales externas para la persistencia.
Precio
Starter a $50/mes. Pro a $500/mes.
7. Pinecone
Pinecone es una base de datos vectorial totalmente gestionada y sin servidor que sirve como infraestructura de memoria fundamental para miles de aplicaciones de IA. Aunque no es una 'herramienta de memoria' independiente en el sentido conversacional, es el motor de backend que permite a la IA almacenar y recuperar enormes cantidades de memoria semántica.

Características clave
Búsqueda vectorial sin servidor: escala automáticamente para manejar miles de millones de embeddings vectoriales sin gestión de infraestructura.
Actualizaciones de índices en tiempo real: permite actualizaciones inmediatas en la base de datos, asegurando que la memoria de la IA refleje cambios de datos en tiempo real.
Búsqueda híbrida: combina búsqueda vectorial densa (significado semántico) con búsqueda de palabras clave dispersa para una recuperación de documentos muy precisa.
Filtrado por metadatos: permite consultas complejas (por ejemplo, 'Encuentra esta memoria, pero solo dentro de documentos cargados por el equipo de RR. HH. en 2024').
Seguridad empresarial: cumplimiento SOC 2 y controles de acceso de nivel empresarial.
Ventajas
Increíblemente fiable y escalable para implementaciones empresariales que requieren un almacenamiento masivo de memoria.
La arquitectura sin servidor elimina la carga de DevOps de gestionar la infraestructura de bases de datos.
El filtrado por metadatos es excelente para gestionar permisos y segmentar el conocimiento del equipo.
Desventajas
Es puramente una capa de base de datos; los equipos deben construir su propia lógica de recuperación, análisis e interfaces de aplicación.
No entiende de forma nativa 'flujos de trabajo' o 'sesiones de usuario'—solo entiende embeddings vectoriales.
Se cobra según el uso de la infraestructura, lo que exige una optimización cuidadosa para evitar que los costes se disparen.
Precio
Starter a $50/mes. Enterprise a $500/mes.
8. Weaviate
Weaviate es una base de datos vectorial de código abierto y nativa de IA, diseñada para actuar como memoria a largo plazo para aplicaciones inteligentes. Se distingue por ofrecer una integración fluida con modelos de ML y sólidas capacidades de búsqueda híbrida, lo que la convierte en una favorita para arquitecturas empresariales de RAG.

Características clave
Vectorización integrada: puede vectorizar automáticamente los datos al ingerirlos usando módulos integrados, simplificando la canalización de creación de memoria.
Búsqueda híbrida avanzada: combina búsqueda vectorial con búsqueda de palabras clave BM25 para garantizar una recuperación muy precisa de documentos y puntos de datos específicos.
Soporte para multitenencia: diseñado para manejar de forma segura espacios de memoria distintos para miles de usuarios o inquilinos diferentes.
Relaciones tipo grafo: admite referencias cruzadas entre objetos de datos, lo que permite que la memoria de la IA entienda cómo se relacionan distintos documentos y conceptos.
Implementación flexible: puede ejecutarse localmente, mediante Docker, en Kubernetes o a través de la nube completamente gestionada.
Ventajas
La multitenencia la hace excelente para empresas B2B SaaS que crean memoria para sus propios usuarios finales.
La vectorización integrada reduce la barrera de entrada para los equipos que construyen canalizaciones de memoria.
Su naturaleza de código abierto ofrece flexibilidad de implementación y evita la dependencia del proveedor.
Desventajas
Al igual que Pinecone, es una base de datos, lo que significa que carece de una UI/UX nativa para que los equipos no técnicos interactúen directamente con la memoria de IA.
Requiere recursos dedicados de desarrollo para implementar y mantener la lógica de orquestación de la memoria.
Las funciones de grafo son útiles, pero requieren una curva de aprendizaje pronunciada para modelarlas correctamente.
Precio
Flex a $45/mes. Premium a $400/mes.
9. Chroma
Chroma es una base de datos de embeddings de IA ligera y de código abierto, muy apreciada por los desarrolladores por su simplicidad y velocidad. Actúa como un almacén de memoria fácil de implementar para aplicaciones LLM, permitiendo que la IA recupere rápidamente contexto de documentos e interacciones pasadas.

Características clave
Simplicidad pensada primero para desarrolladores: puede instalarse y ponerse en marcha en solo unas pocas líneas de código, de forma nativa en Python o JavaScript.
Almacenamiento en memoria y persistente: funciona fácilmente en memoria para pruebas o guarda en disco para memoria local persistente.
Embeddings automáticos: incluye funciones de embedding integradas, lo que significa que los desarrolladores pueden pasar texto sin procesar y Chroma se encarga de la vectorización.
Ricas integraciones de ecosistema: se conecta sin problemas con LlamaIndex, LangChain y otros marcos de IA importantes.
Local primero: altamente optimizado para ejecutarse localmente, garantizando privacidad de datos para documentos sensibles del equipo.
Ventajas
Probablemente la base de datos vectorial más fácil de configurar para prototipos rápidos de memoria de IA.
Excelente para implementaciones locales y con prioridad en la privacidad, donde los datos sensibles del equipo no pueden salir de la red interna.
Completamente gratuita y de código abierto.
Desventajas
Carece de las funciones avanzadas de multitenencia empresarial y escalado distribuido de bases de datos vectoriales más grandes.
No es una plataforma de infraestructura gestionada; los equipos deben administrar sus propios despliegues para producción.
Es estrictamente un almacén de embeddings; no maneja de forma nativa el estado agéntico, las reglas de flujo de trabajo ni la portabilidad entre herramientas.
Precio
Starter es gratis, Team cuesta $250 al mes y el precio Enterprise es personalizado.
10. Qdrant
Qdrant es un motor de búsqueda vectorial de alto rendimiento construido en Rust, diseñado para servir como un backend de memoria rápido y escalable para aplicaciones de IA. Es especialmente adecuado para aplicaciones que requieren un filtrado intensivo de metadatos junto con búsqueda semántica.

Características clave
Búsqueda vectorial de alta velocidad: escrito en Rust, ofrece un rendimiento excepcional y una gran eficiencia de recursos para la recuperación de memoria.
Filtrado avanzado de carga útil: permite a los equipos adjuntar cargas útiles JSON complejas a las memorias y filtrar búsquedas según lógica empresarial estricta.
Compatibilidad con cuantización: utiliza técnicas avanzadas de compresión para almacenar enormes cantidades de memoria vectorial a bajo coste sin perder precisión.
Arquitectura distribuida: construido para alta disponibilidad y escalado horizontal en entornos empresariales.
SDK en varios idiomas: proporciona clientes oficiales para Python, Rust, Go, TypeScript y más.
Ventajas
Rendimiento increíble y bajo consumo de recursos gracias a su arquitectura basada en Rust.
El filtrado de carga útil es muy valioso para los equipos que necesitan combinar reglas estrictas de palabras clave con memoria semántica.
Muy rentable a escala gracias a la cuantización integrada.
Desventajas
Requiere un equipo de ingeniería sólido para implementarlo como parte de una canalización personalizada de RAG/memoria.
Gestión de usuarios menos 'lista para usar' en comparación con herramientas de memoria específicas como Mem0.
No tiene una UI nativa para que los usuarios de negocio gobiernen o rastreen la lógica de memoria de IA.
Precio
Qdrant Cloud ofrece un servicio gestionado con un nivel gratuito para siempre para prototipado, seguido de precios basados en el uso que escalan según los recursos de clúster y el almacenamiento requeridos. También hay precios empresariales personalizados disponibles.
¿Qué herramienta de memoria de IA es mejor para distintas necesidades del equipo?
La madurez en IA y el caso de uso de cada equipo son diferentes. Para evitar comparar peras con manzanas, aquí le mostramos cómo debería categorizar estas herramientas según su escenario de compra específico:
Mejor para infraestructura de memoria de IA de nivel empresarial
Si su objetivo es construir una capa de memoria centralizada, gobernada y portátil que sirva a toda la organización —especialmente para documentos complejos y flujos de trabajo repetitivos—, MemoryLake es muy recomendable. Va más allá de las bases de datos en bruto al proporcionar una plataforma de infraestructura que los equipos operativos no técnicos pueden realmente gobernar.
Mejor para una implementación ligera por parte de desarrolladores
Si usted es un desarrollador que construye una app de IA y solo necesita una API para recordar preferencias del usuario, Mem0 ofrece una solución fantástica y lista para usar. Si necesita prototipado local, Chroma es el almacén vectorial más rápido de poner en marcha.
Mejor para canalizaciones RAG con mucha carga de documentos y hojas de cálculo
Si su equipo de ciencia de datos está construyendo motores de contexto personalizados desde cero usando enormes lagos de datos corporativos, una combinación de LlamaIndex (para ingesta y orquestación de datos) y Pinecone o Weaviate (para almacenamiento vectorial) representa el estándar de la industria.
Mejor para flujos de trabajo agénticos y automatización
Si está construyendo agentes de IA autónomos que necesitan ejecutarse en segundo plano, editar su propia memoria y mantener estados complejos de varios pasos, frameworks como Letta (MemGPT) y LangChain (LangGraph) son las herramientas más robustas disponibles.
Herramientas de memoria de IA vs. historial de chat vs. bases de datos vectoriales
Para tomar una decisión de compra inteligente, los equipos deben entender las distinciones técnicas del mercado de IA. A menudo, los proveedores confunden estos tres conceptos, lo que conduce a implementaciones fallidas.
Historial de chat (la base)
Esto es lo que hace ChatGPT o Claude por defecto. Simplemente añade sus mensajes anteriores a la ventana de contexto hasta que se alcanza el límite de tokens. Una vez que inicia un nuevo chat, la IA lo olvida todo. Es sin estado, no portable e inadecuado para la memoria de documentos a escala de equipo.
Bases de datos vectoriales (la capa de almacenamiento)
Herramientas como Pinecone, Weaviate y Qdrant son bases de datos vectoriales. Almacenan datos como embeddings matemáticos para que una IA pueda realizar búsquedas semánticas. Sin embargo, una base de datos es solo almacenamiento. No sabe de forma nativa cómo gestionar 'sesiones de usuario', 'portabilidad entre agentes' o 'aplicación de flujos de trabajo'. Tiene que contratar desarrolladores para construir la lógica de memoria encima de ellas.
Plataformas de infraestructura de memoria de IA (la solución)
Herramientas como MemoryLake actúan como la capa integral por encima de la base de datos. Proporcionan la plataforma de infraestructura real. Gestionan la ingesta de hojas de cálculo, administran el control de versiones de los documentos, mantienen la continuidad de las sesiones y ofrecen una UI de gobernanza. Cierran la brecha entre el almacenamiento de datos en bruto y la experiencia de IA del usuario final.
Conclusión
La era de copiar y pegar las mismas instrucciones, SOP y hojas de cálculo en una ventana de prompt de IA en blanco está llegando a su fin. A medida que la IA evoluciona de un simple asistente para lluvia de ideas a un miembro autónomo del equipo, la memoria persistente ya no es un lujo; es un requisito fundamental de infraestructura.
Al evaluar el mercado, los equipos deben reconocer la diferencia entre bases de datos pensadas para desarrolladores, gestores de estado ligados a frameworks y verdaderas plataformas de memoria empresarial. Si tiene un equipo de desarrolladores que construyen canalizaciones RAG personalizadas, invertir en Pinecone, LlamaIndex o Letta aportará un valor inmenso.
Sin embargo, si su equipo está centrado en resultados de negocio o si su conocimiento operativo vive principalmente en archivos, hojas de cálculo y reglas de flujo de trabajo complejas, necesita una solución que cierre la brecha entre los datos en bruto y la continuidad de la IA.
Para los equipos que han superado el simple historial de chat y las APIs ligeras, MemoryLake merece ser evaluado. Al funcionar como una capa de memoria persistente y portátil, permite que su IA conserve el contexto vital del equipo a través de diferentes sesiones, modelos y agentes. Garantiza que, cuando cambie su lógica empresarial, la memoria de su IA se actualice con ella, respaldada por la gobernanza y la trazabilidad que exigen los flujos de trabajo empresariales.
Deje de volver a entrenar su IA cada vez que abra una pestaña nueva. Invierta en infraestructura de memoria de IA escalable y permita que su IA por fin aprenda cómo trabaja realmente su equipo.
Preguntas frecuentes
¿Qué es una herramienta de memoria de IA?
Una herramienta de memoria de IA es software o infraestructura que permite a los modelos de inteligencia artificial almacenar, recordar y actualizar información de forma persistente —como preferencias del usuario, contexto empresarial o reglas operativas— a lo largo de múltiples sesiones e interacciones, superando la amnesia inherente de los LLM estándar.
¿En qué se diferencia la memoria de IA del historial de chat?
El historial de chat simplemente vuelve a introducir los mensajes pasados en el prompt actual hasta que el modelo alcanza su límite de tokens. Las herramientas de memoria de IA extraen hechos de forma dinámica, los almacenan externamente y recuperan de manera selectiva solo la información más relevante, permitiendo una retención de contexto infinita durante meses o años.
¿Pueden las herramientas de memoria de IA recordar hojas de cálculo y documentos?
Sí, pero depende de la herramienta. Las herramientas ligeras de memoria de chat tienen dificultades con los datos estructurados. Las plataformas de infraestructura avanzadas como MemoryLake o frameworks como LlamaIndex están diseñadas específicamente para ingerir, analizar y recordar de forma persistente datos de hojas de cálculo complejas y documentos extensos de varias páginas.
¿Cuál es la diferencia entre las herramientas de memoria de IA y las bases de datos vectoriales?
Una base de datos vectorial (como Pinecone) es almacenamiento backend para datos vectorizados. Una herramienta o plataforma de memoria de IA (como MemoryLake o Mem0) incluye la lógica de orquestación, la gestión de usuarios, la continuidad entre sesiones y la gobernanza necesarias para que esos datos almacenados funcionen realmente como 'memoria' para un agente de IA.
¿Qué herramientas de memoria de IA son mejores para equipos?
Para equipos de desarrollo que construyen aplicaciones, Mem0 o Letta son excelentes. Para equipos de negocio y operaciones que necesitan que una IA recuerde de forma persistente los SOP de la empresa, documentos y flujos de trabajo sin requerir código personalizado, las plataformas empresariales como MemoryLake son la mejor opción.
¿Qué deberían buscar las empresas en una plataforma de memoria de IA?
Las empresas deben priorizar la gobernanza (saber por qué la IA recordó algo), la trazabilidad, la seguridad, el soporte multimodal (documentos/hojas de cálculo) y la portabilidad (la capacidad de cambiar de modelo de IA sin perder la memoria acumulada del equipo).
¿Son suficientes las APIs de memoria ligeras para equipos con muchos flujos de trabajo?
Generalmente, no. Las APIs ligeras son excelentes para recordar preferencias simples del usuario (por ejemplo, 'prefiero Python antes que JavaScript'). Sin embargo, los equipos con muchos flujos de trabajo, que lidian con estrictas normas de cumplimiento, patrones operativos repetitivos y hojas de cálculo detalladas, necesitan una capa de infraestructura más robusta que admita una aplicación compleja de reglas y control de versiones de datos.
¿Qué hace diferente a MemoryLake frente a herramientas de memoria más simples?
MemoryLake no se posiciona solo como una herramienta, sino como una capa de infraestructura persistente y gobernada por el usuario. Enfatiza la portabilidad entre modelos, lo que significa que la memoria de su equipo no queda bloqueada en un solo proveedor de IA. La empresa destaca su capacidad para manejar de forma nativa entradas multimodales complejas —como documentos empresariales y flujos de trabajo repetitivos—, al tiempo que ofrece a los equipos la gobernanza necesaria para auditar y gestionar esa memoria de forma segura.